
【系列文章合集】
前面已经介绍过了两种线性表——顺序存储结构的顺序表和链式存储结构的链表,也介绍了如何对其进行基本增删改查操作。这两种线性表的增加和删除可以在表的任意位置进行操作,比如链表的头插法和尾插法。
下面介绍一种特殊的线性表——栈。
1. 什么是栈?
栈,我们在日常生活中经常会听到一个与之相关的词语——栈道。什么是栈道?指沿悬崖峭壁修建的一种道路。李白诗《蜀道难》中的“天梯石栈相勾连”就是指这种栈:

这种栈道的特点是很窄、很险,上图的栈仅能容纳一人,只能通过一侧进来和出去。在上图中,如果最左边的人想要出去,就得等右边的人全走了,他才能走。也即,最先进来的最后出去,最后进来的最先出去。
栈的英文是 Stack,本义是“一堆成叠的”。比如一堆成叠的书:

在这叠书中,放书和拿书都从上面,要想拿到底下那个最大的,就得先把上面的几个小的先拿掉。也即,先放的书最后才能拿,最后放的书可以最先那。
有了这两个实际的例子,我们心中对“栈”这个数据结构就有了一个“形状”了。
首先,栈是一个线性表(线性表的详细介绍),所以它得具有以下特点:
- 线性表由若干元素组成,用来存储信息。
- 元素之间有顺序。
- 除了首元素(只有一个直接后继元素)和尾元素(只有一个直接前驱元素)外,其它元素都有且仅有一个直接前驱元素和一个直接后继元素。
其次,栈是一个受限的线性表,受限之处为:
- 只能在一端进行操作(增删改查等)
根据以上总结的特点,我们可以画出栈的示意图,由于只能在一端进行操作,所以我们可以将其画为只有一个开口的“容器”:
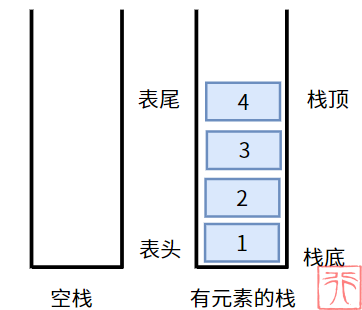
进行插入和删除操作的那一端称为栈顶(表尾),另一端称为栈底(表头)。
栈有两种重要的操作——入栈(压栈)和出栈(弹栈)。
所谓入栈(压栈),即栈的插入操作,由于栈的只能从栈顶插入元素的特性,所以插入元素看起来是将元素给“压入”栈。

所谓出栈(弹栈),即栈的删除操作,由于栈的只能从栈顶删除元素的特性,所以删除元素看起来是将元素给“弹出”栈,弹出的元素必定是栈顶元素。
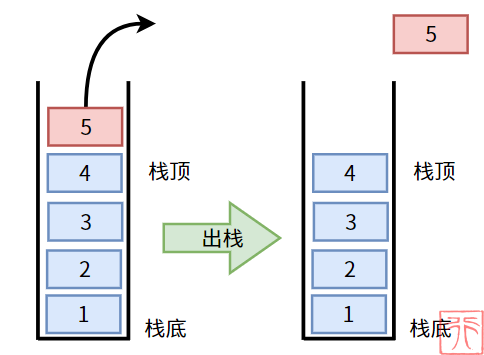
栈的只能在一端操作的特性,导致栈具有一个非常特殊的特点,下图中的栈,元素入栈的顺序为:1、2、3、4,但是元素出栈的顺序则为:4、3、2、1。
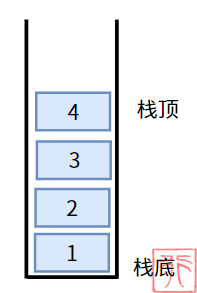
也即,先入栈的后出栈(First In Last Out, FILO),后入栈的先出栈(Last In First Out, LIFO),这是栈作为一种受限的线性表的非常重要的特性。
总结一下:栈是一种只能在表尾操作的后入先出的受限的线性表。
2. 栈的实现思路
栈虽然是一种受限的线性表,但线性表有的一些基本特性,栈也具备。在前面已经介绍过了线性表的顺序存储结构(数组实现)和线性表的链式存储结构(链表实现),栈也可以使用这两种方式来实现得到数组栈和链表栈。
2.1. 数组实现——数组栈
分析一下栈的结构就可以知道栈有两个必要结构:
- 用来存储数据的数组——
data[] - 用来表示线性表的最大存储容量的值——
MAXSIZE - 用来标识栈顶元素的栈顶下标——
top
这里规定:栈顶下标是栈顶元素的下标。
栈顶下标还可以表示栈的当前长度。
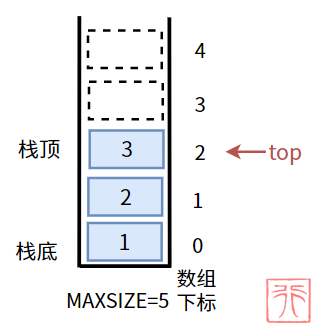
使用 C 语言的结构体实现如下:
为了方便起见,这里的栈只存储整数
#define MAXSIZE 5 //栈的最大存储容量
/*数组栈的结构体*/
typedef struct {
int data[MAXSIZE]; //存储数据的数组
int top; //栈顶下标
}2.2. 链表实现——链表栈
首先我们得先了解单链表的具体原理及实现,详细介绍移步至文章【单链表】。
链表栈的结构和数组栈的结构有所不同,其必要结构如下:
- 链表的基本单元结点 ——
StackNode- 结点的数据域——
data - 结点的指针域——
next
- 结点的数据域——
- 指向链表头的头指针 ——
head - 指向栈顶结点的栈顶指针 ——
top
为了方便起见,我们可以再添加一个栈的长度—— length。
前面说了,栈是一种只能在表尾操作的后入先出的受限的线性表。放在链表中,就是只在链表尾或链表头操作。那么是选择链表尾还是链表头呢?
上面已经列出了链表栈的必要结构,其中包括了两个指针:头指针和栈顶指针。我们可以把这两个指针合二为一,即使用链表的头指针作为栈的栈顶指针,如此一来,链表栈的操作就需要放在链表头进行,即借用链表头插法和头删法完成栈的 push 和 pop。
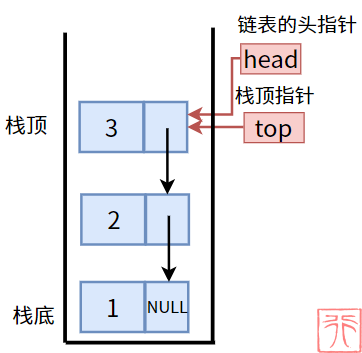
数组栈的容量是固定的,而链表栈的容量则不是固定的。在这里,我们使用不带头结点的链表来实现栈。
代码实现如下:
/*链表栈结点的结构体*/
typedef struct StackNode {
int data; //数据域
struct StackNode *next; //指针域
} StackNode;/*栈的结构体*/
typedef struct StackLink {
StackNode *top; //栈顶指针
int length; //栈的长度
} StackLink;3. 栈的状态
3.1. 数组栈的状态
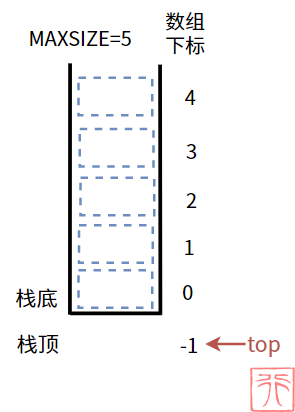
数组栈有三种状态:空栈、满栈、非空非满栈。通过栈顶下标和栈的最大容量之间的关系,可以很容易判断出这三种状态。
【空栈】:栈中没有元素。
因为数组下标是从 0 开始的,所以此时栈顶下标 top 的值通常置为 -1,以此表示栈中无元素。
【满栈】:栈中元素已满,没有多余容量。
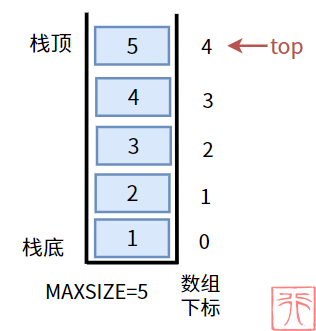
从图中可以看出,栈满时满足条件 top = MAXSIZE - 1。
【非空非满栈】: 栈不是空栈且容量仍有剩余。
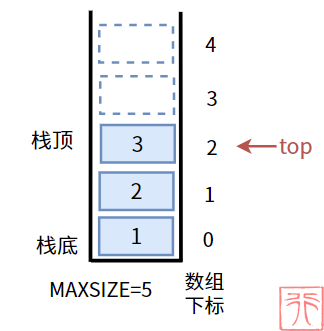
此时的栈满足条件 -1 < top < MAXSIZE - 1。
3.2. 链表栈的状态
数组栈之所以有三种状态,是因为有最大容量这个限制,而链表栈的元素不收约束,所以链表栈只有空栈和非空栈两种状态。
当为空栈时,栈顶指针和头指针都指向 NULL:
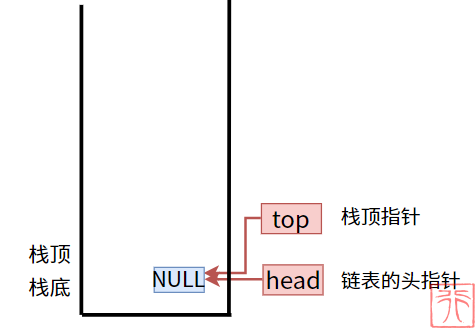
4. 初始化
所谓初始化,即把栈初始化为空栈的状态。
4.1. 数组栈的初始化
将数组栈的栈顶下标置为 -1 即可。
/**
* 数组栈的初始化:将栈的栈顶下标置为 -1
* stack: 指向要操作的栈的指针
*/
void init(StackArray *stack)
{
stack->top = -1;
}4.2. 链表栈的初始化
需要将栈顶指针 top (即链表头指针 head)置为 NULL,将栈的长度 length 置为 0。
/**
* 初始化:将栈顶指针置为 NULL,长度置为 0
* stack: 指向要操作的栈的指针
*/
void init(StackLink *stack)
{
stack->top = NULL;
stack->length = 0;
}5. 入栈操作
5.1. 数组栈
入栈前我们要搞清楚一个问题:
由于栈顶下标是栈顶元素的下标,所以在入栈前我们需要先将栈顶下标“上移”,给新入栈的元素腾出位置。然后才能将新元素入栈。
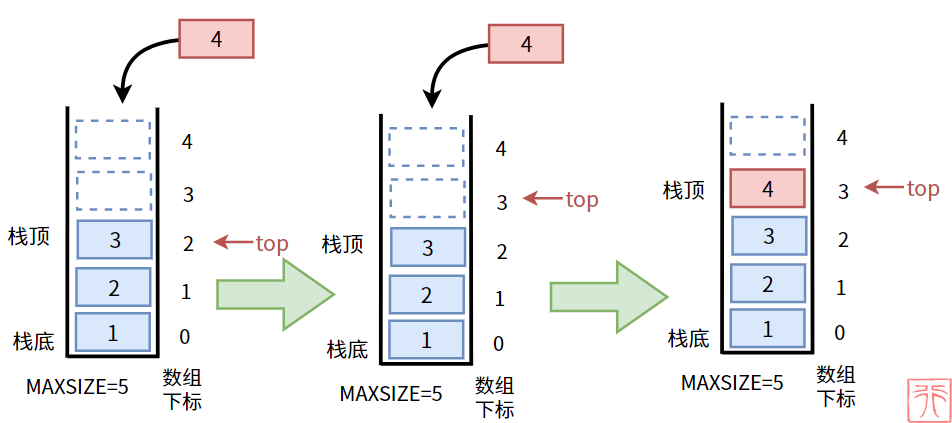
在入栈前先检查一下栈是否已满,具体代码实现如下:
/**
* 入栈操作
* stack: 指向要操作的栈的指针
* elem: 要入栈的数据
* return: 0失败,1成功
*/
int push(StackArray *stack, int elem)
{
if (stack->top == MAXSIZE - 1) {
printf("栈已满,无法继续入栈。\n");
return 0;
}
stack->top++;
stack->data[stack->top] = elem;
return 1;
}5.2. 链表栈
链表栈的入栈操作实质为[头插法](###2.7.2. 头插法),过程如下:
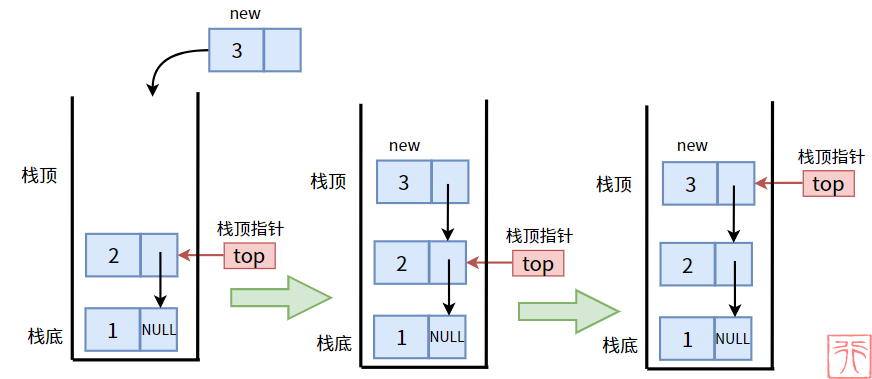
具体代码实现如下:
StackNode *create_node(int elem)
{
StackNode *new = (StackNode *) malloc(sizeof(StackNode));
new->data = elem;
new->next = NULL;
return new;
}
/**
* 入栈操作: 本质是单链表的尾插法
* head: 头指针
* elem: 要入栈的结点的值
*/
void push(StackLink *stack, int elem)
{
StackNode *new = create_node(elem);
// 链表的头插法
new->next = stack->top;
stack->top = new;
//栈长度加一
stack->length++;
}6. 出栈操作
6.1. 数组栈
出栈操作和入栈操作刚还相反,即先将元素出栈,然后将栈顶下标“下移”。
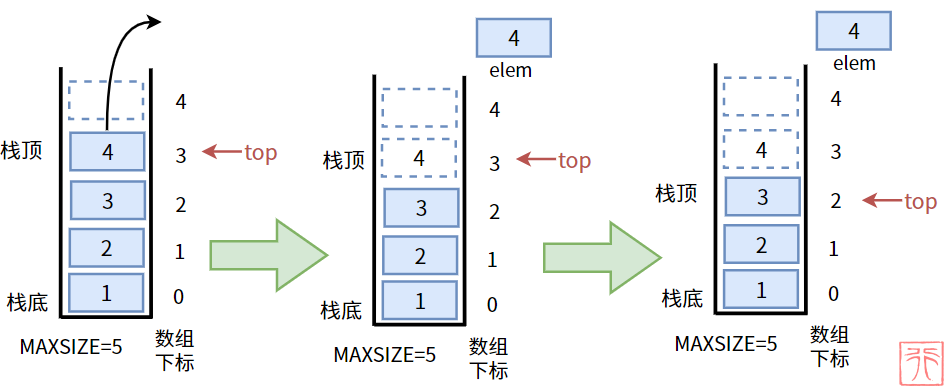
出栈前先检查栈是否为空栈,具体代码实现如下:
/**
* 出栈操作
* stack: 指向要操作的栈的指针
* elem: 指向保存变量的指针
* return: 0失败,1成功
*/
int pop(StackArray *stack, int *elem)
{
if (stack->top == -1) {
printf("栈空,无元素可出栈。\n");
return 0;
}
*elem = stack->data[stack->top];
stack->top--;
return 1;
}6.2. 链表栈
链表栈的出栈操作实质为头删法,即从链表头删除结点,过程如下:
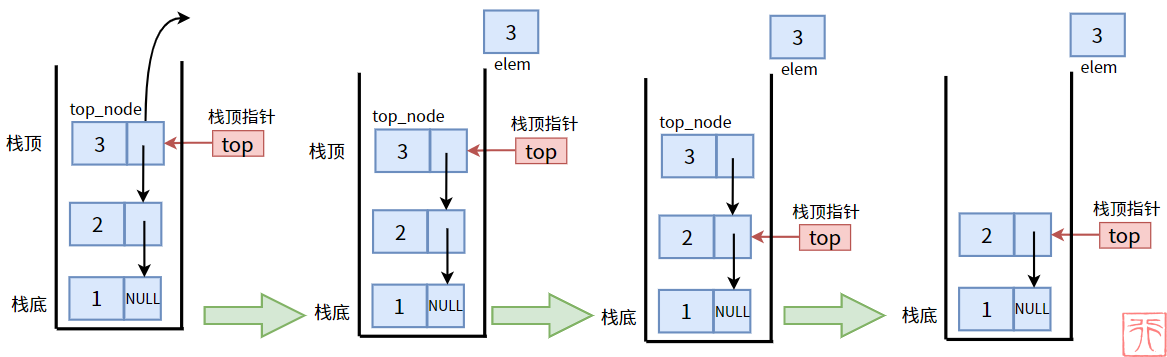
出栈前先检查栈是否为空栈,具体代码实现如下:
/**
* 出栈操作
* stack: 指向要操作的栈的指针
* elem: 指向保存变量的指针
* return: 0失败,1成功
*/
int pop(StackLink *stack, int *elem)
{
if (stack->length == 0) {
printf("栈空,无元素可出栈。\n");
return 0;
}
// top_node 指向栈顶结点
StackNode *top_node = stack->top;
//保存栈顶结点的值
*elem = top_node->data;
//栈顶指针下移
stack->top = top_node->next;
//释放 top_node
free(top_node);
stack->length--;
return 1;
}7. 遍历栈
这里以打印栈为例来介绍如何遍历栈。
7.1. 数组栈
数组栈的遍历本质是在遍历数组,一个 for 循环即可搞定。
/**
* 打印栈
* stack: 要打印的栈
*/
void output(StackArray stack)
{
if (stack.top == -1) {
printf("空栈。\n");
return;
}
for (int i = stack.top; i >= 0; i--) {
printf("%d ", stack.data[i]);
}
printf("\n");
}7.2. 链表栈
链表栈的遍历本质是在遍历链表,借助一个辅助指针从栈顶开始进行 while 或 for 循环即可。
/**
* 打印栈
* stack: 要打印的栈
*/
void output(StackLink *stack)
{
if (stack->length == 0) {
printf("空栈。\n");
return;
}
StackNode *p = stack->top;
while (p != NULL) {
printf("%d ", p->data);
p = p->next;
}
printf("\n");
}以上就是栈的基本原理介绍。
如有错误,还请指正。
如果感觉写的不错,可以点个关注。












