

点击右侧关注,大数据开发领域最强公众号!


点击右侧关注,暴走大数据!

生产消费者模式,指的是由生产者将数据源源不断推送到消息中心,由不同的消费者从消息中心取出数据做自己的处理,在同一类别下,所有消费者拿到的都是同样的数据;订阅发布模式,本质上也是一种生产消费者模式,不同的是,由订阅者首先向消息中心指定自己对哪些数据感兴趣,发布者推送的数据经过消息中心后,每个订阅者拿到的仅仅是自己感兴趣的一组数据。这两种模式是使用消息中间件时最常用的,用于功能解耦和分布式系统间的消息通信。
本文将继续以“数据接入”和“事件分发”这两个场景为例,来探讨Kafka作为消息系统的应用方法(High Level)。搞清楚Kafka的基本概念和应用方法是进行系统方案设计的前提,编写代码只是具体落地实施,而解决bug和性能调优是系统跑起来之后的事情了。需要指出的是,本文重点是探讨应用方法,具体应用时需要根据自身需求来做调整,没有任何技术方案是万能的。
数据接入
假设有一个用户行为采集系统,负责从App端采集用户点击行为数据。通常会将数据上报和数据处理分离开,即App端通过REST API上报数据,后端拿到数据后放入队列中就立刻返回,而数据处理则另外使用Worker从队列中取出数据来做,如下图所示。

这样做的好处有:第一,功能分离,上报的API接口不关心数据处理功能,只负责接入数据;第二,数据缓冲,数据上报的速率是不可控的,取决于用户使用频率,采用该模式可以一定程度地缓冲数据;第三,易于扩展,在数据量大时,通过增加数据处理Worker来扩展,提高处理速率。这便是典型的生产消费者模式,数据上报为生产者,数据处理为消费者。
事件分发
假设有一个电商系统,那么,用户“收藏”、“下单”、“付款”等行为都是非常重要的事件,通常后端服务在完成相应的功能处理外,还需要在这些事件点上做很多其他处理动作,比如发送短信通知、记录用户积分等等。我们可以将这些额外的处理动作放到每个模块中,但这并不是优雅的实现,不利于功能解耦和代码维护。
我们需要的是一个事件分发系统,在各个功能模块中将对应的事件发布出来,由对其感兴趣的处理者进行处理。这里涉及两个角色:A对B感兴趣,A是处理者,B是事件,由事件处理器完成二者的绑定,并向消息中心订阅事件。服务模块是后端的业务逻辑服务,在不同的事件点发布事件,事件经过消息中心分发给事件处理器对应的处理者。整个流程如下图所示。这边是典型的订阅发布模式。

Kafka基本概念
Kafka是一个分布式流数据系统,使用Zookeeper进行集群的管理。与其他消息系统类似,整个系统由生产者、Broker Server和消费者三部分组成,生产者和消费者由开发人员编写,通过API连接到Broker Server进行数据操作。我们重点关注三个概念:
Topic,是Kafka下消息的类别,类似于RabbitMQ中的Exchange的概念。这是逻辑上的概念,用来区分、隔离不同的消息数据,屏蔽了底层复杂的存储方式。对于大多数人来说,在开发的时候只需要关注数据写入到了哪个topic、从哪个topic取出数据。
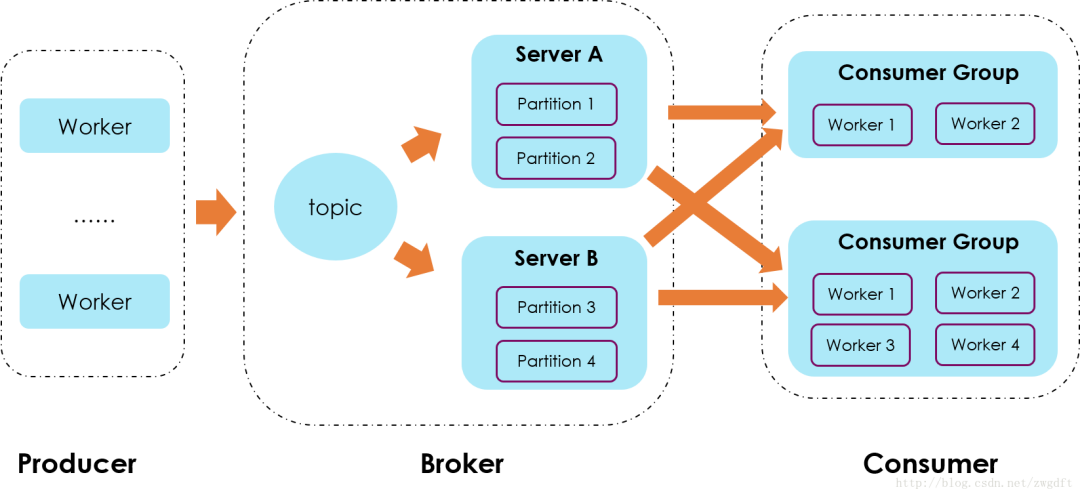
Partition,是Kafka下数据存储的基本单元,这个是物理上的概念。同一个topic的数据,会被分散的存储到多个partition中,这些partition可以在同一台机器上,也可以是在多台机器上,比如下图所示的topic就有4个partition,分散在两台机器上。这种方式在大多数分布式存储中都可以见到,比如MongoDB、Elasticsearch的分片技术,其优势在于:有利于水平扩展,避免单台机器在磁盘空间和性能上的限制,同时可以通过复制来增加数据冗余性,提高容灾能力。为了做到均匀分布,通常partition的数量通常是Broker Server数量的整数倍。
Consumer Group,同样是逻辑上的概念,是Kafka实现单播和广播两种消息模型的手段。同一个topic的数据,会广播给不同的group;同一个group中的worker,只有一个worker能拿到这个数据。换句话说,对于同一个topic,每个group都可以拿到同样的所有数据,但是数据进入group后只能被其中的一个worker消费。group内的worker可以使用多线程或多进程来实现,也可以将进程分散在多台机器上,worker的数量通常不超过partition的数量,且二者最好保持整数倍关系,因为Kafka在设计时假定了一个partition只能被一个worker消费(同一group内)。
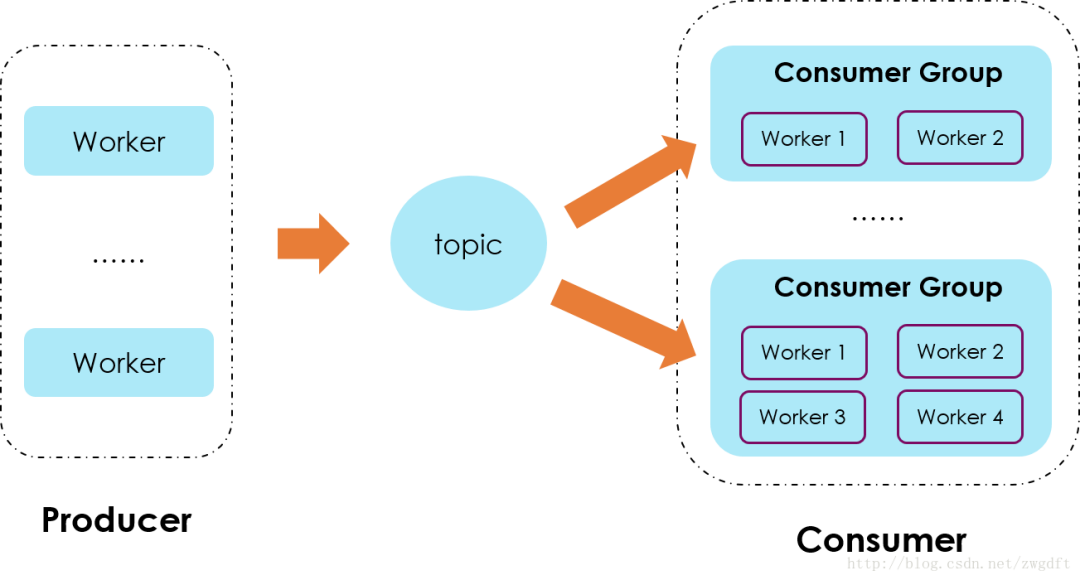
生产消费者模式
搞清楚了Kafka的基本概念后,我们来看如何设计生产消费者模式来实现上述的“数据接入”场景。在下图中,由Producer负责接收前端上报的数据,投递到对应的topic中(这里忽略了Broker Server的细节),在Consumer端,所有对该数据感兴趣的业务都可以建立自己的group来消费数据,至于group内部开多少个worke来消费完全取决于数据量和业务的实时性要求了。
订阅发布模式
再来看“事件分发”的场景,假如我们有“收藏”、“下单”、“付款”三个事件,业务一对“收藏”和“下单”事件感兴趣,而业务二对“下单”和“付款”事件感兴趣,那么我们如何进行事件订阅?不同于RabbitMQ中有数据路由机制(routing key),可以将感兴趣的事件绑定到自己的Queue上,Kafka只提供了单播和广播的消息模型,无法直接进行消费对象的绑定,所以理论上Kafka是不适合做此种场景下的订阅发布模式的,如果一定要做,有这么几个方案:
方案一:继续使用上述生产消费者的模式,在不同的group中过滤出自己感兴趣的事件数据,然后进行处理。这种方式简单有效,缺点就是每个group都会收到很多自己不感兴趣的垃圾数据。
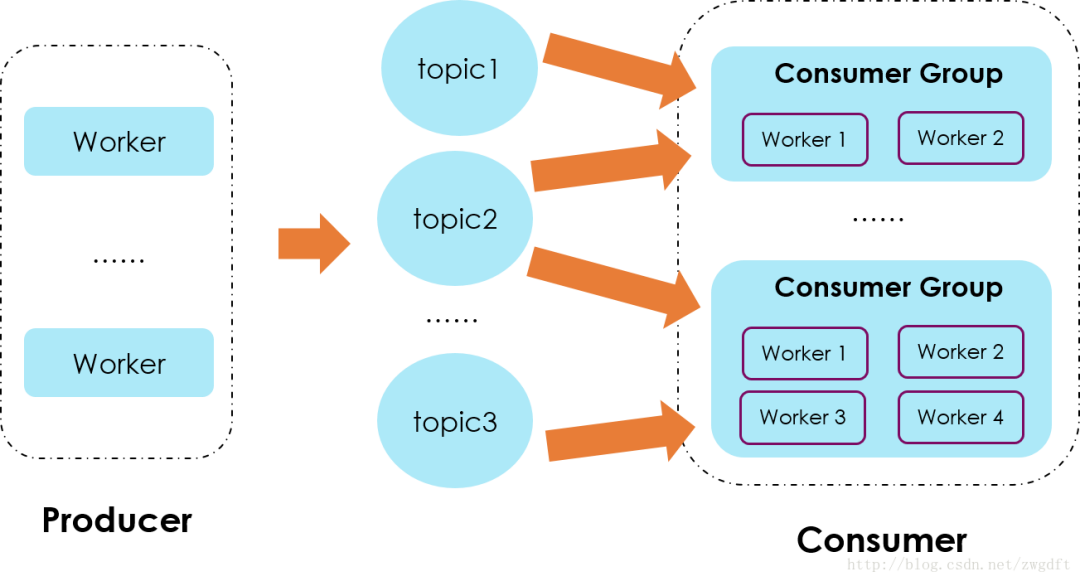
方案二:把每个事件的数据推送到不同的topic中,即以事件名称来作为topic分类,在Consumer端,建立自己的group来消费自己感兴趣的一组topic。这种方式适用于事件个数可以明确评估并且数量较少,如果事件种类很多,会导致topic的数量过多,创建过多的topic和partition则会影响到Kafka的性能,因为Kafka的每个Topic、每个分区都会对应一个物理文件,当Topic数量增加时,消息分散的落盘策略会导致磁盘IO竞争激烈成为瓶颈。
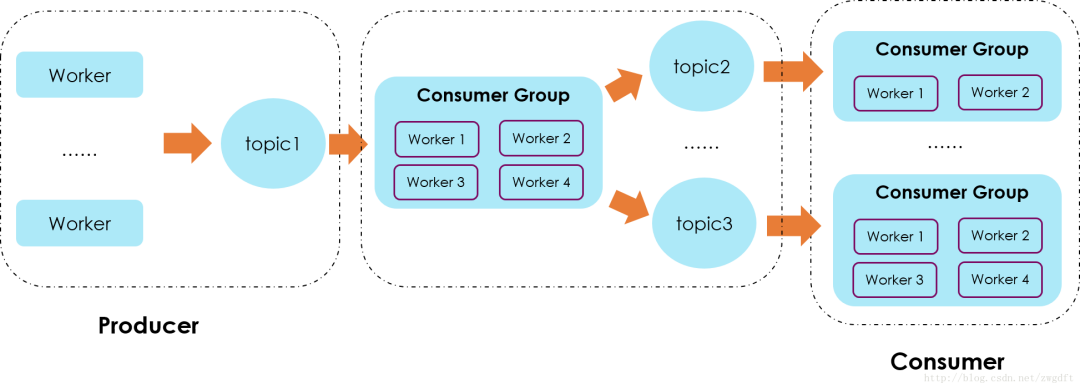
方案三:采用流处理方式对数据进行分类,即增加一个中间数据流处理,将数据按照订阅规则进行归类,然后写入不同的topic中,在Consumer端,每个group可以拿到仅仅是自己感兴趣的数据。这种方式适用于数据量较大、但是Consumer端的消费group有限的情况,否则也会出现上述的topic碎片化的问题。
方案四:自己做partition的分配,但是不容易控制,应尽量避免。
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











