

点击右侧关注,大数据开发领域最强公众号!


点击右侧关注,暴走大数据!

文章目录
一、概述
二、Window分类
1、TimeWindow与CountWindow
2、TimeWindow子类型
Tumble Window(翻转窗口)
Hop Window(滑动窗口)
Session Window(会话窗口)
三、Window分类及整体流程
四、创建WindowOperator算子
五、WindowOperator处理数据图解
六、WindowOperator源码调试
1、StreamExecGroupWindowAggregate#createWindowOperator()创建算子
2、WindowOperator#processElement()处理数据,注册Timer
3、Timer触发
InternalTimerServiceImpl#advanceWatermark()
WindwOperator#onEventTime()
emitWindowResult()提交结果
七、Emit(Trigger)触发器
1、Emit策略
2、用途
3、语法
4、示例
5、Trigger类和结构关系
概述
窗口是无限流上一种核心机制,可以流分割为有限大小的“窗口”,同时,在窗口内进行聚合,从而把源源不断产生的数据根据不同的条件划分成一段一段有边界的数据区间,使用户能够利用窗口功能实现很多复杂的统计分析需求。
本文内容:
Flink SQL WINDOW功能介绍
底层实现源码分析:StreamExecGroupWindowAggregate创建WindowOperator
底层实现源码分析:WindowOperator算子处理数据这两个地方源码分析。
Window分类
1、TimeWindow与CountWindow Flink Window可以是时间驱动的(TimeWindow),也可以是数据驱动的(CountWindow)。由于flink-planner-blink SQL中目前只支持TimeWindow相应的表达语句(TUMBLE、HOP、SESSION),因此,本文主要介绍TimeWindow SQL示例和逻辑,CountWindow感兴趣的读者可自行分析。
2、TimeWindow子类型 Flink TimeWindow有滑动窗口(HOP)、滚动窗口(TUMBLE)以及会话窗口(SESSION)三种,所选取的字段时间,可以是系统时间(PROCTIME)或事件时间(EVENT TIME)两种,接来下依次介绍。
- Tumble Window(翻转窗口)
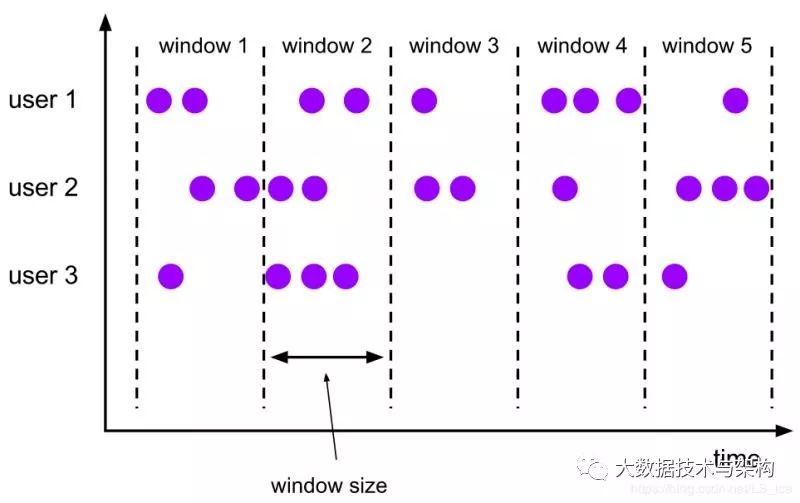
翻转窗口Assigner将每个元素分配给具有指定大小的窗口。翻转窗口的大小是固定的,且不会重叠。例如,指定一个大小为5分钟的翻滚窗口,并每5分钟启动一个新窗口,如下图所示:
TUMBLE ROWTIME语法示例:
CREATE TABLE sessionOrderTableRowtime ( ctime TIMESTAMP, categoryName VARCHAR, shopName VARCHAR, itemName VARCHAR, userId VARCHAR, price FLOAT, action BIGINT, WATERMARK FOR ctime AS withOffset(ctime, 1000), proc AS PROCTIME()) with ( `type` = 'kafka', format = 'json', updateMode = 'append', `group.id` = 'groupId', bootstrap.servers = 'xxxxx:9092', version = '0.10', `zookeeper.connect` = 'xxxxx:2181', startingOffsets = 'latest', topic = 'sessionsourceproctime');CREATE TABLE popwindowsink ( countA BIGINT, ctime_start TIMESTAMP, ctime_end VARCHAR, ctime_rowtime VARCHAR, categoryName VARCHAR, price_sum FLOAT) with ( format = 'json', updateMode = 'append', bootstrap.servers = 'xxxxx:9092', version = '0.10', topic = 'sessionsinkproctime', `type` = 'kafka');INSERT INTO popwindowsink(SELECTCOUNT(*),TUMBLE_START(ctime, INTERVAL '5' MINUTE),DATE_FORMAT(TUMBLE_END(ctime, INTERVAL '5' MINUTE), 'yyyy-MM-dd-HH-mm-ss:SSS'), --将TUMBLE_END转为可视化的日期DATE_FORMAT(TUMBLE_ROWTIME(ctime, INTERVAL '5' MINUTE), 'yyyy-MM-dd-HH-mm-ss:SSS'), --这里TUMBLE_ROWTIME为TUMBLE_END-1ms,一般用于后续窗口级联聚合categoryName,SUM(price)FROM sessionOrderTableRowtimeGROUP BY TUMBLE(ctime, INTERVAL '5' MINUTE), categoryName)
TUMBLEP ROCTIME语法示例:
INSERT INTO popwindowsink(SELECTCOUNT(*),TUMBLE_START(proc, INTERVAL '5' MINUTE),DATE_FORMAT(TUMBLE_END(proc, INTERVAL '5' MINUTE), 'yyyy-MM-dd-HH-mm-ss:SSS'),DATE_FORMAT(TUMBLE_PROCTIME(proc, INTERVAL '5' MINUTE), 'yyyy-MM-dd-HH-mm-ss:SSS'), --注意这里proc字段即Source DDL中指定的PROCTIMEcategoryName,SUM(price)FROM sessionOrderTableRowtimeGROUP BY TUMBLE(proc, INTERVAL '5' MINUTE), categoryName)
ROWTIME与PROCTIME区别:
在使用上:主要是填入的ctime、proc关键字的区别,这两个字段在Source DDL中指定方式不一样.
在实现原理上:ROWTIME模式,根据ctime对应的值,去确定窗口的start、end;PROCTIME模式,在WindowOperator处理数据时,获取本地系统时间,去确定窗口的start、end.
由于生产系统中,主要使用ROWTIME来计算、聚合、统计,PROCTIME一般用于测试或对统计精度要求不高的场景,本文后续都主要以ROWTIME进行分析。
- Hop Window(滑动窗口)
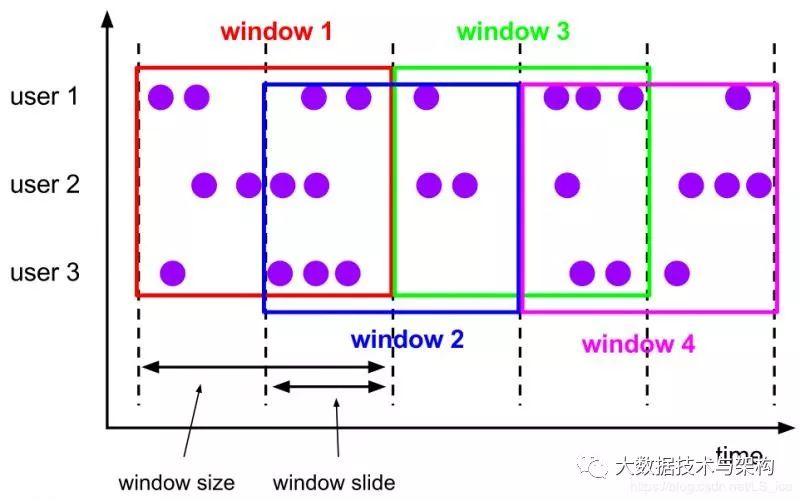
滑动窗口Assigner将元素分配给多个固定长度的窗口。类似于滚动窗口分配程序,窗口的大小由窗口大小参数配置。因此,如果滑动窗口小于窗口大小,则滑动窗口可以重叠。在这种情况下,元素被分配到多个窗口。其实,滚动窗口TUMBLE是滑动窗口的一个特例。例子,设置一个10分钟长度的窗口,以5分钟间隔滑动。这样,每5分钟就会出现一个窗口,其中包含最近10分钟内到达的事件,如下图:
HOP ROWTIME语法示例:
INSERT INTO popwindowsink(SELECTCOUNT(*),HOP_START(ctime, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE),DATE_FORMAT(HOP_END(ctime, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE), 'yyyy-MM-dd-HH-mm-ss:SSS'),DATE_FORMAT(HOP_ROWTIME(ctime, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE), 'yyyy-MM-dd-HH-mm-ss:SSS'), --注意这里ctime字段即Source DDL中指定的ROWTIMEcategoryName,SUM(price)FROM sessionOrderTableRowtimeGROUP BY HOP(ctime, INTERVAL '5' MINUTE, INTERVAL '10' MINUTE), categoryName)
Session Window(会话窗口)
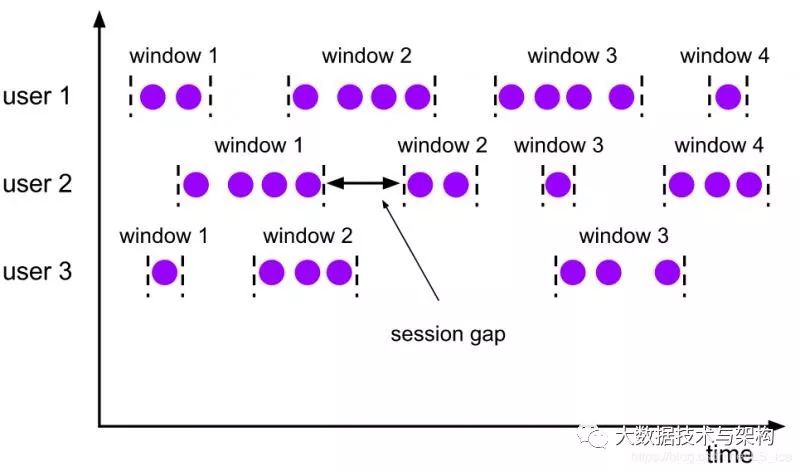
会话窗口Assigner根据活动会话对元素进行分组。与翻滚窗口和滑动窗口相比,会话窗口不会重叠,也没有固定的开始和结束时间。相反,会话窗口在一段时间内不接收元素时关闭,即,当一段不活跃的间隙发生时,当前会话关闭,随后的元素被分配给新的会话。
SESSION ROWTIME语法示例:
INSERT INTO popwindowsink(SELECTCOUNT(*),SESSION_START(ctime, INTERVAL '5' MINUTE),DATE_FORMAT(SESSION_END(ctime, INTERVAL '5' MINUTE, 'yyyy-MM-dd-HH-mm-ss:SSS'),DATE_FORMAT(SESSION_ROWTIME(ctime, INTERVAL '5' MINUTE), 'yyyy-MM-dd-HH-mm-ss:SSS'), --注意这里ctime字段即Source DDL中指定的ROWTIMEcategoryName,SUM(price)FROM sessionOrderTableRowtimeGROUP BY SESSION(ctime, INTERVAL '5' MINUTE), categoryName)
Window分类及整体流程
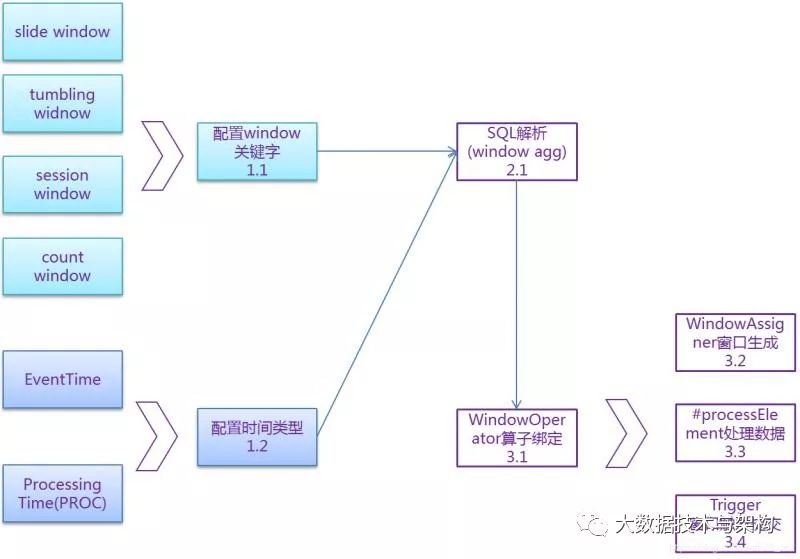
上图内部流程分析:应用层SQL:1.1 window分类及配置,包括滑动、翻转、会话类型窗口1.2 window时间类型配置,默认待字段名的EventTime,也可以通过PROCTIME()配置为ProcessingTimeCalcite解析引擎:2.1 Calcite SQL解析,包括逻辑、优化、物理计划和算子绑定(#translateToPlanInternal),在本文特指StreamExecGroupWindowAggregateRule和StreamExecGroupWindowAggregate物理计划WindowOperator算子创建相关:3.1 StreamExecGroupWindowAggregate#createWindowOperator创建算子3.2 WindowAssigner的创建,根据输入的数据,和窗口类型,生成多个窗口3.3 processElement()真实处理数据,包括聚合运算,生成窗口,更新缓存,提交数据等功能3.4 Trigger根据数据或时间,来决定窗口触发
创建WindowOperator算子
由于window语法主要是在group by语句中使用,calcite创建WindowOperator算子伴随着聚合策略的实现,包括聚合规则匹配(StreamExecGroupWindowAggregateRule),以及生成聚合physical算子StreamExecGroupWindowAggregate两个子流程:
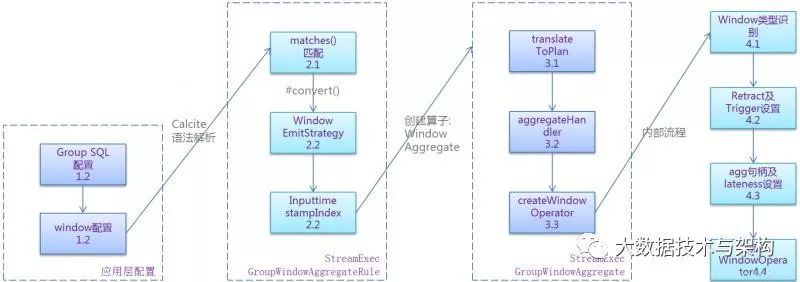
上图内部流程分析:a. StreamExecGroupWindowAggregateRule会对window进行提前匹配,生成的WindowEmitStrategy内部具有:是否为EventTime表标识、是否为SessionWindow、early fire和late fire配置、延迟毫秒数(窗口结束时间加上这个毫秒数即数据清理时间)b. StreamExecGroupWindowAggregateRule会获取聚合逻辑计划中,window配置的时间字段,记录时间字段index信息,window的触发和清理都会用到这个时间c. StreamExecGroupWindowAggregate入口即为translateToPlanInternal,它的实现方式与spark比较类似,会先循环调用child子节点translateToPlan方法,生成inputtranform信息作为输入d.创建aggregateHandler是一个代码生成的过程,其生成的创建的class实现了accumulate、retract、merge、update方法,这个handler最后也传递给了WindowOperater,处理数据时,可以进行聚合、回撤并输出最新数据给下游e. StreamExecGroupWindowAggregate与window相关的最后一步就是调用#createWindowOperator创建算子,其内部先创建了一个WindowOperatorBuilder,设置window类型、retract标识、trigger(window触发条件)、聚合函数句柄等,最后创建WindowOperator
WindowOperator处理数据图解
在上一小节,已经完成了WindowOperator参数的设定,并创建实例,接下来我们主要分析WindowOperator真实处理数据的流程(起点在WindowOperator#processElement方法):
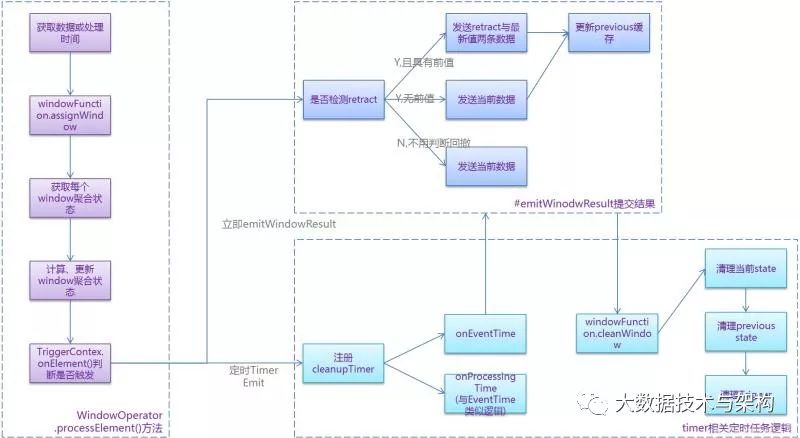
processElement处理数据流程:a、 获取当前record具有的事件时间,如果是Processing Time模式,从时间服务Service里面获取时间即可b、使用上一步获取的时间,接着调用windowFunction.assignWindow生成窗口,其内部实际上是调用各类型的WindowAssigner生成窗口,windowFunction有三大类,分别是Paned(滑动)、Merge(会话)、General(前两种以外的),WindowAssigner类型大致有5类,分别是Tumbling(翻转)、Sliding(滑动)、Session(会话)、CountTumbling 、CountSlide这几类,根据输入的一条数据和时间,可以生成1到多个窗口c、接下来是遍历涉及的窗口进行聚合,包括从windowState获取聚合前值、使用句柄进行聚合、更新状态至windowState,将当前转态d、上一步聚合完成后,就可以遍历窗口,使用TriggerContext(其实就是不同类型窗口Trigger触发器的代理),综合early fire、late fire、水印时间与窗口结束时间,综合判断是否触发窗口写出e、如果TriggerContext判断出触发条件为true,则调用emitWindowResult写出,其内部有retract判断,更新当前state及previous state,写出数据等操作f、如果TriggerContext判断出触发条件为false,则触发需要注册cleanupTimer,到达指定时间后,触发onEventTime或onProcessingTimeg、onEventTime或onProcessingTime功能十分类似,首先会触发emitWindowResult提交结果,另外会判断窗口结束时间+Lateness和当前时间是否相等,相等则表示可以清除窗口数据、当前state及previous state、窗口对应trigger。
WindowOperator源码调试
为了更直观的理解Window内部运行原理,这里我们引入一个Flink源码中已有的SQL Window测试用例,并进行了简单的修改(即修改为使用HOP滑动窗口)
classWindowJoinITCase{ @Test def testRowTimeInnerJoinWithWindowAggregateOnFirstTime(): Unit = { val sqlQuery = """ |SELECT t1.key, HOP_END(t1.rowtime, INTERVAL '4' SECOND, INTERVAL '20' SECOND), COUNT(t1.key) |FROM T1 AS t1 |GROUP BY HOP(t1.rowtime, INTERVAL '4' SECOND, INTERVAL '20' SECOND), t1.key |""".stripMargin val data1 = new mutable.MutableList[(String, String, Long)] data1.+=(("A", "L-1", 1000L)) data1.+=(("A", "L-2", 2000L)) data1.+=(("A", "L-3", 3000L)) //data1.+=(("B", "L-8", 2000L)) data1.+=(("B", "L-4", 4000L)) data1.+=(("C", "L-5", 2100L)) data1.+=(("A", "L-6", 10000L)) data1.+=(("A", "L-7", 13000L)) val t1 = env.fromCollection(data1) .assignTimestampsAndWatermarks(new Row3WatermarkExtractor2) .toTable(tEnv, 'key, 'id, 'rowtime) tEnv.registerTable("T1", t1) val sink = new TestingAppendSink val t_r = tEnv.sqlQuery(sqlQuery) val result = t_r.toAppendStream[Row] result.addSink(sink) env.execute() }}
1、StreamExecGroupWindowAggregate#createWindowOperator()创建算子
StreamExecGroupWindowAggregate#createWindowOperator()是创建WindowOperator算子的地方,对应的代码和注释:
class StreamExecGroupWindowAggregate{ private def createWindowOperator( config: TableConfig, aggsHandler: GeneratedNamespaceAggsHandleFunction[_], recordEqualiser: GeneratedRecordEqualiser, accTypes: Array[LogicalType], windowPropertyTypes: Array[LogicalType], aggValueTypes: Array[LogicalType], inputFields: Seq[LogicalType], timeIdx: Int): WindowOperator[_, _] = { val builder = WindowOperatorBuilder .builder() .withInputFields(inputFields.toArray) val timeZoneOffset = -config.getTimeZone.getOffset(Calendar.ZONE_OFFSET) // 设置WindowOperatorBuilder,最后通过Builder创建WindowOperator val newBuilder = window match { case TumblingGroupWindow(_, timeField, size) //Tumble PROCTIME模式,内部设置Assiger if isProctimeAttribute(timeField) && hasTimeIntervalType(size) => builder.tumble(toDuration(size), timeZoneOffset).withProcessingTime() case TumblingGroupWindow(_, timeField, size) //Tumble ROWTIME模式,内部设置Assiger if isRowtimeAttribute(timeField) && hasTimeIntervalType(size) => builder.tumble(toDuration(size), timeZoneOffset).withEventTime(timeIdx) case SlidingGroupWindow(_, timeField, size, slide) //HOP PROCTIME模式,内部设置Assiger if isProctimeAttribute(timeField) && hasTimeIntervalType(size) => builder.sliding(toDuration(size), toDuration(slide), timeZoneOffset) .withProcessingTime() ..... case SessionGroupWindow(_, timeField, gap) if isRowtimeAttribute(timeField) => builder.session(toDuration(gap)).withEventTime(timeIdx) } // Retraction和Trigger设置 //默认是no retract和EventTime.afterEndOfWindow if (emitStrategy.produceUpdates) { // mark this operator will send retraction and set new trigger newBuilder .withSendRetraction() .triggering(emitStrategy.getTrigger) } newBuilder .aggregate(aggsHandler, recordEqualiser, accTypes, aggValueTypes, windowPropertyTypes) .withAllowedLateness(Duration.ofMillis(emitStrategy.getAllowLateness)) .build() }}
2、WindowOperator#processElement()处理数据,注册Timer
public classWindowOperator{ publicvoidprocessElement(StreamRecord<BaseRow> record) throws Exception { BaseRow inputRow = record.getValue(); long timestamp; // 获取时间戳(数据时间或系统时间),这个时间是后续逻辑划分窗口的依据 // 例如获取的timestamp为10000L if (windowAssigner.isEventTime()) { timestamp = inputRow.getLong(rowtimeIndex); } else { timestamp = internalTimerService.currentProcessingTime(); } // 计算当前数据所属于的窗口,注意滑动窗口这里计算出来也只有一个affected窗口(见调试数据),在这个窗口内进行聚合 Collection<W> affectedWindows = windowFunction.assignStateNamespace(inputRow, timestamp); boolean isElementDropped = true; for (W window : affectedWindows) { isElementDropped = false; // 设置ValueState命名空间,例如TimeWindow{start=8000, end=12000} windowState.setCurrentNamespace(window); // 从windowState获取上次聚合值 BaseRow acc = windowState.value(); if (acc == null) { acc = windowAggregator.createAccumulators(); } windowAggregator.setAccumulators(window, acc); // 默认进行聚合 if (BaseRowUtil.isAccumulateMsg(inputRow)) { windowAggregator.accumulate(inputRow); } else { windowAggregator.retract(inputRow); } acc = windowAggregator.getAccumulators(); // 更新TimeWindow{start=8000, end=12000}对应聚合值 windowState.update(acc); } // 对应的实际窗口,例如输入Timestamp为10000L,且执行HOP(t1.rowtime, INTERVAL '4' SECOND, INTERVAL '20' SECOND),拆分出实际的窗口为: // TimeWindow{start=-8000, end=12000} // TimeWindow{start=-4000, end=16000} // TimeWindow{start=0, end=20000} // TimeWindow{start=4000, end=24000} // TimeWindow{start=8000, end=28000} Collection<W> actualWindows = windowFunction.assignActualWindows(inputRow, timestamp); for (W window : actualWindows) { isElementDropped = false; triggerContext.window = window; // 判断窗口是否立即触发,例如earliy fire模式,默认这里是不触发的,交给onEventTime()或onProcessingTime()来触发 boolean triggerResult = triggerContext.onElement(inputRow, timestamp); if (triggerResult) { emitWindowResult(window); } // 注册清理时间,根据时间模式,分别对应到Event Time对应Timer或Processing Time对应Timer // Event Time对应Timer通过全局watermark来触发,实现代码在InternalTimerServiceImpl#advanceWatermark() // watermark是一个递增的逻辑,后面代码解析 registerCleanupTimer(window); } if (isElementDropped) { // markEvent will increase numLateRecordsDropped lateRecordsDroppedRate.markEvent(); } }}
运行数据:

3、Timer触发 I、InternalTimerServiceImpl#advanceWatermark()
WindowOperator#onEventTime()的调用前,可以先看其上层调用:InternalTimerServiceImpl#advanceWatermark()
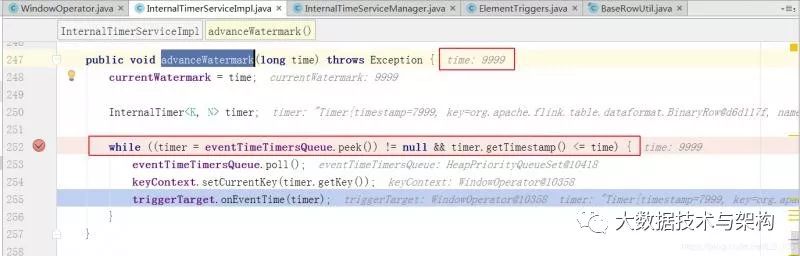
当获取的watermark为9999L时,把eventTimeTimerQueue队列中所有小于这个值的timer poll出来,调用WindowOperator.onEnventTime(timer)
II、WindwOperator#onEventTime()
WindwOperator#onEventTime()方法比较清晰,主要是window的触发和window的清理两段逻辑:
public classWindowOperator{ publicvoidonEventTime(InternalTimer<K, W> timer) throws Exception { setCurrentKey(timer.getKey()); triggerContext.window = timer.getNamespace(); if (triggerContext.onEventTime(timer.getTimestamp())) { // fire emitWindowResult(triggerContext.window); } if (windowAssigner.isEventTime()) { windowFunction.cleanWindowIfNeeded(triggerContext.window, timer.getTimestamp()); } }}
III、emitWindowResult()提交结果
#emitWindowResult()重点关注下其第一行代码:BaseRow aggResult = windowFunction.getWindowAggregationResult(window); 这个表示根据具体的TimeWindow{start=4000, end=24000},去获取聚合数据,如果是滑动窗口,需要将4000, 8000 ,12000,16000 , 20000, 24000这几段affect窗口里面的聚合值合并起来,内部逻辑:
public classPanedWindowProcessFunction{ public BaseRow getWindowAggregationResult(W window) throws Exception { Iterable<W> panes = windowAssigner.splitIntoPanes(window); BaseRow acc = windowAggregator.createAccumulators(); // null namespace means use heap data views windowAggregator.setAccumulators(null, acc); for (W pane : panes) { BaseRow paneAcc = ctx.getWindowAccumulators(pane); if (paneAcc != null) { windowAggregator.merge(pane, paneAcc); } } return windowAggregator.getValue(window); }}

Emit(Trigger)触发器
配置方式指定Trigger:Flink1.9.0目前支持通过TableConifg配置earlyFireInterval、lateFireInterval毫秒数,来指定窗口结束之前、窗口结束之后的触发策略(默认是watermark超过窗口结束后触发一次),策略的解析在WindowEmitStrategy,在StreamExecGroupWindowAggregateRule就会创建和解析这个策略
SQL方式指定Trigger:Flink1.9.0代码中calcite部分已有SqlEmit相关的实现,后续可以支持SQL 语句(INSERT INTO)中配置EMIT触发器
本文Emit和Trigger都是触发器这一个概念,只是使用的方式不一样
1、Emit策略 Emit 策略是指在Flink SQL 中,query的输出策略(如能忍受的延迟)可能在不同的场景有不同的需求,而这部分需求,传统的 ANSI SQL 并没有对应的语法支持。比如用户需求:1小时的时间窗口,窗口触发之前希望每分钟都能看到最新的结果,窗口触发之后希望不丢失迟到一天内的数据。针对这类需求,抽象出了EMIT语法,并扩展到了SQL语法。
2、用途 EMIT语法的用途目前总结起来主要提供了:控制延迟、数据精确性,两方面的功能。
控制延迟。针对大窗口,设置窗口触发之前的EMIT输出频率,减少用户看到结果的延迟(WITH| WITHOUT DELAY)。
数据精确性。不丢弃窗口触发之后的迟到的数据,修正输出结果(minIdleStateRetentionTime,在WindowEmitStrategy中生成allowLateness)。
在选择EMIT策略时,还需要与处理开销进行权衡。因为越低的输出延迟、越高的数据精确性,都会带来越高的计算开销。
3、语法 EMIT 语法是用来定义输出的策略,即是定义在输出(INSERT INTO)上的动作。当未配置时,保持原有默认行为,即 window 只在 watermark 触发时 EMIT 一个结果。
语法:INSERT INTO tableName query EMIT strategy [, strategy]*
strategy ::= {WITH DELAY timeInterval | WITHOUT DELAY} [BEFORE WATERMARK |AFTER WATERMARK]
timeInterval ::=‘string’ timeUnit
WITH DELAY:声明能忍受的结果延迟,即按指定 interval 进行间隔输出。WITHOUT DELAY:声明不忍受延迟,即每来一条数据就进行输出。BEFORE WATERMARK:窗口结束之前的策略配置,即watermark 触发之前。AFTER WATERMARK:窗口结束之后的策略配置,即watermark 触发之后。注:
其中 strategy可以定义多个,同时定义before和after的策略。但不能同时定义两个 before 或 两个after 的策略。
若配置了AFTER WATERMARK 策略,需要显式地在TableConfig中配置minIdleStateRetentionTime标识能忍受的最大迟到时间。
minIdleStateRetentionTime在window中只影响窗口何时清除,不直接影响窗口何时触发, 例如配置为3600000,最多容忍1小时的迟到数据,超过这个时间的数据会直接丢弃
4、示例 如果我们已经有一个TUMBLE(ctime, INTERVAL ‘1’ HOUR)的窗口,tumble_window 的输出是需要等到一小时结束才能看到结果,我们希望能尽早能看到窗口的结果(即使是不完整的结果)。例如,我们希望每分钟看到最新的窗口结果:INSERT INTO result SELECT * FROM tumble_window EMIT WITH DELAY ‘1’ MINUTE BEFORE WATERMARK – 窗口结束之前,每隔1分钟输出一次更新结果
tumble_window 会忽略并丢弃窗口结束后到达的数据,而这部分数据对我们来说很重要,希望能统计进最终的结果里。而且我们知道我们的迟到数据不会太多,且迟到时间不会超过一天以上,并且希望收到迟到的数据立刻就更新结果:INSERT INTO result SELECT * FROM tumble_window EMIT WITH DELAY ‘1’ MINUTE BEFORE WATERMARK, WITHOUT DELAY AFTER WATERMARK --窗口结束之后,每条到达的数据都输出
tEnv.getConfig.setIdleStateRetentionTime(Time.days(1), Time.days(2))//min、max,只有Time.days(1)这个参数直接对window生效
补充一下WITH DELAY '1’这种配置的周期触发策略(即DELAY大于0),最后都是由ProcessingTime系统时间触发:
class WindowEmitStrategy{ private def createTriggerFromInterval( enableDelayEmit: Boolean, interval: Long): Option[Trigger[TimeWindow]] = { if (!enableDelayEmit) { None } else { if (interval > 0) { // 系统时间触发,小于wm的所有timer都执行onProcessingTime() Some(ProcessingTimeTriggers.every(Duration.ofMillis(interval))) } else { // 为0则每条都触发 Some(ElementTriggers.every()) } } }}
5、Trigger类和结构关系 在源码中,Window Trigger的实现子类有10个左右,需要结合上一个小节的EMIT SQL能更容易理清他们之间的关系,这里简单介绍下:

AfterEndOfWindow:这个就是没配置任何EMIT策略时,默认的EvenTime、ProcTime
Window触发策略(即窗口结束后触发一次)
EveryElement:即delay=0,在processElement()时直接触发,无论是在窗口结束之前或者窗口结束之后都触发,且不再注册timer
AfterEndOfWindowNoLate:对应EMIT WITHOUT DELAY AFTER WATERMARK,窗口结束之前不输出,窗口结束之后无延迟输出
AfterFirstElementPeriodic:对应WITH DELAY ‘1’ MINUTE BEFORE| AFTER WATERMARK,即按系统时间周期执行,由ProcessingTime系统时间周期触发
欢迎点赞+收藏+转发朋友圈素质三连


文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











