
GitHub地址:https://github.com/leebingbin/
背景
随着互联网的发展,网站应用的规模不断扩大,常规的垂直应用架构已无法应对,分布式服务架构以及流动计算架构势在必行,亟需一个治理系统确保架构有条不紊的演进。
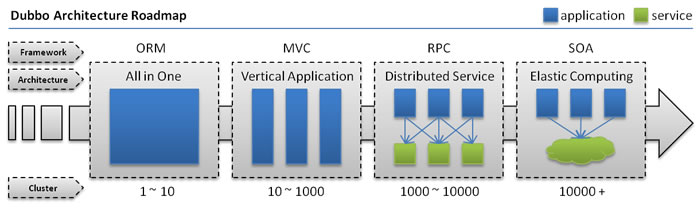
• 单一应用架构
• 当网站流量很小时,只需一个应用,将所有功能都部署在一起,以减少部署节点和成本。
• 此时,用于简化增删改查工作量的 数据访问框架(ORM) 是关键。
• 垂直应用架构
• 当访问量逐渐增大,单一应用增加机器带来的加速度越来越小,将应用拆成互不相干的几个应用,以提升效率。
• 此时,用于加速前端页面开发的 Web框架(MVC) 是关键。
• 分布式服务架构
• 当垂直应用越来越多,应用之间交互不可避免,将核心业务抽取出来,作为独立的服务,逐渐形成稳定的服务中心,使前端应用能更快速的响应多变的市场需求。
• 此时,用于提高业务复用及整合的 分布式服务框架(RPC) 是关键。
• 流动计算架构
• 当服务越来越多,容量的评估,小服务资源的浪费等问题逐渐显现,此时需增加一个调度中心基于访问压力实时管理集群容量,提高集群利用率。
• 此时,用于提高机器利用率的 资源调度和治理中心(SOA) 是关键。
需求
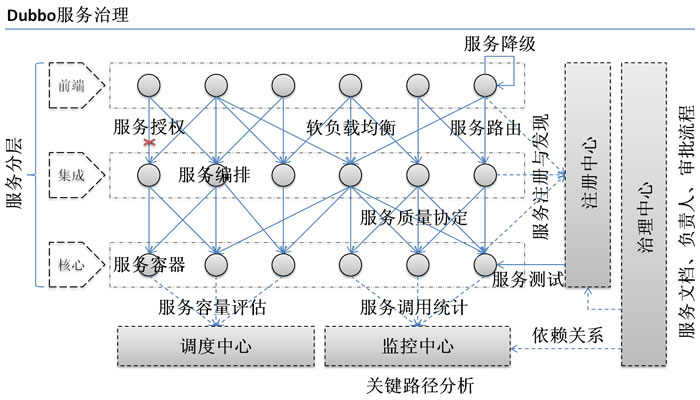
在大规模服务化之前,应用可能只是通过RMI或Hessian等工具,简单的暴露和引用远程服务,通过配置服务的URL地址进行调用,通过F5等硬件进行负载均衡。
(1) 当服务越来越多时,服务URL配置管理变得非常困难,F5硬件负载均衡器的单点压力也越来越大。
此时需要一个服务注册中心,动态的注册和发现服务,使服务的位置透明。
并通过在消费方获取服务提供方地址列表,实现软负载均衡和Failover,降低对F5硬件负载均衡器的依赖,也能减少部分成本。
(2) 当进一步发展,服务间依赖关系变得错踪复杂,甚至分不清哪个应用要在哪个应用之前启动,架构师都不能完整的描述应用的架构关系。
这时,需要自动画出应用间的依赖关系图,以帮助架构师理清理关系。
(3) 接着,服务的调用量越来越大,服务的容量问题就暴露出来,这个服务需要多少机器支撑?什么时候该加机器?
为了解决这些问题,第一步,要将服务现在每天的调用量,响应时间,都统计出来,作为容量规划的参考指标。
其次,要可以动态调整权重,在线上,将某台机器的权重一直加大,并在加大的过程中记录响应时间的变化,直到响应时间到达阀值,记录此时的访问量,再以此访问量乘以机器数反推总容量。
架构
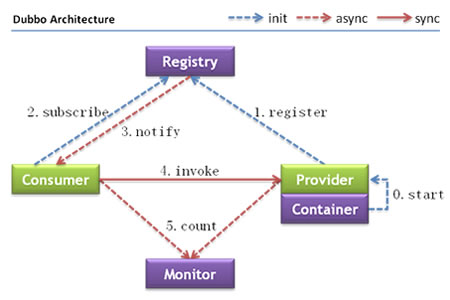
节点角色说明:
• Provider: 暴露服务的服务提供方。
• Consumer: 调用远程服务的服务消费方。
• Registry: 服务注册与发现的注册中心。
• Monitor: 统计服务的调用次调和调用时间的监控中心。
• Container: 服务运行容器。
调用关系说明:
• 0. 服务容器负责启动,加载,运行服务提供者。
• 1. 服务提供者在启动时,向注册中心注册自己提供的服务。
• 2. 服务消费者在启动时,向注册中心订阅自己所需的服务。
• 3. 注册中心返回服务提供者地址列表给消费者,如果有变更,注册中心将基于长连接推送变更数据给消费者。
• 4. 服务消费者,从提供者地址列表中,基于软负载均衡算法,选一台提供者进行调用,如果调用失败,再选另一台调用。
• 5. 服务消费者和提供者,在内存中累计调用次数和调用时间,定时每分钟发送一次统计数据到监控中心。
(1) 连通性:
• 注册中心负责服务地址的注册与查找,相当于目录服务,服务提供者和消费者只在启动时与注册中心交互,注册中心不转发请求,压力较小
• 监控中心负责统计各服务调用次数,调用时间等,统计先在内存汇总后每分钟一次发送到监控中心服务器,并以报表展示
• 服务提供者向注册中心注册其提供的服务,并汇报调用时间到监控中心,此时间不包含网络开销
• 服务消费者向注册中心获取服务提供者地址列表,并根据负载算法直接调用提供者,同时汇报调用时间到监控中心,此时间包含网络开销
• 注册中心,服务提供者,服务消费者三者之间均为长连接,监控中心除外
• 注册中心通过长连接感知服务提供者的存在,服务提供者宕机,注册中心将立即推送事件通知消费者
• 注册中心和监控中心全部宕机,不影响已运行的提供者和消费者,消费者在本地缓存了提供者列表
• 注册中心和监控中心都是可选的,服务消费者可以直连服务提供者
(2) 健状性:
• 监控中心宕掉不影响使用,只是丢失部分采样数据
• 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务
• 注册中心对等集群,任意一台宕掉后,将自动切换到另一台
• 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯
• 服务提供者无状态,任意一台宕掉后,不影响使用
• 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复
(3) 伸缩性:
• 注册中心为对等集群,可动态增加机器部署实例,所有客户端将自动发现新的注册中心
• 服务提供者无状态,可动态增加机器部署实例,注册中心将推送新的服务提供者信息给消费者
(4) 升级性:
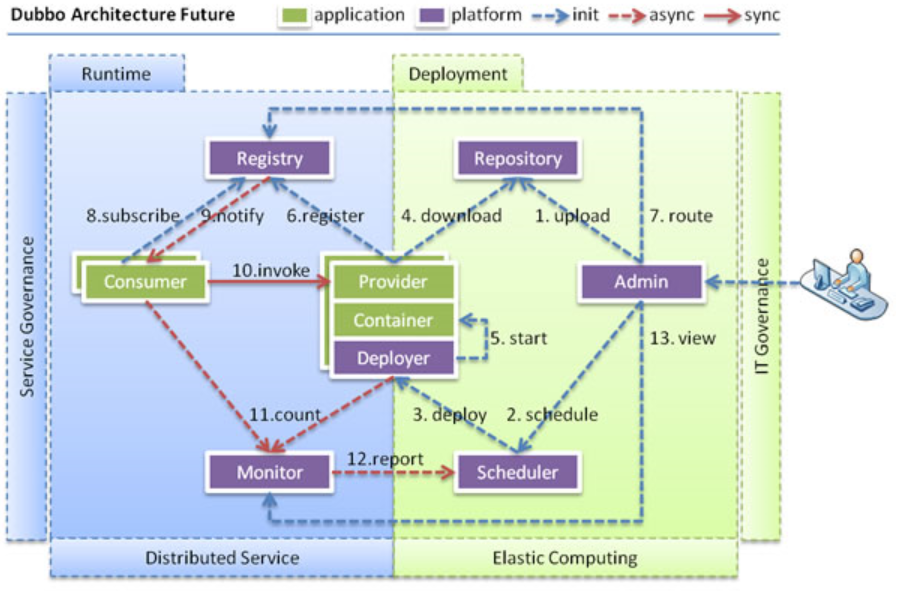
• 当服务集群规模进一步扩大,带动IT治理结构进一步升级,需要实现动态部署,进行流动计算,现有分布式服务架构不会带来阻力:
安装 Dubbo 注册中心(Zookeeper-3.4.6)
zookeeper是一个为分布式应用提供一致性服务的软件,它是开源的Hadoop项目中的一个子项目,并且根据google发表的
1、 修改操作系统的/etc/hosts 文件中添加:
# zookeeper servers
192.168.3.66 edu-provider-01
2、 到 http://apache.fayea.com/zookeeper/下载 zookeeper-3.4.6:
$ wget http://apache.fayea.com/zookeeper/zookeeper-3.4.6/zookeeper-3.4.6.tar.gz
3、 解压 zookeeper 安装包:
$ tar -zxvf zookeeper-3.4.6.tar.gz
4、 在/home/wusc/zookeeper-3.4.6 目录下创建以下目录:
$ cd /home/wusc/zookeeper-3.4.6
$ mkdir data
$ mkdir logs
5、 将 zookeeper-3.4.6/conf 目录下的 zoo_sample.cfg 文件拷贝一份,命名为为zoo.cfg
$ cp zoo_sample.cfg zoo.cfg
6、 修改 zoo.cfg 配置文件:
$ vi zoo.cfg
# The number of milliseconds of each tick
tickTime=2000
# The number of ticks that the initial
# synchronization phase can take
initLimit=10
# The number of ticks that can pass between
# sending a request and getting an acknowledgement
syncLimit=5
# the directory where the snapshot is stored.
# do not use /tmp for storage, /tmp here is just
# example sakes.
dataDir=/home/wusc/zookeeper-3.4.6/data
dataLogDir=/home/wusc/zookeeper-3.4.6/logs
# the port at which the clients will connect
clientPort=2181
#2888,3888 are election port
server.1=edu-provider-01:2888:3888
其中,
2888 端口号是 zookeeper 服务之间通信的端口。
3888 是 zookeeper 与其他应用程序通信的端口。
edu-provider-01 是在 hosts 中已映射了 IP 的主机名。
initLimit:这个配置项是用来配置 Zookeeper 接受客户端(这里所说的客户端不是用户连接 Zookeeper 服务器的客户端,而是 Zookeeper 服务器集群中连接到Leader 的 Follower 服务器)初始化连接时最长能忍受多少个心跳时间间隔数。当已经超过 10 个心跳的时间(也就是 tickTime)长度后 Zookeeper 服务器还没
有收到客户端的返回信息,那么表明这个客户端连接失败。总的时间长度就是5*2000=10 秒。
syncLimit:这个配置项标识 Leader 与 Follower 之间发送消息,请求和应答时间长度,最长不能超过多少个 tickTime 的时间长度,总的时间长度就是 2*2000=4秒。
server.A=B:C:D:其中 A 是一个数字,表示这个是第几号服务器; B 是这个服务器的 IP 地址或/etc/hosts 文件中映射了 IP 的主机名; C 表示的是这个服务器与集群中的 Leader 服务器交换信息的端口; D 表示的是万一集群中的 Leader 服务器挂了,需要一个端口来重新进行选举,选出一个新的 Leader,而这个端口就是用来执行选举时服务器相互通信的端口。如果是伪集群的配置方式,由于 B 都是一样,所以不同的 Zookeeper 实例通信端口号不能一样,所以要给它们分配不同的端口号。
7、 在 dataDir=/home/wusc/zookeeper-3.4.6/data 下创建 myid 文件
编辑 myid 文件,并在对应的 IP 的机器上输入对应的编号。如在 zookeeper 上, myid文件内容就是 1。 如果只在单点上进行安装配置, 那么只有一个 server.1。
$ vi myid
1
8、 wusc 用户下修改 vi /home/wusc/.bash_profile, 增加 zookeeper 配置:
# zookeeper env
export ZOOKEEPER_HOME=/home/wusc/zookeeper-3.4.6
export PATH=$ZOOKEEPER_HOME/bin:$PATH
使配置文件生效
$ source /home/wusc/.bash_profile
9、 在防火墙中打开要用到的端口 2181、 2888、 3888
切换到 root 用户权限,执行以下命令:
# chkconfig iptables on
# service iptables start
编辑/etc/sysconfig/iptables
# vi /etc/sysconfig/iptables
增加以下 3 行:
-A INPUT -m state --state NEW -m tcp -p tcp --dport 2181 -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 2888 -j ACCEPT
-A INPUT -m state --state NEW -m tcp -p tcp --dport 3888 -j ACCEPT
重启防火墙:
# service iptables restart
查看防火墙端口状态:
# service iptables status
10、 启动并测试 zookeeper( 要用 wusc 用户启动,不要用 root) :
(1) 使用 wusc 用户到/home/wusc/zookeeper-3.4.6/bin 目录中执行:
$ zkServer.sh start
(2) 输入 jps 命令查看进程:
$ jps
1456 QuorumPeerMain
1475 Jps
其中, QuorumPeerMain 是 zookeeper 进程,启动正常
(3) 查看状态:
$ zkServer.sh status
(4) 查看 zookeeper 服务输出信息:
由于服务信息输出文件在/home/wusc/zookeeper-3.4.6/bin/zookeeper.out
$ tail -500f zookeeper.out
11、 停止 zookeeper 进程:
$ zkServer.sh stop
12、 配置 zookeeper 开机使用 wusc 用户启动:
编辑/etc/rc.local 文件,加入:
su - wusc -c '/home/wusc/zookeeper-3.4.6/bin/zkServer.sh start'
GitHub地址:https://github.com/leebingbin/










