
序言
sharding-jdbc在分库分表方面提供了很大的便利性,在使用DB的时候,通常都会涉及到事务这个概念,而在分库分表的环境上再加上事务,就会使事情变得复杂起来。本章试图剖析sharding-jdbc在事务方面的解决思路。
传统事务回顾
传统的事务模型如下:
Connection conn = getConnection();
try{
Statement stmt1 = conn.parpareStatement(sql1);
stmt1.executeUpdate();
Statement stmt2 = conn.parpareStatement(sql2);
stmt2.executeUpdate();
conn.commit();
}catch(Exception e){
conn.rollback();
}
对于同一个连接,可以执行多条sql语句,任何一条语句出现错误的时候,整个操作流程都可以回滚,从而达到事务的原子操作。
再来看最基本的spring事务操作:
class ServiceA(){
public void updateA(){...}
}
class ServiceB(){
public void updateB(){...}
}
@Transactional
class ServiceC(){
public void updateC(){
serviceA.updateA();
serviceB.updateB();
}
}
我们知道,当updateC执行的时候,不管是updateA还是updateB出现了异常,updateC都可以整体回滚,达到原子操作的效果,其主要原因是updateA和updateB共享了同一个Connection,这是spring底层通过ThreadLocal缓存了Connection实现的。
以上介绍的这两种情况都只是针对单库单表的原子操作,事务的实现并不难理解,那么在跨库的情况下,sharding-jdbc又是如何解决事务问题的呢?
shrading-jdbc之弱事务
在官方文档中,针对弱事务有如下三点说明:
- 完全支持非跨库事务,例如:仅分表,或分库但是路由的结果在单库中。
- 完全支持因逻辑异常导致的跨库事务。例如:同一事务中,跨两个库更新。更新完毕后,抛出空指针,则两个库的内容都能回滚。
- 不支持因网络、硬件异常导致的跨库事务。例如:同一事务中,跨两个库更新,更新完毕后、未提交之前,第一个库死机,则只有第二个库数据提交。
为了理解以上几点,我们来看看sharding-jdbc默认是如何处理事务的。

这是一个非常常见的处理模式,一个总连接处理了多条sql语句,最后一次性提交整个事务,每一条sql语句可能会分为多条子sql分库分表去执行,这意味着底层可能会关联多个真正的数据库连接,我们先来看看如果一切正常,commit会如何去处理。
public abstract class AbstractConnectionAdapter extends AbstractUnsupportedOperationConnection {
@Override
public final void commit() throws SQLException {
Collection<SQLException> exceptions = new LinkedList<>();
for (Connection each : cachedConnections.values()) {
try {
each.commit();
} catch (final SQLException ex) {
exceptions.add(ex);
}
}
throwSQLExceptionIfNecessary(exceptions);
}
}
引擎会遍历底层所有真正的数据库连接,一个个进行commit操作,如果任何一个出现了异常,直接捕获异常,但是也只是捕获而已,然后接着下一个连接的commit,这也就很好的说明了,如果在执行任何一条sql语句出现了异常,整个操作是可以原子性回滚的,因为此时所有连接都不会执行commit,但如果已经到了commit这一步的话,如果有连接commit失败了,是不会影响到其他连接的。
sharding-jdbc之柔性事务
sharding-jdbc的弱事务并不是完美的,有时可能会导致数据的一致性问题,所以针对某些特定的场景,又提出了柔性事务的概念。先来看一张官方的说明图:
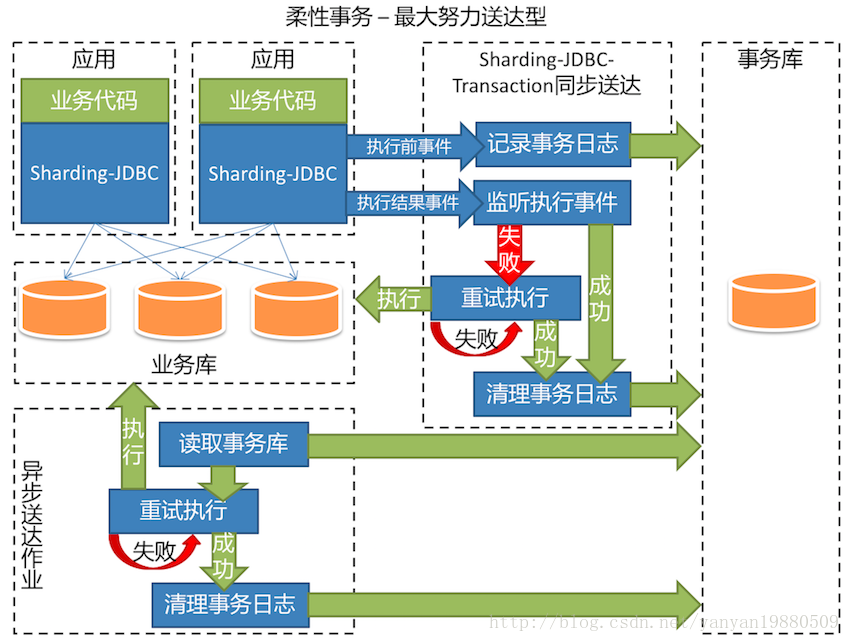
这里想表达两个意思:
1. 对于sql的执行,在执行前记录日志,如果执行成功,把日志删除,如果执行失败,重试一定次数(如果未达到最大尝试次数便执行成功了,一样删除日志)。
2. 异步任务不断扫描执行日志,如果重试次数未达到最大上限,尝试重新执行,如果执行成功,删除日志。
从上面两点分析可以看出,由于采用的是重试的模式,也就是说同一条语句,是有可能被多次执行的,所以官方提到了柔性事务的适用场景:
- 根据主键删除数据。
- 更新记录永久状态,如更新通知送达状态。
而且它还有一定的限制: SQL需要满足幂等性,具体为:
- INSERT语句要求必须包含主键,且不能是自增主键。
- UPDATE语句要求幂等,不能是UPDATE xxx SET x=x+1
- DELETE语句无要求。
在有了一个大概的了解之后,我们来更加深入的了解。
sharding-jdbc使用了google的EventBus事件模型,注册了一个Listener,监听器对三种事件进行了处理,如下代码所示:
switch (event.getEventExecutionType()) {
case BEFORE_EXECUTE:
transactionLogStorage.add(new TransactionLog(event.getId(), bedSoftTransaction.getTransactionId(), bedSoftTransaction.getTransactionType(),
event.getDataSource(), event.getSql(), event.getParameters(), System.currentTimeMillis(), 0));
return;
case EXECUTE_SUCCESS:
transactionLogStorage.remove(event.getId());
return;
case EXECUTE_FAILURE:
boolean deliverySuccess = false;
for (int i = 0; i < transactionConfig.getSyncMaxDeliveryTryTimes(); i++) {
if (deliverySuccess) {
return;
}
boolean isNewConnection = false;
Connection conn = null;
PreparedStatement preparedStatement = null;
try {
conn = bedSoftTransaction.getConnection().getConnection(event.getDataSource(), SQLType.DML);
if (!isValidConnection(conn)) {
bedSoftTransaction.getConnection().release(conn);
conn = bedSoftTransaction.getConnection().getConnection(event.getDataSource(), SQLType.DML);
isNewConnection = true;
}
preparedStatement = conn.prepareStatement(event.getSql());
//TODO for batch event need split to 2-level records
for (int parameterIndex = 0; parameterIndex < event.getParameters().size(); parameterIndex++) {
preparedStatement.setObject(parameterIndex + 1, event.getParameters().get(parameterIndex));
}
preparedStatement.executeUpdate();
deliverySuccess = true;
transactionLogStorage.remove(event.getId());
} catch (final SQLException ex) {
log.error(String.format("Delivery times %s error, max try times is %s", i + 1, transactionConfig.getSyncMaxDeliveryTryTimes()), ex);
} finally {
close(isNewConnection, conn, preparedStatement);
}
}
return;
default:
throw new UnsupportedOperationException(event.getEventExecutionType().toString());
}
以上代码可以抽取为如下图的描述:
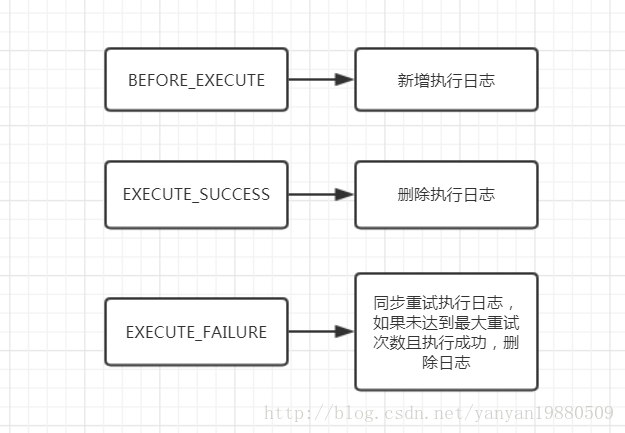
监听器根据三种不同的事件类型对事务日志进行不同的操作。有监听 ,必然就有事件的投递,那么引擎是什么时候产生这些事件的呢?
我们知道每一条sql语句拆分后有可能对应多条子sql语句,而每一条子sql语句是单独执行的,执行是封装在一个内部方法的:
private <T> T executeInternal(final SQLType sqlType, final BaseStatementUnit baseStatementUnit, final List<List<Object>> parameterSets, final ExecuteCallback<T> executeCallback,
final boolean isExceptionThrown, final Map<String, Object> dataMap) throws Exception {
synchronized (baseStatementUnit.getStatement().getConnection()) {
T result;
ExecutorExceptionHandler.setExceptionThrown(isExceptionThrown);
ExecutorDataMap.setDataMap(dataMap);
List<AbstractExecutionEvent> events = new LinkedList<>();
if (parameterSets.isEmpty()) {
events.add(getExecutionEvent(sqlType, baseStatementUnit, Collections.emptyList()));
}
for (List<Object> each : parameterSets) {
events.add(getExecutionEvent(sqlType, baseStatementUnit, each));
}
for (AbstractExecutionEvent event : events) {
EventBusInstance.getInstance().post(event);
}
try {
result = executeCallback.execute(baseStatementUnit);
} catch (final SQLException ex) {
for (AbstractExecutionEvent each : events) {
each.setEventExecutionType(EventExecutionType.EXECUTE_FAILURE);
each.setException(Optional.of(ex));
EventBusInstance.getInstance().post(each);
ExecutorExceptionHandler.handleException(ex);
}
return null;
}
for (AbstractExecutionEvent each : events) {
each.setEventExecutionType(EventExecutionType.EXECUTE_SUCCESS);
EventBusInstance.getInstance().post(each);
}
return result;
}
}
以上代码可以简化为如下流程:
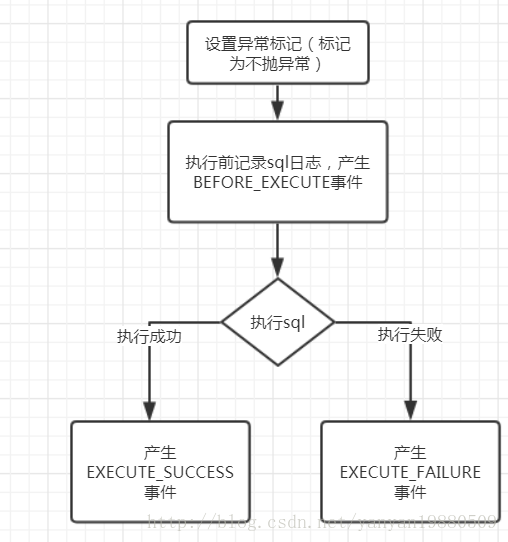
其实执行流程比较简单,但还有两个重要的细节这里没有体现:
当使用柔性事务的时候,需要创建事务管理器,并获取事务对象,调用事务对象的begin开始一个事务,在这一步,会强制设置连接的autoCommit=true,这会导致所有的sql语句执时后立即提交,想想如果能回滚,那柔性事务也就失去了意义。
当事务执行begin时,会标记当前不抛出异常,这样当执行sql语句有异常时,会生成相应的EXECUTE_FAILURE事件,从而进行事务日志处理,而不是往外抛出异常,当事务结束时,调用事务对象的end方法,恢复异常的捕获。
一个常见的代码编写模式如下(来自官方的demo)
private static void updateFailure(final DataSource dataSource) throws SQLException {
String sql1 = "UPDATE t_order SET status='UPDATE_1' WHERE user_id=10 AND order_id=1000";
String sql2 = "UPDATE t_order SET not_existed_column=1 WHERE user_id=1 AND order_id=?";
String sql3 = "UPDATE t_order SET status='UPDATE_2' WHERE user_id=10 AND order_id=1000";
SoftTransactionManager transactionManager = new SoftTransactionManager(getSoftTransactionConfiguration(dataSource));
transactionManager.init();
BEDSoftTransaction transaction = (BEDSoftTransaction) transactionManager.getTransaction(SoftTransactionType.BestEffortsDelivery);
Connection conn = null;
try {
conn = dataSource.getConnection();
transaction.begin(conn);
PreparedStatement preparedStatement1 = conn.prepareStatement(sql1);
PreparedStatement preparedStatement2 = conn.prepareStatement(sql2);
preparedStatement2.setObject(1, 1000);
PreparedStatement preparedStatement3 = conn.prepareStatement(sql3);
preparedStatement1.executeUpdate();
preparedStatement2.executeUpdate();
preparedStatement3.executeUpdate();
} finally {
transaction.end();
if (conn != null) {
conn.close();
}
}
}
看到这个编写模式,你一定会想,如果我使用MyBatis和spring,这一切能否整合起来,这个话题有兴趣大家可以去尝试。
总结
分布式事务处理起来有一定的难度,sharding-jdbc采用了简单的弱事务模式和特殊场景下的柔性事务模式,没有最好,只有更好,根据自身业务去选择事务模式才是最重要的。












