
大家好,又到了Python办公自动化系列。
今天我们来讲解一个比较简单的案例,使用openpyxl从Excel中提取指定的数据并生成新的文件,之后进一步批量自动化实现这个功能,通过本例可以学到的知识点:
openpyxl模块的运用glob模块建立批处理
数据源:阿里云天池的电商婴儿数据(可自行搜索并下载,如果要完成进阶难度可直接将该数据Excel拷贝999次即可,当然这个拷贝可以交给代码来实现)
需求说明
初级难度:提取电商婴儿数据.xlsx中购买数buy_mount超过50的记录建立新的Excel表
最后形成如下的表格:
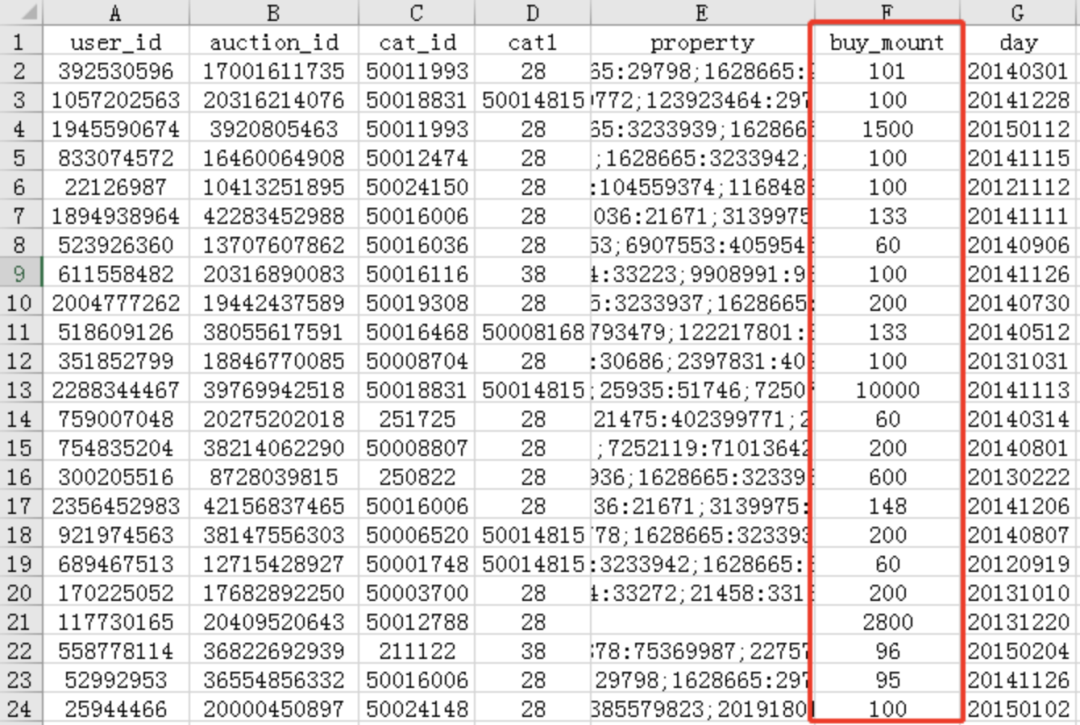
进阶难度:同一个文件夹下有1000份电商婴儿数据的Excel表格(命名为电商婴儿数据1.xlsx,电商婴儿数据2.xlsx至电商婴儿数据1000.xlsx),需要提取所有表格中购买数buy_mount超过50的记录并汇总至一个新的Excel表
Python实现
让我们先完成初级难度的需求挑战,首先导入所需模块并打开数据表,注意
打开已经存在的Excel用`load_workbook`,创建新的Excel用`Workbook`from openpyxl import load_workbook, Workbook
# 数据所在的文件夹目录
path = 'C:/Users/xxxxxx'
# 打开电商婴儿数据工作簿
workbook = load_workbook(path + '/' + '电商婴儿数据.xlsx')
# 打开工作表
sheet = workbook.active接下来筛选符合条件的行
buy_mount = sheet['F']
row_lst = []
for cell in buy_mount:
if isinstance(cell.value, int) and cell.value > 50:
print(cell.row)
row_lst.append(cell.row)这一步本质上就是对购买数的各个单元格进行判断,如果数值超过50就将其行号放入一个空列表中,间接完成了筛出符合条件的行。注意这一列有可能有的单元格cell的值value不是数值类型,因此需要用isinstance()进行判断,当然也可以将单元格的值先用int()转为整型再判断。
筛选出符合条件的行号就可以提取行并且放入新的Excel中了,因此需要先创建新的工作簿,现在创建新的工作簿写入符合条件的行,思路是根据行号获取到指定行后,遍历所有单元格的值组装成一个列表,用sheet.append()写入新表
new_workbook = Workbook()
new_sheet = new_workbook.active
# 创建和 电商婴儿数据 一样的表头(第一行)
header = sheet[1]
header_lst = []
for cell in header:
header_lst.append(cell.value)
new_sheet.append(header_lst)
# 从旧表中根据行号提取符合条件的行,并遍历单元格获取值,以列表形式写入新表
for row in row_lst:
data_lst = []
for cell in sheet[row]:
data_lst.append(cell.value)
new_sheet.append(data_lst)
# 最后切记保存
new_workbook.save(path + '/' + '符合筛选条件的新表.xlsx')初级难度的需求已经成功完成,至此我们已经学会从单个表中提取需要的行并且放到新的表格里。有的人可能会说了:一个表格的筛选可以直接用Excel中的 筛选 来完成,不需要用代码写这么复杂,还难以理解。因此就有了进阶需求。现在需要完成的工作变成,获取1000个表格中所有符合条件的行并汇总成一个新表。如果是手动操作的行,需要打开每个表格,然后一通筛选操作后,将所有满足条件的行都复制到新表,并且执行上述操作1000次!
这显然不现实,而如果你已经理解初级需求的思路,那么只需要加上几行代码,就可以完成进阶需求。所需要的模块是glob。批处理的大概代码框架如下:
import glob
# 1000份数据所在的文件夹目录
path = 'C:/Users/xxxxxx'
for file in glob.glob(path + '/*'):
pass如果需要遍历特定类型的文件可以限定后缀,以xlsx后缀的Excel文件为例
for file in glob.glob(path + '/*.xlsx'):
pass最后只需要将上面写好的针对单个文件的代码放到循环体内部,且load_workbook的路径变成循环出的每一个xlsx文件的绝对路径。当然,还需要想清楚有些代码不能在循环体里重复被执行,如创建新表和给新表添加表头,创建新表放在循环体外就可以,添加表头可以用一个单独的变量来判断这个操作是否已经被执行。完整代码如下:
from openpyxl import load_workbook, Workbook
import glob
path = 'C:/Users/xxxxxx'
new_workbook = Workbook()
new_sheet = new_workbook.active
# 用flag变量明确新表是否已经添加了表头,只要添加过一次就无须重复再添加
flag = 0
for file in glob.glob(path + '/*.xlsx'):
workbook = load_workbook(file)
sheet = workbook.active
buy_mount = sheet['F']
row_lst = []
for cell in buy_mount:
if isinstance(cell.value, int) and cell.value > 50:
print(cell.row)
row_lst.append(cell.row)
if not flag:
header = sheet[1]
header_lst = []
for cell in header:
header_lst.append(cell.value)
new_sheet.append(header_lst)
flag = 1
for row in row_lst:
data_lst = []
for cell in sheet[row]:
data_lst.append(cell.value)
new_sheet.append(data_lst)
new_workbook.save(path + '/' + '符合筛选条件的新表.xlsx')小结
以上就是使用Python实现批量从Excel中提取指定数据的全部过程和代码,如果你也有相关需求,稍作修改即可使用。其实如果你仔细思考会发现这个需求使用pandas会以更简洁的代码实现,但是由于我们之后的Python办公自动化案例中会频繁使用openpyxl,并且在操作Excel时有更多的功能,因此在之后我们将主要讲解如何使用这个openpyxl实现。最后还是希望大家能够理解Python办公自动化的一个核心就是批量操作-解放双手,让复杂的工作自动化!
**-----**------**-----**---**** End **-----**--------**-----**-****

往期精彩文章推荐:

欢迎各位大佬点击链接加入群聊【helloworld开发者社区】:https://jq.qq.com/?_wv=1027&k=mBlk6nzX进群交流IT技术热点。
本文转自 https://mp.weixin.qq.com/s/e5AyfkQjBom8jea00o3VYA,如有侵权,请联系删除。











