
React Hooks几乎在所有方面都能让我们在编程中获得好处。但是某些时候的性能问题,也需要使用一些技巧来解决。我们可以使用Hooks编写快速的应用程序,但是在动手之前需要注意一两件事。
应该使用缓存记忆吗?
在大多数情况下,React速度非常快。如果您的应用程序足够快并且没有任何性能问题,那么本文不适合您。解决"虚幻"的性能问题是一件实用的事情,在开始优化之前,请先熟悉React Profiler。
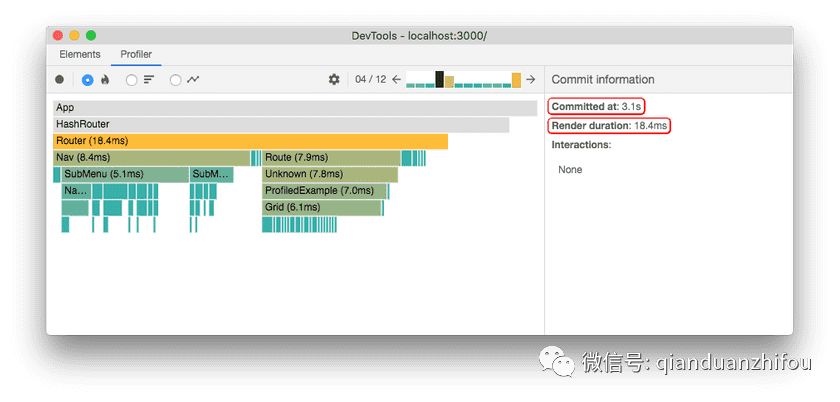
如果您确定了渲染速度较慢的场景,那么使用缓存记忆可能是最好的选择。
React.memo是一个性能优化工具,也是一个高级组件。它类似于React.PureComponent,但用于函数组件而不是类。如果您的函数组件在相同的Props属性下呈现相同的结果,React将会使用缓存,跳过这次渲染,并重用最后一次渲染的结果。
默认情况下,它将仅对props对象中的复杂对象进行浅层比较。如果要控制比较,还可以提供自定义比较功能作为第二个参数。
不使用缓存记忆
让我们看一个不使用缓存记忆的示例,和理解为什么这会导致性能问题。
function List({ items }) {
每次单击inc时,即使List的内容没有变化,renderApp和renderList也都会被打印输出。如果组件节点树足够大,则很容易成为性能瓶颈。我们需要减少渲染数量。
简单的缓存记忆
const List = React.memo(({ items }) => {
在此示例中,缓存记忆可以正常工作并减少渲染数量。在挂载期间,将打印输出renderApp和renderList,但单击inc时,仅输出renderApp。
记忆 & 回调函数
让我们进行一些小的修改,然后将inc按钮添加到所有列表项。需要注意的是,将回调函数传递给已记忆的组件可能会导致细微的错误。
function App() {
在这个例子中,记忆将会失败。由于我们使用的是内联函数参数,因此会为每次渲染都会创建新的引用,从而使React.memo毫无用处。在记忆组件之前,我们需要一种记忆函数本身的方法。
useCallback
幸运的是,React为此有两个内置的钩子:useMemo和useCallback。useMemo用于昂贵的计算,useCallback用于传递优化的子组件所需的回调。
function App() {
在这个例子中,记忆再次失败。每次按inc时都会调用renderList。useCallback的默认行为是在传递新的函数实例时计算新值。由于内联lambda在每次渲染期间都会创建新实例,因此具有默认配置的useCallback在这里没有用。
useCallback & 输入
const inc = useCallback(() => setCount(count + 1), [count]);
useCallback接受第二个参数,即输入数组,并且仅当这些输入参数更改时,useCallback才会返回新值。在此示例中,每次count更改时,useCallback将返回新的引用。由于计数在每次渲染期间都会更改,因此useCallback将在每个渲染期间返回新值。所以此代码也不会缓存记忆。
useCallback & 输入空数组
const inc = useCallback(() => setCount(count + 1), []);
useCallback可以将一个空数组作为输入,该数组将仅调用一次内部lambda并记住该引用以供将来调用。这段代码确实说明了一点,单击任何按钮时将调用一个renderApp,主inc按钮正常工作,而内部inc按钮运行失败。
计数器将从0递增到1,此后将停止。Lambda创建一次,但是被多次调用。由于创建lambda时count为0,所以创建之后,就与以下代码完全相同:
const inc = useCallback(() => setCount(1), []);
问题的根本原因在于,我们试图同时读写状态。幸运的是,React提供了两种解决问题的方法:
具有函数更新参数的useState
const inc = useCallback(() => setCount(c => c + 1), []);
useState返回的setter可以将function用作参数,您可以在其中读取给定状态的先前值。在此示例中,缓存记忆正确运行,没有任何错误。
useReducer
const [count, dispatch] = useReducer(c => c + 1, 0);
在这种情况下,useReducer缓存记忆与useState完全一样。由于保证了dispatch在渲染之间具有相同的引用,因此不需要useCallback,这使代码更容易减少了与缓存记忆相关的错误。
useReducer vs useState
useReducer更适用于管理包含多个子组件值的状态对象,或者下一个状态取决于前一个值时。使用useReducer的常见模式是与useContext一起使用,以避免在大型组件树中显式传递回调。
我建议的经验法则是,对于只在组件内部使用的数据,主要使用useState;对于需要在父级和子级之间进行双向数据交换,则useReducer是一个更好的选择。
最后
做一个形象的概括:React.memo和useReducer是最好的朋友,React.memo和useState是有时会产生冲突并引起问题的兄弟姐妹,useCallback则是您应该始终谨慎的隔壁邻居。
本文分享自微信公众号 - 前端知否(qianduanzhifou)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。














