
作者:Hemant Dangi 译:徐轶韬
MySQL 8.0.19引入了无Binlog副本(保留事务提交顺序),这意味着用户可以在不启用二进制日志的情况下部署异步副本,并保留相同的顺序提交事务。用户可以禁用Binlog(skip-log-bin)和回放线程产生的日志(log-slave-updates = FALSE)进行的更改,同时保留相同提交顺序(slave-preserve-commit-order = TRUE)。
对于基于writeset的依赖跟踪来实现事务并行化的用户来说,保持提交顺序是非常有用的。因此,用户现在可以在没有二进制日志的副本上,同时使用并行工作线程和WRITESET来提高回放线程的吞吐量,同时在副本上导出相同的事务提交顺序(与在输入复制流中观察到的一致)。
在深入探讨细节之前,让我介绍一些有关Slave Preserve Commit Order(SPCO)的背景知识。已经熟悉“Slave Preserve Commit Order”概念的读者可以跳过下一部分。
Slave Preserve Commit Order
对于多线程从服务器(slave_parallel_workers> 1),启用slave_preserve_commit_order变量可确保_事务在从服务器上的外部化顺序与从服务器的中继日志中出现的顺序相同,并在从服务器上与主服务器上保留相同的事务历史记录_。事务可以并行执行,但是执行线程需要按序等待,直到所有先前的事务都提交后再提交。
例
假设我们有两个事务T1和T2,并且我们假设T1在中继日志中出现在T2之前。事务T1和T2可以开始并行执行,但是执行线程将在提交之前等待,直到所有先前的事务都提交为止。

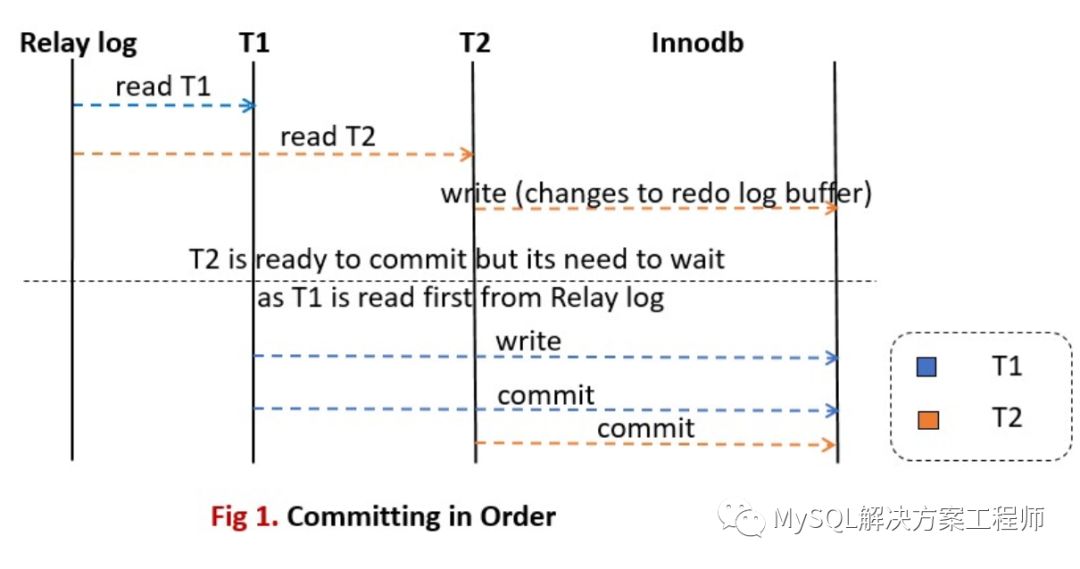
事务T2可以在T1之前执行,但是由于T1在中继日志中的T2之前,并且还启用了slave_preserve_commit_order,因此它将必须在T1之后提交。
从服务器保留提交顺序功能使每个事务在提交之前都等待先前的事务提交,无论其是否有无binlog副本,其工作方式都相同。在下一节中,将深入了解实现并检查性能影响方面的一些基准测试结果。
从服务器保留提交顺序(无Binlog副本)
在MySQL 5.6中,增加了二进制日志组提交功能,以提高多线程(MTS)从服务器的性能,方法是减少对磁盘的写入和刷新次数。无Binlog副本的从服务器保留提交顺序使用二进制日志组提交的刷新阶段。关于二进制日志组提交,您可以在WL#5223上阅读其详细信息,其中包括其他与二进制日志相关的阶段(同步和提交)。将记录写入并刷新到磁盘的刷新阶段是一项开销昂贵的操作,为了提高性能,将多个从服务器线程的记录按组进行刷新。
性能
为了评估在无Binlog副本上从服务器保留提交顺序的好处,让我们看一下基准测试的结果,我们将其与MySQL 8.0.19的启用Binlog的副本进行持久设置来比较。使用以下mysql配置执行基准测试:
- 主机:所有主服务器,与以下设置中使用的binlog ON/OFF无关:
- –binlog-transaction-dependency-tracking= COMMIT_ORDER –innodb_flush_log_at_trx_commit=2 –sync_binlog=0
- 无Binlog副本
- –slave-parallel-workers=128 –slave-parallel-type=LOGICAL_CLOCK –slave-preserve-commit-order=ON –innodb_flush_log_at_trx_commit=1 –sync_binlog=0 –disable-log-bin
- Binlog副本
- –slave-parallel-workers=128 –slave-parallel-type=LOGICAL_CLOCK –log_bin=mysql-bin.log –log_slave_updates=ON –slave-preserve-commit-order=ON –innodb_flush_log_at_trx_commit=1 –sync_binlog=1
- 以下系统变量配置对于用于性能运行的所有mysql服务器是通用的:
- –gtid-mode=ON –enforce_gtid_consistency –log_slave_updates –innodb_buffer_pool_instances=45 –innodb_buffer_pool_size=92160M –innodb_doublewrite=0 –innodb_io_capacity=4000 –innodb_log_files_in_group=4 –innodb_log_file_size=1024M –innodb_open_files=10000 –innodb_read_io_threads=32 –innodb_thread_concurrency=64 –innodb_undo_log_truncate=OFF –innodb_undo_tablespaces=3 –innodb_write_io_threads=32 –loose-information_schema_stats=latest –max_connections=2050 –max_prepared_stmt_count=1048576 –sort_buffer_size=327680 –sql_mode=NO_ENGINE_SUBSTITUTION –table_open_cache=8000
- 上面没有提到的所有mysql系统变量都使用默认值。
基准测试是在一台具有两个Intel Xeon CPU E5-2660 v3处理器(20核,40 h / w线程)和256GB RAM的计算机上执行的。在复制副本上的回放线程(sql_thread)停止的情况下,将工作负载应用于主服务器,当所有数据都加载到副本服务器的中继日志中时,仅启动回放线程(sql_thread)。下图是在主服务器上执行两个Sysbench工作负载后获得的。
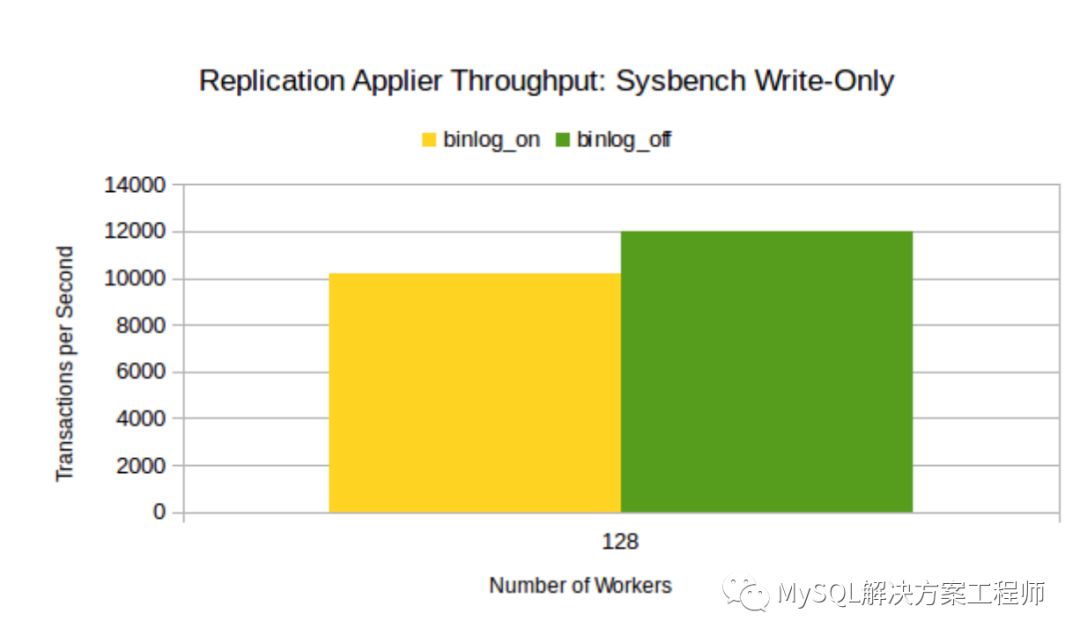
OLTP Write-only 其中每个事务由一个OLTP索引更新,一个OLTP非索引更新,一个OLTP 插入删除更新构成。使用主服务器上的1024个客户端线程来应用750万个事务。为128个从服务器并行工作线程计算适当的吞吐量(事务/秒),如下图所示:
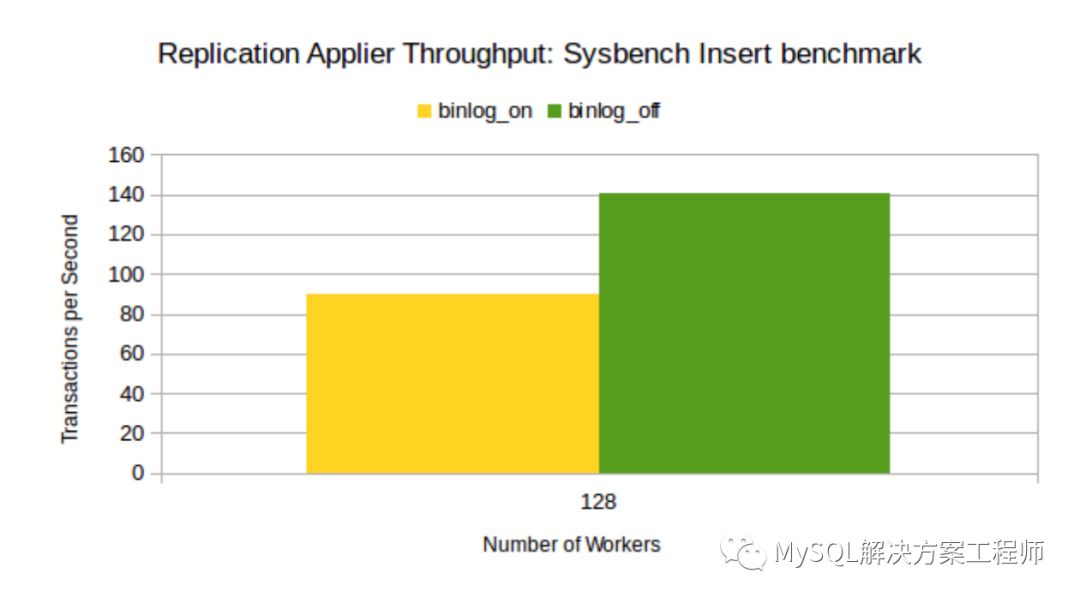
OLTP Insert benchmark 其使用10的客户端线程每个线程在主服务器上执行事务包括1024插入查询。78,000个事务已应用于主服务器。为128个从服务器并行工作线程计算适当的吞吐量(事务/秒),如下图所示:
结论
无Binlog副本的从服务器保留提交顺序增强了MySQL复制在以下方面:
节省副本的磁盘空间,否则副本将用于二进制日志记录。
与启用了binlog的副本相比,如上图所示,提高副本上二进制日志回放线程的吞吐量。
自由使用WRITESET并行化(–binlog_transaction_dependency_tracking = WRITESET | WRITESET_SESSION)来提高从服务器上二进制日志回放线程的吞吐量。
感谢您关注MySQL!
本文分享自微信公众号 - MySQL解决方案工程师(mysqlse)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。













