
阅读指南
文章目录
- 1.事务四大特性
- 2.数据库隔离级别
- 3.MYSQL的两种存储引擎区别(事务、锁级别等等),各自的适用场景
- 4.索引有B+索引和hash索引
- 5.聚集索引和非聚集索引
- 6.索引的优缺点,什么时候使用索引,什么时候不能使用索引
- 7.InnoDB索引和MyISAM索引的区别
- 8.索引的底层实现(B+树,为何不采用红黑树,B树)重点
- 9.B+树的实现
- 10.为什么使用B+Tree
- 11.Sql的优化
- 12.索引最左前缀问题
- 13.索引分类,索引失效条件
- 14.数据库的主从复制
- 15.long_query怎么解决
- 16.varchar和char的使用场景
- 17.数据库连接池的作用
- 19.分库分表,主从复制,读写分离
- 20.数据库三范式
- 21.关系型数据库和非关系型数据库区别
- 22.数据库中join的left join , inner join, cross join
- 23.有哪些锁,select时怎么加排它锁
- 24.死锁怎么解决
- 25.最左匹配原则
1.事务四大特性
原子性,要么执行,要么不执行
隔离性,所有操作全部执行完以前其它会话不能看到过程
一致性,事务前后,数据总额一致
持久性,一旦事务提交,对数据的改变就是永久的 2.数据库隔离级别
多个事务读可能会道理以下问题
脏读:事务B读取事务A还没有提交的数据
不可重复读:,一行被检索两次,并且该行中的值在不同的读取之间不同时
幻读:当在事务处理过程中执行两个相同的查询,并且第二个查询返回的行集合与第一个查询不同时
这两个区别在于,不可重复读重点在一行,幻读的重点 ,返回 的集合不一样
示例图,Id =1这一行
幻读,返回的集合不一样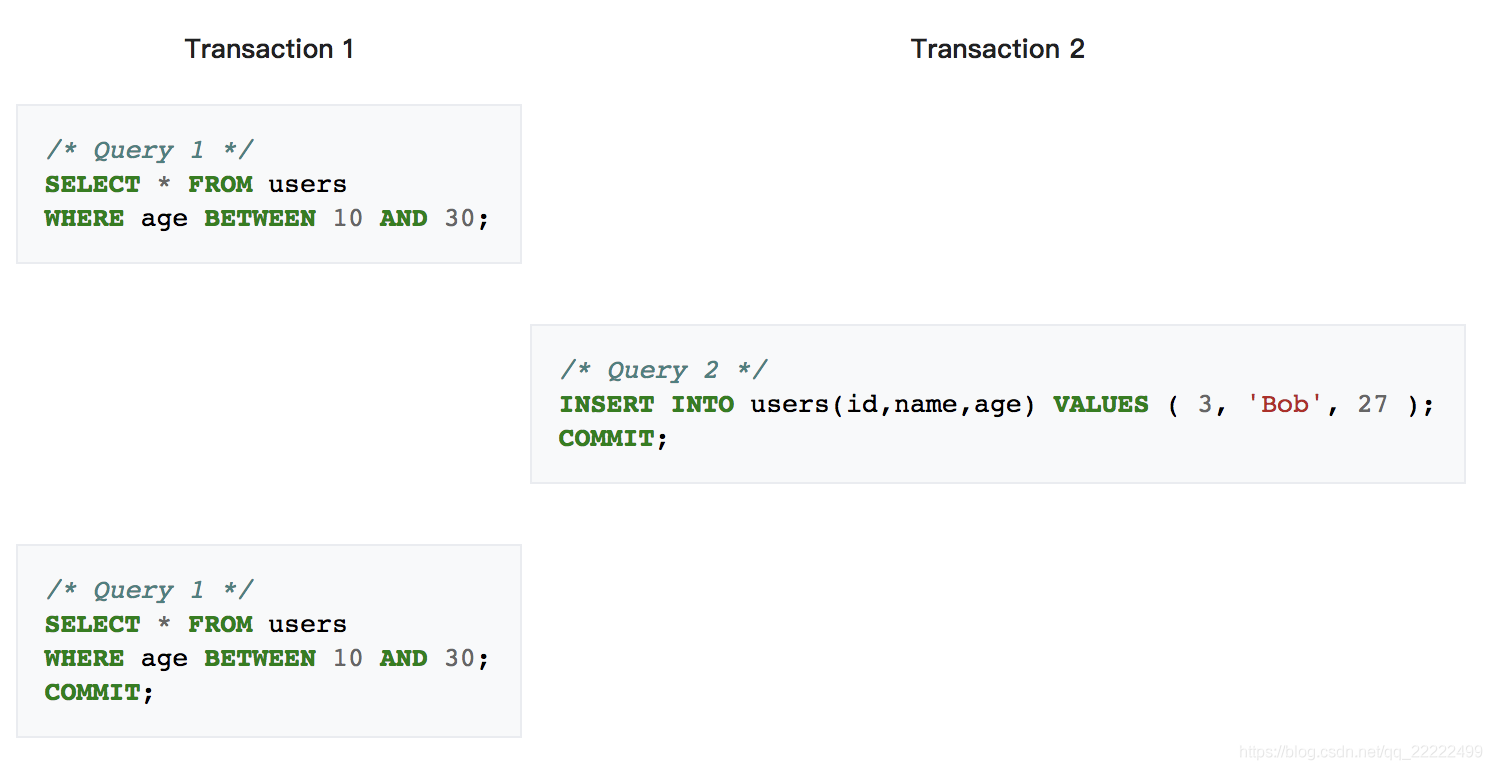
隔离级别总结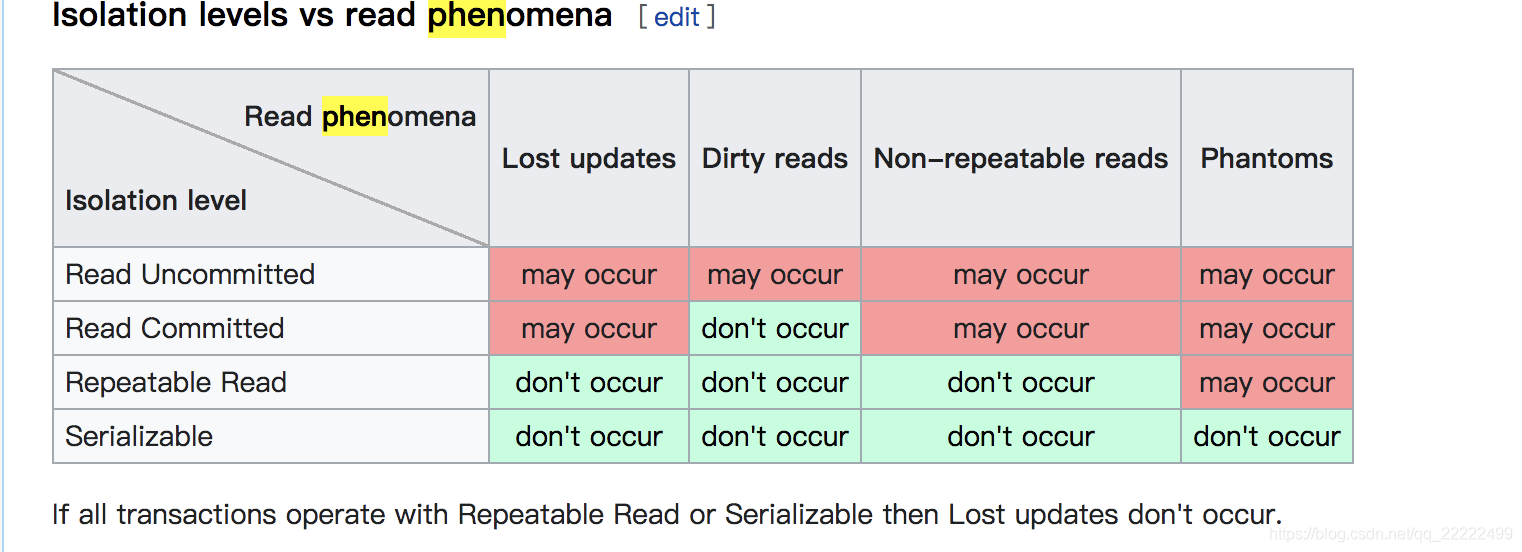
3.MYSQL的两种存储引擎区别(事务、锁级别等等),各自的适用场景
| 引擎 | 特性 |
|---|---|
| MYISAM | 不支持外键,表锁,插入数据时,锁定整个表,查表总行数时,不需要全表扫描 |
| INNODB | 支持外键,行锁,查表总行数时,全表扫描 |
4.索引有B+索引和hash索引
| 索引 | 区别 |
|---|---|
| Hash | hash索引,等值查询效率高,不能排序,不能进行范围查询 |
| B+ | 数据有序,范围查询 |
5.聚集索引和非聚集索引
| 索引 | 区别 |
|---|---|
| 聚集索引 | 数据按索引顺序存储,中子结点存储真实的物理数据 |
| 非聚集索引 | 存储指向真正数据行的指针 |
6.索引的优缺点,什么时候使用索引,什么时候不能使用索引
索引最大的好处是提高查询速度,
缺点是更新数据时效率低,因为要同时更新索引
对数据进行频繁查询进建立索引,如果要频繁更改数据不建议使用索引。 7.InnoDB索引和MyISAM索引的区别
一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主 8.索引的底层实现(B+树,为何不采用红黑树,B树)重点
| 树 | 区别 |
|---|---|
| 红黑树 | 增加,删除,红黑树会进行频繁的调整,来保证红黑树的性质,浪费时间 |
| B树也就是B-树 | B树,查询性能不稳定,查询结果高度不致,每个结点保存指向真实数据的指针,相比B+树每一层每屋存储的元素更多,显得更高一点。 |
| B+树 | B+树相比较于另外两种树,显得更矮更宽,查询层次更浅 |
9.B+树的实现
一个m阶的B+树具有如下几个特征:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只用来索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素 10.为什么使用B+Tree
索引查找过程中就要产生磁盘I/O消耗,主要看IO次数,和磁盘存取原理有关。
根据B-Tree的定义,可知检索一次最多需要访问h个节点。数据库系统的设计者巧妙利用了磁盘预读原理,
将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入
局部性原理与磁盘预读 11.Sql的优化
1.sql尽量使用索引,而且查询要走索引
2.对sql语句优化
子查询变成left join
limit 分布优化,先利用ID定位,再分页
or条件优化,多个or条件可以用union all对结果进行合并(union all结果可能重复)
不必要的排序
where代替having,having 检索完所有记录,才进行过滤
避免嵌套查询
对多个字段进行等值查询时,联合索引 12.索引最左前缀问题
如果对三个字段建立联合索引,如果第二个字段没有使用索引,第三个字段也使用不到索引了 13.索引分类,索引失效条件
| 索引类型 | 概念 |
|---|---|
| 普通索引 | 最基本的索引,没有任何限制 |
| 唯一索引 | 与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。 |
| 主键索引 | 它是一种特殊的唯一索引,不允许有空值。 |
| 全文索引 | 针对较大的数据,生成全文索引很耗时好空间。 |
| 组合索引 | 为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则 |
失效条件
条件是or,如果还想让or条件生效,给or每个字段加个索引
like查询,以%开发
内部函数
对索引列进行计算
is null不会用,is not null 会用 14.数据库的主从复制
| 复制方式 | 操作 |
|---|---|
| 异步复制 | 默认异步复制,容易造成主库数据和从库不一致,一个数据库为Master,一个数据库为slave,通过Binlog日志,slave两个线程,一个线程去读master binlog日志,写到自己的中继日志一个线程解析日志,执行sql,master启动一个线程,给slave传递binlog日志 |
| 半同步复制 | 只有把master发送的binlog日志写到slave的中继日志,这时主库,才返回操作完成的反馈,性能有一定降低 |
| 并行操作 | slave 多个线程去请求binlog日志 |
15.long_query怎么解决
设置参数,开启慢日志功能,得到耗时超过一定时间的sql 16.varchar和char的使用场景
| 类型 | 使用场景 |
|---|---|
| varchar | 字符长度经常变的 |
| char | 用字符长度固定的 |
17.数据库连接池的作用
维护一定数量的连接,减少创建连接的时间
更快的响应时间
统一的管理 19.分库分表,主从复制,读写分离
读写分离,读从库,写主库
spring配置两个数据库,通过AOP(面向切面编程),在写或读方法前面进行判断得到动态切换数据源。 20.数据库三范式
| 级别 | 概念 |
|---|---|
| 1NF | 属性不可分 |
| 2NF | 非主键属性,完全依赖于主键属性 |
| 3NF | 非主键属性无传递依赖 |
21.关系型数据库和非关系型数据库区别
关系型数据库
优点
1、容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解;
2、使用方便:通用的SQL语言使得操作关系型数据库非常方便;
3、易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率;
4、支持SQL,可用于复杂的查询。
5.支持事务
缺点
1、为了维护一致性所付出的巨大代价就是其读写性能比较差;
2、固定的表结构;
3、不支持高并发读写需求;
4、不支持海量数据的高效率读写 非关系型数据库
1、使用键值对存储数据;
2、分布式;
优点
无需经过sql层的解析,读写性能很高
基于键值对,数据没有耦合性,容易扩展
存储数据的格式:nosql的存储格式是key,value形式
缺点
不提供sql支持 22.数据库中join的left join , inner join, cross join
1.以A,B两张表为例
A left join B
选出A的所有记录,B表中没有的以null 代替
right join 同理
2.inner join
A,B有交集的记录
3.cross join (笛卡尔积)
A中的每一条记录和B中的每一条记录生成一条记录
例如A中有4条,B中有4条,cross join 就有16条记录 23.有哪些锁,select时怎么加排它锁
| 锁 | 概念 |
|---|---|
| 乐观锁 | 自己实现,通过版本号 |
| 悲观锁 | 共享锁,多个事务,只能读不能写,加 lock in share mode |
| 排它锁 | 一个事务,只能写,for update |
| 行锁 | 作用于数据行 |
| 表锁 | 作于用表 |
24.死锁怎么解决
找到进程号,kill 进程 25.最左匹配原则
最左匹配原则是针对索引的
举例来说:两个字段(name,age)建立联合索引,如果where age=12这样的话,是没有利用到索引的,
这里我们可以简单的理解为先是对name字段的值排序,然后对age的数据排序,如果直接查age的话,这时就没有利用到索引了,
查询条件where name=‘xxx’ and age=xx 这时的话,就利用到索引了,再来思考下where age=xx and name=’xxx‘ 这个sql会利用索引吗,
按照正常的原则来讲是不会利用到的,但是优化器会进行优化,把位置交换下。这个sql也能利用到索引了 之前的排版有问题,效果不好,重新排了版,增加了目录和优化了展示,
如果觉得对你有帮助的话,求点赞,求关注,比心
本文转自 https://blog.csdn.net/qq_22222499/article/details/79060495,如有侵权,请联系删除。











