这篇博文的面向群体是 还不太了解 Prometheus 和 想要开始使用 Prometheus 的人群.
本文想做的事是 想尽力讲清楚 Prometheus 是如何看待监控这件事情 以及 Prometheus 是如何实现这些需求的.
本文中不会出现的内容: 跟 Prometheus 实现细节有太多相关的东西 等
当想看监控的时候, 我们到底想要什么?
我们想要看的东西也就是我们对监控的需求.
需求
在实际的生产过程中, 产生的和需要收集的监控数据分为很多种, 例如以下这些, 除此之外, 还有很多很多. 但从实现方式上来说, 大多都大同小异.
瞬时状态的 CPU 和 MEM 使用率读数
硬盘使用量的增长率
对 集群节点 状态 进行筛选 , 记录节点位于什么时刻不可用, 这就要求有 Tag 支持
瞬时状态的 网卡流量, 例如 100 Mbps,
服务请求量, 服务的 QPS, 服务的 错误率和错误次数
全部请求的平均时耗
一段时间内, 所有请求的 时耗中, 50% 的请求时耗小于多少毫秒, 95% 的请求时耗小于多少毫秒? 以此评估整体的接口情况
一段时间内, 所有请求的 时耗中, 多少请求时耗大于 1000ms, 多少请求时耗位于 200-500 区间内, 用于了解 请求时耗的具体分布, 以评估接口情况
……
那么我们就需要一个 监控系统 来完成 上述需求, 这个监控系统 仅仅能收集上面的这些数据还不够, 如果不能展示 和 查询, 这些数据的保存将毫无意义. 另外, 既然是监控, 那么必然要有告警的功能.
那么总结一下, 我们需要 能够 将 监控数据 收集 和 查询 的监控系统 来完成我们的需求, 除此之外, 我们还需要 告警 和 展示 的功能
而 Prometheus 就是完成了 我们上述需求的一个 监控系统 的 实现.
从 Prometheus 的视角看这些需求
数据的保存
Prometheus 使用一个 TSDB 来保存 这些监控数据,
TSDB 的全称是 Time series Database (时序数据库), 是为了解决 时序性数据的保存问题, 而诞生的 数据库类型.
一开始的话, 其实这些保存 时序型数据 的需求都可以使用 关系型 数据库 来解决. 但 如果直接基于 关系型数据库 来直接做需求的话, 各种写入 和 读出的 适配都得得按照 关系型数据库的规则来做, 比较麻烦, 虽然确实有一些 TSDB 是基于 关系型数据库实现的.
另外 由于时序型数据 的一些特点, 例如 大部分都是写入操作, 极少修改, 大部分读都是顺序读, 对于一个指标的分析. 那么基于这些特点, 又有一些 技巧, 来做很多的优化, 所以便有了 单独的 TSDB 实现. 例如 InfluxDB, FaceBook 的 Gorilla 等, Prometheus 的 TSDB 便是 参考了 FB 的 Gorilla 之后, 自行实现的.
TSDB 中的 保存的数据, 通常以 数据点(Point) 作为基本单位, 多个 Point 构成 Series (序列), 所有关于同一个主题的数据点 构成 Metrics(指标), 而每个数据点会带有一个 TimeStemp , 也就是这个点所关联的时间, 然后每个数据点会带一些 Tag, 也可以叫 Label , 下文中一律称为 Tag
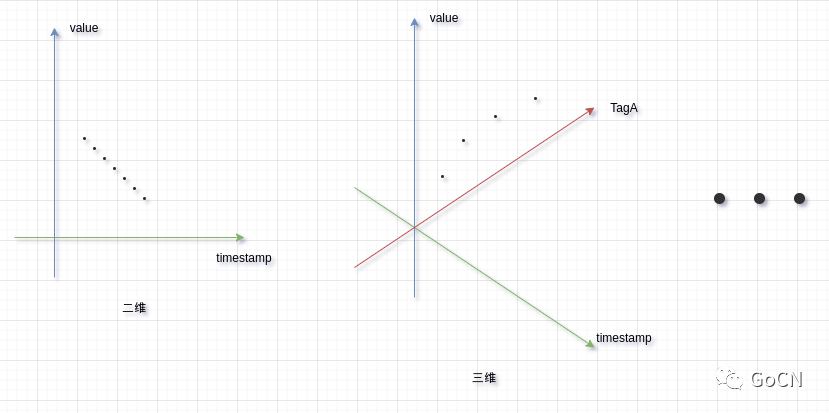
然后我们可以通过对 TSDB 通过 指定 一些相关的指标和 Tag 来进行查询, TSDB 的 数据的层级结构如下所示.
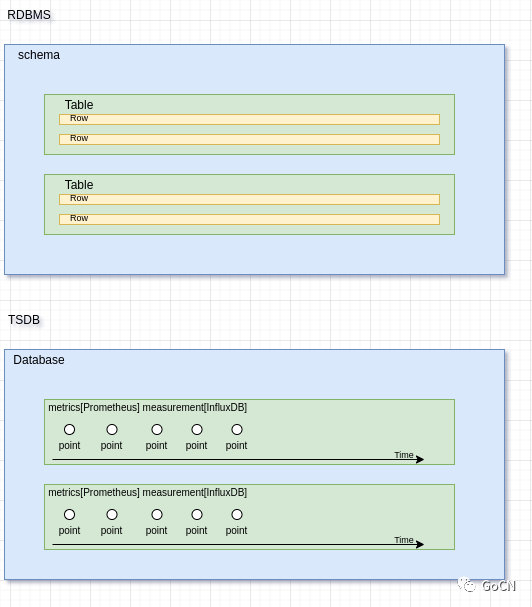
TSDB 和 关系型数据库系统 类似, 通常分为三层, 读者可以按这种对应关系来理解, 不过细节的意义上还是有所不同的.
Database对应 RDBMS 的 Schema , 概念类似 , 而在 Prometheus 中则没有 这一层, 所有的 Metrics 都在一个 Database 中Metrics对应 RDBMS 的 Table , 在 InfluxDB 中这一层叫做measurement,概念类似 .Point对应 RDBMS 的 一条数据 Row , 这个是 TSDB 中的最小单位, 每个 Point 带有一些 Tag , 可以根据不同的条件筛选出来
收集? 如何收集?
监控的收集无非就是上报, 而上报需要 服务端 和 客户端配合. 这里先介绍服务端.
对 Prometheus 来讲, 他的上报采用的是 pull 模型, 也就是拉取模型, 服务端根据客户端的位置, 按时去固定接口拉取. PULL 模型 相较于 PUSH 模型在 客户端较多的情况下较为明显, 很好了缓解了 服务端的并发压力, 但也带来了一些问题, 例如 每个客户端的 位置都要注册给服务端, 会很麻烦, 这个问题通常使用 服务发现和注册 来解决.
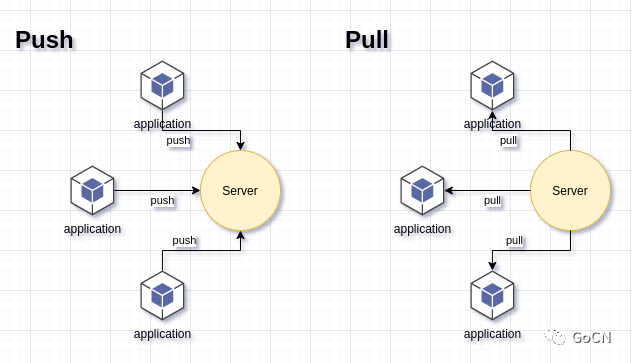
整个过程上报流程可以描述为 客户端按照协议, 准备好数据, 然后服务端的抓取器 定时访问, 来抓取.
相较于 服务端, 客户端就要复杂的多, 我们先来聊聊 Prometheus 上报的协议
协议
Prometheus 服务端 要求 客户端 准备一个 访问 endpoint, 在 Prometheus 访问 endpoint 的时候, 客户端程序需要按照 类似于下面这种格式 准备好 上报数据,
# 这里每一条 由 三个部分组成, # metricName : metrics 的名字 // [a-zA-Z_:][a-zA-Z0-9_:]*# labels : 也可以不填 // [a-zA-Z0-9_]*# value : float64 类型的值# <--- metricName ---> <- labels -> <--value-->go_gc_duration_seconds{quantile="0"} 1.1883e-05go_gc_duration_seconds{quantile="0.25"} 2.2286e-05go_gc_duration_seconds{quantile="0.5"} 4.734e-05go_gc_duration_seconds{quantile="0.75"} 7.4898e-05go_gc_duration_seconds{quantile="1"} 0.000809044go_gc_duration_seconds_sum 0.683513876go_gc_duration_seconds_count 10304go_goroutines 36go_info{version="go1.13.12"} 1go_memstats_alloc_bytes 1.2614712e+07go_memstats_alloc_bytes_total 8.483245152e+10go_memstats_buck_hash_sys_bytes 1.648549e+06go_memstats_frees_total 1.199358391e+09
然后 Prometheus 服务端 在抓取到这些数据, 会将一条记录做成一个 point , 存入 TSDB 中.
这就是全部协议的内容, 很简单. 另外上面的 endpoint 通常情况下 是一个 类似于 http://ip:port/metrics这样,然后以 metrics 结尾的 url, 不过也可以根据自身需求来拟定 url 格式.
抽象
协议在 描述 服务端 如何与 客户端 交互, 但若所有监控项 都由 客户端这么生成其实会有些繁琐 和 混乱, 所以 Prometheus 的客户端除了对 生成结构进行封装外, 还提出了 四种 Metrics 规则类型 供 用户使用. 这些 Metrics 规则类型仅仅和 Client 端有关, 与 Server 无关.
很多教程 一上来就给你讲 四种 Metrics 规则类型, 让人以为 这四个东西是 Prometheus 里非常重要的 东西, 甚至笔者在 写这篇 文章的前几版 之前, 也是这样认为. 但事实上, 这仅仅代表 Prometheus 看待 监控这件事的想法和态度 , 然后抽象出来一方面方便用户使用, 另一方面, 在社区发展第三方内容(例如 第三方 Client SDK 和 Exportor )的时候, 可以规范大家的实现, 以方便讨论.
即便 用户不使用这四种 Metrics 规则类型, 也可以完全自定义自己的指标数据, 甚至定义自己的 指标类型 , 只要满足 上述协议即可. 这四种 Metrics 类型, 更像 Prometheus 团队 在做监控这件事上 ,提出的一个行之有效的方法论(maybe 是 Google 团队 XD).
除此之外, 由于 这些规则被放在 Client 放在客户端运行, 所有的 规则都会在算好之后, 被抓取到服务端, 这样也进一步 下降了服务端的压力, 和上面使用 Pull 的方式 的想法类似, 将压力下推和分散到 Client 端.
只加不减的类型 Counter
顾名思义 Counter, 累加者, 这个是最常用的类型, 常常用于 记录 HTTP Request Total 这种数据, 这个 类型 通常会一直上升, 基于这个特性, 我们又可以使用一些函数来获取到另一些我们比较常关心的 指标 , 例如 单日访问量 和 QPS
由于只增不减 的特性, 所以我们使用 当前时刻的值 减去 当前时刻一日之前的值, 即可获得单日的访问量, 例如下图, 用
2020-01-03 11:00时刻的数据, 减去2020-01-02 11:00时刻的数据, 即可算出单日请求量, 事实上, 任意时段的 请求量, 我们都可以使用类似的方法算出.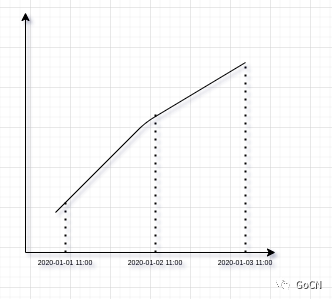
有了 时间段内请求量, 我们要算出 QPS 那就很简单了, 只需要 使用
时间段内请求量 / 秒数即可, 例如 想展示一天时段内的 QPS, 我们以 5m 为一格, 那么 5m 内的 QPS 就是5m 内的请求总数 / 60*5, 然后把每个 5m 的 QPS 算出来, 展示在 时间轴上, 即可看到一天 所有时段的 QPS 数据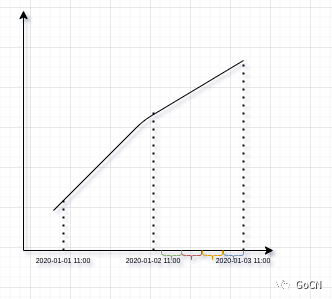
瞬时指标 Gauge
这个指标就比较直白, 用于表示一些瞬时指标, 例如 上面需求提到的 瞬时 CPU 读数, 瞬时 Disk Used Space, 等 , 这个指标不会累加, 只是按当前值为主.
直方图 Histogram 和 分位值 Summary
这两个指标类型在使用上, 通常会一起使用. 但也根据需求, 有时候会单独使用. 在聊这两种指标之前, 我想先聊聊 平均值, 用来引出 这两种指标.
平均值的缺陷
假设 如下图的一个瞬间, 系统 处理 100 条并发请求的 时耗如下左边所示, 这 100 条请求里面 时耗分为 五个段, 0 ~ 100 ms,101~200 ms,201 ~ 300 ms,301 ~ 400 ms,401 ~ 500 ms, 接着 很快就能算出 这一秒请求的时耗 平均值 是 300 ms, 在 3s 或者更长的时间段里, 我们都能看到时间段内的所有请求的平均值 在 300ms.
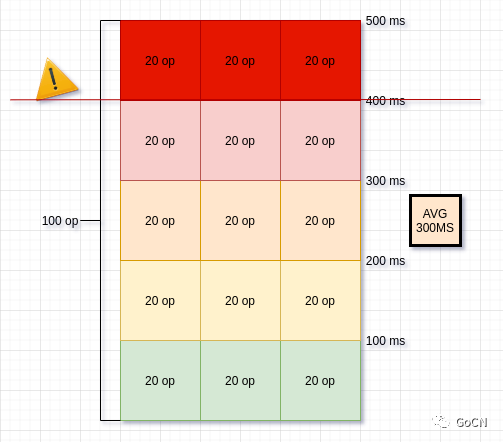
假设请求时延 超过 400 ms 被认为 不可接受, 那么很明显, 如果我们只关注 平均值(avg) , 我们就很可能认为这一时段, 系统正处于正常状态, 但实际上, 系统此时已经发生异常, 有 20% 的 请求处于不可接受的状态. 平均值 过度的 屏蔽了 请求时耗分布 的 具体细节.
分位值 Summary
而为了解决 平均值的这个缺陷, 这个时候就需要引入 分位值(Top Percentile) 的概念.
顾名思义, 分位值 就是 分位 分位上的值, 例如 中位数, 其实也就是 50% 分位数. 通常计算分位值的 分位数 是在将 样本集 的数据排序后, 取出指定位置的数据 作为对应位置的分位值.例如 一个已经排好序的数组 里面有 100 个数, 那么 这个数组的 25% 分位值 就是第 25 个数. 例如下面的 图, 就分别展示了 25% 分位值, 50% 分位值, 75% 分位值 , 95% 分位值 和 99% 分位值
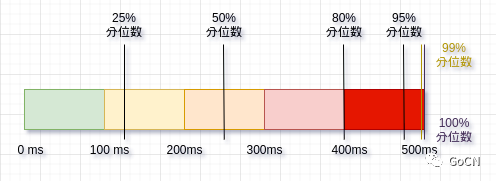
那么利用分位数,我们就可以明确知道 这个时段内的请求分布情况, 相比刚才计算 平均数的方式, 分位值 的优势就展示的比较明显.
分位值除了可以比较好的展示时段内请求的细节外, 分位值还可以作为服务异常的基准指标, 以搜索接口为例, 假设 规定搜索接口 95% 的请求都需要保证在 1s 内完成, 如果超过就告警. 用分位值来做就很好做, 直接 95% 的分位值 不允许大于 1s 即可.
在 Prometheus 中, 客户端根据 协议 提交给 服务端 的 分位数 指标数据大致会像下面这个样子
# quantile 可以由用户自行指定go_gc_duration_seconds{quantile="0"} 1.1883e-05go_gc_duration_seconds{quantile="0.25"} 2.2286e-05go_gc_duration_seconds{quantile="0.5"} 4.734e-05go_gc_duration_seconds{quantile="0.75"} 7.4898e-05go_gc_duration_seconds{quantile="0.99"} 0.000809044go_gc_duration_seconds_sum 0.683513876go_gc_duration_seconds_count 10304
直方图 Histogram
但仅仅只有 Summary , 还是不太够, 虽然知道了分位值 , 但有时候我们想知道, 到底有多少请求 大于 400ms , 多少请求在 100ms 内, 这个仅仅通过 Summary 是没有办法告诉我们的, 我们需要借助 Histogram 来表示.
Histogram 也就是直方图, 没错, 就是 小学课本上那种. 在客户端 使用直方图 进行计数, 我们就可以很清晰的看到 请求时耗 在 我们划定的 区间中的分布.
在 Prometheus 中, 客户端根据 协议 生成好后, 提交给 服务端 的 指标数据大致会像下面这样.
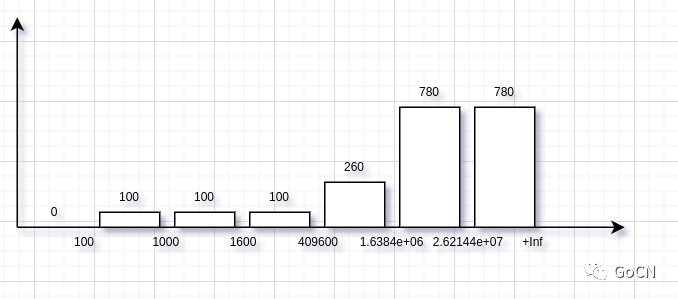
# le 可以由用户自行指定prometheus_tsdb_compaction_chunk_range_bucket{le="100"} 0prometheus_tsdb_compaction_chunk_range_bucket{le="1000"} 100prometheus_tsdb_compaction_chunk_range_bucket{le="1600"} 100prometheus_tsdb_compaction_chunk_range_bucket{le="409600"} 100prometheus_tsdb_compaction_chunk_range_bucket{le="1.6384e+06"} 260prometheus_tsdb_compaction_chunk_range_bucket{le="2.62144e+07"} 780prometheus_tsdb_compaction_chunk_range_bucket{le="+Inf"} 780prometheus_tsdb_compaction_chunk_range_sum 1.1540798e+09prometheus_tsdb_compaction_chunk_range_count 780
关于直方图的实现, Prometheus 客户端 生成的 并不是像上面图这样错落有致, 而是用这个公式这样算出来的 当前的区间的值 = 当前区间内的实际值 + 上一个区间的值, 初看可能比较绕. 不过这样做的好处有很多,
我们如果要计算 任意区间之间的 实际值 的话, 就只需要使用后面区间减去 前面区间的值即可, 在计算多个区间的值的时候尤其明显.
当区间在减少的时候, 数据依旧不失真
数据存储时比较好优化
……
结
至此, 我们基本讲完了 Prometheus 的大多数 使用细节. 接着我们来看看 Prometheus 的结构.
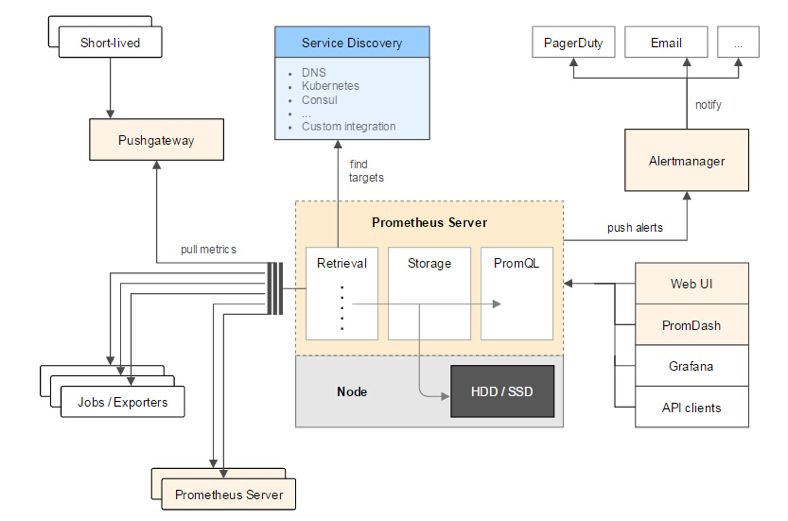
Prometheus
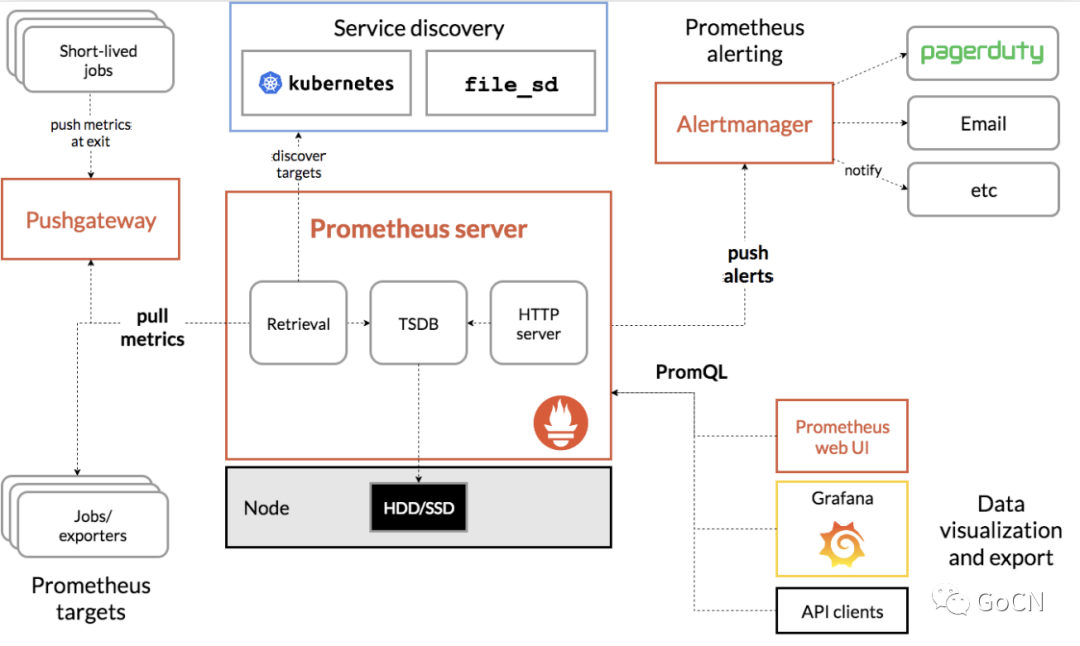
上面这个是 Prometheus 官网的 Prometheus 结构图, 我们可以看到 Prometheus 的结构分为三块,
最左边的 是 监控数据的 source 区, 里面有 Prometheus 使用它的 抓取器 来抓取 我们的 应用程序的 监控数据, 然后保存到 TSDB 上,
接着 最右边的 部分分为两块, 一块是 AlertManager , Prometheus 会定期检查一些告警规则, 如果这些规则 被满足, 将会 推送 给 AlertManager 表示这些数据需要告警. 另一块是 展示的部分 , Grafana 或者 Prometheus 的 WebUI 通过 PromQL 查询 Prometheus 的 TSDB 来获取 结果并展示.
告警
告警的部分, 在 Prometheus 推送消息给 AlertManager 之后, AlertManager 会自行判断, 这条告警是否需要推送出去, AlertManger 中有一些 沉默 和 告警阈值的规则, 当 一条告警触发 多少次, 或者 多久之内触发一次, 就会告警到 设置好的 Channel , 这样可以避免 由 告警风暴 带来的麻痹 和 狼来了的故事.
PromQL
PromQL 是 Prometheus 设计出来的一种 DSL , 使用起来的感觉向使用 函数. 关于 PromQL 的内容, 可以参考 另一篇博文 PromQL 指南
基于指标的监控系统 和 基于日志的监控系统的区别
在 接触 Prometheus + Grafana 指标监控系统 之前, 笔者也接触过 ElasticSearch + Logstash/Fluentd 的 日志监控系统,
笔者认为二者各有各的优势, Prometheus 方案的重点在于轻和迅速, 没有太多的基础设施, 甚至可以不依赖 服务注册中心, 只要把 Prometheus 拉起来, 然后 服务接入一下 Prometheus Client , 就可以开始使用监控. 但 Prometheus 由于基于 TSDB 的缘故, 所以 Prometheus 没有办法支持太过高维度的指标 或者 枚举值太多的 Tag, 而这点对于 基于日志监控系统 来讲则还好.
而基于日志的监控系统的问题在于太重了, 光是搭建和维护 一个 ES 集群加上 Logstash 以及 Beats 收集器 和 Kibana, 就已经有些费力 . 另外 过多的 东西需要在 Logstash 这一层配置, 每次 业务方新的需求写到日志中, 需要添加一些 Logstash 的 配置, 来解析日志以方便 Kibana 的视图查询.当然我们也可以用 通用解析的方案来实现, 那么接着有时候就要添加一些 Index 规则 , 笔者觉得过高的自由度带来了更多问题. 当然这只是笔者的想法, 如果有别的看法, 欢迎交流.
所以总结来讲, 笔者认为, 基于指标的监控系统 和 基于日志的监控系统 更像是一种互补的方案, 虽然通常情况下, 监控需求方面, 如果需要关注 过高维度的指标或者过高枚举值的 情况, 通常都是 这个需求本身就不合理. 但仍然有些情况, 我们必须实现这种需求, 那么就可以考虑 基于日志的监控系统
Ref
本文分享自微信公众号 - GoCN(golangchina)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。