
前几天,Flink官方release了Flink1.10版本,这个版本有很多改动。比如:
Flink 1.10 同时还标志着对 Blink的整合宣告完成,随着对 Hive 的生产级别集成及对 TPC-DS 的全面覆盖,Flink 在增强流式 SQL 处理能力的同时也具备了成熟的批处理能力。本篇博客将对此次版本升级中的主要新特性及优化、值得注意的重要变化以及使用新版本的预期效果逐一进行介绍。
其中最重要的一个特性之一是:推出了生产可用的 Hive 集成。
Flink 1.9推出了预览版的 Hive 集成。该版本允许用户使用 SQL DDL 将 Flink 特有的元数据持久化到 Hive Metastore、调用 Hive 中定义的 UDF 以及读、写 Hive 中的表。Flink 1.10 进一步开发和完善了这一特性,带来了全面兼容 Hive 主要版本的生产可用的 Hive 集成。
笔者就遇到的几个问题,归类总结如下。如果你在生产环境遇到各种奇奇怪怪得问题,可能带来一些启示:
架构设计
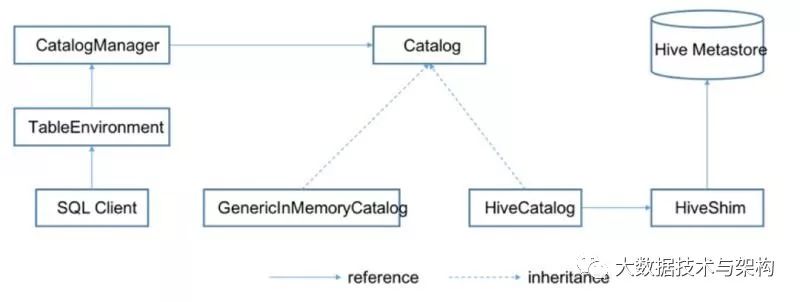
Flink在创建运行环境时会同时创建一个CatalogManager,这个CatalogManager就是用来管理不同的Catalog实例,我们的Flink运行环境就是通过这个访问Hive:
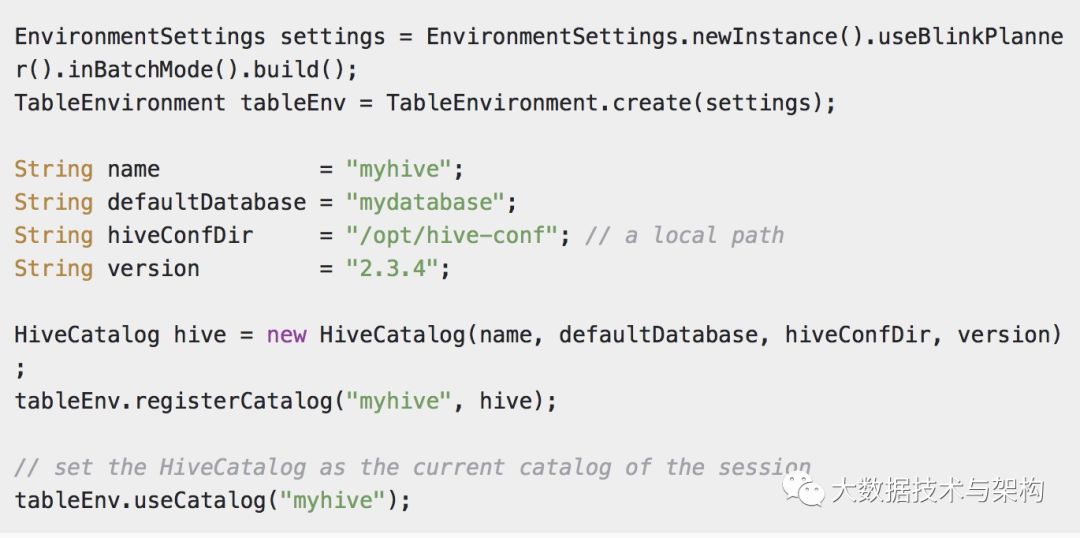
官网给出的例子如下:
Hive Catalog + Hive 需要一个配置文件
Hadoop和Spark链接Hive时都会有一个hive-site.xml的配置文件,同样Flink在和Hive集成时也需要一个配置文件:sql-client-hive.yaml 这个配置文件中包含了:hive配置文件的路径,执行引擎等。官网给出的配置案例:

官网同样给出了警示⚠️信息如下:
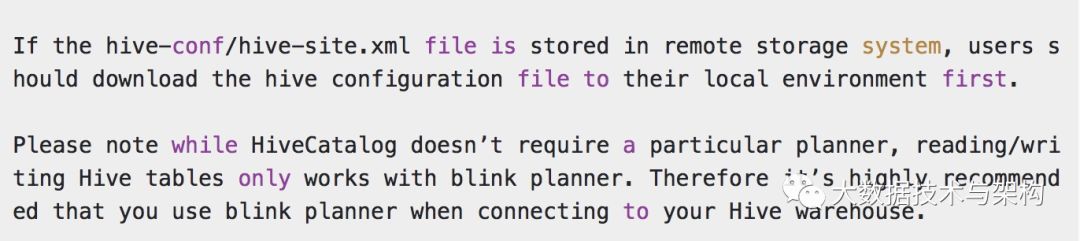
意思是说,本地需要一个hive-site.xml,另外sql-client-hive.yaml 中的planner配置必须为blink 。
SQL CLI工具支持
这个玩具类似一个对话窗口,可以通过脚本sql-client.sh 脚本启动,运行方法如下:


需要注意的是,运行脚本的当前机器必须有必须的环境变量,例如:HADOOP_CONF_DIR、HIVE_HOME、HADOOP_CLASSPATH等,把Hadoop集群搭建的时候指定的一些环境变量拿过来即可。
必要依赖和版本区别
Flink 1.10 对Hive集成支持了很多版本,对于不同的Hive版本需要不同的Jar包支持,具体可以参考: https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/hive/#connecting-to-hive
另外,官网还给出了目前对Hive支持的一些注意点⚠️:
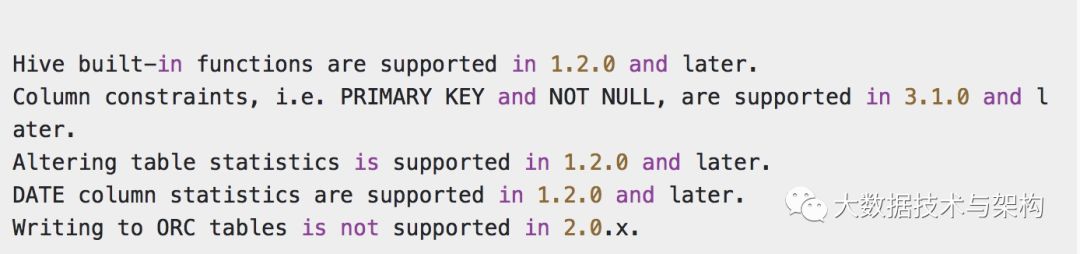
很简单的英文,不再翻译了。
优点和不足
本次更新issue里提到了目前主要做的一些优化,包括:Projection Pushdown(只读取必要的列),Limit Pushdown(sql能limit的就limit,减少数据量),分区裁剪(只读必须分区)等等。总体来说目前都是sql优化的一些常用手段。
目前的不足之处主要包含:
存储格式目前还没有完全支持,We have tested on the following of table storage formats: text, csv, SequenceFile, ORC, and Parquet. ,相信很快就会再次release。
另外ACID、Bucket表暂时还不支持。
Hive作为数据仓库系统的绝对核心,承担着绝大多数的离线数据ETL计算和数据管理,期待Flink未来的完美支持。
欢迎点赞+收藏+转发朋友圈素质三连


文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。










