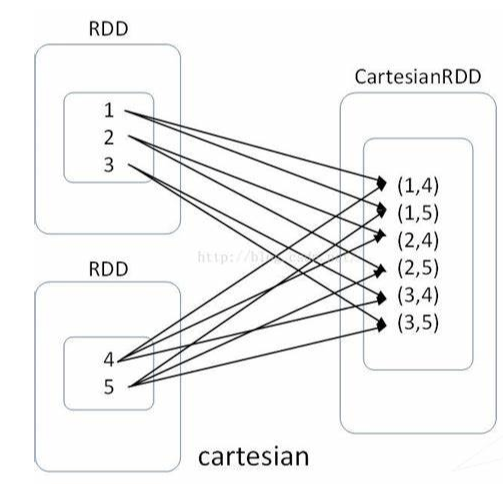
一、笛卡尔积
- 概念
笛卡尔乘积是指在数学中,两个集合_X_和_Y_的笛卡尓积(Cartesian product),又称直积,表示为_X_ × _Y_,第一个对象是_X_的成员而第二个对象是_Y_的所有可能有序对的其中一个成员。[1]
简单点说就是:集合X的每个元素和集合B的每个元素进行两两组合,组合次数等于集合X元素数量 * 集合Y元素数量。
从笛卡尔积中筛选出有效数据图解
select * from emp e, dept d where e.deptno = d.deptno;
笛卡尔积查询示意图
- 一些注意事项
- 从上图可以看出,部门不相同的行都没有实际意义,单纯笛卡尔积的出现大多数情况没有意义。如果出现笛卡尔积或者小范围内出现,则说明sql语句很可能错了;
- 从上图可以看出,两张表先笛卡尔积在通过条件逐条排除,中间会产生很多无效数据,所以尽量在进行笛卡尔积前进行条件过滤;
二、四种连接方式简介[2]
内连接(表A inner join 表B on 条件)
返回表A(左表)和表B(右表)相匹配的数据;左外连接(表A left join 表B on 条件)
表A(左表)的记录全部表示出来,而表B(右表)只会显示符合条件的记录,表B(右表)记录不足的地方均为null;右外连接(表A right join 表B on 条件)
和左外连接的结果刚好相反,是以表B(右表)为基础,显示表B(右表)的全部记录,在加上表A(左表)符合条件的记录,表A(左表)记录不足的地方均为null;全连接(表A full join 表B on 条件)
返回表A(左表)和表B(右表)中的所有行;四种连接方式.jpg
三、案例详解
sql运行环境介绍
数据库:oracle数据库 10g
可视化开发工具:PL/SQL Developer
表格信息来源:oracle自带表emp表(员工表)和dept表(部门表)
员工表与部门表的关系:一对多的关系(一个员工属于一个部门,一个部门有多个员工)
两张表格内容
员工表:emp表jpg.jpg
部门表:
dept表jpg.jpg
工资登记表:
salgrade.jpg
案例
查询出每个员工的上级领导(查询内容:员工编号、员工姓名、员工部门编号、员工工资、领导编号、领导姓名、领导工资)
select e1.empno 雇员编号, e1.ename 雇员姓名, e1.deptno 雇员部门编号, e1.sal 雇员月薪, e1.mgr 雇员领导编号, e2.ename 领导名称, e2.sal 领导工资 from emp e1, emp e2 where e1.mgr = e2.empno(+);
查询结果:
Paste_Image.png
思路:(+)符号表示外联表,意思是需要补全的内容。
在题目1的基础上查询员工所对应的部门
select e1.empno 雇员编号, e1.ename 雇员姓名, e1.deptno 雇员部门编号, e1.sal 雇员工资, d1.dname 员工部门名称, e1.sal 雇员月薪, e1.mgr 领导编号, e2.ename 领导名称, e2.sal 领导工资 from emp e1, emp e2, dept d1 where e1.mgr = e2.empno(+) and d1.deptno(+) = e1.deptno
**查询结果: **
Paste_Image.png
红线处是左外连接的效果。
- 在题目3的基础上查询领导的部门名称
方法1 使用oracle
select e1.empno 雇员编号, e1.ename 雇员姓名, e1.deptno 雇员部门编号, d1.dname 员工部门名称, e1.sal 雇员月薪, e1.mgr 领导编号, e2.ename 领导名称, d2.dname 领导部门名称, e2.sal 领导工资 from emp e1, emp e2, dept d1, dept d2 where e1.mgr = e2.empno(+) and d1.deptno(+) = e1.deptno and d2.deptno(+) = e2.deptno;
运行结果:
Paste_Image.png
方法2 使用原生sql查询
select e1d1.雇员编号, e1d1.雇员姓名, e1d1.雇员部门编号, e1d1.员工部门名称, e1d1.雇员月薪, e1d1.领导编号, e2e1d2.领导姓名, e2e1d2.领导月薪, e2e1d2.领导部门编号, e2e1d2.领导部门名称 from (select e1.empno 雇员编号, e1.ename 雇员姓名, e1.deptno 雇员部门编号, d1.dname 员工部门名称, e1.sal 雇员月薪, e1.mgr 领导编号 from emp e1 left join dept d1 on e1.deptno = d1.deptno) e1d1 left join (select e2e1.领导的编号 领导的编号, e2e1.领导姓名 领导姓名, e2e1.领导月薪 领导月薪, d2.deptno 领导部门编号, d2.dname 领导部门名称 from (select distinct e2.empno 领导的编号,e2.ename 领导姓名, e2.sal 领导月薪, e2.deptno 领导部门编号 from emp e2 left join emp e1 on e1.mgr = e2.empno) e2e1 left join dept d2 on e2e1.领导部门编号 = d2.deptno) e2e1d2 on e1d1.领导编号 = e2e1d2.领导的编号;
查询结果:
Paste_Image.png
思路:我只是想装个逼,不是为了吓唬人的!!!原生sql确实能做同样的功能,但是太复杂了,使用了5张表,不断地左外连接。
查询出每个员工编号,姓名,部门名称,工资等级和他的上级领导的姓名,工资等级
select e.empno 员工编号, e.ename 员工姓名, d.dname 员工部门名称, s.grade 员工工资等级, e2.ename 领导姓名, s2.grade 领导工资等级 from emp e, dept d, salgrade s, emp e2, salgrade s2 where e.deptno = d.deptno(+) and e.sal between s.losal and s.hisal and e.mgr = e2.empno(+) and e2.sal between s2.losal and s2.hisal;
查询结果:
Paste_Image.png
思路:第一张员工表(emp e)和第二张部门表(dept d)在条件(e.deptno = d.deptno(+))下进行查询,结果作为一张新表,与第三张员工工资等级表('salgrade s')在条件(' e.sal between s.losal and s.hisal')下进行查询,结果作为另一张新表,与第四张领导表('emp e2')在条件('emp e2')下进行查询,结果作为另另一张新表,与第五张领导工资级别表('salgrade s2')在条件('e2.sal between s2.losal and s2.hisal')下进行查询,记得最终结果。
查询比SCOTT工资高的员工
select * from emp where sal > (select sal from emp where ename = 'SCOTT');
运行结果:
Paste_Image.png
思路:使用子查询的方法。先查询到SCOTT员工的工资(select sal from emp where ename = 'SCOTT'),然后在把结果作为另一条sql语句条件表达式的一部分,进行查询。
- 查询职位是经理并且工资比7782号员工高的员工
方法1(子查询):
select * from emp where job = 'MANAGER' and sal > (select sal from emp where empno = 7782);
方法2(集合运算):
select * from emp where job = 'MANAGER' intersect -- 交集 select * from emp where sal > (select sal from emp where empno = 7782);
查询结果:
Paste_Image.png
思路: 方法1和上一题基本一致,就是多加了一个条件。方法二,使用了集合的交集(intersect)、并集(union)、补集(minus)的方法,获取结果;集合运算也是有前提的,两个结果集,列的数量相等并且对应的列数据类型一致才可以进行运算。
查询 部门最低工资 大于 30号部门最低工资 的结果
select deptno, min(sal) from emp group by deptno having min(sal) > (select min(sal) from emp where deptno = '30');
查询结果:
Paste_Image.png
思路: 先查询出30号部门最低工资select min(sal) from emp where deptno = '30',再查询部门的最低工资select deptno, min(sal) from emp group by deptno,根据题目要求将两个查询语句拼接即可。
查询出和SCOTT同部门并且同职位的员工(不包含SCOTT本人)
select * from emp where (job, deptno) = (select job, deptno from emp where ename = 'SCOTT') and ename != 'SCOTT';
运行结果:
Paste_Image.png
思路: 使用了多列子查询的方法.
题目9: 查询每个部门的最低工资对应的雇员信息(包括部门名称)
select e.*, d.dname from emp e, dept d where e.sal in (select min(sal) from emp group by deptno) and e.deptno = d.deptno;
查询结果:
Paste_Image.png
思路:先查询每个部门的最低工资select min(sal) from emp group by deptno,在查询最低工资对应的员工信息
select * from emp where e.sal in 各部门最低工资结果集,再将查询结果集(新表)和dept表进行内连接,去除无效记录即得结果.
查询出不是领导的员工
select * from emp where empno not in (select distinct mgr from emp where mgr is not null);
查询结果:
思路: 查询出各个员工的领导的编号select distinct mgr from emp where mgr is not null(总裁没有上级领导,所以为null,要排除掉),在查询员工表中员工编号不在此结果集的排除掉select * from emp where empno not in 领导编号结果集,即得结果.
题目11: 查询员工表中工资最高的前三名
select t.*,rownum from (select * from emp order by sal desc) t where rownum < 4;
查询结果:
Paste_Image.png
思路: 不能通过select * from emp where rownum < 4 order by sal desc;de方式获取到结果,原因是rownmu是伪列,在查询条件前就已经生成,不能成为查询的条件,需要对排序结果进行二次查询,产生新的rownum才能作为查询的条件依据.
在上一题的基础上查询工资第4~6名的员工信息
select * from (select ed.*, rownum r from (select * from emp order by sal desc) ed where rownum < 7) t where t.r > 3
运行结果:
Paste_Image.png
思路: 先将表按照sal降序排列select * from emp order by sal desc, 在将结果作为临时表,获取工资前6名的员工信息和行号select ed.*, rownum r from sal降序表 ed where rownum < 7,将查询结果作为另一张临时表,查询出工资4~6名的数据select * from 前6名员工表 where t.r > 3;不使用select ed.*, rownum r from sal降序表 ed where rownum > 3 and rownum < 7是因为rownum不支持大于号运算。
** 本题涉及到oracle分页的思想,以后有时间再深入**
找到员工表中薪水大于本部门平均薪水的员工
select * from emp e, (select deptno, avg(sal) avgsal from emp group by deptno) t where t.deptno = e.deptno and e.sal > t.avgsal;
查询结果:
Paste_Image.png
思路: 先查询每个部门的平均薪水select deptno, avg(sal) avgsal from emp group by deptno作为临时表,在查询select * from emp e, 各部门平均工资表 where t.deptno = e.deptno and e.sal > t.avgsal,即得结果。
统计每年入职的员工个数
select to_char(hiredate, 'yyyy') 年份, count(*) 入职人数 from emp e group by to_char(hiredate, 'yyyy');
查询结果:
Paste_Image.png
思路: 使用oracle的转换函数将日期类型转换成字符串类型,进行排序。·to_char(日期类型, '日期格式'),其中日期格式一般表示为‘yyyy-MM-dd HH-mi-ss’,可以选择性的使用。
在上一题的基础上将竖表转换成横表
select '入职人数' "年份", sum(decode(竖表.年份, '1980', 竖表.入职人数)) "1980", sum(decode(竖表.年份, '1981', 竖表.入职人数)) "1981",
sum(decode(竖表.年份, '1982', 竖表.入职人数)) "1982", sum(decode(竖表.年份, '1987', 竖表.入职人数)) "1987", sum(竖表.入职人数) "Total" from (select to_char(hiredate, 'yyyy') 年份, count(*) 入职人数 from emp e group by to_char(hiredate, 'yyyy')) 竖表
运行结果:
Paste_Image.png
思路:decode函数是oracle特有的,使用方法是decode(列名, 需要转义的内容, 转义后的内容,需要转义的内容, 转义后的内容...),例如select job,decode(job,'CLERK','业务员','SALESMAN','销售员','其它') from emp运行结果:
Paste_Image.png
sum函数将编译后的每列累加起来,如果没有sum函数结果是:
Paste_Image.png