
转载本文需注明出处:微信公众号EAWorld,违者必究。
本文目录:
一、背景
二、我们的需求是什么?
三、概念澄清
四、概念模型
五、总体设计
六、关键点设计
七、总结
一、背景
说到自动化部署,大家肯定都会想到一些配置管理工具,像ansible,chef,puppet, saltstack等等。虽然这些工具给运维效率和安全性带来了很多好处。但是实际工作中,我们还是会遇到一些问题:
这些工具无法普及到开发、测试人员,经常找运维帮忙,无法自助;
项目人员无法直观的参看到系统的部署架构设计,及架构的演进过程;
从物理架构设计到最终上线,无法形成闭环;
受差异性的基础设施影响较大。
二、我们的需求是什么?
我们DevOps平台的部署模块就克服上面这些问题,为实现DevOps以产品为核心,以项目管理为驱动,将需求、设计、交付、运维整个链路打通这一目标提供有力支持。具体来看其需求涵盖一下几点:
将架构设计纳入DevOps管理过程中,支持架构设计版本化;
一次架构设计多次部署;
以最佳实践为基础,实现架构设计模版重用;
多环境部署,同时支持应用在虚拟机、容器上的部署;
支持多种部署模式(单机、高可用)、部署策略(全新、蓝绿、滚动升级、回滚)
三、概念澄清
在正式讲解我们的设计之前,我们想澄清CI/CD的基本概念,因为本次的主题和持续集成、持续交付和持续部署这些名词总有些渊源。
1、什么是持续集成?
持续集成(Continuous Integration)指的是,频繁地将代码集成到主干,以便快速发现错误、防止分支大幅度偏离主干。
持续集成的目的,就是在产品快速迭代的同时保持代码质量,它的核心措施主要有两点:
1)代码集成到主干之前,必须通过自动化测试,只要有一个测试用例失败,就不能集成。
2)通过Code Review、代码质量分析工具对代码质量进行把关,以便确定是否能够集成。
Martin Flower说过, “持续集成并不能消除Bug,而是让他们非常容易发现和改正。”
2、什么是持续交付?
持续交付(Continuous Delivery)指的是,新版本为了能够快速安全的交付到生产环境中,需要将新版本先交付到类生产(Production-like)环境中(如UAT/Staging/Lab环境),以便进行相应的业务验证、安全验证、性能验证等过程。
一旦类生产环境验证通过,新版本就进入到生产阶段。
持续交付可以看作是持续集成的进一步。它强调的是,不管怎么更新,软件是随时随地可以交付的。
3、什么是持续部署?
持续部署(Continuous Deployment)指的是,新版本通过类生产环境的验证后,自动部署到生产环境中。
持续部署可以看成持续交付的进一步。持续部署的前提是自动化完成测试、构建、验证等步骤。
持续部署的目标是,代码在任何时刻都可以进入自动地进入生产阶段,为最终用户提供服务。
持续交付和持续部署的区别可以参考下图:
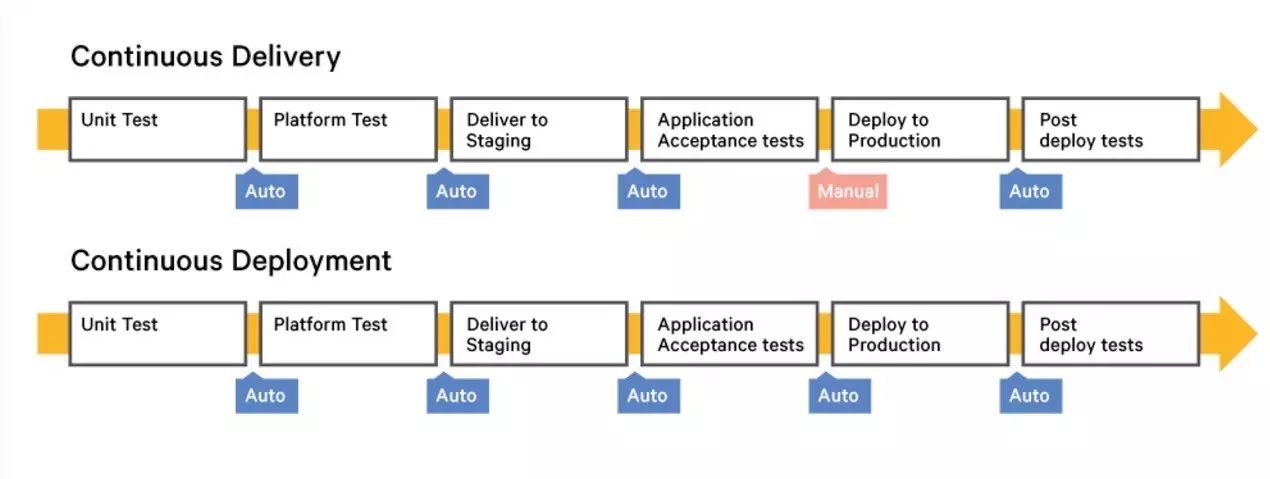
(点击可放大查看)
从上图中,我们可以看出:
持续交付流程将自动的测试新版本应用,但是否将新版本交付到生产环境中是一个手动过程。持续部署则是自动地将新版本交付到生产环境中去。
关于持续交付/持续部署,我们不能说哪一个是最好的方案。对于不同的组织,适合的就是最好的。
4、什么是自动化部署?
自动化部署(Automatic Deployment)指的是,通过自动化工具将应用介质部署到指定环境中去。
自动化部署只是持续交付和持续部署流程中的一个功能单元。
自动化部署工具:Ansible、Puppet、SaltStack等等。
通过以上概念的澄清,我们了解了什么是持续集成、持续交付、持续部署以及自动化部署。
本文的主题不是介绍持续集成、持续交付、持续部署的Pipeline与实现,而是介绍DevOps平台中,在传统自动化部署工具之上的自动化部署框架的设计与实现。而自动化部署模块也是我们DevOps平台中的CI/CD的底层能力。
下面我们就来聊聊具体的设计。
四、概念模型
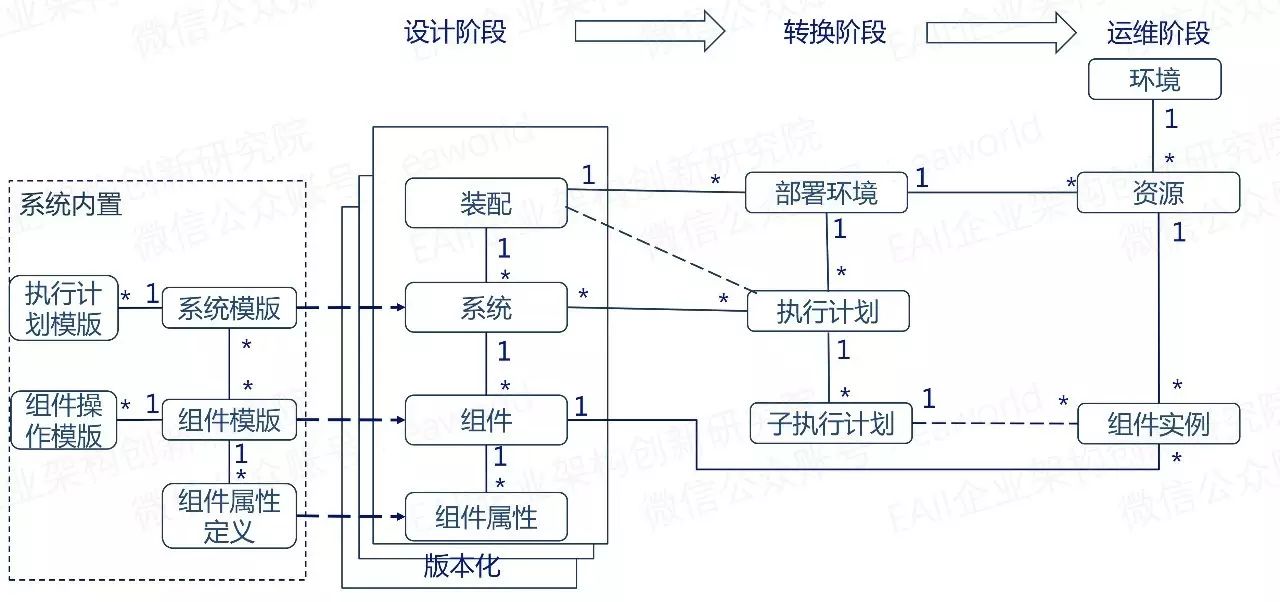
(点击可放大查看)
除了系统内置的一些模版概念,我们将自动化部署流程分为三个阶段,即设计、转换、运维。每个阶段都会有相应的基本模型。
下面,我们分阶段的去解释一下这些概念模型。
1、设计阶段
设计(Design),是在装配(Assembly)内对应用/系统的架构的描述;而应用/系统,是由含有多个组件(Component)的系统(Platform)组成的。
Design阶段的基本流程:
(1)创建装配(Assembly)
通过选择可用的系统模版(Platform Template),添加一个新的Platform;
每一个Platform都对应一种应用(如mysql,tomcat,springboot,nginx);
每一个Platform都是有一组组件(Component)组成的,并且已定义好了组件之间的依赖关系;
在Assembly内,用户可以通过设置Platform Link设置各个Platform之间的关系
(2)配置系统(Platform)内的组件(Component)的属性值
Component是最底层的部署(或者配置)单元,如springboot中的secgroup, compute, os, jdk, fatjar, lb都是一个组件;
每一个Component都有相应的配置模版
(3)提交设计
- 提交的过程是将已经完成的设计做一次Commit,做一次归档。
2、转换阶段
转换(Transition),是在Assembly内对应用/系统在某一Environment内的部署过程。
Transition阶段的基本流程:
(1)创建部署环境(Deploy Environment)
根据环境类型(如dev, test, prod等),添加属于某个Assembly的部署环境
部署之前,部署环境是应用/系统用于部署的配置的抽象
部署之后,部署环境就是管理和监控应用/系统的具体实例的集合
(2)配置部署环境
- 设置每个Platform关联的资源(vm/container)、部署模式(单点,高可用)
(3)选择Assembly内的一个或多个Platform生成并提交执行计划
- 根据部署策略不同,一个Platform的执行计划可能包含几个子计划
(4)执行部署
- 每个Assembly/Environment/Platform下面的每个Component都有一个instance,这些instance可以进行单独Repair
3、运维阶段
运维(Operation),是在Assembly内对各个部署环境内Instances的管理和监控。
Operation阶段的基本任务:
(1)组件实例运维,例如
Compute: Status, Reboot, upgrade-os-security, powercycel, repair, upgrade-os-all
Tomcat/Jboss: Status, Stop, Start, Restart, Repair, Debug
Artifact: Repair, Redeploy, Custom User Attachment
(2)展现正在部署的操作,有可能还会Replace或Cancel其中一项组件部署或整个部署
(3)展示Assembly某一Environment下的组件实例图谱
(4)日志查询
- 对基本的概念模型有了基本认识后,我们来看一下自动化部署框架的总体思路。
五、总体思路
DevOps自动化部署框架采用DevOps平台(设计)+Jenkins(执行)的方式完成。
DevOps的职责
完成部署架构设计;
根据部署架构设计和部署环境的配置创建生成相应的执行计划及子执行计划,每一个子计 划对应一个Jenkins pipeline job配置文件(config.xml);
查询Jenkins执行job的实时进度与结果。
Jenkins的职责
根据config.xml创建Jenkins Pipeline Job;
执行pipeline job;
Jenkins job 通过pipeline script中ansible/openshift命令进行相应的部署等执行操作;
提供查询job执行情况的Rest API。
结合上面提到的三个阶段,具体的流程如下所示:
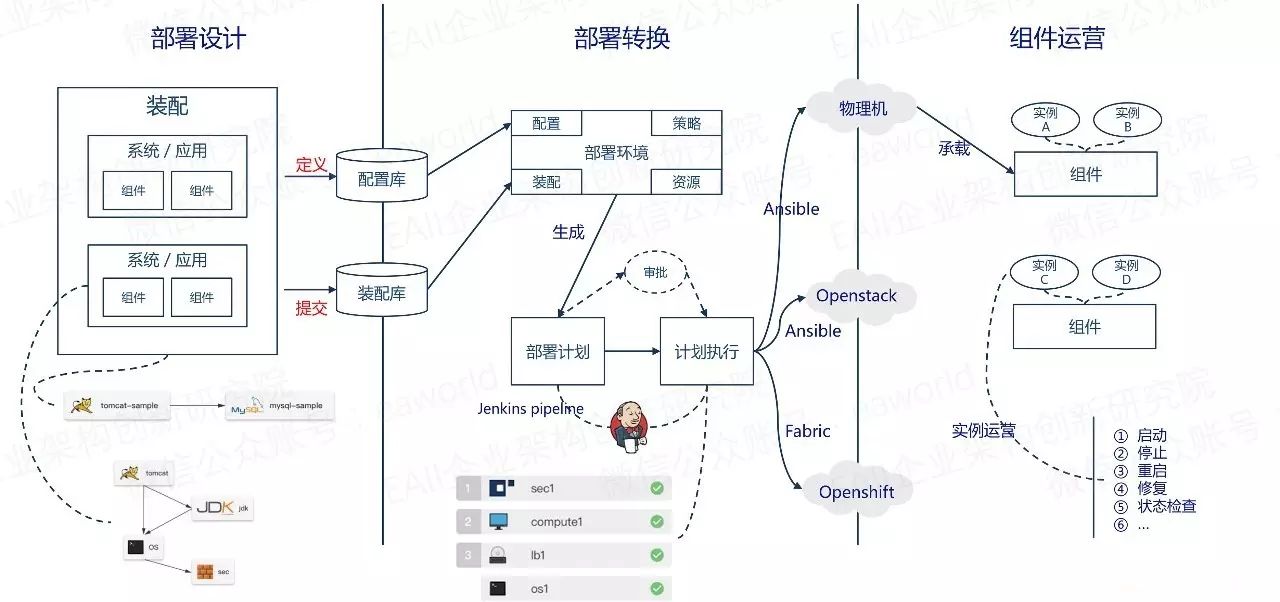
(点击可放大查看)
下面是具体的部署视图:
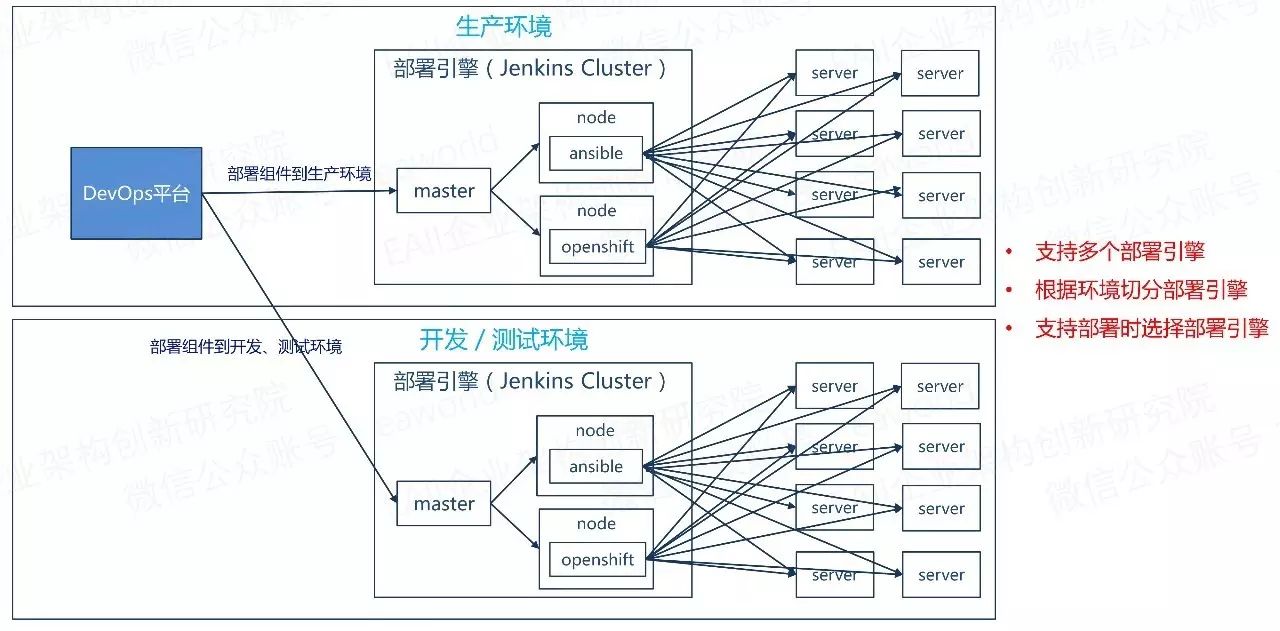
(点击可放大查看)
看完整体思路和部署视图,大家肯定会问为什么选择jenkins作为具体的执行引擎?
首先,jenkins支持master/slave架构,能根据性能需求水平扩张,slave又可以支持多种环境,可以将不同的job分配到不同的slave节点。
还有非常重要的一点,就是Jenkins Pipeline的能力。
Jenkins中pipeline的设计理念是实现基于groovy脚本,灵活,可扩展的工作流。
durable持久性:在jenkins的master按计划和非计划的重启后,pipeline的job仍然能够工作,不受影响。
可暂停性:pipeline基于groovy可以实现job的暂停和等待用户的输入或批准然后继续执行。
更灵活的并行执行,更强的依赖控制,通过groovy脚本可以实现step,stage间的并行执行,和更复杂的相互依赖关系。
可扩展性:通过groovy的编程更容易的扩展插件。
丰富插件:Jenkins已经支持通过groovy命令调用git、maven、npm、gradle、shell、junit、sonarqube、ansible、docker、openshift、kubernetes等插件,不需要我们再单独实现集成。
Rest API:Jenkins提供通过Rest API的方式获取每一个stage的执行情况。
由于我们最终会将应用部署到虚拟机和容器云中,虚拟机部署主要通过jenkins中提供的ansible插件+jenkins pipeline script来实现;容器云部署则根据具体的容器云,通过openshift插件(会有一定扩展)或者http request插件+jenkins pipeline script来实现。
下面我们来看一下Jenkins2的主要概念。
step, 其实跟jenkins1中的概念一样, 是jenkins里job中的最小单位,可以认为是一个脚本的调用和一个插件的调用。比如通过git拉取代码就是一个step,mvn clean package也是一个step,一个http远程调用等等。
node, 是pipleline里groovy的一个概念,node可以给定参数用来选择agent,node里的steps将会运行在node选择的agent上。这里与jenkins1的区别是,一个 job里可以有多个node,将job的steps按照需求运行在不同的机器上。例如一个job里有好几个测试集合需要同时运行在不同的机器上。
stage, 是pipeline里groovy里引入的一个虚拟的概念,是一些step的集合,通过stage我们可以将job的所有steps划分为不同的stage,使得整个job像管道一样更容易维护。pipleline还有针对stage改进过的view,使得监控更清楚。这里补充一句,多个stage可以在一个node里定义及执行,一个stage内的多个step可以分到不同的node上执行。
六、关键点设计
前面我们说的都是概念和流程上的东西,那么用户该如何进行部署架构设计?部署架构设计完成后,如何提交呢? 如何将提交的设计在具体的部署环境中转换成执行计划与子执行计划呢?子计划又如何与jenkins pipeline job映射呢?这就是我们下面要介绍的一些关键点设计。
1、模块化
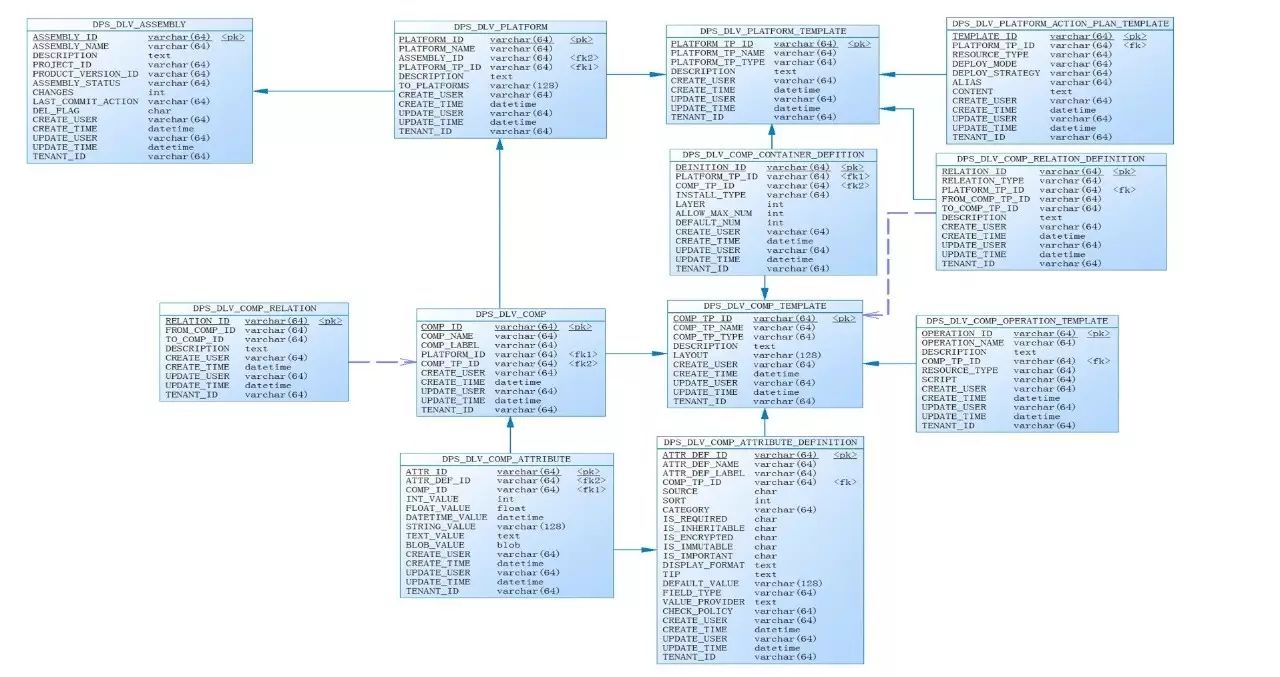
(点击可放大查看)
前面提到,当用户创建Platform时,我们的DevOps平台提供可选的Platform Template,Platform Template定义了其中可以包含的组件类型(Component Template)等信息。也就是说,我们的平台提供了一种基于最佳实践的方式,帮助用户完成系统的架构设计。不仅如此,通过对Platform Template/Component Template等相关数据准备的介绍,也对以后用户扩展添加新的组件类型,提供了充足依据。基本思路如下:
1)定义不同的系统模版Platform Template(见表DPS_DLV_PLATFORM_TEMPLATE)。系统模版就是我们通过最佳实践的方式提供了一套应用/中间件系统的模版。如tomcat,nginx、springboot、mysql等。
一个Platform Template定义了这个模版中包含的组件模版,定义了组件模版之间的依赖关系(见表DPS_DLV_COM_RELATION_DEFINITION),以及每一种组件类型所在的层以及每一种组件类型允许添加的组件的个数(见表DPS_DLV_COMP_CONTAINER_DEFINITION)。当用户添加一个Platform时,必须要选择一种Platform Template。
2)根据不同的部署模式(单节点、高可用)、不同的目标资源(虚拟机、容器)、不同的部署策略(全新、蓝绿、滚动升级、回滚),一个系统模版会对应到多个执行计划模版 (见表DPS_DLV_PLATFORM_ACTION_PLAN_TEMPLATE)。
3)一个系统由多个组件组成,因此系统模版和组件模版之间也是多对多的关系。例如springboot模版对应的组件模版有:secgroup模版、os模版、jdk模版、java application模版等等。
组件模版Component Template(见表DPS_DLV_COMP_TEMPLATE)以及组件的所有属性(见表DPS_DLV_COMP_ATTRIBUTE_DEFINITION)。组件模版就是组件的元数据,为Platform添加的Component都是源于Component Template。
4)为每个Component Template定义Operation模版(见表DPS_DLV_COMP_OPERATION),以便对单个组件实例进行操作,如restart, repair, stop等。
通过以上4步系统预置的Platform Template和Component Template以及相应的数据,就可以提供给用户添加一个Platform了。这些预置数据也为后面生成部署计划Deploy Plan做好的准备。
2、变量管理
在需求分析中,我们就提出希望一次设计多次部署。但是在设计阶段设置各个组件属性时,并不能确定在不同的部署环境中其值是一致的,并且一个系统的不同组件的属性也可能是共用一个值。这时候我们就需要引入变量管理。变量管理的主要思路如下:
1)设计阶段,为系统定义一些变量(ConfigMeta)并设置一个默认值,如install_dir。然后在设置某个组件属性值时可以用@P{install_dir}来表示。
2)提交设计时,也一同将变量定义作为设计的一部分进行提交。
3)转换阶段,在部署环境中,为每一个变量设置当前环境下的值(ConfigValue)。当创建执行计划时,会将属性@P{install_dir}替换为当前环境的值。
不仅Platform内可以定义变量供该Platform下的Component使用,我们也可以给Assembly定义变量供所有Platform及其组件使用, 形如@A{assembly_var}。
3、设计提交
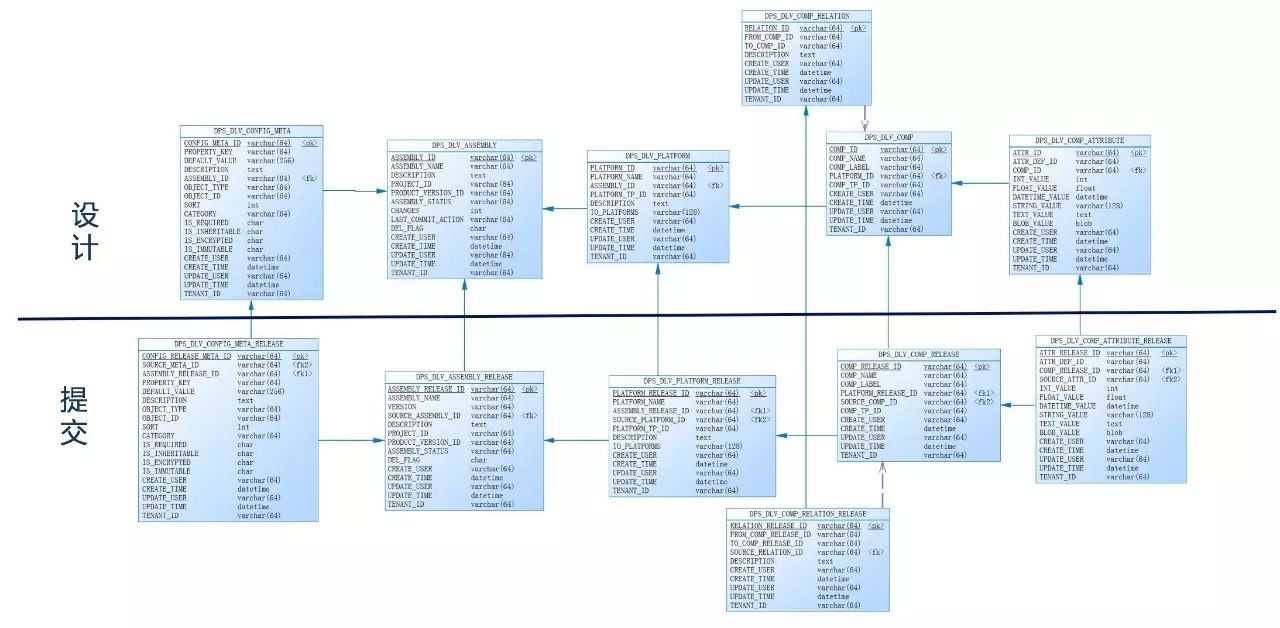
(点击可放大查看)
当用户设计完部署架构、设置每个组件属性及变量后,需要将当前的设计指定好版本进行提交,即归档。只有提交的设计,才能在部署环境中获取的到指定的版本。通过版本化,我们可以设计的不同版本做相关的对比。
上面的表结构是比较清晰的表述。
4、执行计划
根据不同的部署模式(单节点、高可用)、不同的目标资源(虚拟机、容器)、不同的部署策略(全新、蓝绿、滚动升级、回滚),一个系统模版会对应到多个执行计划模版,并且计划模版之间有父子关系。
每一个子执行模版就是一个jenkins pipeline script模版。
当用户在部署环境中选择某个具体系统及部署策略生成相应的执行计划(含子计划)时,每一个子计划的jenkins pipeline script就是将具体的组件属性注入到执行模版中生成的。
另外,为什么需要显示的创建出子计划呢?例如,对于一个高可用的应用,除了要部署具体的应用,还需要更新load balance配置,而这两者之间可能需要加入一些人工活动。所以我们通过显示的创建处子计划,支持用户按子计划一步步的来做。
而jenkins pipeline script的stage几乎都对应到一个具体的组件,具体可以看下图。
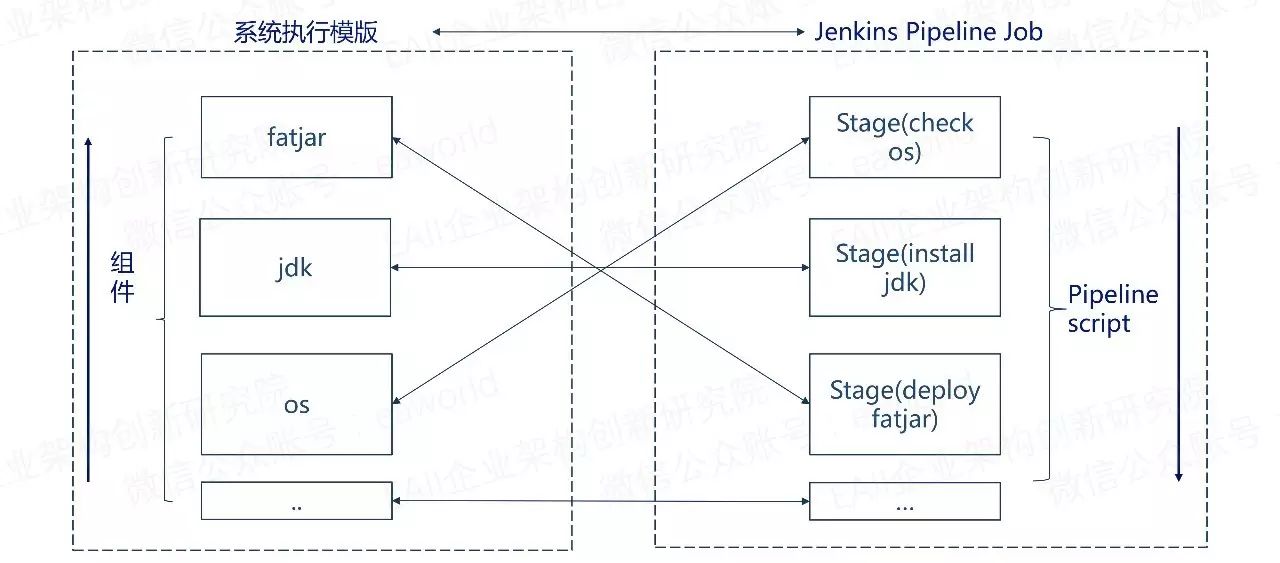
(点击可放大查看)
5、部署策略
前面我们提到了“部署策略”这个词,除了全新部署,我们常见的部署策略有蓝绿发布、滚动升级、灰度发布/金丝雀发布、回滚。下面来看看我们的相应解决方案。每一种部署策略都会有相应的执行计划模版(含子计划)。
蓝绿发布
什么是蓝绿发布?
在发布的过程中用户无感知服务的重启,通常情况下是通过新旧版本并存的方式实现,也就是说在发布的流程中,新的版本和旧的版本是相互热备的,通过切换路由权重的方式(非0即100)实现不同的应用的上线或者下线。
前提条件
双份资源 or 支持双端口模式
负载均衡服务 + 操作API接口
实施方案
第一步,设置系统将要部署的资源列表。
第二步,将新版本部署容器部署到资源列表中。
第三步,调用负载均衡服务的API接口更新负责均衡配置。第四步,更新资源的标签。
考虑到用户可能会手工介入确定是否需要更新负载配置,我们会将第二步、第三步分为两个子执行计划。
滚动升级
什么是滚动升级?
滚动发布,一般是取出一个或者多个服务器停止服务,执行更新,并重新将其投入使用。周而复始,直到集群中所有的实例都更新成新版本。
这种部署方式相对于蓝绿部署,更加节约资源——它不需要运行两个集群、两倍的实例数。我们可以部分部署,例如每次只取出集群的20%进行升级。
前提条件
负载均衡服务 + 操作API 接口
实施方案
第一步,设置滚动升级系数(步进),如20%/n个。
第二步,依次将20%的部署容器移除负载,然后在原资源处部署新版本,然后加入负载。
灰度发布/金丝雀发布
什么是灰度发布/金丝雀发布?
灰度发布是增量发布的一种类型,它的执行方式是在原有软件生产版本可用的情况下,同时部署一个新的版本。同时运行同一个软件产品的多个版本。
其实,灰度发布是滚动升级的一种变体,其实灰度发布是先划分出新版本的路由权重,新版本在真实数据验证通过后,在进行剩余老版本的升级。
前提条件
负载均衡服务 + 操作API 接口
实施方案
第一步,设置新老版本的路由权重,如90%的用户维持使用老版本,10%的用户使用新版本。
第二步,将10%的部署容器移除负载,然后在原资源处部署新版本,然后加入负载。
第三步,待真实数据验证通过后,再进行剩余老版本的滚动升级。
回滚
什么是回滚?
回滚是指将应用/服务回退到上一可用版本,并使之可用。
我们暂时只支持针对蓝绿发布的回滚。
前提条件
新版本是基于蓝绿发布策略完成的部署。
负载均衡服务+操作API接口。
实施方案
更新负载配置
七、总结
本文大致向大家介绍了我们的DevOps平台中自动化部署框架的相关设计,主要简单介绍了实现思路和几个关键点。 其中还有很多细节,比如如何与CMDB集成,如何与各种容器云集成,以及我们实践过程中遇到的各种坑等等,这里不再一一赘述,有问题可在本文文末留言。
如需成为EAii架构研究院会员加入微信群参与架构设计与讨论直播,享受微课堂PPT抢先下载等权益,请留下您的微信号至此公众号eaworld。
关于作者:
许二虎
EAII-企业架构创新研究院 专家委员
现任普元云计算高级工程师。毕业于中国科学技术大学,软件工程硕士。曾任职于群硕软件、科纬迅软件服务、平安健康,具备互联网领域的技术应用经验。在普元云计算平台中的角色是,以靠谱的后端的功底,支撑着整个DevOps业务平台交付。

关于EAWorld
微服务,DevOps,元数据,企业架构原创技术分享,EAii(Enterprise Architecture Innovation Institute)企业架构创新研究院旗下官方微信公众号。
微信号:eaworld,长按二维码关注

本文分享自微信公众号 - EAWorld(eaworld)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。













