

重要链接:
「系列文章目录」
本篇目录
前言
一、缓存:工程思想的产物
二、Web 中的缓存
1.缓存的工作模式
2.缓存的常见问题
三、缓存应用实战
1.Redis 与 Spring Data Redis
2.Redis 安装
3.Spring Data Redis 配置
4.缓存实现
5.验证
小结
前言
大家好,这次过了三个月,再次创下新的记录,大概鸽真的是人类的本性。
不过好在大多数读者看这个教程的目的是做毕业设计,前面的内容都做出来再修修补补一下,老师大概率也不会为难你,所以更新慢也没太大问题。
前两天有读者留言说我写的越来越随意了,但我的直观感受是自己写的越来越艰难。我瞄了一眼被吐槽的那篇文章的数据,貌似收藏和点赞数量都几乎是最高的,看来可能只是觉得代码讲解少吧。
其实真的,贴代码讲代码是最容易的,我可以这样很轻松地写三四十篇文章,但我觉得没有意义。
在这两个月里,我又重新系统地学了一遍软件工程、浏览器工作原理,跟进网络、软件设计、产品方面的课程,并同时对一些技术进行了深入的了解,在这个基础上,我才敢往后推进。
作为一个兴趣使然的假程序员,我想我能告诉大家的最有价值的东西并不在技术细节上,毕竟我身在另一个赛道已经很久了。
我希望你们看到这一篇时,已经把前面说的各种操作、技巧、配置、字段都忘了,这些不重要。
咱们这个项目,缺乏商业价值,架构设计粗糙,代码不够整洁,编程风格混乱,依赖关系复杂,框架过度使用,算法不够高效,安全防范缺失,开发过程随意,缺少测试代码,没有监控措施,缺失关键文档,缺少版本控制。
你说它成功么?并不成功。但是失败么?这套教程目前获得了 70W+ 阅读量,GitHub 仓库将近千星,为我带来了 1W+ 读者里的百分之八十,所以我觉得并不失败。而且正是由于我做到了现在,才知道原来一个项目要考虑这么多的因素,才总结的出如此之多的漏洞与不足。
唯一让我感到遗憾的是没有精力再从头整理一遍,前面的文章还是有很多让人困惑的地方。vue-cli 3.x 出了好久了,很多同学反映前面创建项目报错,还有几个气的骂骂咧咧的,倒是可以理解,我虽然一直说人必须得学会自己解决问题,但毕竟如果入门都入不了的话也没兴趣解决问题对不对。
说了这么多,关键是想让大家明白,我真的不是因为女朋友给我买了 switch,当上了海拉鲁老流氓才混了这么长时间的,玩什么不是玩对不对,怪物猎人它不香么。
。。。
那么根据很久之前的计划以及大家的反馈,这次我们来聊一聊缓存的使用。主要有以下几个关注点:
- 缓存是什么?为什么需要缓存?
- 使用缓存需要注意哪些问题?
- Redis 是什么?
- 针对我们的项目,应该如何使用缓存?
一、缓存:工程思想的产物
缓存一词最初主要指 CPU 与内存之间的高速静态随机存取存储器(SRAM)。
我们知道,CPU 需要频繁从内存中读取指令、数据,但各个硬件的发展是不均衡的,我们当前使用的主流的动态随机存储存取器(DRAM)内存技术无法满足 CPU 高速读取的需求,成为制约计算机运行效率的重要因素之一。
而 SRAM 速度快,但体积大,成本高,就目前来讲,一块 16G 的 SRAM 可能比主板还大,且价格极高,因此短期之内不可能替代 DRAM 成为内存的主流技术选择。
怎么办呢,妥协一下,用块小的 SRAM 放到 DRAM 的内存和 CPU 之间,不占什么地方,也不贵。那放上去有什么用?数据岂不是还要多经过一层 SRAM 才能到 CPU?这样会变快吗?
当然不会更快,但计算机的运行效率确实提升了,这是为什么?因为实际上在一段时间里,一小部分指令或数据会被 CPU 频繁读取,机智的人类通过算法,把这些指令、数据提取出来放到缓存里,这样就能够四两拨千斤,取得明显的效果。
你看,使用缓存不是必须的,如果我们能造出高速、便宜的存储,就没有这么多麻烦了。但在现实中,总会有各种各样的不完美,机会总是稍纵即逝,如果去等待完美的条件,就难以向前迈进。
工程思想的核心,就是权衡与妥协,接受不完美、不确定,通过各种手段把缺陷控制在可以容忍的范围内,在有限的条件下尽可能地完成设定的目标、事业。
缓存是一种工程思想下自然而然的优秀实践,这一实践逐渐被抽象成一种设计思路,在各种受到资源获取开销制约的场景下得到广泛应用。
二、Web 中的缓存
在做项目的过程中,不知道你们有没有感叹过,一个平平无奇的应用,涉及的点实在是太多了。各个点之间需要衔接,要衔接就会有两个层次的不均衡:
- 一是性能的不均衡,包括速率、吞吐量等,造成这种不均衡的原因包括软件、硬件、网络、协议、策略等、位置多个维度
- 二是数据本身活跃性的不均衡,有些数据会被频繁传递,有些很久才被访问一次
基于这两个不平衡,诞生了各种缓存方案。比较常见的有以下几种:
- 浏览器缓存,包括本地的页面资源文件和 DNS 映射
- DNS 服务器上的缓存(IP - 域名映射)
- CDN,利用边缘 Cache 服务器提高访问速度
- ORM 框架提供的缓存,比如 Spring Data JPA 的持久化上下文
- 利用高性能非关系型数据库(如 Redis)提供缓存服务,作为对关系型数据库的补充
不得不说,对成熟的应用来说,一个普通的请求想过了缓存这关还真不容易。
看起来缓存还真是个好东西,到哪都好用。但多用了一个东西,毕竟还是会增加复杂性,复杂性越高越不好控制,我们设计一个软件的架构,就是要让它在够用的前提下尽可能简单,实现简单、控制简单、维护简单。
1.缓存的工作模式
缓存的实际使用方法是有一些规律可循的,我们来简单了解一下常见的几种模式。
Cache-Aside:
最常见的模式,可以翻译为旁路缓存或边缘缓存。缓存作为数据库(或存储)的补充,数据的获取策略是,如果缓存中存在,则从缓存获取,如果不存在,则从数据库获取,并写入缓存。
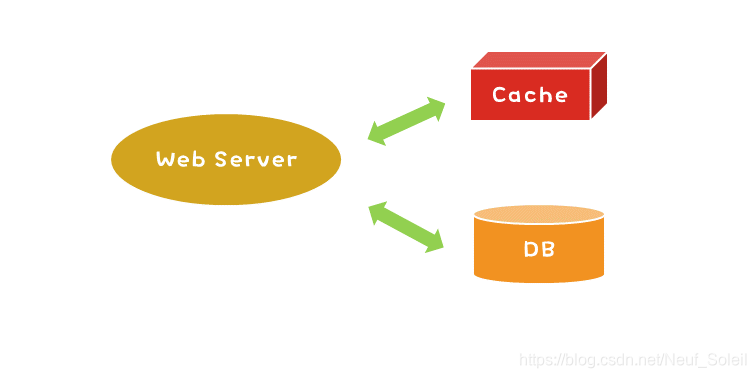
Read-Through:
把数据库藏在缓存背后,一切请求交由缓存响应。也就是说,如果命中缓存,则直接从缓存获取,如果没有命中,则从数据库中查询,写入缓存后再由缓存返回。
应用这种模式,写入缓存的操作会阻塞请求的响应,我觉得其实大部分情况下没有必要使用。
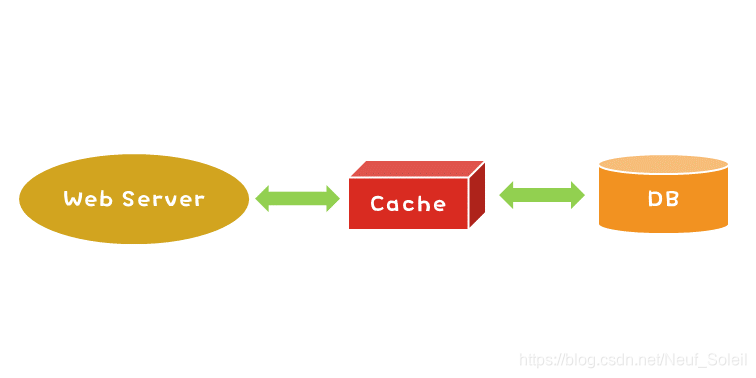
Write-Through:
对于需要动态更新数据的应用来说,仅仅通过读操作触发缓存更新肯定是不够的,如果数据库更新了而缓存迟迟没有更新肯定说不过去。
当更新数据库的数据时,也有两种常见的操作缓存的模式。Write-Through 模式是:请求更新数据,如果该数据在缓存中存在,则先更新缓存,再更新数据库。
Write-Back:
请求更新数据,更新缓存,至于数据库什么时候更新,不一定,有机会再更新,可以攒一波再更新,有缓存在就行。
这种异步的方式一听就有数据不一致的风险,但因为够快,所以在一些要求高并发大吞吐量的系统中比较常见。其实高并发的一个核心解决方案就是缓存,高并发的复杂性很大程度上取决于缓存方案的复杂性。
这些方案具体怎么用其实还是看场景,要配置相应的策略防止出现一些问题。
2.缓存的常见问题
在使用缓存时,我们一般都会考虑以下几个问题:
- 数据一致性问题,缓存的数据与数据库由于各种原因产生差异
- 缓存穿透,明明已经用缓存了,还是有一堆请求杀到了数据库。
- 缓存雪崩,一大批缓存同时过期,一大波请求趁虚而入,如同雪崩一般。
下面我们来聊一聊这三个问题如何应对。
数据一致性问题:
一个系统,如果数据都是不变的,应用 Cache-Aside 模式,可以做到缓存中的数据永远和数据库中一致,需要考虑的就是缓存什么时候过期,或者缓存更新的算法,做到尽可能地找出热点数据即可。
但大部分系统是要更新数据的,数据更新了缓存没有及时更新,有时候没有问题,但在一些场景下不能容忍,比如支付宝,你买了东西一看钱没变,于是疯狂买买买,后来突然一下钱全没了,这谁顶的住对不对。
于是我们在写场景下更新缓存,采用先更数据库再更缓存的模式,比如你买了个煎饼果子,支付宝实际余额从 100 变成了 90,你老婆同时在别的地方用你的支付宝又买了杯豆浆,实际余额变成 85,数据库没问题,但你买煎饼果子时缓存服务卡了一下子,更新操作发生在了豆浆事件的后面,你们俩回家一看查出来的余额是 90,以为白嫖了 5 块钱,但其实还是假象。
其实数据一致性问题还是在并发这个范畴内,整体原则就是分析实际场景,尽可能选择既高效又安全的方案。当然这并不是一件容易的事,如果容易就没有那么多年薪百万的架构师了。
缓存穿透:
引发缓存穿透的情形一般有两种,一是大量查询一个数据库里也没有的数据,这种数据正常不会被缓存,结果每次都要到数据库里兜一圈。那我们可以设置一个规则,数据库没有的数据我们也缓存起来,值设置成空就行了。
另一种情形是,数据库里有这个数据,之前从没人查询过,但突然有那么一瞬间来了一大波请求,缓存根本来不及反应,压力就全都到了数据库上。这种怎么办?两种办法,一是限流,二是预判。
限流好理解,请求少了就反应的过来了。预判怎么预判?你怎么知道哪个数据会被频繁访问?
不好意思,一般还真的知道,一个数据突然被访问的情况,一般是你自己捣鼓出来的什么幺蛾子,比如淘宝要搞双十一,那有些数据一定会被突然频繁访问,这些数据当然能预判个八九不离十。在请求排山倒海般到来之前,先把它填充到缓存里就完事儿了。(这种做法通常称为缓存预热)
缓存雪崩:
其实本质上雪崩和穿透是一类问题,只是出现的阶段不一样,穿透是缓存已经稳定建立起来了,雪崩是缓存突然同时过期了。当然还有一种情况,就是完全还没有缓存的时候,一大波请求涌入。比如缓存没做持久化,结果机房断电了,重启之后就是没有缓存的。
解决方法仍然是限流和缓存预热。其实这些名词也是没意思,奈何总是有人会问,有人会考。
三、缓存应用实战
了解了缓存的基本概念和应用模式,我们来整点实际操作。前端页面的本地缓存已经由浏览器实现了,我们不用管,主要操心一下后端。
你看,前端后端都有缓存,但各自解决问题的边界是不一样的,前端缓存应对的是静态页面资源的访问,本地缓存可以更具体地说是同一用户(终端)的多次访问,而后端缓存更多的考虑多个用户的多次访问,面向的资源主要是数据库里的数据。
对于我们项目的后端呢,我想了半天,觉得没有需要的地方,我们这么简单一应用,也没用户,也没流量,要啥自行车啊?
但为了学习嘛,就强行假设有很多人用咱们做的这个破网站吧。那哪些场景用的比较多,数据库压力比较大呢?应该是前台的图书信息和文章两个部分。
那么用什么来实现缓存呢?目前最常见的做法是用 Redis 来实现。
1.Redis 与 Spring Data Redis
首先我们要记住,Redis 和 MySQL 一样,是一个数据库管理系统,人家不是就为了做缓存的。
Redis ≠ 缓存 ,只是由于这玩意儿现在访问速度快,但又不能完全替代关系型数据库,所以确实适合用来做关系型数据库的缓存,都是形势所迫,说不定哪一天就翻身了。
我们要在应用中操纵这个数据库,自然也需要与关系型数据库相似的访问方法。MySQL 我们用 Spring Data JPA,Redis 我们就用 Spring Data Redis。
其实在此之前,Java 访问 Redis 主要是通过 Jedis 和 Lettuce 两种由不同团队开发的客户端(提供访问、操作所需的 API),Jedis 比较原生,Lettuce 提供的能力更加全面。
Spring Data Redis 是在 Lettuce 的基础上做了一些封装,与 Spring 生态更加贴合,使用起来也更简便。
2.Redis 安装
官方下载地址:https://redis.io/download
正常 Redis 只提供 Linux 版本,Windows 版本由微软提供,版本只到 3.2.100,在 2016 年以后就没有再更新过。下载地址为:https://github.com/microsoftarchive/redis/releases
Linux 下可以用 docker 安装镜像,更下方便。我下载的是 Windows 版,但不推荐大家使用。
3.Spring Data Redis 配置
这部分内容可以参考 @MacroZheng 的 「Spring Data Redis 最佳实践!」
首先是在 pom.xml 中添加依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- redis 连接池 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
再在 application.properties 中配置一些参数,常用的有以下几种:
spring.redis.host=localhost
spring.redis.port=6379
# Redis 数据库索引(默认为 0)
spring.redis.database=0
# Redis 服务器连接密码(默认为空)
spring.redis.password=
#连接池最大连接数(使用负值表示没有限制)
spring.redis.lettuce.pool.max-active=8
# 连接池最大阻塞等待时间(使用负值表示没有限制)
spring.redis.lettuce.pool.max-wait=-1
# 连接池中的最大空闲连接
spring.redis.lettuce.pool.max-idle=8
# 连接池中的最小空闲连接
spring.redis.lettuce.pool.min-idle=0
# 连接超时时间(毫秒)
spring.redis.timeout=2000
# redis 只用作缓存,不作为 repository
spring.data.redis.repositories.enabled=false
Java 中的对象存储进 Redis 之前需要进行序列化,默认为字节数组。我们为了方便解析,可以将其配置为 JSON 格式。可以创建一个 RedisConfig 类,代码如下:
package com.gm.wj.config;
import com.fasterxml.jackson.annotation.JsonAutoDetect;
import com.fasterxml.jackson.annotation.PropertyAccessor;
import com.fasterxml.jackson.databind.ObjectMapper;
import org.springframework.cache.annotation.CachingConfigurerSupport;
import org.springframework.cache.annotation.EnableCaching;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.cache.RedisCacheConfiguration;
import org.springframework.data.redis.cache.RedisCacheManager;
import org.springframework.data.redis.cache.RedisCacheWriter;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.Jackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.RedisSerializationContext;
import org.springframework.data.redis.serializer.RedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
import java.time.Duration;
@EnableCaching
@Configuration
public class RedisConfig extends CachingConfigurerSupport {
public static final String REDIS_KEY_DATABASE="wj";
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisSerializer<Object> serializer = redisSerializer();
RedisTemplate<String, Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
redisTemplate.setKeySerializer(new StringRedisSerializer());
// 设置 redisTemplate 的序列化器
redisTemplate.setValueSerializer(serializer);
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(serializer);
redisTemplate.afterPropertiesSet();
return redisTemplate;
}
@Bean
public RedisSerializer<Object> redisSerializer() {
//创建JSON序列化器
Jackson2JsonRedisSerializer<Object> serializer = new Jackson2JsonRedisSerializer<>(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
objectMapper.enableDefaultTyping(ObjectMapper.DefaultTyping.NON_FINAL);
serializer.setObjectMapper(objectMapper);
return serializer;
}
@Bean
public RedisCacheManager redisCacheManager(RedisConnectionFactory redisConnectionFactory) {
RedisCacheWriter redisCacheWriter = RedisCacheWriter.nonLockingRedisCacheWriter(redisConnectionFactory);
//设置Redis缓存有效期为1天
RedisCacheConfiguration redisCacheConfiguration = RedisCacheConfiguration.defaultCacheConfig()
.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(redisSerializer())).entryTtl(Duration.ofDays(1));
return new RedisCacheManager(redisCacheWriter, redisCacheConfiguration);
}
}
上面的文章里介绍了如何通过注解使用缓存,我们一般希望能够更灵活地运用,因此通常选用 RedisTemplate 来实现自由操作。
RedisTemplate 是 Spring Data Redis 提供的一个完成 Redis 操作、异常转换和序列化的类,我们可以类比 JdbcTemplate 去使用它。官方文档地址:
docs.spring.io - RedisTemplate
4.缓存实现
下面我们来尝试实现为项目的图书馆页面和笔记本(文章)页面加上缓存。首先编写一个 Service 类,封装我们将要用到的操作。
package com.gm.wj.redis;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.redis.core.*;
import org.springframework.stereotype.Service;
import java.util.Set;
import java.util.concurrent.TimeUnit;
@Service
public class RedisService {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
// 设置带过期时间的缓存
public void set(String key, Object value, long time) {
redisTemplate.opsForValue().set(key, value, time, TimeUnit.SECONDS);
}
// 设置缓存
public void set(String key, Object value) {
redisTemplate.opsForValue().set(key, value);
}
// 根据 key 获得缓存
public Object get(String key) {
return redisTemplate.opsForValue().get(key);
}
// 根据 key 删除缓存
public Boolean delete(String key) {
return redisTemplate.delete(key);
}
// 根据 keys 集合批量删除缓存
public Long delete(Set<String> keys) {
return redisTemplate.delete(keys);
}
// 根据正则表达式匹配 keys 获取缓存
public Set<String> getKeysByPattern(String pattern) {
return redisTemplate.keys(pattern);
}
}
注意这里存储对象均被视为 Object,如果存储对象为 String,可以进一步使用 StringRedisTemplate 来实现更贴合字符串的处理方法。
接下来,就可以在具体的 Service 里添加缓存的处理逻辑。
BookService:
针对获取图书列表的请求,可以先根据设置的 key 查询缓存,如果有则直接从缓存里获取,如果没有则从数据库查询并写入缓存。
public List<Book> list() {
List<Book> books;
String key = "booklist";
Object bookCache = redisService.get(key);
if (bookCache == null) {
Sort sort = new Sort(Sort.Direction.DESC, "id");
books = bookDAO.findAll(sort);
redisService.set(key, books);
} else {
books = CastUtils.objectConvertToList(bookCache, Book.class);
}
return books;
}
注意从缓存拿回来的是 Object ,我们需要编写一个方法把它转换为 List:
public static <T> List<T> objectConvertToList(Object obj, Class<T> clazz) {
List<T> result = new ArrayList<T>();
if(obj instanceof List<?>)
{
for (Object o : (List<?>) obj)
{
result.add(clazz.cast(o));
}
return result;
}
return null;
}
如果我们对图书的信息进行了修改,需要对缓存也进行相应的修改。因为我们缓存的粒度是整个列表,所以在对数据库进行增删改操作时可以直接将书籍列表的缓存全部清除。
这样其实避免了上面说的缓存更新顺序不一致的问题,我就硬删除,先删后删缓存里结果都一样。
public void addOrUpdate(Book book) {
redisService.delete("booklist");
bookDAO.save(book);
}
public void deleteById(int id) {
redisService.delete("booklist");
bookDAO.deleteById(id);
}
问题还是来了,即使在理想的情况下,数据库和缓存的操作都不会失败,假如我在后台删了一本书,缓存被清除了,数据库还没来得及更新,这个节骨眼上有用户访问了一下,结果又拿到了旧的数据还写入了缓存,那下次清除缓存前用户拿到的全是旧数据。
如果我先改数据库再删缓存呢?
public void addOrUpdate(Book book) {
bookDAO.save(book);
redisService.delete("booklist");
}
public void deleteById(int id) {
bookDAO.deleteById(id);
redisService.delete("booklist");
}
还是不妥,虽然前面没删缓存,但假如缓存先自然失效了,用户的访问还是会触发缓存写入操作,此后极短时间内我们又更新了书籍,这两个事件是异步的,我们无法得知缓存写入何时能够完成,如果是在缓存删除之后,那缓存中就还是会长期存在旧的数据。
此外,如果前面不删缓存,有那么一丢丢的时间,数据库更新了而缓存没有更新,用户还是会拿到旧的数据。
前后删都不行,怎么办?
又有人提出了 “延时双删” 策略,就是先清除缓存,在更新数据库后,等一段时间,再去第二次执行删除操作。这样,用户拿到旧库的数据,并且在第二次删除缓存之后才触发缓存更新的概率就比较低。这个时间怎么把握呢?可以测试、估算,没有一个准数。这个过程最好设置成异步的,以免阻塞正常操作。
在这个等待的过程中,还是可能出现有用户读到旧数据的缓存的情况,脑壳疼。。。
现实中还有很多更合理高效的方案,但我估计都不那么完美,我们只能根据实际需要,在合理的成本范围内做出选择。
OK,最后再贴一下为文章设置缓存的代码:
package com.gm.wj.service;
import com.gm.wj.dao.JotterArticleDAO;
import com.gm.wj.entity.JotterArticle;
import com.gm.wj.redis.RedisService;
import com.gm.wj.util.MyPage;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Sort;
import org.springframework.stereotype.Service;
import java.util.Set;
@Service
public class JotterArticleService {
@Autowired
JotterArticleDAO jotterArticleDAO;
@Autowired
RedisService redisService;
// MyPage 是自定义的 Spring Data JPA Page 对象的替代
public MyPage list(int page, int size) {
MyPage<JotterArticle> articles;
// 用户访问列表页面时按页缓存文章
String key = "articlepage:" + page;
Object articlePageCache = redisService.get(key);
if (articlePageCache == null) {
Sort sort = new Sort(Sort.Direction.DESC, "id");
Page<JotterArticle> articlesInDb = jotterArticleDAO.findAll(PageRequest.of(page, size, sort));
articles = new MyPage<>(articlesInDb);
redisService.set(key, articles);
} else {
articles = (MyPage<JotterArticle>) articlePageCache;
}
return articles;
}
public JotterArticle findById(int id) {
JotterArticle article;
// 用户访问具体文章时缓存单篇文章,通过 id 区分
String key = "article:" + id;
Object articleCache = redisService.get(key);
if (articleCache == null) {
article = jotterArticleDAO.findById(id);
redisService.set(key, article);
} else {
article = (JotterArticle) articleCache;
}
return article;
}
public void addOrUpdate(JotterArticle article) {
jotterArticleDAO.save(article);
// 删除当前选中的文章和所有文章页面的缓存
redisService.delete("article" + article.getId());
Set<String> keys = redisService.getKeysByPattern("articlepage*");
redisService.delete(keys);
}
public void delete(int id) {
jotterArticleDAO.deleteById(id);
// 删除当前选中的文章和所有文章页面的缓存
redisService.delete("article:" + id);
Set<String> keys = redisService.getKeysByPattern("articlepage*");
redisService.delete(keys);
}
}
这里我就直接后删缓存了,不多费劲。这里注意 Spring Data JPA 的 Page 对象无法被反序列化,因为它的实现类 PageImpl 没有空参构造器。因此我们需要自定义一个 MyPage 类:
package com.gm.wj.util;
import org.springframework.data.domain.Page;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Iterator;
import java.util.List;
public class MyPage<T> implements Iterable<T>, Serializable {
private static final long serialVersionUID = -3720998571176536865L;
private List<T> content = new ArrayList<>();
private long totalElements;
private int pageNumber;
private int pageSize;
private boolean first;
private boolean last;
private boolean empty;
private int totalPages;
private int numberOfElements;
public MyPage() {
}
//只用把原来的page类放进来即可
public MyPage(Page<T> page) {
this.content = page.getContent();
this.totalElements = page.getTotalElements();
this.pageNumber = page.getPageable().getPageNumber();
this.pageSize = page.getPageable().getPageSize();
this.numberOfElements = page.getNumberOfElements();
}
//是否有前一页
public boolean hasPrevious() {
return getPageNumber() > 0;
}
//是否有下一页
public boolean hasNext() {
return getPageNumber() + 1 < getTotalPages();
}
//是否第一页
public boolean isFirst() {
return !hasPrevious();
}
//是否最后一页
public boolean isLast() {
return !hasNext();
}
//获取内容
public List<T> getContent() {
return Collections.unmodifiableList(content);
}
//设置内容
public void setContent(List<T> content) {
this.content = content;
}
//是否有内容
public boolean hasContent() {
return getNumberOfElements() > 0;
}
//获取单页大小
public int getPageSize() {
return pageSize;
}
//设置单页大小
public void setPageSize(int pageSize) {
this.pageSize = pageSize;
}
//获取全部元素数目
public long getTotalElements() {
return totalElements;
}
//设置全部元素数目
public void setTotalElements(long totalElements) {
this.totalElements = totalElements;
}
//设置是否第一页
public void setFirst(boolean first) {
this.first = first;
}
// 设置是否最后一页
public void setLast(boolean last) {
this.last = last;
}
//获取当前页号
public int getPageNumber() {
return pageNumber;
}
//设置当前页号
public void setPageNumber(int pageNumber) {
this.pageNumber = pageNumber;
}
//获取总页数
public int getTotalPages() {
return getPageSize() == 0 ? 1 : (int) Math.ceil((double) totalElements / (double) getPageSize());
}
//设置总页数
public void setTotalPages(int totalPages) {
this.totalPages = totalPages;
}
//获取单页元素数目
public int getNumberOfElements() {
return numberOfElements;
}
//设置单页元素数目
public void setNumberOfElements(int numberOfElements) {
this.numberOfElements = numberOfElements;
}
//判断是否为空
public boolean isEmpty() {
return !hasContent();
}
//设置是否为空
public void setEmpty(boolean empty) {
this.empty = empty;
}
//迭代器
@Override
public Iterator<T> iterator() {
return getContent().iterator();
}
}
唉,还是这么多代码,到时候报错多了又得有人喷我,幸亏我一直比较皮实,心态还算可以。
5.验证
以 Windows 为例,打开缓存服务(cmd 进入缓存文件夹,执行 redis-sever),显示界面如下:
打开项目,可以在 application.properties 中配置一条语句,显示后端执行的 sql 命令:
spring.jpa.properties.hibernate.show_sql=true
运行项目,访问文章页面、图书馆页面、点击最上面的文章。
这时,控制台显示了一些语句
可以再启动一个终端,进入 redis 目录输入 redis-cli 打开客户端,输入 keys * 查看保存的键
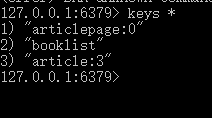
可以看到,第 1 页(JPA 分页默认第一页为 0)、图书列表、第三篇文章(逆序第一篇)被添加进了 Redis 里。
之后,我们再刷新图书馆、笔记本页面或者访问第一篇文章时,sql 语句就不会再显示了。
不知道大家是否还记得前面提到过的 JPA 持久化上下文,实际上,就算输出了这些指令,也不会真的去查询数据库,而是复用之前已经查询到的对象。那为什么还要用 Redis 呢?其实一开始我也说了,真的没有必要。
当然,这只是因为我们的项目结构比较简单。假如我们想把缓存服务部署在别的服务器上,持久化上下文就无法生效了。或者我想使用更灵活的算法,比如只缓存比较活跃的数据,而不是来者不拒,就还是需要有更强大的能力支持。
小结
这篇文章说的东西比较多,稍微做个总结吧。
不用记得太多,下面几句话就够了:
- 缓存是工程思想的产物,是解决不对称问题的一种优秀实践,并得到了广泛应用
- 缓存的引入会提高项目复杂度,要综合取舍使用方案
- Redis 不是缓存,但可以实现缓存服务
下一篇打算唠唠关于单元测试方面的东西。此外,我准备背地里偷偷优化一下前面的文章,不过你们都看到这儿了,也没必要回头再去找哪些地方改了,向前看就好了。
之前开玩笑说这个教程能写到退休,但我仔细想了一下,还是尽快地收个尾吧,都两年了,再过去两年,可能教程里用的技术都过时百分之八十了。
这个系列完结后,我会多写一些偏理论的文章。我干的工作比较杂,比起深入钻研一个技术点,可能还是更适合帮助大家了解一个行业、一个生态的全貌。
各位放心,我不会再鸽这么长时间了,那俩垃圾游戏已经被我打通关了,DLC 什么的等我涨工资了再买吧。
2020 都不容易,送给大家一句话,要敢于做困难事,坚持做困难事,困难是人进步的源泉,总有一天你会发现,自己变秃了,也变强了。
总有人觉得一年不如一年,但我始终认为我们就身处在最好的时代,风起云涌,无限可能。












