
在 Web 开发中,解析 HTML 是一个常见的任务,特别是当我们需要从网页中提取数据或操作 DOM 时。掌握 Node.js 中解析 HTML 的各种方式,可以大大提高我们提取和处理网页数据的效率。本文将介绍如何在 Node.js 中解析 HTML。
基本概念
HTML 解析是指将 HTML 文本转换为可操作的数据结构,通常是 DOM(文档对象模型)。DOM 是一个树状结构,表示了网页的结构和内容,允许我们使用 JavaScript 操作和修改网页。
常用的 HTML 解析方法
以下是在 Node.js 中常用的几种 HTML 解析方法:
1.Cheerio:Cheerio 是一个类似于 jQuery 的库,它可以在服务器端使用 CSS 选择器来解析 HTML 并操作 DOM。它适用于解析静态 HTML 页面。
2.jsdom:jsdom 是一个在 Node.js 中模拟 DOM 环境的库。它能够解析和操作 HTML,同时还支持模拟浏览器环境中的许多特性,如事件处理和异步请求。
3.htmlparser2:htmlparser2 是一个快速的 HTML 解析器,它能够将 HTML 文档解析成 DOM 节点流。它通常用于处理大型 HTML 文档或流式数据。
实践案例:使用 Cheerio 解析 HTML
以下是一个使用 Cheerio 解析 HTML 的实际案例,其中包含基本的路由与请求处理。确保你的开发环境中已经安装了 Node.js 和 npm。
1、首先,创建一个新的文件夹,并在该文件夹中运行以下命令初始化项目:
npm init -y2、安装所需的依赖库:
npm install express cheerio axios3、创建一个名为 index.js 的文件,然后编写以下代码:
const express = require('express');
const axios = require('axios');
const cheerio = require('cheerio'); // 引入 cheerio 库,用于解析 HTML
const app = express();
const PORT = 3000;
app.get('/', async (req, res) => {
try {
// 使用 Axios 发起 GET 请求获取网页的 HTML 内容
const response = await axios.get('https://apifox.com/blog/mock-manual/'); // 替换为你想要解析的网页 URL
const html = response.data; // 获取响应中的 HTML 内容
const $ = cheerio.load(html); // 将 HTML 文本传递给 cheerio,创建一个类似于 jQuery 的对象
// 使用 cheerio 对象的选择器来获取网页标题,并提取文本内容
const title = $('title').text();
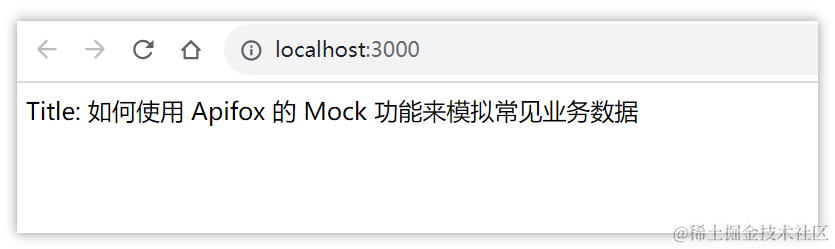
res.send(`Title: ${title}`); // 将标题作为响应发送给客户端
} catch (error) {
console.error(error);
res.status(500).send('An error occurred'); // 发生错误时发送错误响应
}
});
app.listen(PORT, () => {
console.log(`Server is running on port ${PORT}`); // 启动服务器并监听指定端口
});在上述代码中,注释解释了每个关键步骤的作用:
- 通过
axios.get()发起 GET 请求,获取网页的 HTML 内容。 - 使用 Cheerio 的
$ = cheerio.load(html)创建了一个可用于选择 DOM 元素的 Cheerio 对象。 - 通过
$()使用类似于 jQuery 的选择器,获取<title>元素的文本内容。 - 最后,将提取的标题作为响应发送给客户端。在这个案例中,我们使用 Express 来创建一个简单的服务器,当访问根路由时,我们使用 Axios 获取网页的 HTML 内容,然后使用 Cheerio 解析并提取网页标题。在浏览器或 API 工具中访问
http://localhost:3000/,你将看到响应。
提示、技巧与注意事项
- 在使用 Cheerio、jsdom 或 htmlparser2 时,务必了解它们的文档和用法,以充分利用其功能。
- 当解析复杂的动态页面时,考虑使用模拟浏览器行为的库,如 Puppeteer。
使用接口工具调试后端接口
以 Apifox 为例,Apifox = Postman + Swagger + Mock + JMeter,Apifox 支持调试 http(s)、WebSocket、Socket、gRPC、Dubbo 等协议的接口,并且集成了 IDEA 插件。在后端人员写完服务接口时,测试阶段可以通过 Apifox 来校验接口的正确性,图形化界面极大的方便了项目的上线效率。
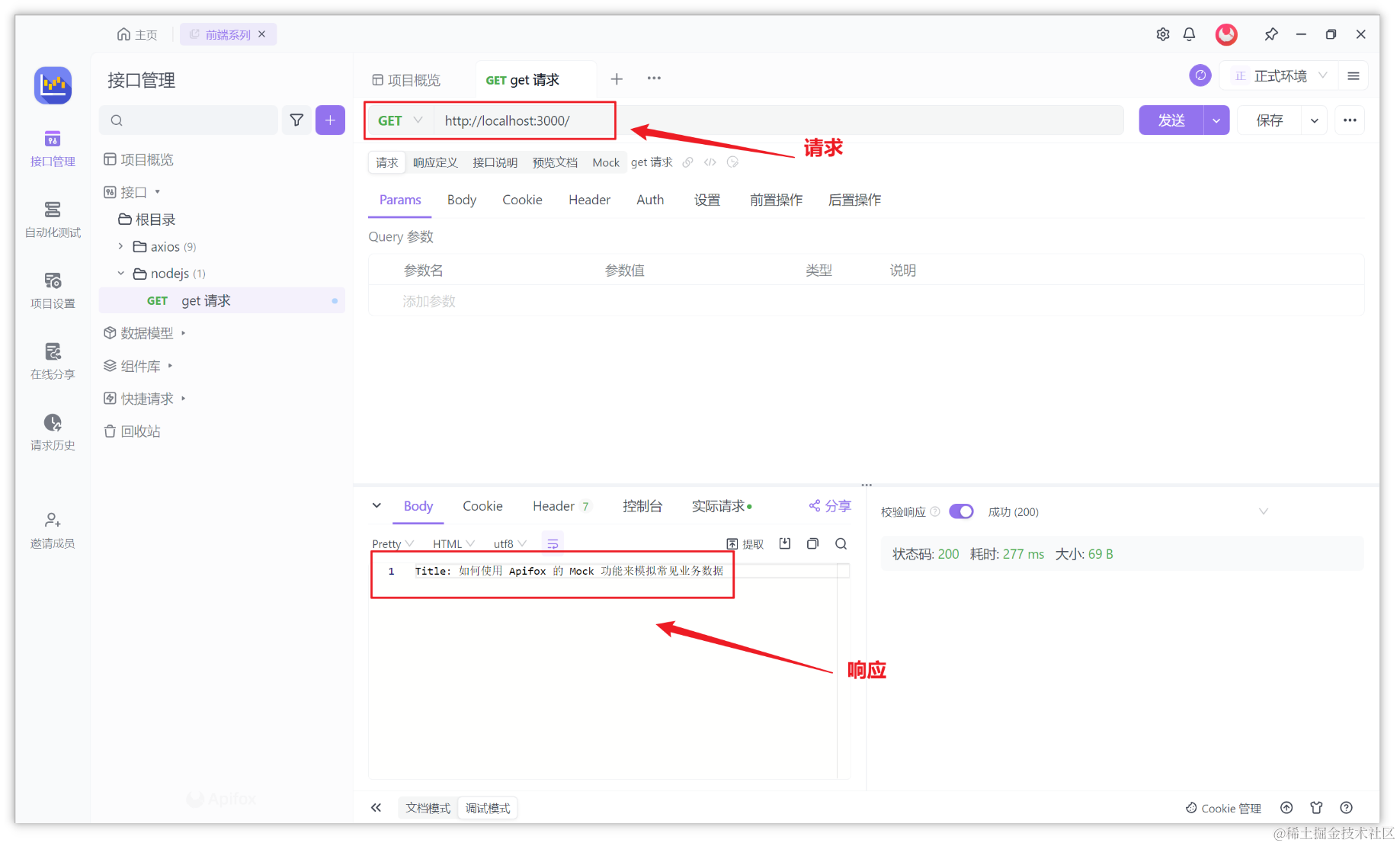
在本文的例子中,就可以通过 Apifox 来测试接口。新建一个项目后,在项目中选择 “调试模式” ,填写请求地址后即可快速发送请求,并获得响应结果,上文的实践案例如图所示:
总结
Node.js 提供了多种方法来解析 HTML,包括 Cheerio、jsdom 和 htmlparser2。选择适合你需求的库,可以轻松地操作和提取网页内容。
知识扩展:
参考链接:
- Cheerio 官方文档:https://cheerio.js.org/
- jsdom GitHub 仓库:https://github.com/jsdom/jsdom
- htmlparser2 GitHub 仓库:https://github.com/fb55/htmlparser2








