
在基于激光的自动驾驶或者移动机器人的应用中,在移动场景中提取单个对象的能力是十分重要的。因为这样的系统需要在动态的感知环境中感知到周围发生变化或者移动的对象,在感知系统中,将图像或者点云数据预处理成单个物体是进行进一步分析的第一个步骤。
在这篇文章中就提出了一种十分高效的分割方法。首先是将扫描到的点云移除平面处理,然后移除平面后一定范围内的点云数据分割成不同的对象。该论文的是集中解决了在很小的计算量的条件下,能够在大多数系统上做到高效的分割。避免了直接对3D点云的计算,并直接在2.5D 的深度图像上进行操作。此方案能够很好的解决处理稀疏的3D点云数据。作者使用了新型Velodyne VLP-16扫描仪,并且代码是在C++和ROS中实现了这种方法,并且代码是开源的,这种方法可以做到使用单核CPU以及高于传感器的帧运行速率运行,能够产生高质量的分割结果。

左图:使用Velodyne VLP-16扫描仪得到的稀疏3D点云数据分割后生成的对象(如人,车和树)。 不同的颜色对应不同的分割结果。 右:用于实验的Clearpath Husky机器人。
在3D激光点云数据中分离单个对象是移动机器人或自动驾驶车辆自主导航的重要任务。 在未知环境中航行的自动驾驶车辆面临着对其周围环境进行推理的复杂任务。,在拥有汽车和行人的繁忙街道上,地图可能受到环境动态性质导致的错误数据关联的影响。 在扫描配准和映射过程中,能够更好地推理此类对象并忽略可能的动态对象的关键步骤是将3D点云数据分割为不同的对象,以便可以单独跟踪它们
所以本论文很重要的贡献是将实现快读高效且稳健的3D稀疏点云的分割。(本人亲自测试,真的很快,我的电脑的配置真的很菜,但是运行起来都超快)在移动的CPU上都可以处理超过70HZ(64线)或者250HZ的(16线)的Velodyne传感器。
**地面去除 **
在进行分割之前,需要从扫描的点云数据中移除地面。这种地面移除的方法,只是把低于车辆高度的3D点移除。这种方法在简单的场景中起作用,但是如果在车辆的俯仰或者侧倾角不等于零或者地面不是完美的平面。则会失败。但是可以使用RANSAC的平面拟合的方法改善情况。
激光雷达的会提供每个激光束的距离值,时间戳以及光束的方向作为原始数据。这使得我们可以直接将数据转换为深度图像。图像中的行数由垂直方向上的光束的数量定义,比如对于Velodyne扫描仪,有16线,32线以及64线,而图像的列数有激光每360度旋转得到的距离值。这种虚像的每个像素存储了传感器到物体之间的距离,为了加速计算甚至可以考虑在需要时将水平方向上的多个读数组合成一个像素。
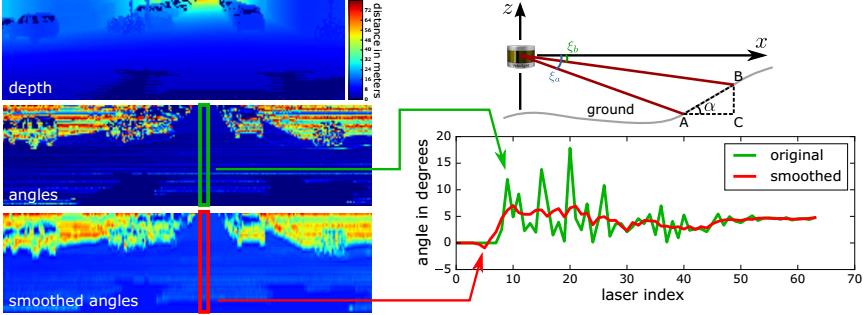
左上角:深度图像的一部分。 左中:通过显示α角度生成的图像。 左下:应用Savitsky-Golay平滑后的角度。
右上角:α角的图示。 右下图:左图中标记的α角度列的平滑图示。
使用上述生成的和成图像来处理而不是直接处理计算3D点云,可以有效的加速处理速度,对于其他的不提供距离值的扫描仪也可以将3D点云投影到圆柱图像上,计算每个像素的欧几里得距离,仍然可以使用该论文提出的方法。
为了识别地面,这里面有三个假设:
1, 假设传感器是大致安装在水平移动基座上。
2, 假设地面的曲率很低。
3, 移动机器人或者车辆至少在深度图像上最低行的像素观测地平面
在假设成立的条件下,首先将深度图像的每一列(c)像素的距离值(R)转化为角度值 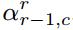 这些角度表示了连接两点的倾斜角度。
这些角度表示了连接两点的倾斜角度。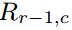 和
和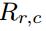 分别代表在该行相邻的深度值。知道连续垂直的两个单个激光束深度值,可以使用三角规则计算角度α,如下所示:
分别代表在该行相邻的深度值。知道连续垂直的两个单个激光束深度值,可以使用三角规则计算角度α,如下所示:
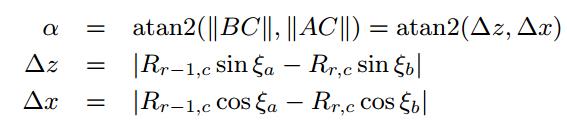
其中ξa和ξb是对应于行r-1和r的激光束的垂直角,由于每个α计算需要两个深度值,所以生成的角度图大小比深度图范围的行数小1.这里假设吧这些所有的角度表示为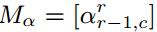 ,表示为在r行和c列(行和列)坐标上的角度值。
,表示为在r行和c列(行和列)坐标上的角度值。

地面识别算法。

根据上述算法得出的地面,地面标记为浅蓝色。
但是由于激光雷达也是有误差点的,所以这里也是需要处理一些在深度范围内的离群点,具体可查看论文。为了达到角度平滑的效果使用了Savitsky-Golay滤波算法对每一个列进行处理。在得到滤波后的角度图后,在这个基础上开始执行地面识别,使用了广度优先搜索将相似的点标记在一起,广度优先搜索(Breadth-first search BFS) 是一种流行的图搜索遍历算法,他从图给定的点开始遍历,并在移动到下一级令居之前首先开始探索直接相邻的节点,在该论文中使用了网格上的N4领域值计算角度差值,以确定矩阵M的两个相邻元素是否满足角度上的约束条件Δa,设置为5°。
使用激光深度图像进行快速有效的分割
传感器的垂直分辨率对分割问题的难度是有着十分重要的影响的,我们需要判断对于相邻点,去判断该激光束是否是被同一物体反射。为了解决激光是否是同一个物体反射的问题,这里是基于角度测量的方法。这种方法的好处是文中反复提及多次这种方法的优点 :首先,我们可以直接在深度图像中利用明确定义的邻域关系,这使得分割问题更容易。 其次,我们避免生成3D点云,这使得整体方法的计算速度更快。
在下图中展示了分割的效果
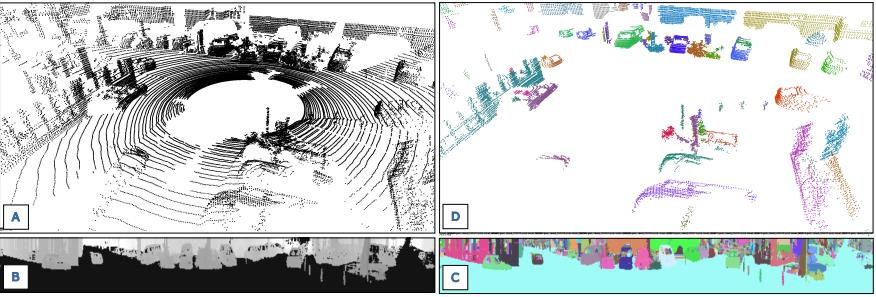
这是使用该分割方案的结果,(A)图是来自Velodynede 点云,(B)根据传感器的原始值创建的深度图像,并且已经将地面点去除了。(C)图是在生成的深度图的基础上执行的分割结果。(D)将分割后的深度图还原为点云,并以不同的颜色显示。
这里详细的解释一下关于如果使用角度约束的方法实现分割的:
如下图所示的一个示例场景,其中两个人在骑自行车者前面彼此靠近地行走,骑自行车者在他们和停放的汽车之间经过。 这里使用的Velodyne VLP-16扫描仪记录了这个场景。 中间的图像展示出了从位于O处的扫描仪测量的两个任意点A和B的结果,表示出了激光束OA和OB。 在不失一般性的情况下,我们假设A和B的坐标位于以O为中心的坐标系中,y轴沿着两个激光束中较长的那一个。 我们将角度β定义为激光束与连接A和B的线之间的角度,该角度一般是远离扫描仪。 在实践中,角度β证明是有价值的信息,可以用来确定点A和B是否位于同一物体上。
那么基于激光的测量值我们是知道第一次测量的距离值OA以及对应的第二次测量值OB,分别将这两次的测量结果标记为d1和d2,那么利用以上信息既可以用下列公式测量角度:
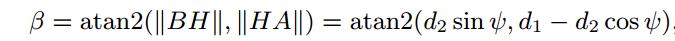
下列图中的右图示出了从场景的俯视图中在xy平面中的计算。 注意,我们可以计算在范围图像中在行或列方向上相邻的点A和B对的角度β。 在第一种情况下,角度对应于行方向上的角度增量,而另一种情况下对应于列方向上的增量。
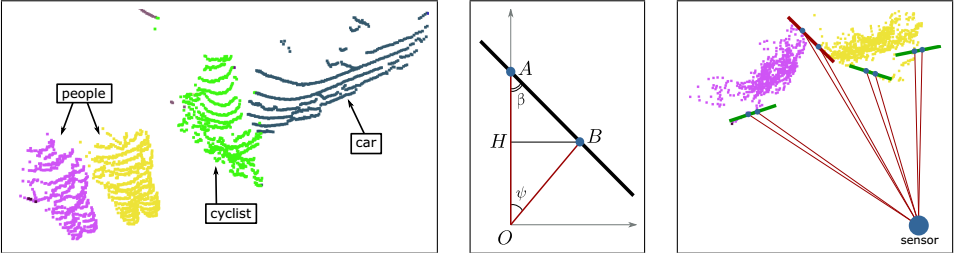
左:示例场景有两个行人,一个骑自行车者和一辆汽车。 中间:假设传感器在O点并且线OA和OB表示两个激光束,则点A和B产生一条线,该线估计对象的表面,如果它们都属于同一对象。 我们基于角度β做出是否为同一物体的判断。 如果β>θ,其中θ是预定阈值,认为这些点代表一个对象。 右图:示例场景中行人的俯视图。 绿线表示β>θ的点,而红线表示低于阈值的角度,因此将对象标记为不同。
基于阈值的β的分割方法在实验评估中进行实验,实际情况可以是被扫描物体是平面的情况,例如墙壁,并且几乎平行于激光束方向。在这种情况下,角度β将很小,因此物体可能被分成多个区段。这基本上意味着如果β小于θ,则难以确定两个点是否源自两个不同的物体,或者仅仅位于几乎平行于波束方向的平面物体上。然而,尽管有这个缺点,我们的实验表明该方法在实践中仍然有用。上述行为很少发生,如果是这样,它通常将会导致特别倾斜的平面物体的过度分割。

以上就是关于去地面后使用的分割算法。可以看得出最重要的一个公式就是β角度值的求解
实验部分
该算法
(i)所有计算都可以快速执行,即使在大约70 Hz的移动CPU的单核上运行,
(ii)可以 将移动机器人获得3D原始数据生成深度数据并分段为有意义的个体
(iii)该方法在稀疏数据上表现良好,例如从16光束Velodyne Puck扫描仪获得的稀疏数据。 在实验中中,使用点云库PCL中来实现的欧几里德聚类。 在所有实验中,我们使用默认参数θ= 10°。

代码开源(https://github.com/PRBonn/depth\_clustering),且小编亲自测试,并附上测试视频,有兴趣者关注微信公众号,
并可以推荐有价值的您觉得比较好的与点云相关的代码或者论文,发送到群主邮箱(dianyunpcl163.com),如此可以一起交流讨论!!
有兴趣的小伙伴可以关注微信公众号,加入QQ或者微信群,和大家一起交流分享吧(该群主要是与点云三维视觉相关的交流分享群,欢迎大家加入并分享)















