

上周六晚,爱奇艺的独家综艺《乐队的夏天》总决赛终于落下了帷幕,虽然决赛过程有些“曲折”,但是我最喜欢的刺猬乐队,仍然凭借自己的硬实力,最终排在第二名!
值得一提的是,这只乐队的吉他手兼主唱也是一位程序员。

刺猬乐队其实成立10多年了,很有实力。
但是在老牌乐队云集的这次比赛中,第一次31进16时仅仅排在第12名,那么他又是如何逆风翻盘的?
让我来复盘一下。
获取数据
获取爱奇艺视频《乐队的夏天》各期节目的下面的评论。
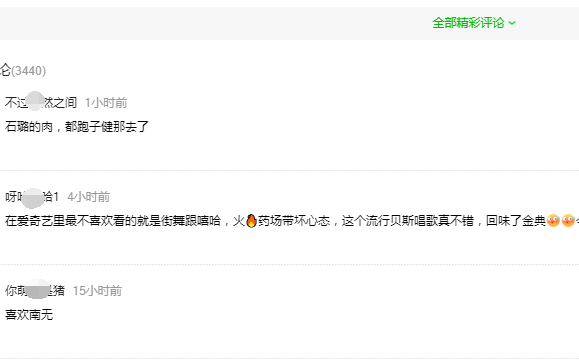
F12,Network查看异步请求XHR,找到评论接口。
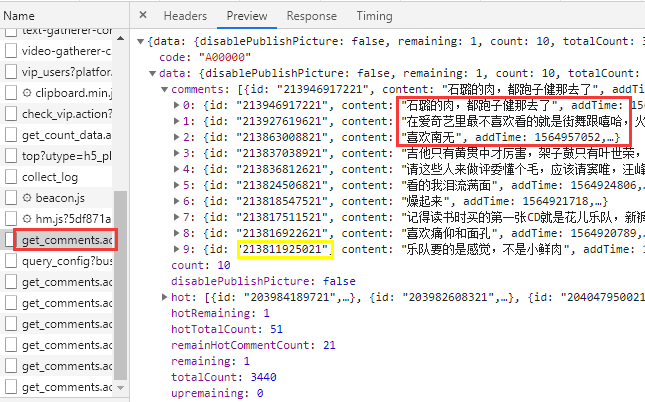
不要以为这里结束了,我们来看一下Request URL
https://sns-comment.iqiyi.com/v3/comment/get_comments.action?
content_id=2537368600&types=time&last_id=213811925021
&business_type=17&agent_type=119&agent_version=9.9.0&authcookie=经过测试,大部分参数都是不变的,只有“content_id”和“last_id”,content_id对于每一期节目是固定的,我们可以自己手动获分析获得。那么last_id是怎么来的?
给大家放一下连续几页的 last_id 看一下吧。
213811925021
213372828221
212600215021
211973666621它们之间并没有什么累加的规律。
放弃的同学可以直接翻到上一张图,标黄的部分“213811925021”,正是我们看到的第一个 last_id 参数。
也就是说每个json里的最后一个 CommentId ,作为下一个url的 last_id 使用。
那么我们需要注意的就是在解析json的过程中需要返回最后一个 CommentId 。
def get_comments(url):
data = []
doc = get_json(url)
jobs=doc['data']['comments']
for job in jobs:
dic = {}
global CommentId
CommentId=jsonpath.jsonpath(job,'$..id')[0] #id
dic['id'] = CommentId
dic['content']=jsonpath.jsonpath(job,'$..content')[0] #评论
add_Time=jsonpath.jsonpath(job,'$..addTime')[0] #时间
dic['addTime'] = stampToTime(add_Time) #转化时间格式
dic['uid']=jsonpath.jsonpath(job['userInfo'],'$..uid')[0] #用户id
dic['uname']=jsonpath.jsonpath(job['userInfo'],'$..uname')[0] #用户名称
dic['gender']=jsonpath.jsonpath(job['userInfo'],'$..gender')[0] #性别
data.append(dic)
return data,CommentId #获得每个json里的最后一个CommentId 剩下的循环爬取就好。
汇总后就获得了2.6万条评论数据。
数据分析
一个乐队名称在每期评论中的提及次数,可以侧面反映这只乐队在这期节目后受到观众喜欢的程度。
#乐队在评论中的提及数
a = {'痛仰':'痛仰', '新裤子':'裤子','猴子军团':'猴子军团','鹿先森':'鹿先森','旺福':'旺福','九连真人':'九连','盘尼西林':'盘尼西林|青霉素',
'反光镜':'反光镜','click15':'click15|#15','海龟先生':'海龟先生','皇后皮箱':'皇后皮箱','面孔':'面孔','和平和浪':'和平和浪','MR.MISS':'MR.MISS|MISS',
'VOGUE5':'VOGUE5|VOGUE','薄荷绿':'薄荷绿','熊猫眼':'熊猫眼','果味VC':'果味VC','BONGBONG':'BONGBONG','醒山':'醒山','刺猬':'刺猬','旅行团':'旅行团',
'麋鹿王国':'麋鹿王国','宇宙人':'宇宙人','黑撒':'黑撒','南无':'南无','斯斯与帆':'斯斯与帆','葡萄不愤怒':'葡萄不愤怒','茶凉粉':'茶凉粉',
'青年小伙子':'青年小伙子','Mr.WooHoo':'Mr.WooHoo|WooHoo',}
for key, value in a.items():
data1[key] = data1['content'].str.contains(value)
staff_count = pd.Series({key: data1.loc[data1[key], 'content'].count() for key in a.keys()}).sort_values()
print(staff_count)
以第一期为例,结果如下。

每期节目的乐队排名都依次降序盘点汇总一下。

结果还蛮惊讶的。
除去第二期他们没有参加,也就是说从第三期开始,刺猬乐队便开始展现实力,几乎每一期都能让观众如此喜欢。

数据可视化
筛选出评论中提到刺猬乐队的评论数据。
data_ciwei= data[data['content'].str.contains('刺猬')]
爬取得到的数据字段其实没几个。
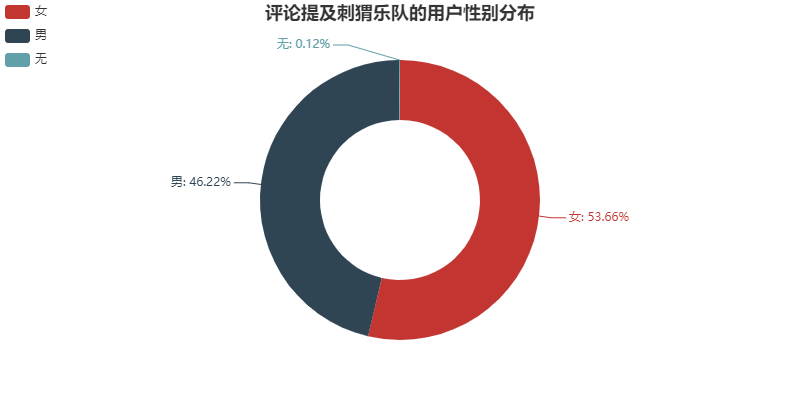
简单看一下喜欢他们的观众的性别分布。
from pyecharts import Pie
# 生成饼图
gender_data = data_ciwei.groupby(['gender'])
gender_cw = gender_data['gender'].agg(['count'])
gender_cw.reset_index(inplace=True)
attr = ['女', '男', '无']
v1 = gender_cw['count']
pie = Pie("评论提及刺猬乐队的用户性别分布", title_pos='center', title_top=0)
pie.add("", attr, v1, radius=[40, 70], label_text_color=None, is_label_show=True, legend_orient="vertical", legend_pos="left", legend_top="%10")
pie使用pyecharts作图。
至于评论的长度之类的就不做分析了。
最后看一下词云,不用jieba分词试试。
from pyecharts import WordCloud
# 生成词云
bj_tag = []
for st in data_ciwei.dropna(subset=['content'])['content']:
bj_tag.extend(st.split(' '))
name, value = WordCloud.cast(Counter(bj_tag))
wordcloud = WordCloud(width=1000, height=500)
wordcloud.add("", name, value, word_size_range=[18, 250])
wordcloud
还是使用pyecharts作图。

可以看出观众对于刺猬乐队的要么是直接夸,要么是和其他强队做对比,总体都是希望它能越来越好。
刺猬总是强调摇滚乐是属于年轻人的,35岁之后可能就不那么摇滚了。
不过35岁之后,他们又将去向哪里呢?
也许等到中年的子健,面对着年轻的乐手们会说:
我不是针对谁,我是说在坐的各位,都没我代码写的好!
本文相关爬虫和数据分析代码:
#下载链接
https://t.zsxq.com/yBAUNb2本文转转自微信公众号凹凸数据原创https://mp.weixin.qq.com/s/SlBrGBJkDKMESCOI1C1zZA,可扫描二维码进行关注:
 如有侵权,请联系删除。
如有侵权,请联系删除。











