通常在面向对象设计中,我们经常听到,高内聚,低耦合,那么到底什么是内聚呢?
内聚究竟是什么?
参考百度百科的解释,内聚的含义如下:
内聚(Cohesion),科学名词,是一个模块内部各成分之间相关联程度的度量。
我自己的理解是:内聚指一个模块内部元素之间的紧密程度
看起来很好理解,但只要深入思考一下,其实没有那么简单。
首先,“模块” 如何理解 ?
一定会有人说,模块当然就是系统里面的 XX 模块了。比如技术社区中的用户管理模块,电子商务中的支付模块...
说的没错,但是在面向对象领域,谈到“内聚”的时候,模块的概念远不止我们通常所理解的 “系统中的某某模块 ” 这么简单
而是可大可小,大到一个子系统,小到一个函数,你都可以理解为内聚里面的 “模块”
所以,你可以用内聚判断一个函数设计的是否合理,一个类设计的是否合理,一个接口设计的是否合理,一个子系统/模块设计的是否合理
其次,“元素” 究竟是什么 ?
有了前面对模块的深入研究以后,元素的含义就比较容易理解了。
- 函数:函数的元素就是 “代码”
- 类/接口:类的元素是 “函数” , “属性”
- 包:包的元素是 “类” , “接口” , “全局数据” 等。
- 模块: 模块的元素是 “包” , “命名空间” 等
最后,“结合” 是什么 ?
结合有 属于的意思,但是 “结合” 这个词容易引起误解,大部分人会想到 “结合” 是 “你中有我,我中有你 ” 。甚至有的人会联想到 “美女和帅哥”
其实这样的理解有点狭隘
我们以类的设计为例:
假如一个类里面的函数都只依赖于其它函数,那么内聚 是最好的,因为 “结合” 的很紧密
但是,反过来说,如果这个类的函数,都不依赖于类的其它函数,我们就一定能说,这个类的内聚性一定不好吗?
答案是:其它也尽然,最常用的就是 CURD 操作类,这几个函数相互之间没有任何依赖关系,但其实这几个函数的内聚性非常高
所以,关于内聚的 结合 的概念,我认为不是非常恰当的描述,那么,究竟什么才是真正的 “内聚” 呢?
答案就是 凝聚力
凝聚力 就是 内聚 的核心思想,抛开面向对象不谈,我们在日常工作生活中,经常会听见
- 你的团队很有凝聚力...
- 领导会说 ,我们要增强团队的凝聚力
- 成功者会说,凝聚力是一个团队成功的基石
面向对象领域的 凝聚力 ,和团队中的 凝聚力 是一样的概念
判断团队凝聚力时,我们关注团队成员是否都专注于团队的目标; 判断面向对象的凝聚力时,我们同样关注元素是否专注于模块的目标,即模块本身的职责
判断团队凝聚力时,我们还会关注团队成员之间是否互相吸引和帮助; 判断面向对象模块凝聚力时,我们同样关注元素间的结合关系
所以,判断一个模块(函数,类,包,子系统)“内聚性”的高低,最重要的是关注模块的元素是否都忠于模块的职责
简单来说就是“不要挂羊头卖狗肉”
内聚的分类
参考维基百科,内聚有 7 种。 以下各种形式的内聚性由低到高列出来
1 偶然内聚
偶然内聚是指模块内部之间的元素之所以被划分在同一模块中,仅仅是因为 巧合 ,下图展示了 偶然内聚
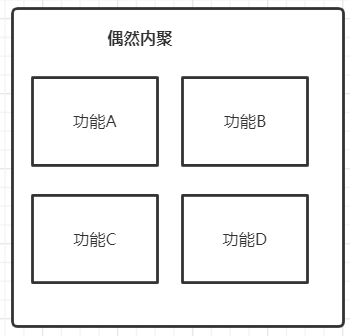
这是内聚性最差的一种内聚,从名字上也能看出来,模块内的元素之间并没有什么关系,元素本身的职责也并不相同
基本上这种内聚形式实际上是没有内聚性的。
可以仔细想一想,我们平时在写代码的过程中或者阅读其它同事的代码中,有没有遇到过这样的代码
举个例子:我们经常写的 utils这样的包。
例如在包 package net.helloworld.utils 模块中,这个包的元素就是里面的 类
那么就有 HtmlUtil 、StringUtil 、UrlUtil 等类
这些类是完全没有关系的,但并不影响我们对这些类的理解和运用
2 逻辑内聚
逻辑内聚是指模块内部的元素之所以被划分在同一模块中,是因为这些元素逻辑上属于同一个比较宽泛的类别
模块的元素逻辑上都属于一个比较宽泛的类别,但实际上这些元素的职责可能是不一样的。
例如,将 “鼠标” 和 “键盘” 划分为 “输入” 类,将 “打印机” , “显示器” 等划分为 “输出” 类。
下图展示了逻辑 “逻辑内聚” , 其中 A1, A2 , A3 , A4 代表 A 类任务的 4 种实现方式
对应到这个样例中, A 就是 “输入” , “鼠标” 就是 A1 , “键盘” 就是 A2
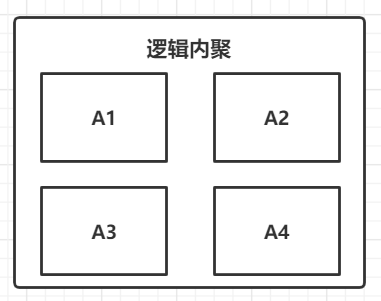
相比于偶然内聚来说,逻辑内聚的元素之间还是有部分凝聚力的,只是这个凝聚力比较弱
但比偶然内聚要强一些
例如,在下面样例中,在包 package net.helloworld.input 即模块 ,每个类是元素。
可以看出, Mouse , Keyboard 都是输入设备的一种,这是它们的凝聚力所在,但这些类本身的职责是完全不同的。
Keyboard.java
package net.helloworld.input;
public class Keyboard {
}Mouse.java
public class Mouse {
}有时候,逻辑内聚与偶然内聚容易混淆。
例如,我们也可以认为 "Utils" 模块里面的各种工具是逻辑内聚的,因为他们都是工具, 这样理解也说得过去,但这种 “内聚性” 比较弱
就像 “鼠标” , “键盘” , “显示器” , “打印机” 都是 “I/O设备” , 而把 “鼠标” 和 “键盘” 划入 “输入设备” , 它们之间的内聚性就更强一些。
3 时间内聚
时间内聚是指模块内部的元素之所以被划分在同一模块中,是因为这些元素在时间上是相近的。
下图明确的展示了 “时间内聚” , 其中 时间 t0 是某个基准点, t1, t2 , t3 , t4 是 t0 发生后的某个时间点。
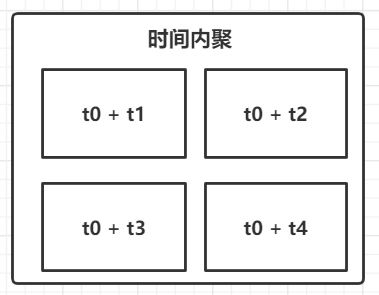
这种内聚一般在函数级别的模块中比较常见,例如,“异常处理” 操作, 一般的异常处理都是“释放资源” (例如 打开的文件 , 连接 ,申请的内存)
“记录日志”,“通知用户” , 那么把这几个处理封装在一个函数中,它们之间的内聚就是 “时间内聚”
示例代码如下:
package net.helloworld.time
public class TimeCohesion {
/**
* handException 函数内部的处理就是 “时间处理”
**/
public void handException(Exception e) {
releaseResource();
log("exception: " + e.getMessage());
notifyUser("Sorry , some error occured !");
}
private void releaseResource(){
//省略具体代码实现
}
private void log(String message){
//省略具体代码实现
}
private void notifyUser(String message){
//省略具体代码实现
}
}
4 过程内聚
过程内聚是指模块内部的元素之所以被划分在同一个模块中,是因为这些元素必须按照固定的 “过程顺序” 进行处理。
如下图所示:
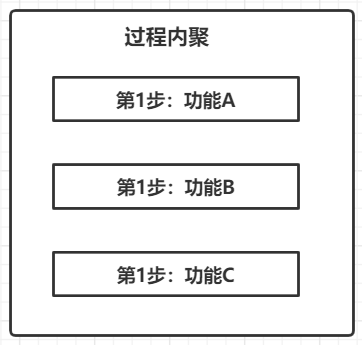
过程内聚和时间内聚比较相似,也是在函数级别的模块中比较常见
例如读写文件操作,一般都是按照下面的顺序进行的
- 判断文件是否存在
- 判断文件是否有权限
- 打开文件
- 读/写文件
那么把这些处理封装在一个函数中,它们之间的内聚就是 “过程内聚”
代码示例如下:
package com.zh.test;
//过程内聚
public class ProceduralCohesion {
/**
* readFile 的实现就是过程内聚
* 与 “时间内聚”不同的是,这些过程是固定的,不能随意调整顺序
* 例如:不能将 read 操作调整到 openFile 操作前
* @param path
*/
public void readFile(String path){
//第1步
checkFileExist(path);
//第2步
checkFilePrivilege();
//第3步
openFile();
//第4步
read();
}
private void checkFileExist(String path) {
//具体代码省略
}
private void checkFilePrivilege() {
//具体代码省略
}
private void openFile() {
//具体代码省略
}
private void read() {
//具体代码省略
}
}虽然过程内聚和时间内聚看起来比较类似,但其实它们有一个非常核心的差别
时间内聚中元素的顺序不是固定的,可以随意调整
而过程内聚中元素的先后顺序是严格要求的,不能轻易调整
例如,在 “时间内聚” 章节中提到的异常处理,我们完全可以调整一下顺序:
package net.helloworld.time;
public class TimeCohesion {
public void handException(Exception e){
notifyUser("Sorry, some error occured!");
log("exception: " + e.getMessage());
releaseResource();
}
private void releaseResource(){
//省略具体代码
}
private void notifyUser(String msg) {
//省略具体代码
}
private void log(String msg){
//省略具体代码
}
}
5 信息内聚
信息内聚是指模块内的元素之所以被划分在同一模块中,是因为这些元素都操作相同的数据
信息内聚还有一个名称叫作 “Communicational cohesion” , 翻译过来就是 “通信内聚”
如下图所示:
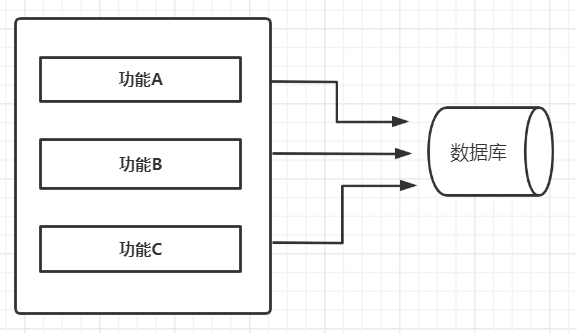
信息内聚最典型的例子莫过于 “增 , 删, 改 , 查” 某个数据了
以常见的学生管理系统为例,学生信息的 “增,删,改,查” 操作都是操作学生的信息。
示例代码如下:
/**
* InformationCohesion 类里面的 add/delete/modify/get 就是信息内聚
* 因为都是针对 Student 这个数据进行操作的
*/
public class InformationCohesion {
public void add(Student student){
//具体代码省略
}
public void delete(int studentId){
//具体代码省略
}
public void modify(Student newStudent){
//具体代码省略
}
public Student get(int studentId){
//具体代码省略
return null;
}
}
6 顺序内聚
顺序内聚是指模块内部元素之所以被划分到同一模块中,是因为某些元素输出是另外元素的输入
顺序内聚其实就像一条流水线一样,上一个环节的输出是下一个环节的输入。
最常见的就是 “规则引擎” 一类的处理,一个函数负责读取配置,将配置转换为执行指令
另一个函数负责执行这些指令。
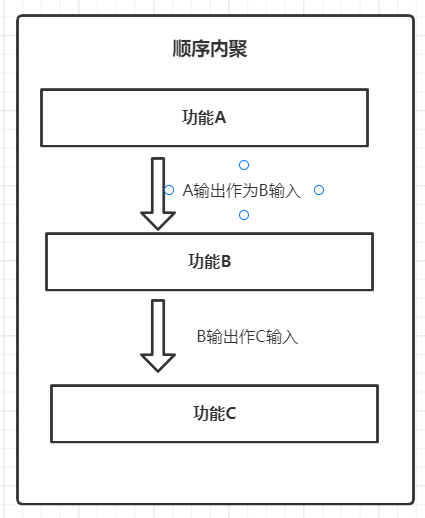
7 功能内聚
功能内聚是指模块内部的元素之所以被划分到同一模块中,是因为这些元素都是为了完成同一个单一任务
如下图:
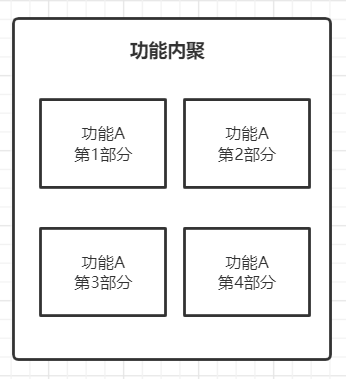
功能内聚是内聚性最好的一种方式,但在实际操作过程中,对于是否满足功能内聚并不能很好地判断出来
原因在于 “同一个单一任务” 这个定义是比较模糊的。
比如在前面各种内聚方式解读中的各种示例,很多人可能会问:
输入难道不是一个单一的任务吗?
异常处理难道不是一个单一的任务吗?
文件读取难道不是一个单一的任务吗?
事件上,站在不同的角度观察,这些任务都可以算作 “单一任务” , 那我们如何理解 “功能内聚” 呢?
关键就在于 “都是” 这个核心点,英文是“all contribute to ” , 即所有元素都是为了同一个任务,缺一不可。
按照这个标准,我们就可以将功能内聚 , 过程内聚 , 顺序内聚 等区分开来。
例如,在过程内聚章节中提到的读取文件的样例就不符合 “all contribute to ”
因为 “checkFileExist” , "checkFilePrivilege" , "openFile" 这些方法并不是只为 “readFile” 而设计的
这些方法同样可以为 “写入文件” , “删除文件 ” 等任务服务
虽然功能内聚比较难于理解,但实际上我们时时刻刻都在和功能内聚打交道
例如 HTTP协议解析, XML文件解析, 甚至每次发薪水的时候 计算个人所得税也是“功能内聚”的一种形式
我们以XML文件解析为例子,示例代码如下:
/**
* 解析 XML 文件,包括解析 Element, Attribute, Comment, DTD 等
* 这些方法都是为了 “解析 XML 文件” 这个单一任务而生的 。
*/
public class FunctionCohesion {
//解析 xml 元素
public void parseElement(){
//具体代码省略实现
}
//解析 XML 属性
public void parseAttribute(){
//具体代码省略实现
}
//解析 XML 注释
public void parseComment(){
//具体代码省略实现
}
//解析 XML DTD
public void parseDTD(){
//具体代码省略实现
}
}以上就是 7 种内聚的方式 ,这对于指导我们设计类的关系时是很有帮助的,下面我们总结一下:
内聚指一个模块内部元素之间的紧密程度
内聚有以下 7 种分类
偶然内聚
逻辑内聚
时间内聚
过程内聚
信息内聚
顺序内聚
功能内聚
下一篇文章 ,我们会讲讲 低耦合