1 系统架构
1.1 What is Kylin
1.2 What is Doris
2 数据模型
2.1 Kylin的聚合模型
2.2 Doris的聚合模型
2.3 Kylin Cuboid VS Doris RollUp
2.4 Doris的明细模型
3 存储引擎
4 数据导入
5 查询
6 精确去重
7 元数据
8 高性能
9 高可用
10 可维护性
10.1 部署
10.2 运维
10.3 客服
11 易用性
11.1 查询接入
11.2 学习成本
11.3 Schema Change
12 功能
13 社区和生态
14 总结
15 参考资料
本文作者:康凯森,来源于:https://blog.bcmeng.com,文章写的非常详细,从各个方面对Kylin和Doris进行了对比。
Apache Kylin 和 Apache Doris 都是优秀的开源OLAP系统,本文将全方位地对比Kylin和Doris。Kylin和Doris分别是MOALP和ROLAP的代表,对比这两个系统的目的不是为了说明哪个系统更好,只是为了明确每个系统的设计思想和架构原理,让大家可以根据自己的实际需求去选择合适的系统,也可以进一步去思考我们如何去设计出更优秀的OLAP系统。
本文对Apache Kylin的理解基于近两年来在生产环境大规模地使用,运维和深度开发,我已向Kylin社区贡献了98次Commit,包含多项新功能和深度优化。
本文对Apache Doris的理解基于官方文档和论文的阅读,代码的粗浅阅读和较深入地测试。
注: 本文的对比基于Apache Kylin 2.0.0 和Apache Doris 0.9.0。
1 系统架构
1.1 What is Kylin
Kylin的核心思想是预计算,利用空间换时间来加速查询模式固定的OLAP查询。
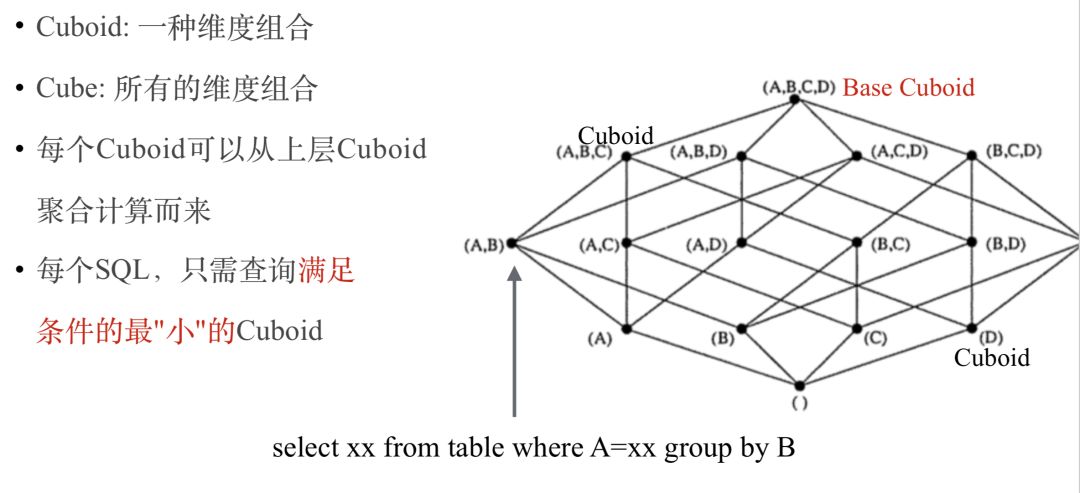
Kylin的理论基础是Cube理论,每一种维度组合称之为Cuboid,所有Cuboid的集合是Cube。 其中由所有维度组成的Cuboid称为Base Cuboid,图中(A,B,C,D)即为Base Cuboid,所有的Cuboid都可以基于Base Cuboid计算出来。 在查询时,Kylin会自动选择满足条件的最“小”Cuboid,比如下面的SQL就会对应Cuboid(A,B):
select xx from table where A=xx group by B
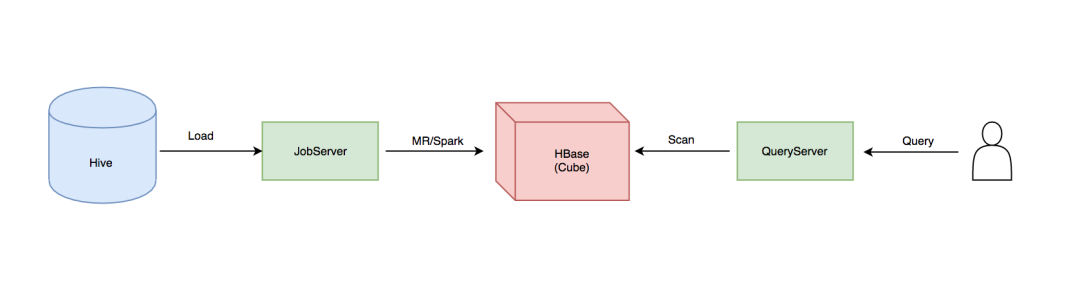
下图是Kylin数据流转的示意图,Kylin自身的组件只有两个:JobServer和QueryServer。Kylin的JobServer主要负责将数据源(Hive,Kafka)的数据通过计算引擎(MapReduce,Spark)生成Cube存储到存储引擎(HBase)中;QueryServer主要负责SQL的解析,逻辑计划的生成和优化,向HBase的多个Region发起请求,并对多个Region的结果进行汇总,生成最终的结果集。
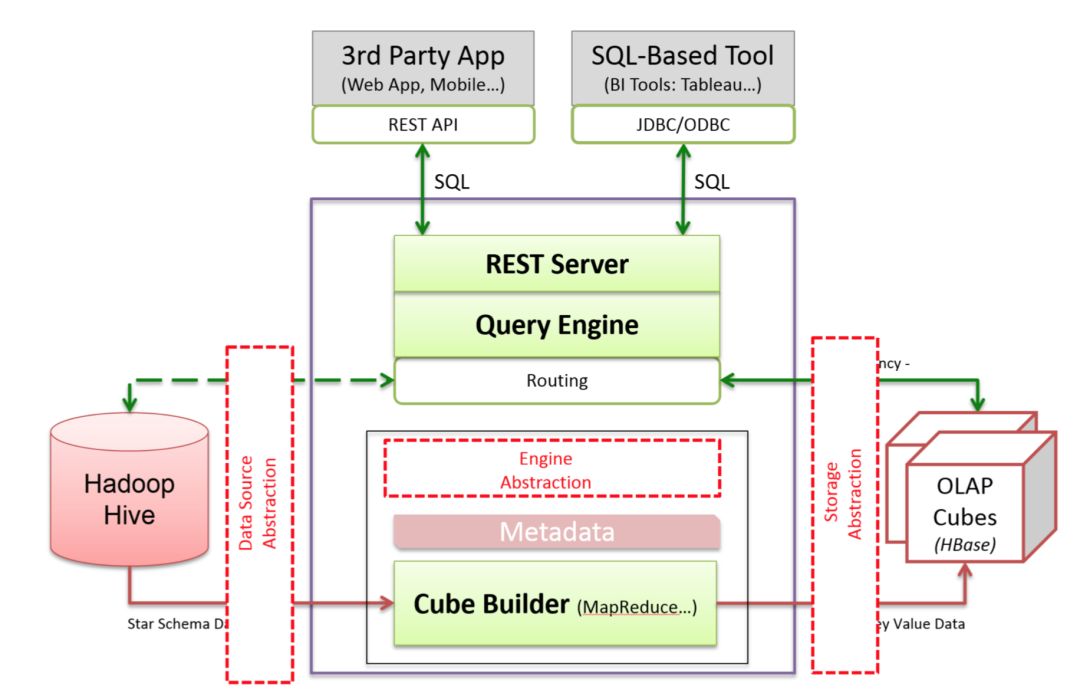
下图是Kylin可插拔的架构图, 在架构设计上,Kylin的数据源,构建Cube的计算引擎,存储引擎都是可插拔的。Kylin的核心就是这套可插拔架构,Cube数据模型和Cuboid的算法。
1.2 What is Doris
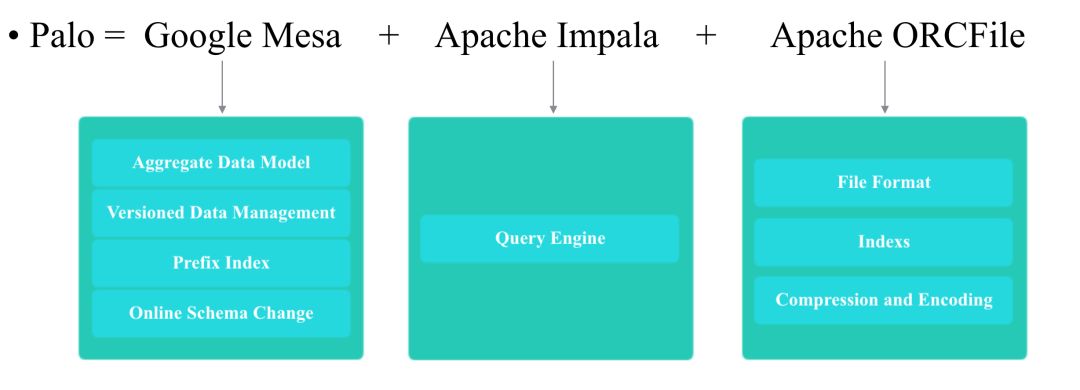
Doris是一个MPP的OLAP系统,主要整合了Google Mesa(数据模型),Apache Impala(MPP Query Engine)和Apache ORCFile (存储格式,编码和压缩) 的技术。
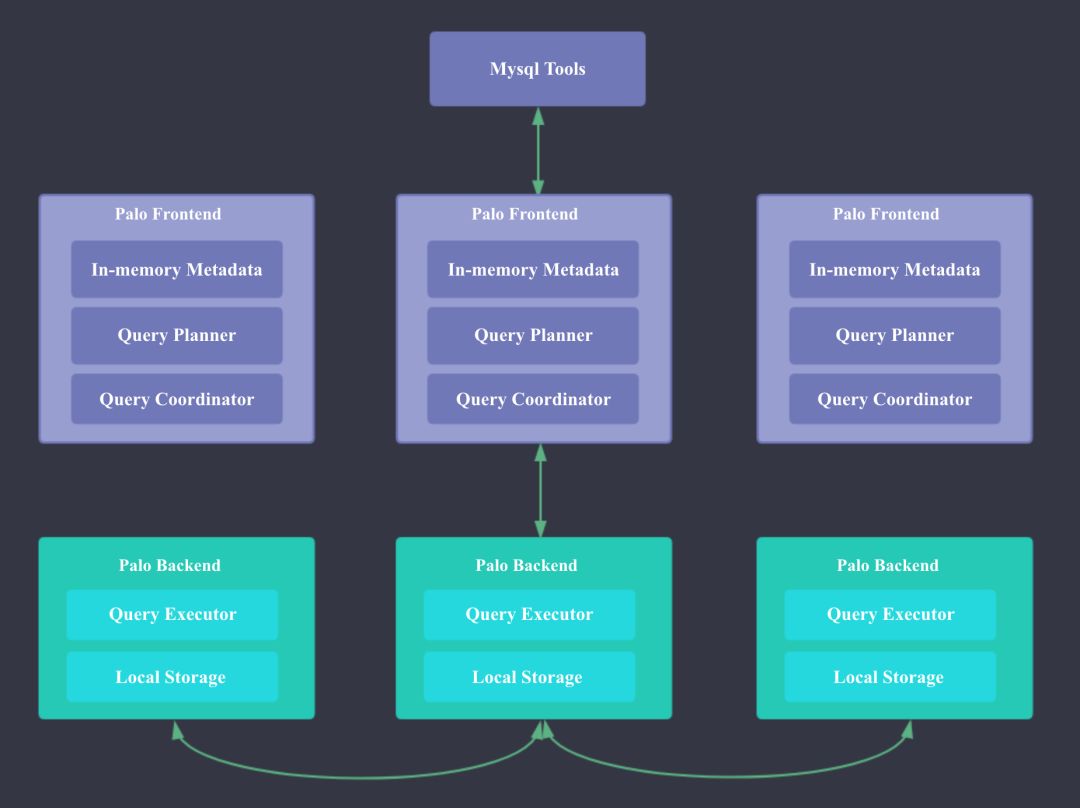
 Doris的系统架构如下,Doris主要分为FE和BE两个组件,FE主要负责查询的编译,分发和元数据管理(基于内存,类似HDFS NN);BE主要负责查询的执行和存储系统。
Doris的系统架构如下,Doris主要分为FE和BE两个组件,FE主要负责查询的编译,分发和元数据管理(基于内存,类似HDFS NN);BE主要负责查询的执行和存储系统。
 2 数据模型
2 数据模型
2.1 Kylin的聚合模型
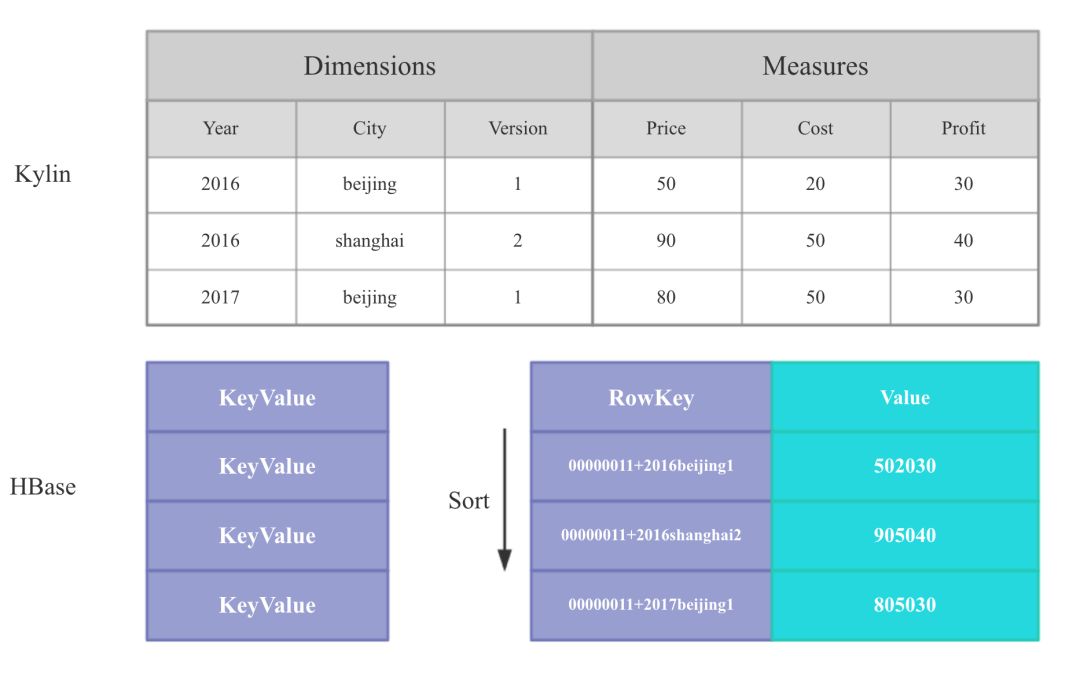
Kylin将表中的列分为维度列和指标列。在数据导入和查询时相同维度列中的指标会按照对应的聚合函数(Sum, Count, Min, Max, 精确去重,近似去重,百分位数,TOPN)进行聚合。
在存储到HBase时,Cuboid+维度 会作为HBase的Rowkey, 指标会作为HBase的Value,一般所有指标会在HBase的一个列族,每列对应一个指标,但对于较大的去重指标会单独拆分到第2个列族。
2.2 Doris的聚合模型
Doris的聚合模型借鉴自Mesa,但本质上和Kylin的聚合模型一样,只不过Doris中将维度称作Key,指标称作Value。
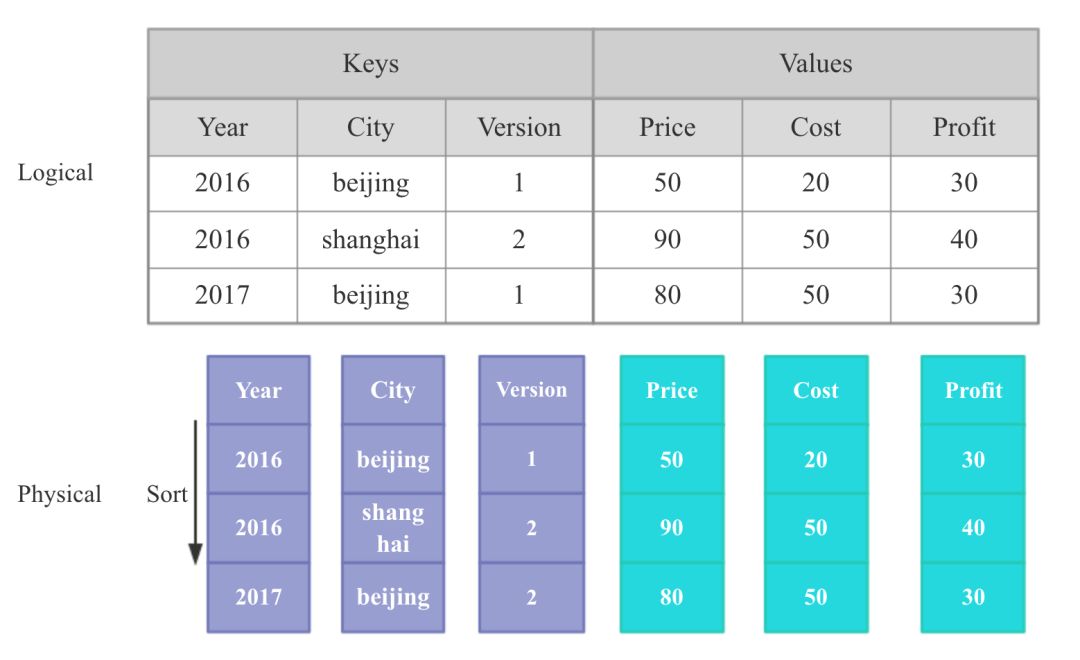
Doris中比较独特的聚合函数是Replace函数,这个聚合函数能够保证相同Keys的记录只保留最新的Value,可以借助这个Replace函数来实现点更新。一般OLAP系统的数据都是只支持Append的,但是像电商中交易的退款,广告点击中的无效点击处理,都需要去更新之前写入的单条数据,在Kylin这种没有Relpace函数的系统中我们必须把包含对应更新记录的整个Segment数据全部重刷,但是有了Relpace函数,我们只需要再追加1条新的记录即可。 但是Doris中的Repalce函数有个缺点:无法支持预聚合,就是说只要你的SQL中包含了Repalce函数,即使有其他可以已经预聚合的Sum,Max指标,也必须现场计算。
为什么Doirs可以支持点更新呢?
Kylin中的Segment是不可变的,也就是说HFile一旦生成,就不再发生任何变化。但是Doirs中的Segment文件和HBase一样,是可以进行Compaction的,具体可以参考Google Mesa 论文解读中的Mesa数据版本化管理。
Doris的聚合模型相比Kylin有个缺点:就是一个Column只能有一个预聚合函数,无法设置多个预聚合函数。 不过Doris可以现场计算出其他的聚合函数。 Apache Doris的开发者Review时提到,针对这个问题,Doris还有一种解法:由于Doris支持多表导入的原子更新,所以1个Column需要多个聚合函数时,可以在Doris中建多张表,同一份数据导入时,Doris可以同时原子更新多张Doris表,缺点是多张Doris表的查询路由需要应用层来完成。
Doris中和Kylin的Cuboid等价的概念是RollUp表,Cuboid和RollUp表都可以认为是一种Materialized Views或者Index。Doris的RollUp表和Kylin的Cuboid一样,在查询时不需要显示指定,系统内部会根据查询条件进行路由。 如下图所示:

Doris中RollUp表的路由规则如下:
选择包含所有查询列的RollUp表
按照过滤和排序的Column筛选最符合的RollUp表
按照Join的Column筛选最符合的RollUp表
行数最小的
列数最小的
2.3 Kylin Cuboid VS Doris RollUp

2.4 Doris的明细模型
由于Doris的聚合模型存在下面的缺陷,Doris引入了明细模型。
必须区分维度列和指标列
维度列很多时,Sort的成本很高
Count成本很高,需要读取所有维度列(可以参考Kylin的解决方法进行优化)
Doris的明细模型不会有任何预聚合,不区分维度列和指标列,但是在建表时需要指定Sort Columns,数据导入时会根据Sort Columns进行排序,查询时根据Sort Column过滤会比较高效。
如下图所示,Sort Columns是Year和City。
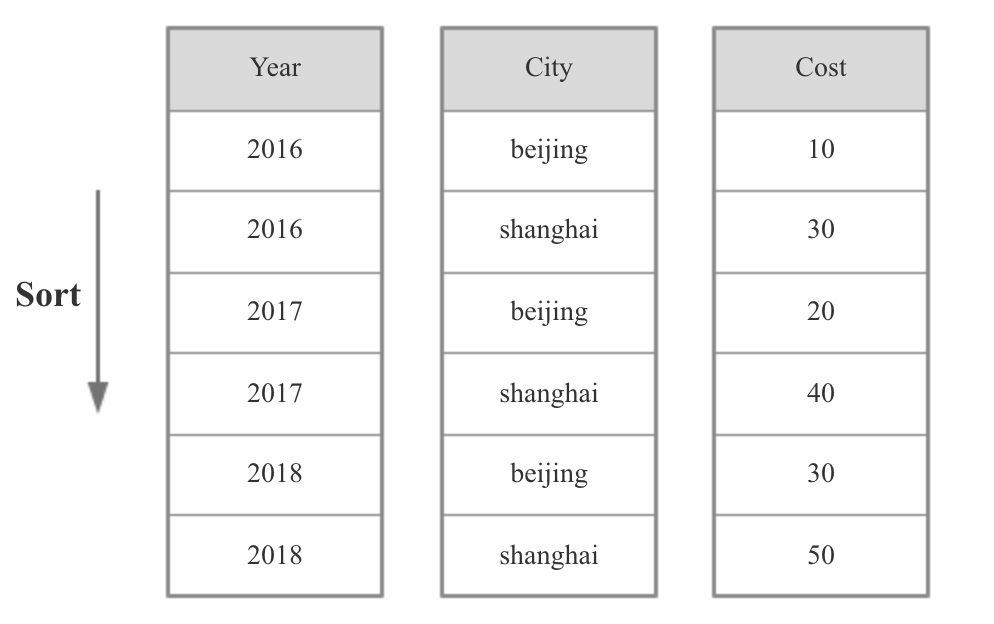
这里需要注意一点,Doris中一张表只能有一种数据模型,即要么是聚合模型,要么是明细模型,而且Roll Up表的数据模型必须和Base表一致,也就是说明细模型的Base 表不能有聚合模型的Roll Up表。
3 存储引擎
Kylin存储引擎HBase:
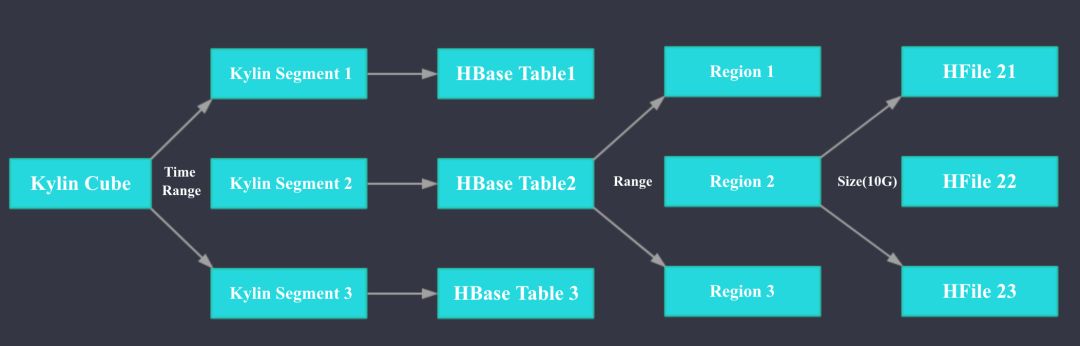
如上图所示,在Kylin中1个Cube可以按照时间拆分为多个Segment,Segment是Kylin中数据导入和刷新的最小单位。Kylin中1个Segment对应HBase中一张Table。HBase中的Table会按照Range分区拆分为多个Region,每个Region会按照大小拆分为多个HFile。
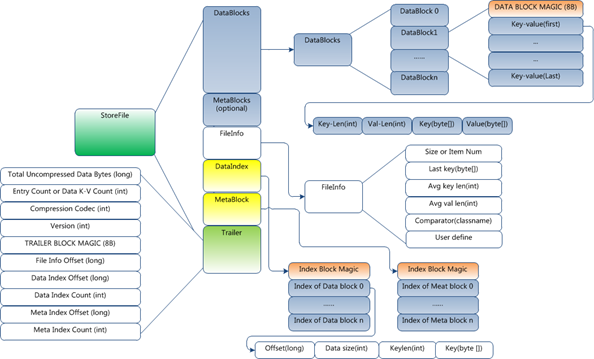
关于HFile的原理网上讲述的文章已经很多了,我这里简单介绍下。首先HFile整体上可以分为元信息,Blcoks,Index3部分,Blcoks和Index都可以分为Data和Meta两部分。Block是数据读取的最小单位,Block有多个Key-Value组成,一个Key-Value代表HBase中的一行记录,Key-Value由Kylin-Len,Value-Len,Key-Bytes,Value-Bytes 4部分组成。更详细的信息大家可以参考下图(下图来源于互联网,具体出处不详):
 Doris存储引擎:
Doris存储引擎:
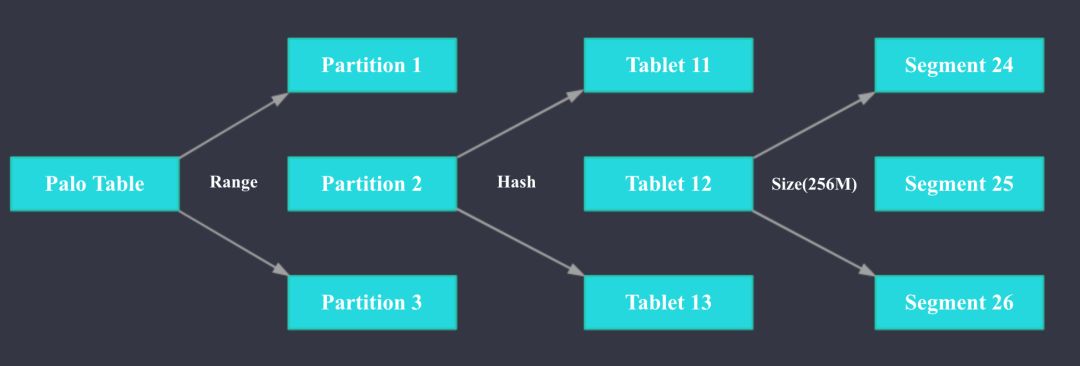
如上图所示,Doris的Table支持二级分区,可以先按照日期列进行一级分区,再按照指定列Hash分桶。具体来说,1个Table可以按照日期列分为多个Partition, 每个Partition可以包含多个Tablet,Tablet是数据移动、复制等操作的最小物理存储单元,各个Tablet之间的数据没有交集,并且在物理上独立存储。Partition 可以视为逻辑上最小的管理单元,数据的导入与删除,仅能针对一个 Partition进行。1个Table中Tablet的数量= Partition num * Bucket num。Tablet会按照一定大小(256M)拆分为多个Segment文件,Segment是列存的,但是会按行(1024)拆分为多个Rowblock。
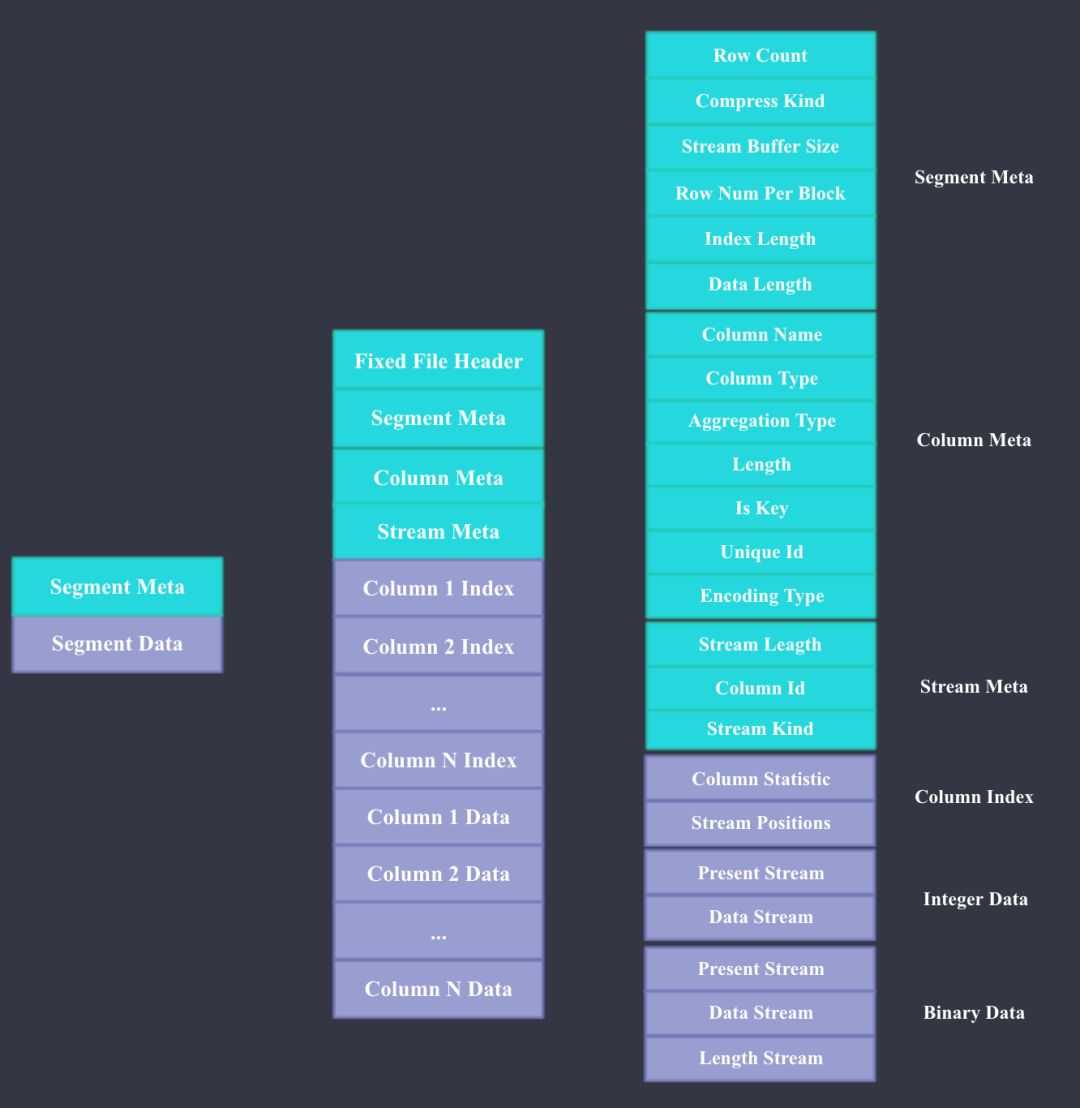
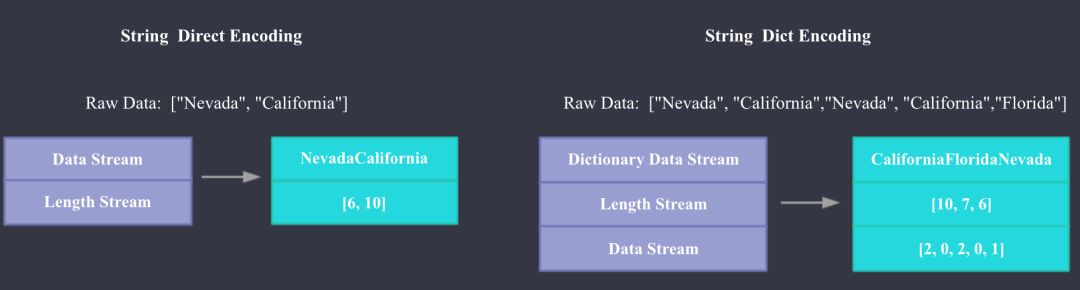
下面我们来看下Doris Segment文件的具体格式,Doris文件格式主要参考了Apache ORC。如上图所示,Doris文件主要由Meta和Data两部分组成,Meta主要包括文件本身的Header,Segment Meta,Column Meta,和每个Column 数据流的元数据,每部分的具体内容大家看图即可,比较详细。Data部分主要包含每一列的Index和Data,这里的Index指每一列的Min,Max值和数据流Stream的Position;Data就是每一列具体的数据内容,Data根据不同的数据类型会用不同的Stream来存储,Present Stream代表每个Value是否是Null,Data Stream代表二进制数据流,Length Stream代表非定长数据类型的长度。下图是String使用字典编码和直接存储的Stream例子。
下面我们来看下Doris的前缀索引:

本质上,Doris 的数据存储是类似 SSTable(Sorted String Table)的数据结构。该结构是一种有序的数据结构,可以按照指定的列有序存储。在这种数据结构上,以排序列作为条件进行查找,会非常的高效。而前缀索引,即在排序的基础上,实现的一种根据给定前缀列,快速查询数据的索引方式。前缀索引文件的格式如上图所示,索引的Key是每个Rowblock第一行记录的Sort Key的前36个字节,Value是Rowblock在Segment文件的偏移量。
有了前缀索引后,我们查询特定Key的过程就是两次二分查找:
先加载Index文件,二分查找Index文件获取包含特定Key的Row blocks的Offest,然后从Sement Files中获取指定的Rowblock;
在Rowblocks中二分查找特定的Key
4 数据导入
Kylin数据导入: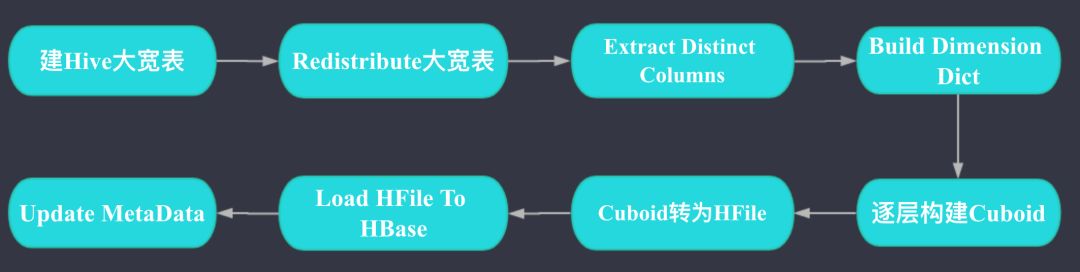
如上图,Kylin数据导入主要分为建Hive大宽表(这一步会处理Join);维度列构建字典;逐层构建Cuboid;Cuboid转为HFile;Load HFile To HBase; 元数据更新这几步。
其中Redistribute大宽表这一步的作用是为了将整个表的数据搞均匀,避免后续的步骤中有数据倾斜,Kylin有配置可以跳过这一步。
其中Extract Distinct Columns这一步的作用是获取需要构建字典的维度列的Distinct值。假如一个ID维度列有1,2,1,2,2,1,1,2这8行,那么经过这一步后ID列的值就只有1,2两行,做这一步是为了下一步对维度列构建字典时更快速。
其他几个步骤都比较好理解,我就不再赘述。更详细的信息可以参考 Apache Kylin Cube 构建原理
Doris数据导入: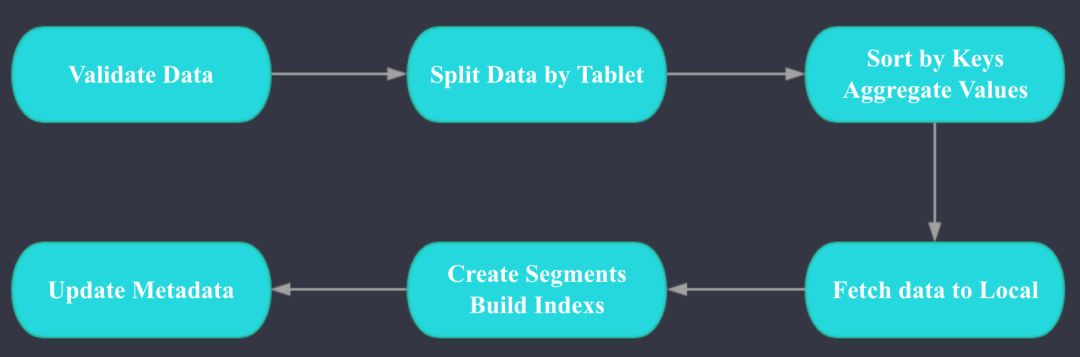
Doris 数据导入的两个核心阶段是ETL和LOADING, ETL阶段主要完成以下工作:
数据类型和格式的校验
根据Teblet拆分数据
按照Key列进行排序, 对Value进行聚合
LOADING阶段主要完成以下工作:
每个Tablet对应的BE拉取排序好的数据
进行数据的格式转换,生成索引
LOADING完成后会进行元数据的更新。
5 查询
Kylin查询:
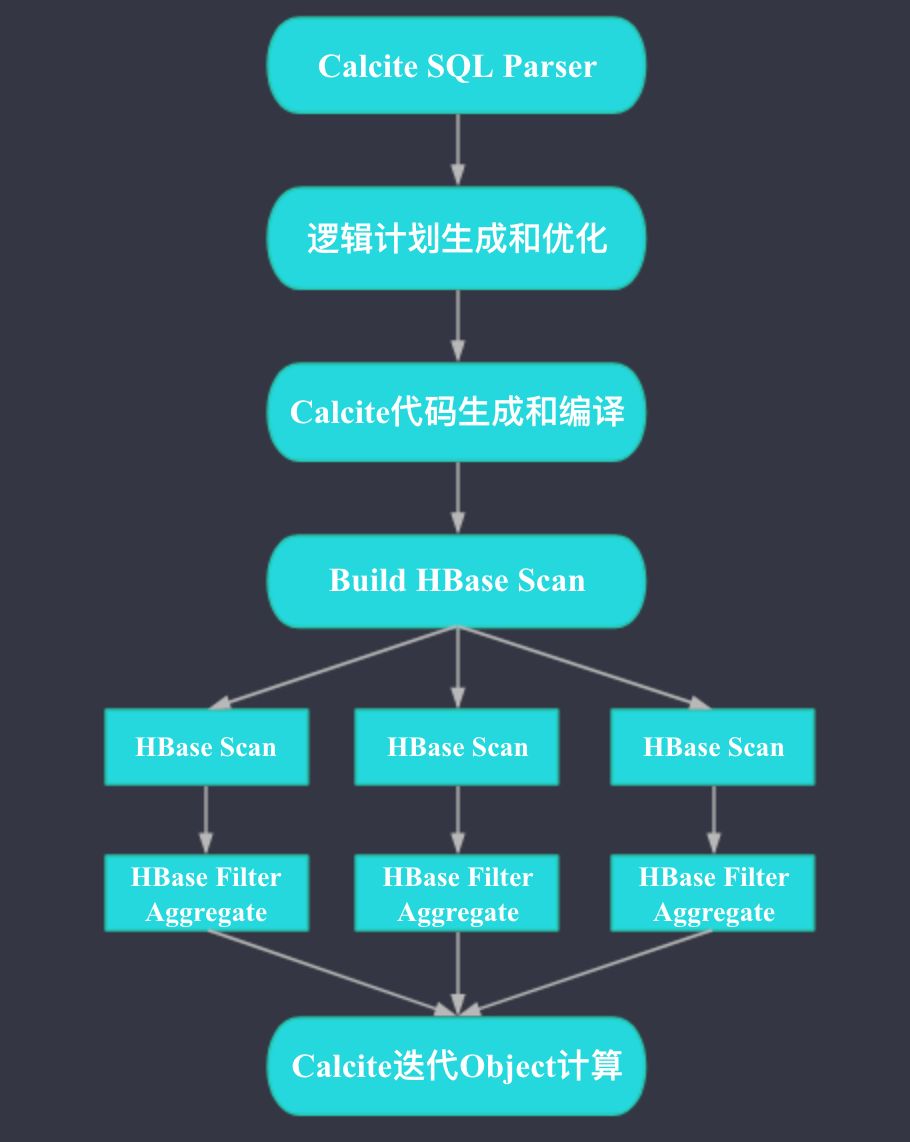 如上图,整个Kylin的查询过程比较简单,是个Scatter-Gather的模型。图中圆形框的内容发生在Kylin QueryServer端,方形框的内容发生在HBase端。Kylin QueryServer端收到SQL后,会先进行SQL的解析,然后生成和优化Plan,再根据Plan生成和编译代码,之后会根据Plan生成HBase的Scan请求,如果可能,HBase端除了Scan之外,还会进行过滤和聚合(基于HBase的Coprocessor实现),Kylin会将HBase端返回的结果进行合并,交给Calcite之前生成好的代码进行计算。
如上图,整个Kylin的查询过程比较简单,是个Scatter-Gather的模型。图中圆形框的内容发生在Kylin QueryServer端,方形框的内容发生在HBase端。Kylin QueryServer端收到SQL后,会先进行SQL的解析,然后生成和优化Plan,再根据Plan生成和编译代码,之后会根据Plan生成HBase的Scan请求,如果可能,HBase端除了Scan之外,还会进行过滤和聚合(基于HBase的Coprocessor实现),Kylin会将HBase端返回的结果进行合并,交给Calcite之前生成好的代码进行计算。
Doris查询:
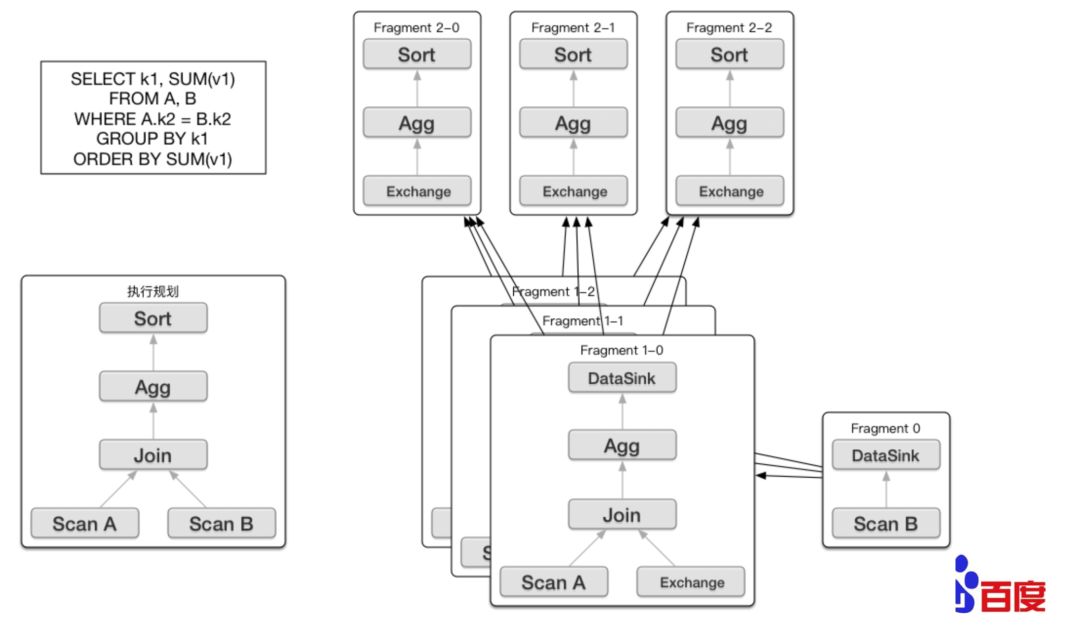
Doris的查询引擎使用的是Impala,是MPP架构。Doris的FE 主要负责SQL的解析,语法分析,查询计划的生成和优化。查询计划的生成主要分为两步:
生成单节点查询计划 (上图左下角)
将单节点的查询计划分布式化,生成PlanFragment(上图右半部分)
第一步主要包括Plan Tree的生成,谓词下推, Table Partitions pruning,Column projections,Cost-based优化等;第二步 将单节点的查询计划分布式化,分布式化的目标是最小化数据移动和最大化本地Scan,分布式化的方法是增加ExchangeNode,执行计划树会以ExchangeNode为边界拆分为PlanFragment,1个PlanFragment封装了在一台机器上对同一数据集的部分PlanTree。如上图所示:各个Fragment的数据流转和最终的结果发送依赖:DataSink。
当FE生成好查询计划树后,BE对应的各种Plan Node(Scan, Join, Union, Aggregation, Sort等)执行自己负责的操作即可。
6 精确去重
Kylin的精确去重:
Kylin的精确去重是基于全局字典和RoaringBitmap实现的基于预计算的精确去重。
Doris的精确去重:
Doris的精确去重是现场精确去重,Doris计算精确去重时会拆分为两步:
按照所有的group by 字段和精确去重的字段进行聚合
按照所有的group by 字段进行聚合
SELECT a, COUNT(DISTINCT b, c), MIN(d), COUNT() FROM T GROUP BY a - 1st phase grouping exprs: a, b, c* - 1st phase agg exprs: MIN(d), COUNT() - 2nd phase grouping exprs: a* - 2nd phase agg exprs: COUNT(*), MIN(<MIN(d) from 1st phase>), SUM(<COUNT(*) from 1st phase>)
下面是个简单的等价转换的例子:
select count(distinct lo_ordtotalprice) from ssb_sf20.v2_lineorder;select count(*) from (select count(*) from ssb_sf20.v2_lineorder group by lo_ordtotalprice) a;
Doris现场精确去重计算性能和去重列的基数、去重指标个数、过滤后的数据大小成负相关;
7 元数据
Kylin的元数据 :
Kylin的元数据是利用HBase存储的,可以很好地横向扩展。Kylin每个具体的元数据都是一个Json文件,HBase的Rowkey是文件名,Value是Json文件的内容。Kylin的元数据表设置了IN_MEMORY => 'true' 属性, 元数据表会常驻HBase RegionServer的内存,所以元数据的查询性能很好,一般在几ms到几十ms。
Kylin元数据利用HBase存储的一个问题是,在Kylin可插拔架构下,即使我们实现了另一种存储引擎,我们也必须部署HBase来存储元数据,所以Kylin要真正做到存储引擎的可插拔,就必须实现一个独立的元数据存储。
Doris的元数据:
Doris的元数据是基于内存的,这样做的好处是性能很好且不需要额外的系统依赖。 缺点是单机的内存是有限的,扩展能力受限,但是根据Doris开发者的反馈,由于Doris本身的元数据不多,所以元数据本身占用的内存不是很多,目前用大内存的物理机,应该可以支撑数百台机器的OLAP集群。 此外,OLAP系统和HDFS这种分布式存储系统不一样,我们部署多个集群的运维成本和1个集群区别不大。
关于Doris元数据的具体原理大家可以参考Doris官方文档Doris 元数据设计文档
8 高性能
Why Kylin Query Fast:
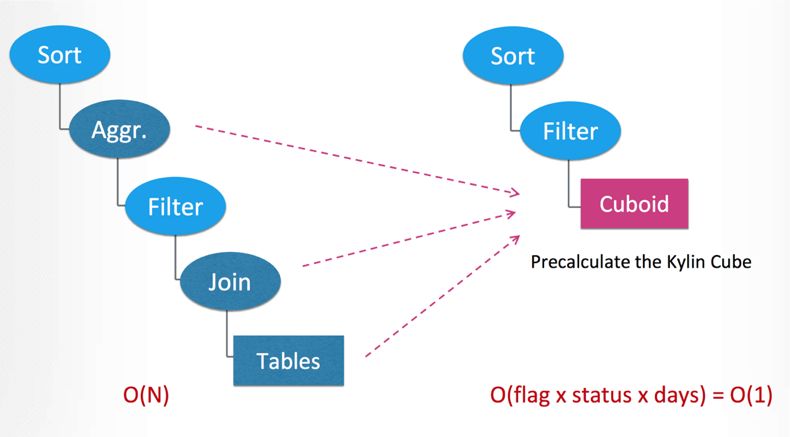
Kylin查询快的核心原因就是预计算,如图(图片出处 Apache kylin 2.0: from classic olap to real-time data warehouse),Kylin现场查询时不需要Join,也几乎不需要聚合,主要就是Scan + Filter。
Why Doris Query Fast:
In-Memory Metadata。
Doris的元数据就在内存中,元数据访问速度很快。
聚合模型可以在数据导入时进行预聚合。
和Kylin一样,也支持预计算的RollUp Table。
MPP的查询引擎。
向量化执行。
相比Kylin中Calcite的代码生成,向量化执行在处理高并发的低延迟查询时性能更好,Kylin的代码生成本身可能会花费几十ms甚至几百ms。
列式存储 + 前缀索引。
9 高可用
Kylin高可用:
Kylin JobServer的高可用: Kylin的JobServer是无状态的,一台JobServer挂掉后,其他JobServer会很快接管正在Running的Job。JobServer的高可用是基于Zookeeper实现的,具体可以参考Apache Kylin Job 生成和调度详解。
Kylin QueryServer的高可用:Kylin的QueryServer也是无状态的,其高可用一般通过Nginx这类的负载均衡组件来实现。
Kylin Hadoop依赖的高可用: 要单纯保证Kylin自身组件的高可用并不困难,但是要保证Kylin整体数据导入和查询的高可用是十分困难的,因为必须同时保证HBase,Hive,Hive Metastore,Spark,Mapreduce,HDFS,Yarn,Zookeeper,Kerberos这些服务的高可用。
Doris高可用:
Doris FE的高可用: Doris FE的高可用主要基于BerkeleyDB java version实现,BDB-JE实现了类Paxos一致性协议算法。
Doris BE的高可用: Doris会保证每个Tablet的多个副本分配到不同的BE上,所以一个BE down掉,不会影响查询的可用性。
10 可维护性
10.1 部署
Kylin部署:如果完全从零开始,你就需要部署1个Hadoop集群和HBase集群。即使公司已经有了比较完整的Hadoop生态,在部署Kylin前,你也必须先部署Hadoop客户端,HBase客户端,Hive客户端,Spark客户端。
Doris部署: 直接部署FE和BE组件即可。
10.2 运维
Kylin运维: 运维Kylin对Admin有较高的要求,首先必须了解HBase,Hive,MapReduce,Spark,HDFS,Yarn的原理;其次对MapReduce Job和Spark Job的问题排查和调优经验要丰富;然后必须掌握对Cube复杂调优的方法;最后出现问题时排查的链路较长,复杂度较高。
Doris运维: Doris只需要理解和掌握系统本身即可。
10.3 客服
Kylin 客服: 需要向用户讲清Hadoop相关的一堆概念;需要教会用户Kylin Web的使用;需要教会用户如何进行Cube优化(没有统一,简洁的优化原则);需要教会用户怎么查看MR和Spark日志;需要教会用户怎么查询;
Doris 客服: 需要教会用户聚合模型,明细模型,前缀索引,RollUp表这些概念。
11 易用性
11.1 查询接入
Kylin查询接入:Kylin支持Htpp,JDBC,ODBC 3种查询方式。
Doris查询接入: Doris支持Mysql协议,现有的大量Mysql工具都可以直接使用,用户的学习和迁移成本较低。
11.2 学习成本
Kylin学习成本:用户要用好Kylin,需要理解以下概念:
Cuboid
聚集组
强制维度
联合维度
层次维度
衍生维度
Extend Column
HBase RowKey 顺序
此外,前面提到过,用户还需要学会怎么看Mapreduce Job和Spark Job日志。
Doris学习成本:用户需要理解聚合模型,明细模型,前缀索引,RollUp表这些概念。
11.3 Schema Change
Schema在线变更是一个十分重要的feature,因为在实际业务中,Schema的变更会十分频繁。
Kylin Schema Change:Kylin中用户对Cube Schema的任何改变,都需要在Staging环境重刷所有数据,然后切到Prod环境。整个过程周期很长,资源浪费比较严重。
Doris Schema Change:Doris支持Online Schema Change。
所谓的Schema在线变更就是指Scheme的变更不会影响数据的正常导入和查询,Doris中的Schema在线变更有3种:
direct schema change:
就是重刷全量数据,成本最高,和kylin的做法类似。
当修改列的类型,稀疏索引中加一列时需要按照这种方法进行。
sorted schema change: 改变了列的排序方式,需对数据进行重新排序。
例如删除排序列中的一列, 字段重排序。
linked schema change: 无需转换数据,直接完成。
对于历史数据不会重刷,新摄入的数据都按照新的Schema处理,对于旧数据,新加列的值直接用对应数据类型的默认值填充。
例如加列操作。
Druid也支持这种做法。
12 功能
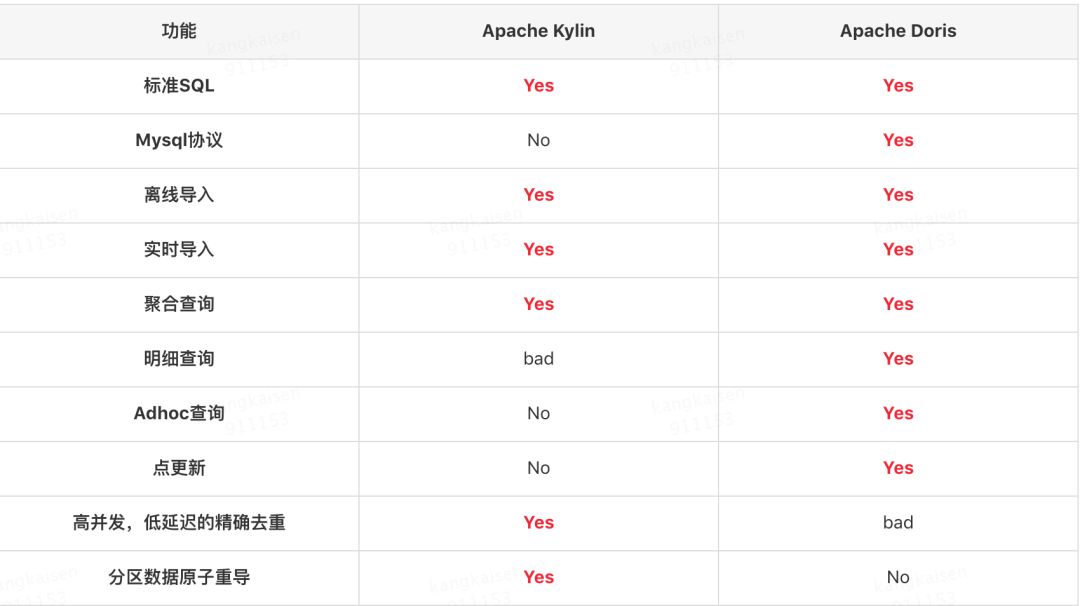
注:关于Kylin的明细查询,Kylin本身只有聚合模型,但是也可以通过将所有列作为维度列,只构建Base Cuboid来实现明细查询, 缺点是效率比较低下。
注:虽然Doirs理论上可以同时支持高并发,低延迟的OLAP查询和高吞吐的Adhoc查询,但显然这两类查询会相互影响。所以Baidu在实际应用中也是用两个集群分别满足OLAP查询和Adhoc查询需求。
13 社区和生态
Doris社区刚刚起步,目前核心用户只有Baidu;Kylin的社区和生态已经比较成熟,Kylin是第一个完全由中国开发者贡献的Apache顶级开源项目,目前已经在多家大型公司的生产环境中使用。
14 总结
本文从多方面对比了Apache Kylin和Apache Doris,有理解错误的地方欢迎指正。本文更多的是对两个系统架构和原理的客观描述,主观判断较少。最近在调研了Doirs,ClickHouse,TiDB之后,也一直在思考OLAP系统的发展趋势是怎样的,下一代更优秀的OLAP系统架构应该是怎样的,一个系统是否可以同时很好的支持OLTP和OLAP,这些问题想清楚后我会再写篇文章描述下,当然,大家有好的想法,也欢迎直接Comment。
15 参考资料
1 Doris文档和源码
2 Kylin源码
3 Apache kylin 2.0: from classic olap to real-time data warehouse 在Kylin高性能部分引用了第4页PPT的截图
4 百度MPP数据仓库Palo开源架构解读与应用 在Doris查询部分引用了第31页PPT的截图
— THE END —

本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。