
**一、内存结构
**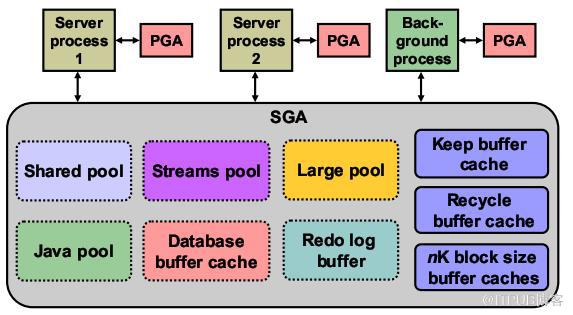
SGA(System Global Area):由所有服务进程和后台进程共享;
PGA(Program Global Area):由每个服务进程、后台进程专有;每个进程都有一个PGA。
二、SGA
包含实例的数据和控制信息,包含如下内存结构:
1)Database buffer cache:缓存了从磁盘上检索的数据块。
2)Redo log buffer:缓存了写到磁盘之前的重做信息。
3)Shared pool:缓存了各用户间可共享的各种结构。
4)Large pool:一个可选的区域,用来缓存大的I/O请求,以支持并行查询、共享服务器模式以及某些备份操作。
5)Java pool:保存java虚拟机中特定会话的数据与java代码。
6)Streams pool:由Oracle streams使用。
7)Keep buffer cache:保存buffer cache中存储的数据,使其尽时间可能长。
8)Recycle buffer cache:保存buffer cache中即将过期的数据。
9)nK block size buffer:为与数据库默认数据块大小不同的数据块提供缓存。用来支持表空间传输。
database buffer cache, shared pool, large pool, streams pool与Java pool根据当前数据库状态,自动调整;
keep buffer cache,recycle buffer cache,nK block size buffer可以在不关闭实例情况下,动态修改。
三、PGA
每个服务进程私有的内存区域,包含如下结构:
1)Private SQL area:包含绑定信息、运行时的内存结构。每个发出sql语句的会话,都有一个private SQL area(私有SQL区)
2)Session memory:为保存会话中的变量以及其他与会话相关的信息,而分配的内存区。
四、SGA COMPONENT
(一)、Buffer Cache
1、DB_CACHE_SIZE
通过参数DB_CACHE_SIZE可指定DB buffer cache的大小
ALTER SYSTEM SET DB_CACHE_SIZE=20M scope=both;
服务进程从数据文件读数据到buffer cache;DBWn从buffer cache写数据到数据文件。
buffer cache的四种状态:
1)pinned:当前块正在读到cache或正写到磁盘,其他会话等待访问该块。
2)clean:
3)free/unused:buffer内为空,为实例刚启动时的状态。
4)dirty:脏数据,数据块被修改,需要被DBWn刷新到磁盘,才能执行过期处理。
同一个数据库中,支持多种大小的数据块缓存。通过DB_nK_CACHE_SIZE参数指定,如
• DB_2K_CACHE_SIZE
• DB_4K_CACHE_SIZE
• DB_8K_CACHE_SIZE
• DB_16K_CACHE_SIZE
• DB_32K_CACHE_SIZE
标准块缓存区大小由DB_CACHE_SIZE指定。如标准块为nK,则不能通过DB_nK_CACHE_SIZE来指定标准块缓存区的大小,应由DB_CACHE_SIZE指定。
例,标准块为8K,则数据库可以设置的块缓存大小的参数如下:
• DB_CACHE_SIZE (指定标准块(这里为8K)的缓存区)
• DB_2K_CACHE_SIZE (指定块大小为2K的缓存区)
• DB_4K_CACHE_SIZE (指定块大小为4K的缓存区)
• DB_16K_CACHE_SIZE (指定块大小为16K的缓存区)
• DB_32K_CACHE_SIZE (指定块大小为32K的缓存区)
2、多种缓冲池(buffer pool)
1)Keep:通过db_keep_cache_size参数指定。
该buffer内的数据可能被重用,以降低I/O操作。该池的大小要大于指定到该池的段的总和。
读入到keep buffer的块不需要过期操作。
2)Recycle:通过db_recycle_cache_size参数指定。
该池中的数据被重用机会较小,该池大小要小于分配到该池的段的总和。读入该池的块需要经常执行过期处理。
3)Default:相当于一个没有Keep与Recycle池的实例的buffer cache,通过db_cache_size参数指定。
3、为对象明确指定buffer pool
buffer_pool子句,用来为对象指定默认的buffer pool,是storage子句的一部分。
对create与alter table、cluster、index语句有效。
如果现有对象没有明确指定buffer pool,则默认都指定为default buffer pool,大小为DB_CACHE_SIZE参数设置的值。
语法:
a.CREATE INDEX cust_idx ON tt(id) STORAGE (BUFFER_POOL KEEP);
b.ALTER TABLE oe.customers STORAGE (BUFFER_POOL RECYCLE);
c.ALTER INDEX oe.cust_lname_ix STORAGE (BUFFER_POOL KEEP);
(二)、Share Pool
1、SHARE_POOL_SIZE
1)Share Pool可通过SHARE_POOL_SIZE参数指定:
SQL> alter system set shared_pool_size=20M scope=both;
2)Share Pool保存的信息被多个会话共享,类型包括:
a.Library Cache
Library Cache又包含共享SQL区与PL/SQL区:
a).共享SQL区保存了分析与编译过的SQL语句。
b).PL/SQL区保存了分析与编译过的PL/SQL块(过程和函数、包、触发器与匿名PL/SQL块)。
b.Data Dictionary Cache
保存了数据字典对象的定义。
c.UGA(User Global Area)
UGA内包含了共享服务器模式下的会话信息。
共享服务器模式时,如果large pool没有配置,则UGA保存在Share Pool中。
(三)、Large Pool 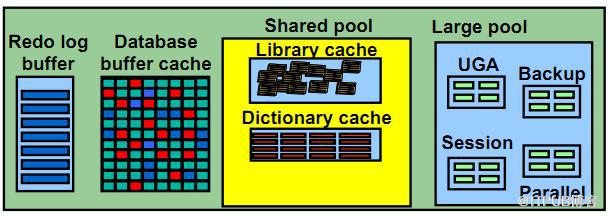
1)Large Pool大小通过LARGE_POOL_SIZE参数指定:
SQL> alter system set large_pool_size=20m scope=both;
2)作用:
a.为I/O服务进程分配内存
b.为备份与恢复操作分配内存
c.为Oracle共享服务器模式与多个数据库间的联机事务分配内存。
通过从large pool中为共享服务器模式分配会话内存,可以减少share pool因频繁为大对象分配和回收内存而产生的碎片。将大的对象从share pool中分离出来,可以提高shared pool的使用效率,使其可以为新的请求提供服务或者根据需要保留现有的数据。
(四)、Java Pool 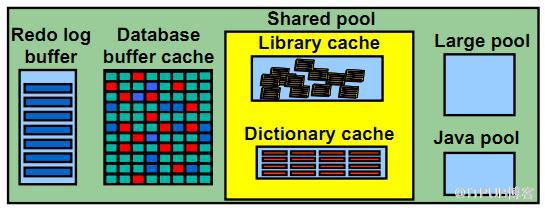 1、JAVA_POOL_SIZE
1、JAVA_POOL_SIZE
通过JAVA_POOL_SIZE参数指定java pool大小。
保存了jvm中特定会话的java code和数据。
2、在编译数据库中的java代码和使用数据库中的java资源对象时,都会用到share pool。
java的类加载程序对每个加载的类会使用大约8K的空间。
系统跟踪运行过程中,动态加载的java类,也会使用到share pool。
(五)、Redo Log Buffer
1、服务进程从用户空间拷贝每条DML/DDL语句的redo条目到redo log buffer中。
2、redo log buffer是一个可以循环使用的buffer,服务进程拷贝新的redo覆盖掉redo log buffer中已通过LGWR写入磁盘(online redo log)的条目。
3、导致LGWR执行写redo log buffer到online redo log的条件
a.用户执行事务提交commit
b.每3秒钟或redo log buffer内已达到1/3满或包含1MB数据
c.DBWn进程将修改的缓冲区写入磁盘时(如果相应的重做日志数据尚未写入磁盘)
**(六)、ASMM(Automatic Shared Memory Management)
**1、SGA_TARGET
1)SGA_TARGET默认值为0,即ASMM被禁用。需要手动设置SGA各中各组件的大小。
2)当SGA_TARGET为非0时,则启用ASMM,自动调整以下各组件大小:
DB buffer cache(default pool)
shared pool
large pool
streams pool
java pool
但ASSM中, 以下参数仍需要手动指定:
log buffer
keep、recycle、以及非标准块缓冲区
固定SGA以及其他内部分配。
2、启用ASMM需要将STATISTICS_LEVEL设置成TYPICAL或ALL
3、启用ASMM,自动调整SGA内部组件大小后。若手动指定某一组件值,则该值为该组件的最小值。如
手动设置SGA_TARGET=8G,SHARE_POOL_SIZE=1G,则ASMM在自动调整SGA内部组件大小时,保证share pool不会低于1G。
SQL> SELECT component, current_size/1024/1024 size_mb FROM v$sga_dynamic_components;
4、SGA_MAX_SIZE
SGA_MAX_SIZE指定内存中可以分配给SGA的最大值。
SGA_TARGET是一个动态参数,其最大值为SGA_MAX_SIZE指定的值。
**五、PGA
**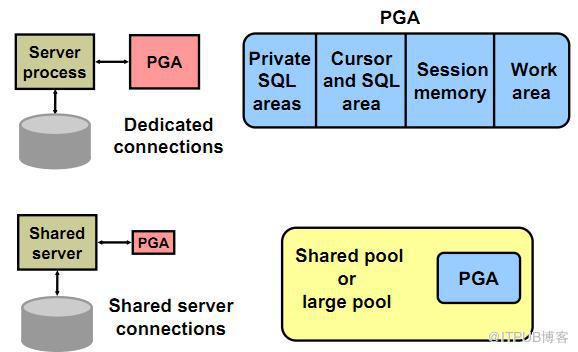
(一)Private SQL Area
1、保存了当前会话的绑定信息以及运行时内存结构。这些信息
2、每个执行sql语句的会话,都有一个private sql area。
3、当多个用户执行相同的sql语句,此sql语句保存在一个称为shared sql area。此share sql area被指定给这些用户的private sql area
4、共享服务器模式:private sql area位于SGA的share pool或large pool中
专用服务器模式:private sql area位于PGA中
(二)Cursor、SQL Areas
(三)Work Area PGA的一大部分被分配给Work Area,用来执行如下操作:
a.基于操作符的排序,group by、order by、rollup和窗口函数。
参数为sort_area_size
b.hash散列连接,
参数为hash_area_size
c.位图合并,
参数为bitmap_merge_area_size
d.位图创建,
参数为create_bitmap_area_size
e.批量装载操作使用的写缓存
**(四)Session memory
** 保存了会话的变量,如登录信息及其他与会话相关的信息,共享服务器模式下,Session memory是共享的。
**(五)自动PGA管理
**设置PGA_AGGREGATE_TARGET为非0,则启用PGA自动管理,并忽略所有*_area_size的设置。如sort_area_size,hash_area_size等。
默认为启用PGA的自动管理,Oracle根据SGA的20%来动态调整PGA中专用与Work Area部分的内存大小,最小为10MB。
用于实例中各活动工作区(work area)的PGA总量,为PGA_AGGREGATE_TARGET减去其他组件分配的PGA内存。得到的结果,按照特定需求动态分配给对应的工作区。
1)设置PGA_AGGREGATE_TARGET大小的步骤
a.设置PGA_AGGREGATE_TARGET为SGA的20%,对于DSS系统,此值可能过低。
b.运行典型的负载,通过oracle收集的pga统计信息来调整PGA_AGGREGATE_TARGET的值。
c.根据oracle的pga建议调整PGA_AGGREGATE_TARGET大小。
2)禁用自动pga管理
为向后兼容,设置PGA_AGGREGATE_TARGET为0,即禁用pga的自动管理。可使用关联的*_area_size参数调整对应工作区的最大大小。
bitmap_merge_area_size
create_bitmap_area_size
hash_area_size
sort_area_size











