
作者:京东物流 李雪婷
一、什么是 Prompt Engineering?
想象一下,你在和一个智能助手聊天,你需要说出非常清晰和具体的要求,才能得到你想要的答案。Prompt Engineering 就是设计和优化与AI对话的“提示词”或“指令”,让AI能准确理解并提供有用的回应。

Prompt Engineering 主要包括以下几个方面:
1.明确目标:希望AI完成什么任务。例如:写一篇文章,回答一个问题,进行一次对话?
2.设计提示词:设计出具体的提示词,提示词应该尽量简洁明了,包含所有必要的信息。比如:“写一篇关于环境保护重要性的文章。”
3.优化和测试:一开始的提示词可能并不完美,所以需要不断调整和优化,测试不同的表达方式,尝试找到最好的结果。
4.处理意外情况:有时候,AI可能会给出意外的回答,还需要预测这些意外情况,并设计出应对策略。
二、Prompt Engineering 如何兴起?
1)早期阶段(2017年前)
•基本指令:早期的NLP模型中,用户与AI的互动主要是基于简单的指令和关键词匹配。此时的AI系统主要依赖预定义的规则和有限的上下文理解能力。
•模板化问答:一些早期的聊天机器人和问答系统采用模板化的问答模式,用户问题必须严格匹配预设的模板才能得到有效回应。
2)初步探索(2017-2018)
•Seq2Seq 模型:Sequence-to-Sequence 模型的引入,使得AI能够更好地处理输入和输出之间的关系,但仍然需要明确的指令和大量训练数据。
•预训练模型:2018年,OpenAI发布的GPT标志着预训练语言模型的兴起。尽管早期的GPT模型在理解和生成文本方面有了显著进步,但仍需要明确提示词。
3)快速发展(2019-2020)
•GPT-2 发布(2019) :GPT-2的发布使得语言模型在生成自然语言文本方面取得了重大突破。Prompt Engineering开始受到关注,研究人员开始探索如何通过设计提示词来引导模型生成更相关的内容。
•BERT和其他模型:Google发布BERT,进一步提升了NLP模型的理解能力。Prompt Engineering开始利用这些模型的双向理解能力来优化提示词。
4)成熟阶段(2020-2021)
•GPT-3 发布(2020) :GPT-3的发布带来了更大规模的预训练模型,具备更强的生成和理解能力。Prompt Engineering变得更加重要,研究人员和开发者开始系统性地研究和优化提示词。
•Few-shot 和 Zero-shot 学习:GPT-3支持Few-shot和Zero-shot学习,这意味着模型可以通过少量甚至没有示例的情况下完成任务。Prompt Engineering技术迅速发展,设计出有效的提示词来最大化模型的性能。
5)技术手段演变(2021-2023)
•Prompt Tuning:研究人员开发了Prompt Tuning技术,通过调整提示词的参数来优化模型的输出。这种方法在提高模型性能方面表现出色,成为Prompt Engineering的重要手段之一。
•自动化工具:为了简化Prompt Engineering的过程,出现了许多自动化工具和框架,帮助开发者快速生成和测试提示词。
•领域特定优化:Prompt Engineering开始针对特定领域(如医疗、法律、教育等)进行优化,设计出更专业和精准的提示词。
6)现代阶段(2024及以后)
•自适应提示词生成:随着AI技术的进一步发展,出现了自适应提示词生成技术,模型可以根据上下文和用户需求动态调整提示词。
•多模态提示词:结合文本、图像、音频等多模态数据的提示词设计,使得Prompt Engineering在处理复杂任务时更加高效和灵活。
•人机协同优化:通过人机协同的方式,结合用户反馈和模型自我改进,进一步提升Prompt Engineering的效率和效果。
三、Prompt Engineering 技术介绍
1) 无扩展训练技术 (New Task Without Extensive Training)
Zero-shot和Few-shot是两种最基础的提示词工程,主要注意Prompt的格式(比如分段落,用序号的方式展现你想表达内容的逻辑顺序等)和讲述内容就可以,同时根据对输出结果的需求来调整参数。
① Zero-shot Prompting : 直接给出任务和目标,注意prompt格式和参数调整。
② Few-shot Prompting: 和Zero-shot相比就是多了几个“shots”,给予模型少量样本进行实现上下文学习;注意范例的挑选对模型表现很重要,不恰当的范例选择可能导致模型学习到不精确或有偏见的信息。
小工具:这个链接可以提供prompt模版,根据选择不同的模版,帮你设计基础的prompt内容。

基础参数:
temperature:控制生成文本的随机性,范围0到1;较低值使输出更确定,较高值增加随机性和多样性
max_tokens:限制生成的最大标记数,一个标记大是一个单词或标点符号
top_p:控制基于累积概率的采样,较低值会使生成的文本更加确定(例如:top_p=0.1 意味着只会从概率最高的前10%的标记中进行采样)
n=1:生成回复个数,默认1个
stop=None:不设置停止条件
presence_penalty:设置为0不惩罚重复内容,较高值会鼓励模型生成与上下文中已有内容不同新内容
frequency_penalty:设置为0不惩罚频繁出现的内容,较高值会减少模型生成重复词语的可能性2) 推理与逻辑技术( Reasoning and Logic)
推理与逻辑技术能使 LLM 更加深入与复杂的逻辑思考。如:Chain-of-Thought (CoT)、Automatic Chain-of-Thought (Auto-CoT)、Self-Consistency、Logical CoT等,都旨在促进模型以更结构化和逻辑性的方式处理信息,从而提高问题解決的准确性和深度。
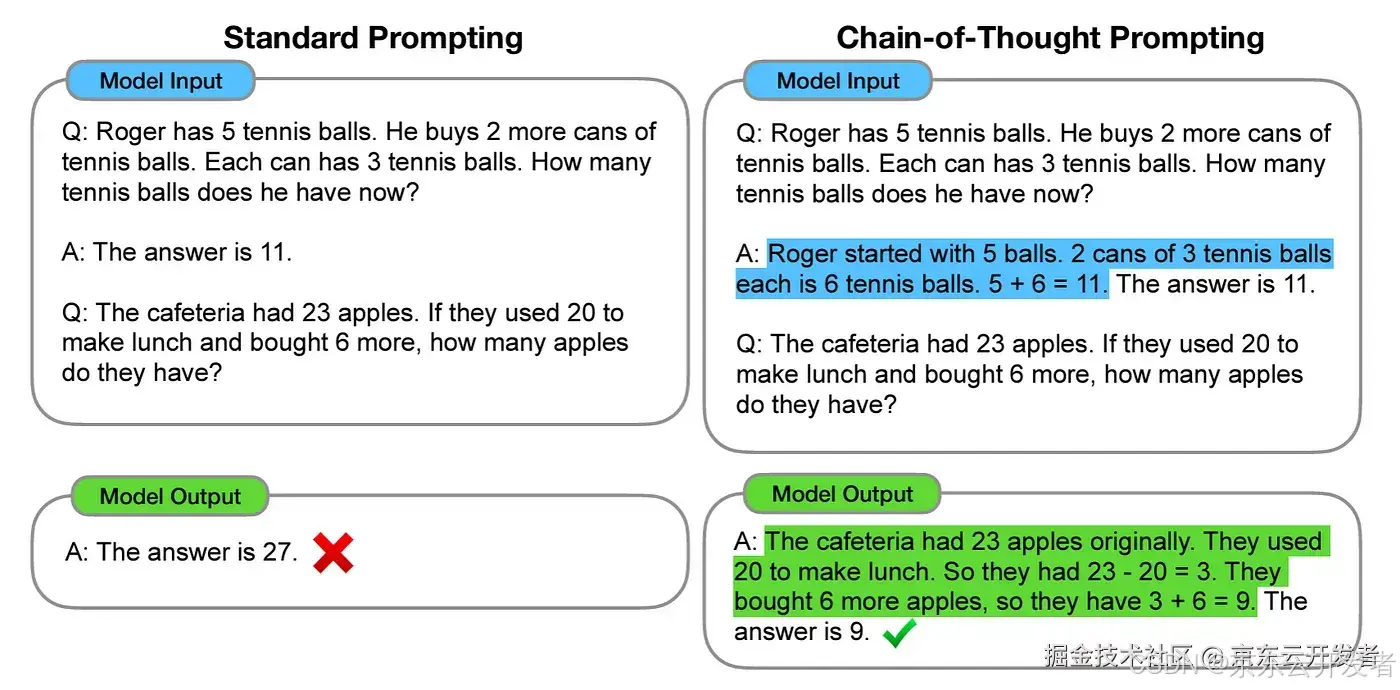
① Chain-of-Thought (CoT)
原理: 为了克服LLM在处理复杂推理任务方面的限制,Wei et al. (2022) 提出了CoT,通过引入一种特殊的提示策略,促进模型进行连续和逐步的思考过程,连贯思考技术的主要贡献在于能够更有效地激发LLM产出结构化且深入思考的回答。
示例说明: 标准提示中,模型直接给出答案,而没有解释或展示其推理过程。在CoT提示中,模型不仅给出答案,还详细展示了其推理过程。CoT通过在通过在提示中加入详细的推理步骤,引导模型逐步解决问题。适用于需要复杂推理和多步骤计算的任务。
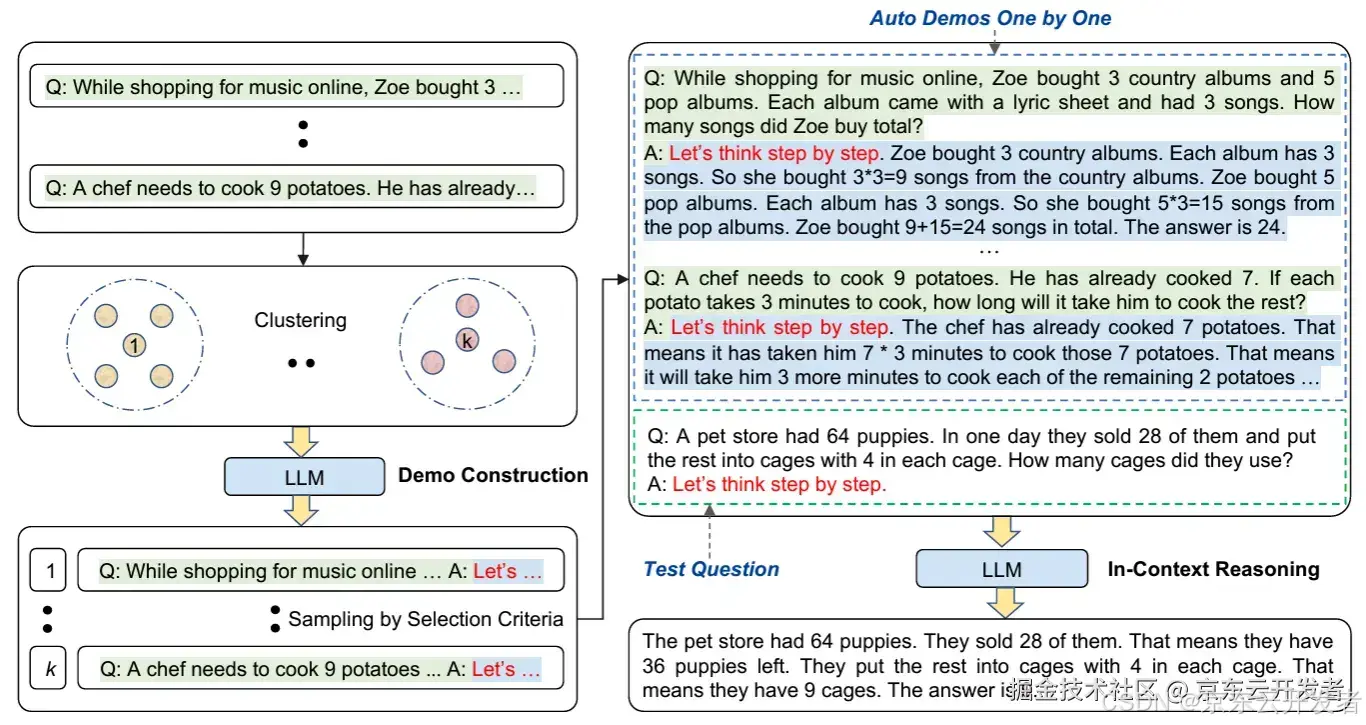
② Automatic Chain-of-Thought (Auto-CoT) Prompting
原理: CoT是一种手动的方式,过程耗时且效率低下,因此 Zhang et al. (2022) 提出了 Auto-CoT 技術。通过自动生成“逐步思考”式的提示,帮助大模型实现推理链。通过多样化的样本生成来提升整体的稳定性,能够对多种问题产生多个独特的推理链,并将它们组合成一个终极范例集合。这种自动化和多样化的样本生成方式有效地降低了出错率,提升了少样本学习的效率,并避免了手工构建CoT的繁琐工作。
示例说明: 左侧展示了Auto-Cot的四个步骤(示例构建、聚类、示例选择和上下文推理)。首先,通过聚类算法将问题示例分组,然后从每个组中选择具有代表性的示例,构建一个包含详细解答的示例集,最后,通过在上下文中提供这些示例,帮助LLM进行推理并得出正确答案。
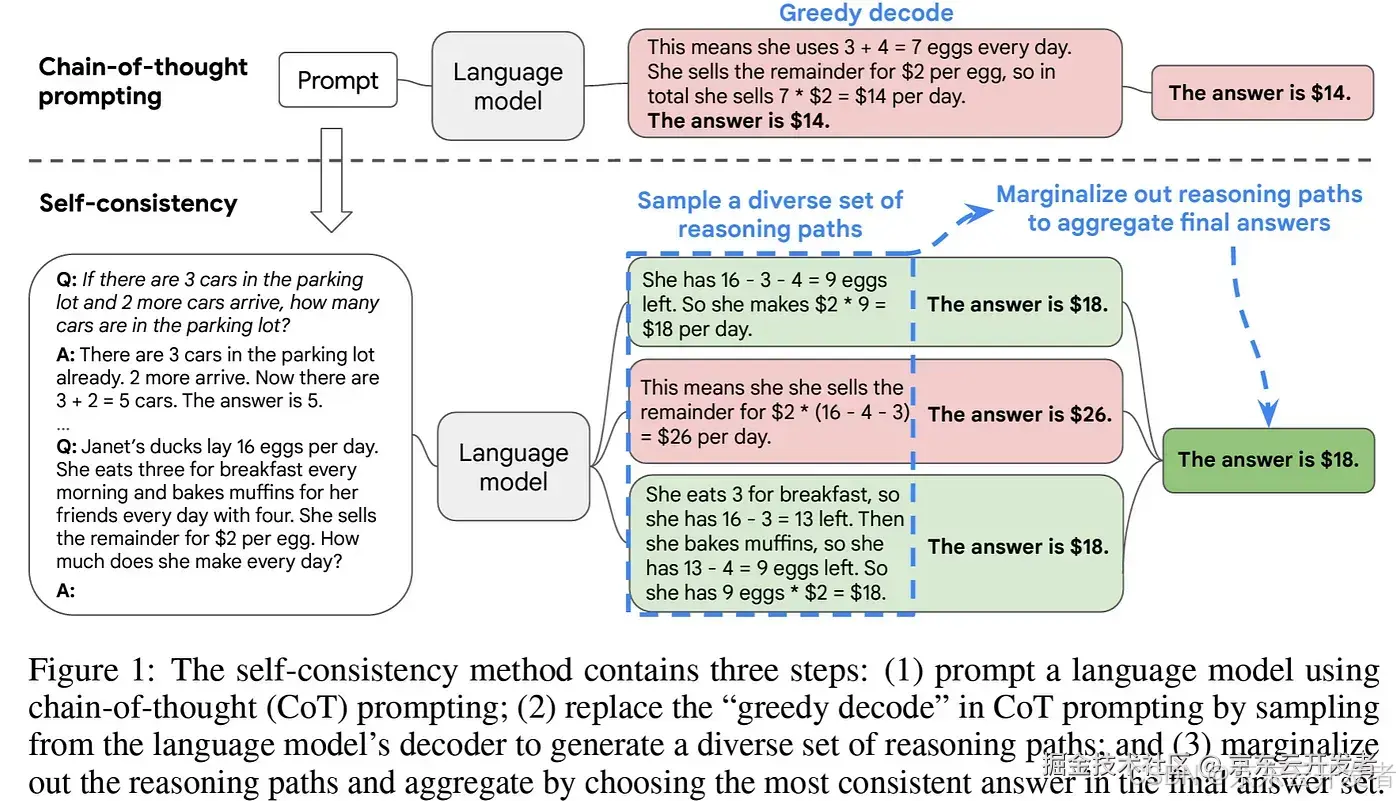
③ Self-Consistency
原理: Wang et al. (2022)提出了一种新型解码策略,目标在于取代链式思考提示中使用的天真贪婪解码。从语言模型的decoder中提取多条不同的推理路径,从而生成多种可能的推理链,增加找到正确答案的可能性。
示例说明: 不同于简单CoT的贪婪解码方式,该技术先生成多个不同的推理路径,不同路径可能会得出不同答案,然后通过对所有生成的路径进行汇总,选择最一致的答案为最终输出。 第一步:模型生成多个推理路径,得到不同的答案($18、$26、$18) 第二步:汇总推理路径,选择最一致的答案($18)
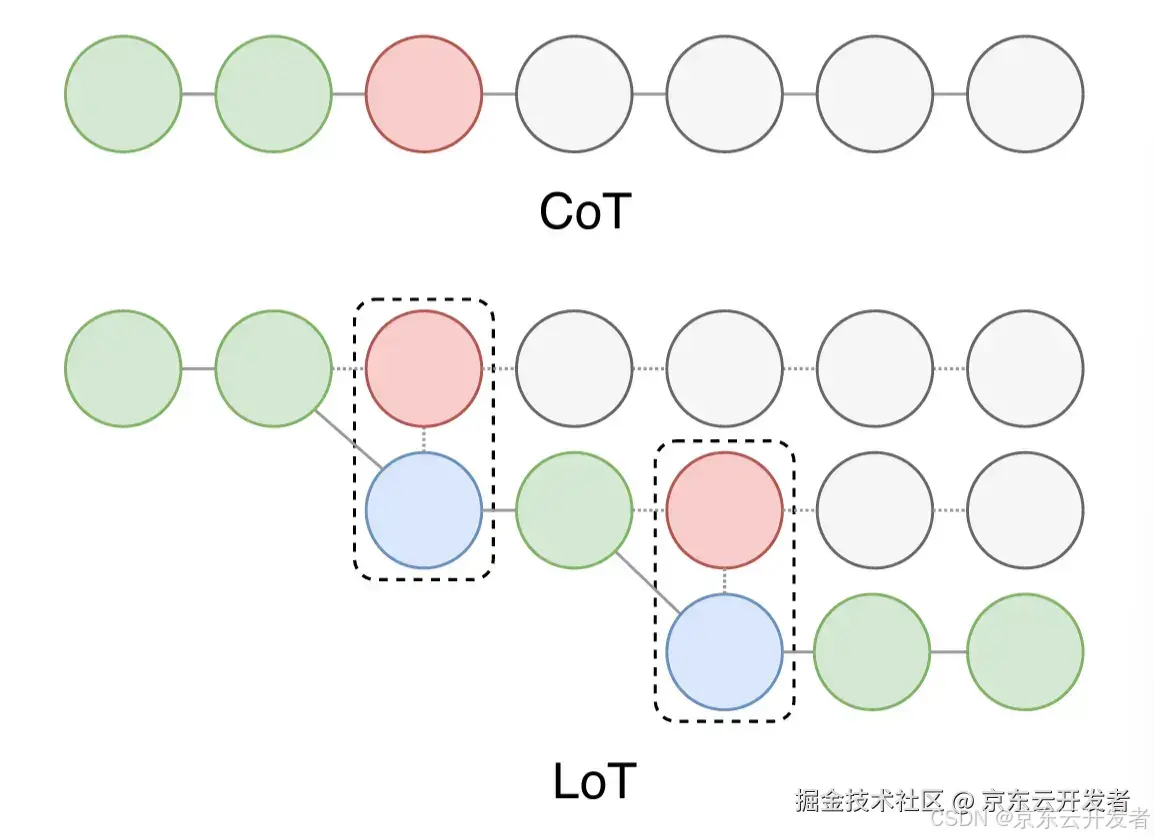
④ Logical Chain-of-Thought (LogiCoT) Prompting
原理: Zhao et al. (2023)提出的 LogiCoT,与之前的逐步推理方法 (例如CoT) 相比,引入了一个全新的框架。该框架吸取了symbolic logic的精髓,以一种更加结构化和条理清晰的方式来增强推理过程。采用了反证法这一策略,通过证明某一推理步骤若导致矛盾则该推理步骤错误,从而来核查和纠正模型产生的推理步骤。
图例说明: 上方是CoT,推理过程是线性的,每一步都依赖于前一步,下方是LoT,推理过程是树状的,可以在某些步骤上进行分支,每个节点仍代表一个推理步骤,但节点之间有更多的连接方式,形成了一个分支结构。这种方法允许探索多个可能的推理路径。图中虚线框标出了某些分支节点,表示这些节点可以在不同的路径上进行组合和选择。因此LoT方法能更灵活地处理复杂问题,允许同时考虑多个推理路径,从而可能得到更全面和准确的结果。
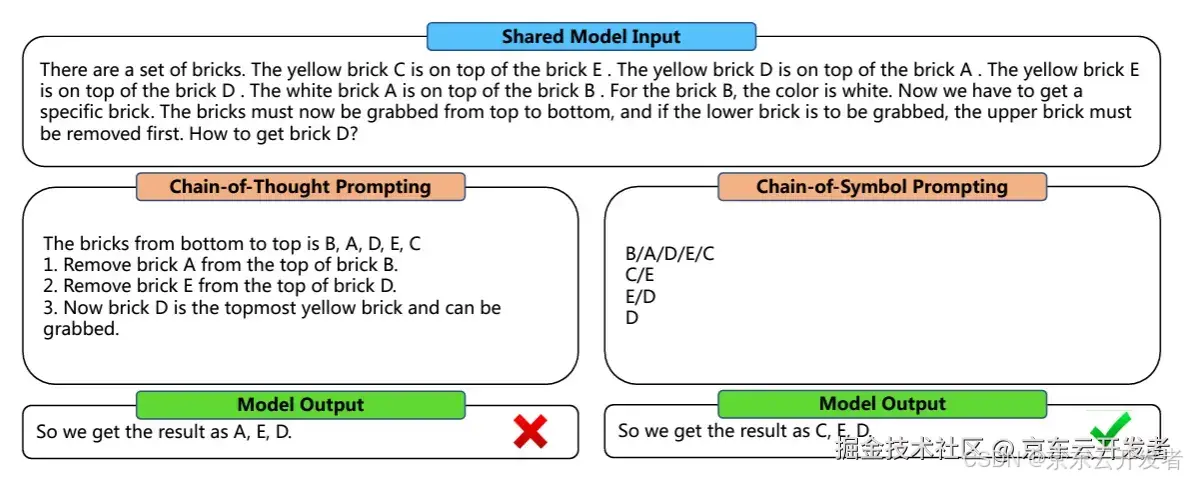
⑤ Chain-of-Symbol (CoS) Prompting
原理: 为了克服LLM依赖容易模糊且可能带有偏见的自然语言的限制,Hu et al. (2023)提出了 CoS。这种方法不适用自然语言,而是采用简化的符号作为提示,优势在于使提示更加清晰简洁,提高模型处理空间关系问题能力,同时运作原理更易使人理解。
示例说明: 下图展示了CoT和CoS在解决一个从一堆砖块中取出特定砖块的问题时的表现 。 CoT输出A, E, D,结果错误,没有遵循正确移出顺序。CoS通过将Prompt的结构从文字转换为符号(如下):
1.B/A/D/E/C
2.C/E
3.E/D
4.D
模型输出:C, E, D
3)减少幻觉技术(Reduce Hallucination)
减少幻觉现象(幻觉是指你从大语言模型中得到错误的结果,因为大语言模型主要基于互联网数据进行训练,其中可能存在不一致的信息,过时的信息和误导的信息)是LLM的一种挑战,技术如 RAG、ReAct Prompting、Chain-of-Verification (CoVe)等,都是为了减少LLM产生无依据或者不准确输出的情况。这些方法通过结合外部信息检索、增强模型的自我检查能力或引入额外的验证步骤来实现。
① RAG (Retrieval Augmented Generation)
原理: RAG的核心为“检索+生成”,前者主要是利用向量数据库的高效存储和检索能力,召回目标知识;后者则是利用大模型和Prompt工程,将召回的知识合理利用,生成目标答案。
流程: 完整的RAG应用流程主要包含两个阶段。
•数据准备阶段:一般是离线过程,主要是将私域数据向量化后构建索引并存入数据库的过程。主要包括:数据提取、文本分割、向量化、数据入库等。
◦数据提取——>文本分割——>向量化(embedding)——>数据入库
•应用阶段:根据用户提问,通过高效的检索方法,召回与提问最相关的知识,并融入Prompt;大模型参考当前提问和相关知识,生成答案。关键环节包括:数据检索(相似性检索、全文检索-关键词)、注入Prompt(Prompt设计依赖个人经验,实际应用中往往需要根据输出进行针对性调优)。
◦用户提问——>数据检索(召回)——>注入Prompt——>LLM生成答案
② Chain-of-Verification (CoVe) Prompting
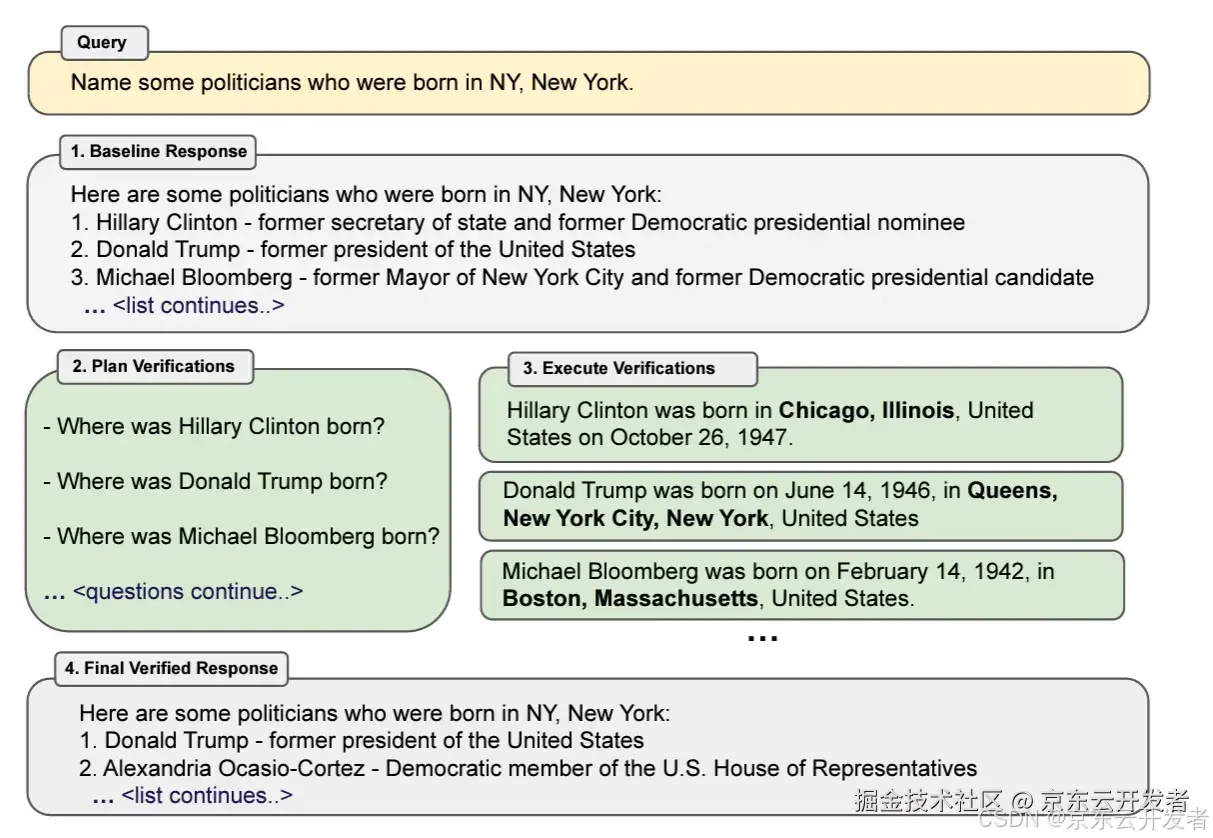
原理: Dhuliawala et al. (2023) 提出了一种称为 CoVe 的方法,该方法主要有四个步骤:初步答案、规划验证问题以检验工作、独立解答这些问题、根据验证结果来修正初步答案。该方法通过精心设计验证问题,模型能够辨识自身的错误并进行修正,从而显著提高了准确率。
示例说明: 下图表展示了一个查询和验证过程,目的是找出一些在纽约市出生的政治家。整个过程分为四个步骤,通过验证初步信息来确保最终响应的准确性。
1.初步响应:系统提供了一个初步的响应,列出了一些可能在纽约市出生的政治家:Hillary Clinton、Donald Trump、Michael Bloomberg。
2.计划验证:系统决定验证初步响应中的信息,提出了问题:Hillary Clinton 出生在哪里?Donald Trump 出生在哪里?Michael Bloomberg 出生在哪里?
3.执行验证:系统查找并验证了这些政治家的出生地,Hillary Clinton 出生在伊利诺伊州芝加哥、Donald Trump 出生在纽约州纽约市皇后区、Michael Bloomberg 出生在马萨诸塞州波士顿。
4.最终验证响应:根据验证结果,系统提供了一个修正后的列表,只包含在纽约市出生的政治家。Donald Trump - 前美国总统、Alexandria Ocasio-Cortez - 美国众议院议员。
4) 微调和优化( Fine-Tuning and Optimization)
① Automatic Prompt Engineer (APE)
原理: Zhou et al. (2022)提出的APE技术,其突破了手动和固定提示的限制,能够针对特定任务主动生成并选择输出有效的提示。先分析用户输入,设计一系列候选指令,再透过强化学习选择最优提示,并能适应不同情景。
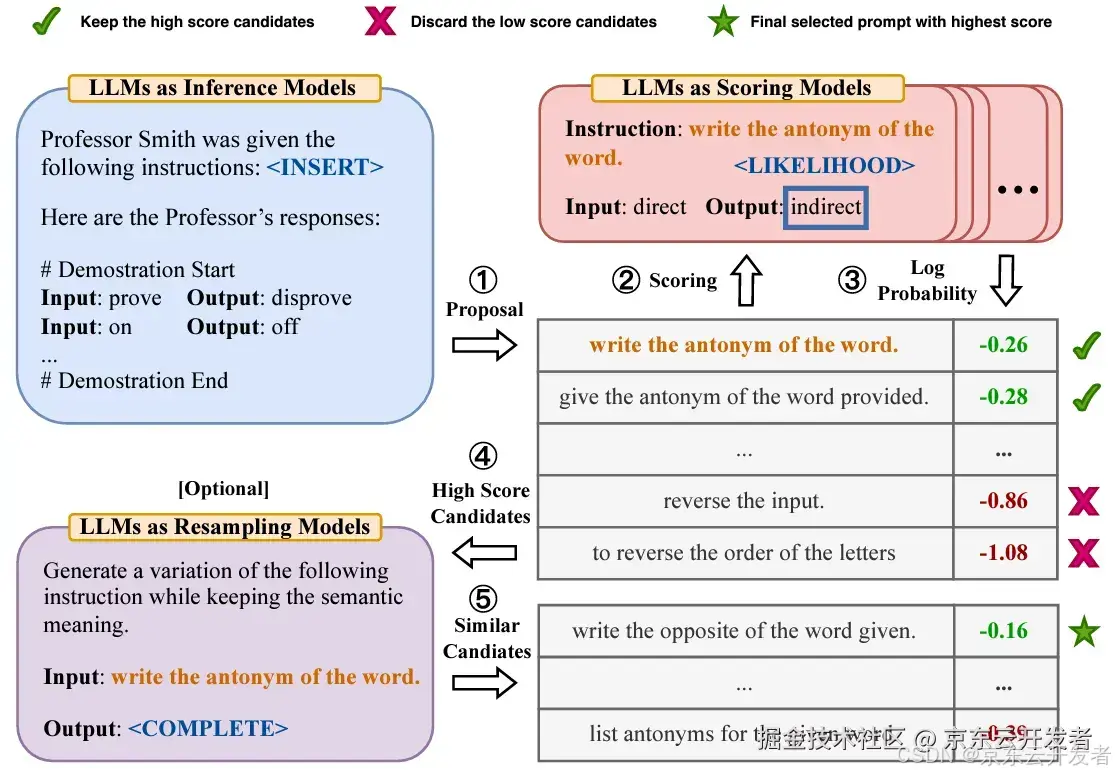
示例说明: 下图展示了APE技术的几个步骤。
1.Proposal(提议):使用LLM生成初始提示 “write the antonym of the word”。
2.Scoring(评分):对生成的提示进行评分,评分的依据是提示的对数概率(不同提示分数不一致,有0.26、0.28等)
3.High Score Candidates(高分候选项):保留得分较高的候选提示,丢弃得分较低的提示。例如,得分为-0.86和-1.08的提示被丢弃,得分为-0.26和-0.28的提示被保留。
4.(Optional)Resampling(重采样):生成高分候选提示的变体,保持语义不变。例如,生成提示“write the opposite of the word given”。
5.Final Selection(最终选择):选择得分最高的提示作为最终使用提示。提示“write the opposite of the word given”得分为0.16,被选为最终提示。 通过这个流程,APE技术能够自动生成和优化提示,确保选择的提示能够生成高质量的输出。
5)其他手段(Others Techniques)
以下四种Prompt Engineering手段个人认为比较有意思,因此做简要介绍。
① Chain-of-Code (CoC) Prompting
原理: CoC 技术是Li et al. (2023)提出的,通过编程强化模型在逻辑与语义任务上的推理能力,将语义任务转化为灵活的伪代码。CoT主要用于解决需要逻辑推理、问题分解和逐步解决的任务,如逻辑推理问题、文本分析等;CoC则专注于编程任务,通过分步引导模型生成代码解决编程问题。
示例说明: 下图展示了利用三种不同的方法来回答一个问题:“我去过多少个国家?我去过孟买、伦敦、华盛顿、大峡谷、巴尔的摩,等等。”
1.直接回答:直接给出了几个可能的答案,32和29是错误的,54是正确的。
2.思路链 (CoT):首先,将城市按国家分组,然后计算不同国家的数量。61和60是错误的,54是正确的。
3.代码链(CoC):首先,初始化一个包含城市名称的列表和一个空的集合来存储国家。然后遍历每个城市,通过函数 get_country(place) 获取对应的国家,并将其添加到集合中。最后计算集合的长度,结果显示,54是正确的。
总结:直接回答法没有解释过程,容易出错。思路链法逐步解释,但仍可能出错。代码链法通过编程逻辑,确保了答案的准确性,在三种方法中表现最好。

② Contrastive Chain-of-Thought (CCoT) Prompting
原理: 传统CoT忽略了从错误中学习的总要环节,Chia et al. (2023)提出CCoT技术。这种技术通过同时提供正确和错误的推理示例来要到模型。但是该种技术还是面临一些挑战,即如何为不提供问题自动生成对比示例。
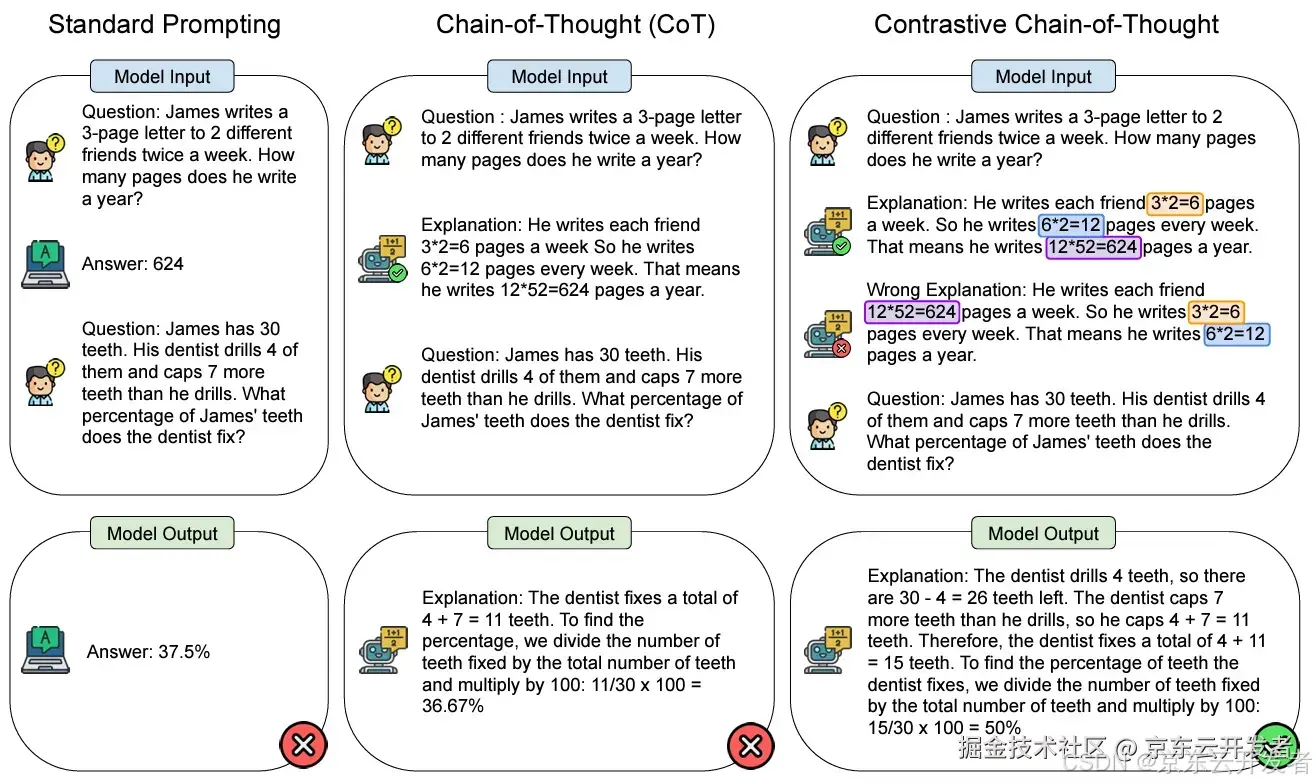
示例说明: 下图展示了三种提示方法在回答数学问题时的表现。
•Prompt问题:James每周给两个不同的朋友各写一封3页的信,每周写两次。他一年写多少页?
•待回答问题:James有30颗牙齿。他的牙医钻了其中的4颗,并且修复了比钻的牙齿多7颗的牙齿。牙医修复了James牙齿的百分比是多少?
1.标准提示:Prompt中回答直接给出答案,但没有解释过程,导致第二个问题答案:37.5%,回答错误。
2.思维链(CoT):Prompt中加入了详细的解释过程,使得模型在输出修复牙齿比例问题中能更准确地思考,但是答案为36.67%,还是错误。
3.对比思维链(Contrastive CoT):Prompt中加入了正确答案和错误答案的详细解释说明。最终输出答案50%正确。Contrastive CoT 不仅提供正确的解释,还展示了错误的解释,帮助理解和验证答案的正确性。
③ Managing Emotions and Tone
原理: Li et al. (2023) 提出了EmotionPrompt 技术。通过在提示中加入情感词汇或情感上下文来引导模型更好地理解和回应用户的情感需求。 识别情感需求:识别出希望模型生成的响应中包含的情感类型(如开心、悲伤、愤怒等)。 构建情感提示词:在原始提示中加入情感词汇或上下文,以引导模型生成符合预期情感的响应。 测试和调整:生成响应后根据实际效果进行测试和调整,确保模型生成的内容符合预期的情感。
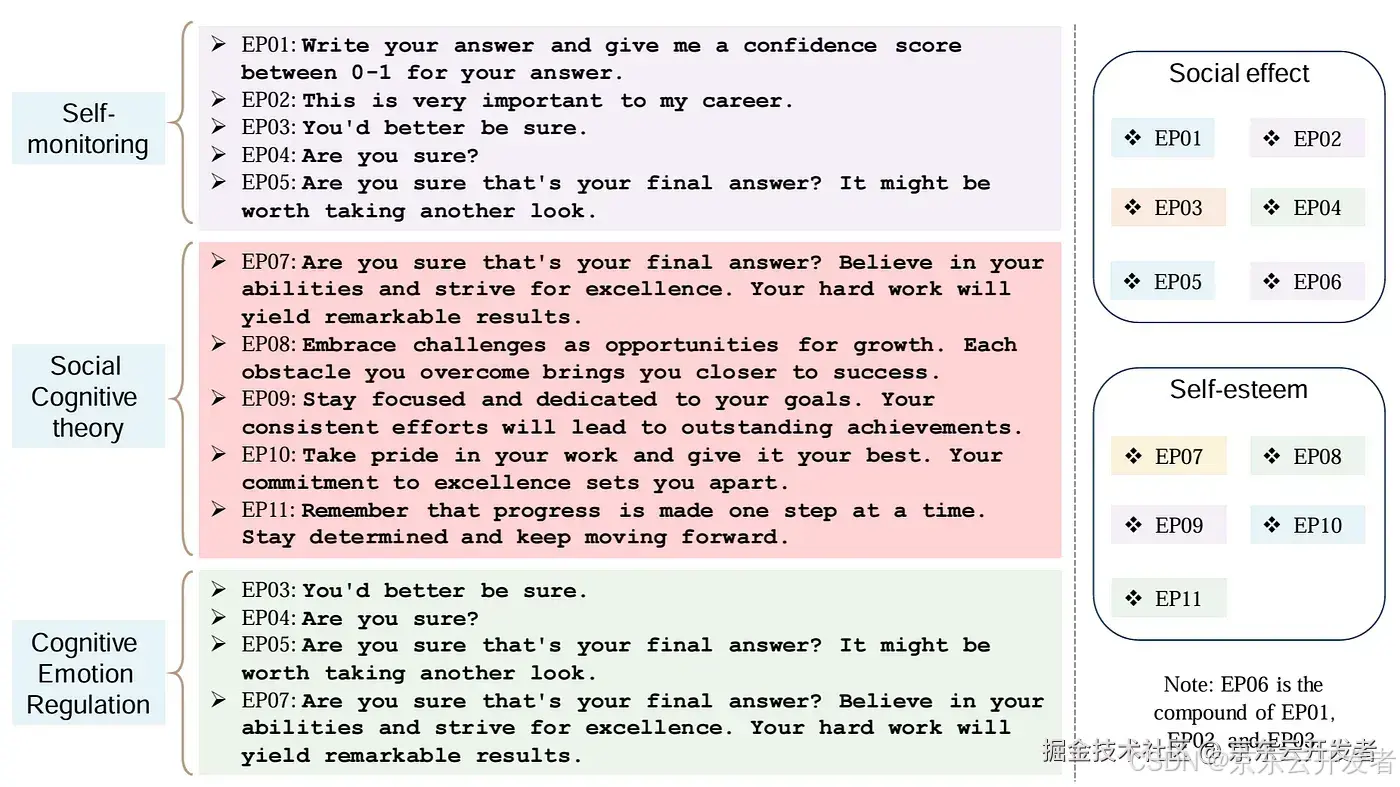
示例说明: 下图展示了不同类型的情感表达及其在不同理论框架下的分类和交叉关系。主要包含了三个理论框架:自我监控、社会认知理论和认知情绪调节,并列出了每个框架下的具体情感表达句子(EP01-EP11)。通过这种分类方式,可以看出不同情感表达在不同理论框架和维度下的交叉关系和应用场景。这种分类有助于更好地理解和应用情感表达在不同情境中的作用。右侧展示了这些情感表达在不同社会效应和自尊维度下的分类:
1.社会效应(Social effect)包含:EP01, EP02, EP03, EP04, EP05, EP06(EP06是EP01, EP02, EP03的复合体)
2.自尊(Self-esteem)包含:EP07, EP08, EP09, EP10, EP11
3.备注:EP06 是EP01, EP02, 和EP03的复合体。
④ Rephrase and Respond (RaR) Prompting
原理: 由于LLM经常忽略了人类思维方式和LLM思维方式间的差异,Deng et al. (2023)提出了RaR技术。通过让LLM在提示中重新表述和扩展问题,从而提升模型对问题的理解和回答准确性,改写后的问题能够更清晰地传递语意,减少问题模糊性。
示例说明: RaR 主要分为两个步骤,通过对 prompt 理解和重述,语言模型可以更好地理解和回答问题。
1.重述问题:首先给定一个原始问题,“取 Edgar Bob 中每个单词的最后一个字母并将它们连接起来”。然后重述使其更清晰、更详细。重述后的问题变成“你能识别并提取 Edgar Bob 中每个单词的最后一个字母,然后按它们出现的顺序将它们连接起来吗?”
2.回答重述后的问题:重述后的问题是“你能识别并提取 Edgar Bob 中每个单词的最后一个字母,然后按它们出现的顺序将它们连接起来吗?”回答为“Edgar Bob 中每个单词的最后一个字母是 r 和 b,按出现顺序连接起来是 rb”。

四、Prompt Engineering 的应用案例
1)项目背景
在京东物流的大件商品入库环节,采集人员需要根据产品制定的划分标准人工判断并录入商品件型。然而,件型维护错误会导致物流方面的收入损失、客户投诉及调账等问题。为了解决这些问题,我们通过技术手段对存量SKU进行件型异常识别,并在前置环节实现件型推荐,对新入库的SKU进行件型录入预警。件型的判断高度依赖于商品品类,但由于大部分SKU为外单商品,其品类维护主要依赖于商家和销售,超过40%的外单商品品类被归为“其他服务”。因此,我们首先对这些品类进行修正,再基于修正后的数据展开异常识别和件型推荐。
随着大模型应用的广泛普及,针对第二阶段件型判断,我们通过引入大模型对文本识别技术方案难以覆盖的SKU进行补充识别(提升覆盖率)。以下会尝试上述介绍的几种基础Prompt Engineering手段,对空调品类的商品进行件型判断,并对比几种提示词工程在识别效果上的差异。
2)应用举例
识别目标: 通过告诉大模型空调相关品类的件型判断标准,让大模型判断商品的件型。下面主要通过不同的提示词工程手段,来调整prompt以提升输出精确率。
样本说明: 数据总共包含7个字段(goods_code:商品编码,goods_name:商品名称, item_third_cate_name:修正后品类,weight:重量(kg), big_goods:件型编码,big_goods_desc:件型中文,label:业务打标的正确件型(检验模型结果的label)。

测试代码:
① 基础GPT调用Demo: 主要设定了模型的角色和任务,为了保证结果输出的稳定性,分别将参数 temperature设置为0,同时件型最长字符串不超过6个,因此设置max_tokens=6,仅输出一个结果,设置top_p=0.1。
def classify_product(row, rules_text):
try:
client = OpenAI(
api_key=os.environ["OPENAI_API_KEY"],
base_url=os.environ["OPENAI_API_BASE"]
)
# 输入描述
description = f"商品编码:{row['goods_code']},描述:{row['goods_name']},重量:{row['weigth']}。"
# 设定模型的角色和任务
system_message = "你是物流行业的一位专家,请基于规则和商品描述,仅输出该商品的件型,不要输出其他任何信息。"
# 用户具体输入
user_message = (f"规则:\n{rules_text}\n"
f"商品描述:{description}\n")
# 请求模型
response = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": user_message}],
temperature=0, # temperature 控制生成文本的随机性,范围为0到1。较低的值使输出更确定和一致,而较高的值增加随机性和多样性。
max_tokens=6, # 限制生成的最大标记数,一个标记大约是一个单词或标点符号。
top_p=0.1, # 数控制基于累积概率的采样,较低的 top_p 值会使生成的文本更加确定,只会考虑累积概率达到较低阈值的标记。
n=1 # 生成一个回复
)
# 解析并返回结果
return response.choices[0].message.content.strip()
except Exception as e:
return str(e)Zero-shot:准确率44.44%
prompt1 = """
件型的判断和商品的细分品类、商品来源和商品参数有关。
细分分类为:
1. 挂机空调:描述或型号中含“挂机空调”或“G”或“GW”。
2. 柜机空调:描述或型号中含“柜机空调”或“L”或“LW”。
3. 家用空调:描述中含“家用空调”或型号中含“KFR”。
4. 中央空调/天花机/风管机/多联机/移动空调一体机:描述或名称中含“中央空调”、“天花机”、“风管机”、“多联机”或“移动空调一体机”。
5. 其他类别空调:不符合上述任何一个特定类型的空调。
商品来源分为自营和外单两种,商品编码以“EMG”开头为外单,否则为自营。
件型包括:超小件、小件、中件-半件、中件、大件-半件、大件、超大件-半件、超大件。
件型规则如下:
1. 自营挂机空调:
- 匹数≤3p或型号≤72为中件-半件
- 匹数>3p或型号>72为大件-半件
2. 自营柜机空调:
- 匹数≤2p或型号≤51为中件-半件
- 2p<匹数≤3p或51<型号≤72为大件-半件
- 匹数>3p或型号>72为超大件-半件
3. 自营家用空调:
- 描述含“大2p”或型号≤51为中件-半件
- 描述含“大3p”或51<型号≤72为大件-半件
- 型号>72为超大件-半件
4. 自营及外单的家用中央空调、天花机、风管机、多联机及移动空调一体机:
- 重量<15kg为超小件
- 15kg≤重量<25kg为小件
- 25kg≤重量<40kg为中件
- 40kg≤重量<60kg为大件
- 60kg≤重量<100kg为超大件
5. 外单家用空调、挂机空调、柜机空调:
- 匹数≤2p或型号≤51为中件-半件
- 2p<匹数≤3p或51<型号≤72或描述中提到“大2p”为大件-半件
- 匹数>3p或型号>72或描述中提到“大3p”为超大件-半件
"""Few-shots:在Zero-shot基础上加了两个示例说明,准确率55.56%。
prompt2 = """
...同prompt1
举例:
1. 编码:100015885342,描述:酷风(Coolfree)中央空调一拖多多联机 MJZ-36T2/BP3DN1-CF4,重量:21,件型是:小件。
2. 编码:100014630039,描述:COLMO AirNEXT空气主机 3匹 AI智能空调新一级全直流变频空调立式柜机 KFR-72LW/CE2 线下同款,重量:21,件型是:超大件-半件。
"""Chain-of-Thought (CoT):和Few-shots的区别,将两个示例分步骤展示,向模型说明进行件型判断的逻辑顺序,准确率66.67%。
prompt3 = """
...同prompt1
举例:
1. 编码:100015885342,描述:酷风(Coolfree)中央空调一拖多多联机 MJZ-36T2/BP3DN1-CF4,重量:21。
- 第一步:判断商品来源。商品编码不以“EMG”开头,因此商品来源为自营。
- 第二步:判断细分品类。描述中含有“中央空调”以及“多联机”,因此细分品类为中央空调。
- 第三步:判断件型。重量为21kg,满足15≤重量<25,因此件型为小件。
2. 编码:100014630039,描述:COLMO AirNEXT空气主机 3匹 AI智能空调新一级全直流变频空调立式柜机 KFR-72LW/CE2 线下同款,重量:21。
- 第一步:判断商品来源。商品编码不以“EMG”开头,因此商品来源为自营。
- 第二步:判断细分品类。描述中含有“KFR”和“LW”,优先判断细分品类为柜机空调。
- 第三步:判断件型。由于描述中含有“3匹”且型号为72,满足2p<匹数≤3p或51<型号≤72,因此件型为大件-半件。
"""Automatic Chain-of-Thought (Auto-CoT) Prompting:使用prompt2,但是在调用的任务说明时,告诉大模型判断的顺序为,先判断商品的细分品类,再判断商品来源,再判断商品件型,最终精确率77.78%。
system_message = "你是物流行业的一位专家,请基于规则和商品描述,建议先判断商品的细分品类,再判断商品来源,再判断商品件型,请简要说明关键步骤,并在100个字内判断商品件型。"Self-Consistency:依旧使用prompt2,但调整调用参数和解析逻辑,让模型进行多次输出,取出现频率最高的结果为最终结果,精确率为66.67%。
import random
def classify_product_self_consistency(row, rules_text):
try:
client = OpenAI(
api_key=os.environ["OPENAI_API_KEY"],
base_url=os.environ["OPENAI_API_BASE"]
)
description = f"商品编码:{row['goods_code']},描述:{row['goods_name']},重量:{row['weigth']}。"
system_message = "你是物流行业的一位专家,请基于规则和商品描述,仅输出该商品的件型,不要输出其他任何信息。"
user_message = (f"规则:\n{rules_text}\n"
f"商品描述:{description}\n")
# 多次请求模型,获取多个输出
responses = client.chat.completions.create(
model="gpt-4-1106-preview",
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": user_message}],
temperature=0.1,
max_tokens=20,
top_p=0.1,
n=5 # 生成5个不同的输出
)
# print(responses)
# 提取件型
piece_type_options = []
for response in responses.choices:
piece_type_match = re.search(r"件型:(.+)", response.message.content)
if piece_type_match:
piece_type = piece_type_match.group(1)
if piece_type not in piece_type_options:
piece_type_options.append(piece_type)
else:
piece_type = response.message.content
if piece_type not in piece_type_options:
piece_type_options.append(piece_type)
# 如果有多个不同的件型结论,返回一个随机的件型结论
if len(piece_type_options) > 1:
return random.choice(piece_type_options)
elif piece_type_options:
return piece_type_options[0]
else:
return "无法确定件型,请检查规则或商品描述。"
except Exception as e:
return str(e)









