

点击右侧关注,大数据开发领域最强公众号!


点击右侧关注,暴走大数据!

检测系统瓶颈
- 性能调优
创建一项基线,用来评估系统的首次运行性能(即集群默认配置)
分析Hadoop计数器,修改,调整配置,并重新执行任务,与基线进行比较
重复执行第2步,直到最高效率
识别资源瓶颈
内存瓶颈
当发现节点频繁出现虚拟内存交换时表示出现了内存瓶颈
CPU瓶颈
通常情况下,处理器负载超过90%,在多处理器系统上整体负载超过50%
判断是否是单个特定线程独占了CPU
IO瓶颈
磁盘持续活动率超过85%(也有可能是由CPU或内存导致)
网络带宽瓶颈
在输出结果或shuffle阶段从map拉取数据时
识别资源薄弱环节
检查Hadoop集群节点健康状况
检查JobTracker页面中是否存在黑名单,灰名单和被排除的节点
灰名单节点会间歇性发生故障从而影响作业运行,应尽快处理(排除或修复)
检查输入数据的大小
当输入数据变大时会导致任务运行时间变长
检查计数器中的
HDFS_BYTES_WRITTEN,Reduce shuffle bytes,Map output bytes,Map input bytes检查海量IO和网络阻塞
如果在读取数据时出现网络或IO瓶颈,会导致计算资源被迫等待
检查
FILE_BYTES_READ,HDFS_BYTES_READ来判断是否是输入引起的检查
Bytes Writeen,HDFS_BYTES_WRITTEN来判断是否是写入引起的通过压缩数据和使用combiner
检查并发任务不足
集群中CPU核处于闲置状态
IO核网络利用率不足
检查CPU过饱和
当低优先级任务经常等待高优先任务运行时发生过饱和,体现为过多的上下文切换
使用
vmstat显示上下文切换情况(cs=context switch)可能由于在主机上运行了过多的任务
强化Map&Reduce任务
强化Map任务
通过单个map的写入文件大小和任务处理时间得出
发生大量溢写时会产生性能问题和读取过载,比较Map output records < Spilled Records
需要精确分配内存缓冲区
二进制文件和压缩文件本质上不基于块,因此不能拆分
小文件会产生大量并行任务来处理,会浪费很多资源
处理小文件的最好方法是打包为大文件
使用Avro对数据序列化来创建容器文件
使用HAR格式文件
使用序列文件把小文件存储成单个大文件
如果数据集很大但数据块很小会导致mapper过多,需要花时间进行拆分;因此输入文件大则数据块大小也要加大
大的数据块会加速磁盘IO,但会增加网络传输开销,因而在Map阶段造成记录溢写
Map任务的流程
输入数据和块大小的影响
处置小文件和不可拆分文件
在Map阶段压缩溢写记录
计算Map任务的吞吐量
Read阶段:从HDFS读取固定大小(64M)的数据块
Map阶段:需要测量整个Map函数执行时间和处理的记录数。来判断是否有某个Map处理了超常规数据;过多的文件数量(小文件)或者过大的文件大小(单个不可拆分的文件)
Spill阶段:对数据进行本地排序,并针对不同的reduce进行划分,同时如果有可用的combiner则进行合并,然后把中间数据写入磁盘
Fetch阶段:把Map的输出缓冲到内存,记录产生的中间数据量
Merge节点:针对每一个reduce任务,把Map输出合并成单个溢写文件
强化Reduce任务
压缩排序和合并的数据量(combiner,数据压缩,数据过滤)
解决本地磁盘问题和网络问题
最大化内存分配以尽可能把数据保留在内存而不是输出到磁盘
造成Reduce低速的原因可能是未经优化的reduce函数,硬件问题或者不当的Hadoop配置
通过输入Shuffle除以Reduce运行时间得到吞吐量
Reduce任务的流程
计算Reduce吞吐量
改善Reduce执行阶段
Shuffle阶段:Map任务向Reduce传输中间数据,并对其进行合并和排序
Reduce阶段:测量每个数据键及其对应的所有值上运行reduce函数的耗时
Write阶段:将结果输出到HDFS
- 调优Map和Reduce参数
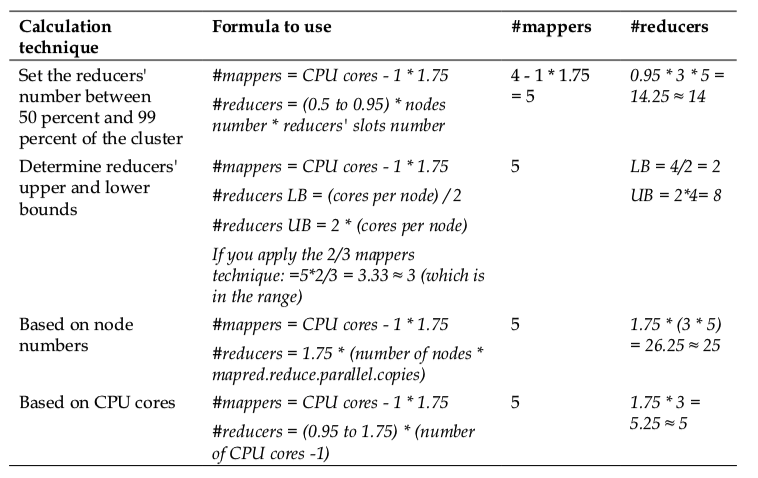
优化MapReduce任务
使用Combiner
类似于本地Reduce操作,可以提升全局Reduce操作效率
习惯上一般直接把reduce函数当做Combiner,逻辑需满足交换律和结合律
Combiner会在Map函数生成的键值对收集到列表,并经过Combiner运算直到Combiner缓冲区达到一定数目时,才会发送给reduce。因此在数据量非常大的情况下可以很好的改善性能
使用压缩技术
输入压缩:在有大量数据且计划重复处理时,应考虑输入压缩。Hadoop会自动对合适扩展名的文件启用压缩和解压
压缩Mapper输出:当map任务中间数据量大时,应考虑在此阶段启用压缩。能改善Shuffle过程,降低网络开销
压缩Reducer输出:可以减少要存储的结果数据量,同时降低下游任务的输入数据量
如果磁盘IO和网络影响了MR作业性能,则在任意阶段(压缩输入,Mapper或Reduce输出)启用压缩都可以改善处理时间,减小IO和网络开销
使用正确的Writable类型
通过使用FileInputFormat实现原始字节比WriteableComparable更有优势
使用Text而不是String来消除字符串拆分所花的时间
使用VIntWritable或者VLongWritable有时比使用int和long更快
在代码中使用正确的可写类型能提高MR作业整体性能
在Shuffle和Sort阶段,中间键的比较可能会成为瓶颈
复用类型
复用已存在的实例比创建新的代价更低
尽量避免创造短生命周期的对象,会造成GC压力变大
开启JVM复用,降低新启动JVM造成的开销
优化Mapper和Reduce代码
用更少的时间获得相同的输出
在相同的时间内用更少的资源获得相同的输出
在相同的时间内用相同的资源获得更多的输出
欢迎点赞+收藏+转发朋友圈素质三连

文章不错?点个【在看】吧!** 👇**
本文分享自微信公众号 - 大数据技术与架构(import_bigdata)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











