
Hive
前言
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的 SQL 查询功能,将类 SQL 语句转换为 MapReduce 任务执行。
数据组织格式
下面是直接存储在HDFS上的数据组织方式
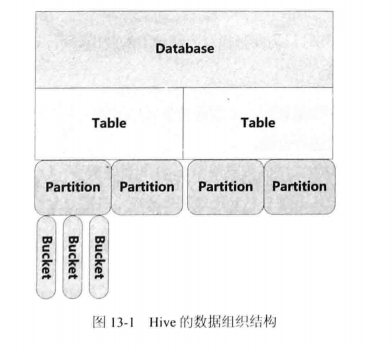
- Table:每个表存储在HDFS上的一个目录下
- Partition(可选):每个Partition存储再Table的子目录下
- Bucket(可选):某个Partition根据某个列的hash值散列到不同的Bucket中,每个Bucket是一个文件
用户可以指定Partition方式和Bucket方式,使得在执行过程中可以不用扫描某些分区。看上去Hive是先指定Partition方式,再在相同的Partition内部调用hash函数;GreenPlum是先指定Hash方式,在Hash分片内部,指定不同的分区方式。
Hive 架构
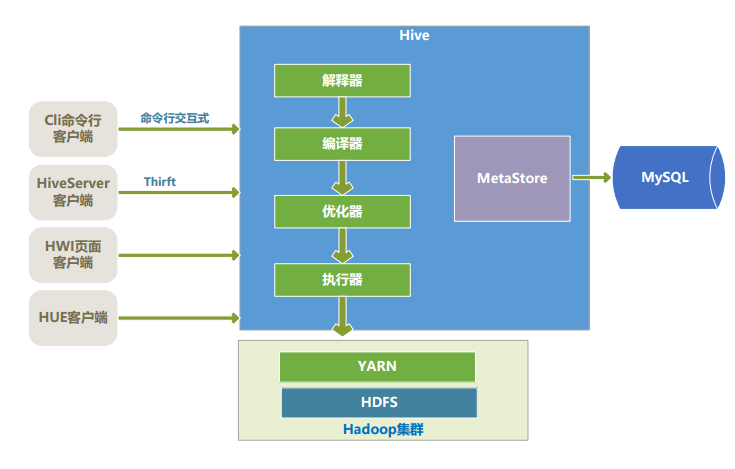
由上图可知,hdfs和 mapreduce 是 hive 架构的根基。
- MetaStore:存储和管理Hive的元数据,使用关系数据库来保存元数据信息。
- 解释器和编译器:将SQL语句生成语法树,然后再生成DAG,成为逻辑计划
- 优化器:只提供了基于规则的优化
- 列过滤:只查询投影列
- 行过滤:子查询where语句包含的partition
- 谓词下推:减少后面的数据量
- Join方式
- Map join:一大一小的表,将小表广播(指定后在执行前统计,没有数据直方图)
- shuffle join:按照hash函数,将两张表的数据发送给join
- sort merge join:排序,按照顺序切割数据,相同的范围发送给相同的节点(运行前在后台创建立两张排序表,或者建表的时候指定)
- 执行器:执行器将DAG转换为MR任务
Hive 特点
- Hive 最大的特点是 Hive 通过类 SQL 来分析大数据,而避免了写 MapReduce 程序来分析数据,这样使得分析数据更容易
- Hive 是将数据映射成数据库和一张张的表,库和表的元数据信息一般存在关系型数据库上(比如 MySQL)
- Hive 本身并不提供数据的存储功能,数据一般都是存储在 HDFS 上的(对数据完整性、格式要求并不严格)
- Hive 很容易扩展自己的存储能力和计算能力,这个是继承自 hadoop 的(适用于大规模的并行计算)
- Hive 是专为 OLAP 设计,不支持事务
Hive 流程
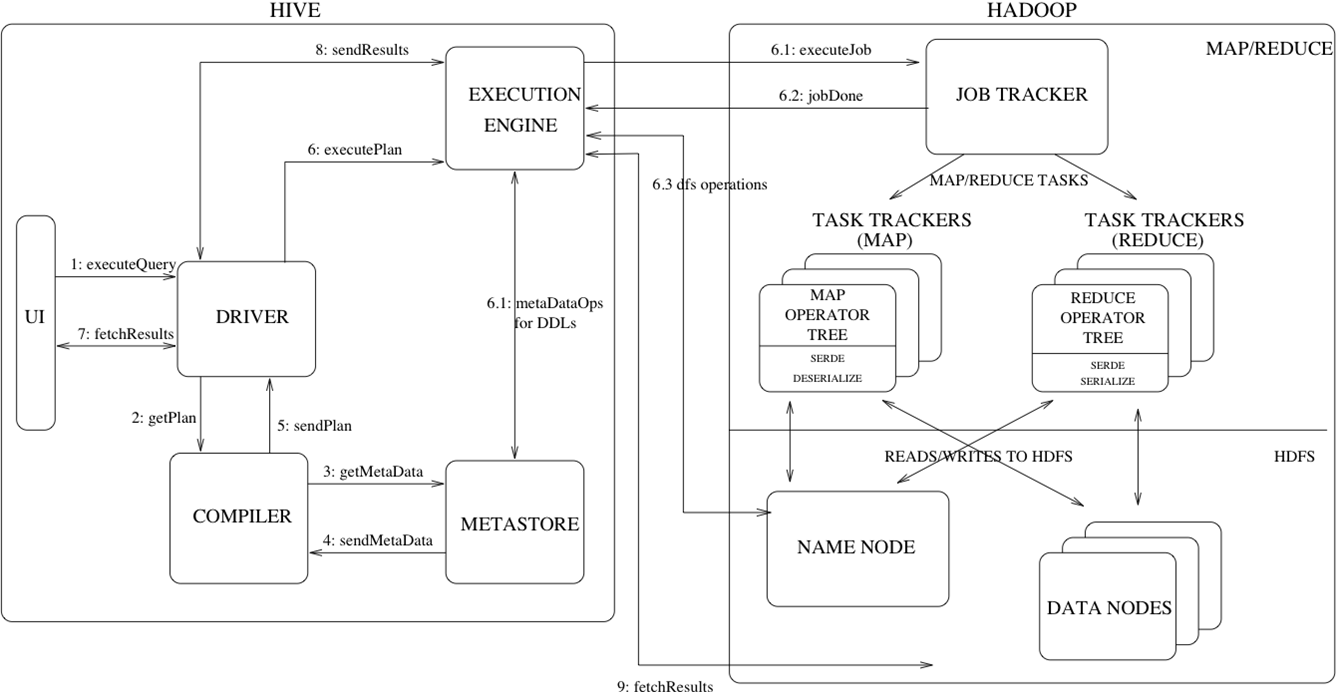
执行流程详细解析
Step 1:UI(user interface) 调用 executeQuery 接口,发送 HQL 查询语句给 Driver
Step 2:Driver 为查询语句创建会话句柄,并将查询语句发送给 Compiler, 等待其进行语句解析并生成执行计划
Step 3 and 4:Compiler 从 metastore 获取相关的元数据
Step 5:元数据用于对查询树中的表达式进行类型检查,以及基于查询谓词调整分区,生成计划
Step 6 (6.1,6.2,6.3):由 Compiler 生成的执行计划是阶段性的 DAG,每个阶段都可能会涉及到 Map/Reduce job、元数据的操作、HDFS 文件的操作,Execution Engine 将各个阶段的 DAG 提交给对应的组件执行。
Step 7, 8 and 9:在每个任务(mapper / reducer)中,查询结果会以临时文件的方式存储在 HDFS 中。保存查询结果的临时文件由 Execution Engine 直接从 HDFS 读取,作为从 Driver Fetch API 的返回内容。
容错(依赖于 Hadoop 的容错能力)
- Hive 的执行计划在 MapReduce 框架上以作业的方式执行,每个作业的中间结果文件写到本地磁盘,从而达到作业的容错性。
- 最终输出文件写到 HDFS 文件系统,利用 HDFS 的多副本机制来保证数据的容错性。
Hive缺陷
- MapReduce:
- Map任务结束后,要写磁盘
- 一个MapReduce任务结束后,需要将中间结果持久化到HDFS
- DAG生成MapReduce任务时,会产生无谓的Map任务
- Hadoop在启动MapReduce任务要消耗5-10秒,需要多次启动MapReduce任务
SparkSQL
SparkSQL在架构上和Hive类似,只是底层把MapReduce替换为Spark
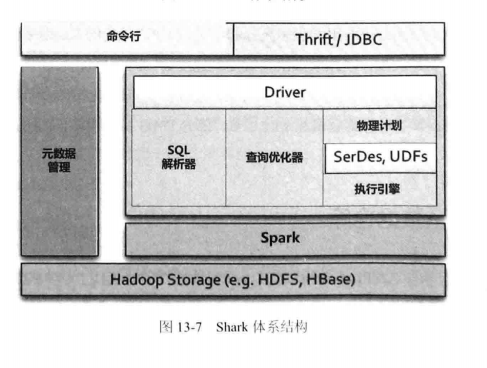
除了替换底层执行引擎,SparkSQL还做了3个方面的优化
- 可以基于内存的列簇存储方案
- 对SQL语句提供基于代价优化
- 数据共同分片
基于代价优化
SparkSQL会根据数据的分布,统计分片大小,热点数据等等的数据直方图。根据数据直方图可以完成:
- 根据表的大小动态改变操作符类型(join类型,aggeragate类型)
- 根据表的大小决定并发数(DAG节点分裂个数)
数据共同分片
通过创建表的时候,指定数据的分布方式,类似于GreenPlum指定distribute。这样join的时候不用网络交换。










