
github新增仓库 "dubbo-read"(点此查看),集合所有《Dubbo原理和源码解析》系列文章,后续将继续补充该系列,同时将针对Dubbo所做的功能扩展也进行分享。不定期更新,欢迎Follow。
一、Dubbo 配置方式
Dubbo 支持多种配置方式:
- XML 配置:基于 Spring 的 Schema 和 XML 扩展机制实现
- 属性配置:加载 classpath 根目录下的 dubbo.properties
- API 配置:通过硬编码方式配置(不推荐使用)
- 注解配置:通过注解方式配置(Dubbo-2.5.7及以上版本支持,不推荐使用)
对于 属性配置 方式,可以通过环境变量、-D 启动参数来指定 dubbo.properties 文件,加载文件顺序为:
- -D 启动参数
- 环境变量
- classpath 根目录
加载代码如下:
public static final String DUBBO_PROPERTIES_KEY = "dubbo.properties.file";
public static final String DEFAULT_DUBBO_PROPERTIES = "dubbo.properties";
private static volatile Properties PROPERTIES;
public static Properties getProperties() {
if (PROPERTIES == null) {
synchronized (ConfigUtils.class) {
if (PROPERTIES == null) {
String path = System.getProperty(Constants.DUBBO_PROPERTIES_KEY);
if (path == null || path.length() == 0) {
path = System.getenv(Constants.DUBBO_PROPERTIES_KEY);
if (path == null || path.length() == 0) {
path = Constants.DEFAULT_DUBBO_PROPERTIES;
}
}
PROPERTIES = ConfigUtils.loadProperties(path, false, true);
}
}
}
return PROPERTIES;
}
本文主要分析 XML 配置的实现原理和源码,其他方式不予赘述。
二、XML 配置
文章开头已经提到,XML 配置方式是基于 Spring 的 Schema 和 XML 扩展机制实现的。通过该机制,我们可以编写自己的 Schema,并根据自定义的 Schema 自定义标签来配置 Bean。
使用 Spring 的 XML 扩展机制有以下几个步骤:
- 定义 Schema(编写 .xsd 文件)
- 定义 JavaBean
- 编写 NamespaceHandler 和 BeanDefinitionParser 完成 Schema 解析
- 编写 spring.handlers 和 spring.schemas 文件串联解析部件
- 在 XML 文件中应用配置
Dubbo 配置相关的代码在 dubbo-config 模块。
2.1 定义 Schema
Schema 的定义体现在 .xsd 文件上,文件位于 dubbo-config-spring 子模块下:

至于 XSD 的数据类型、如何定义,并不是本文的重点,请参考 W3school《Schema 教程》。
2.2 定义 JavaBean
dubbo-config-api 子模块中定义了 Dubbo 所有标签对应的 JavaBean,JavaBean 里面的属性一一对应标签的各配置项。
2.3 解析 Schema
Dubbo 服务框架的 Schema 的解析通过 DubboNamespaceHandler 和 DubboBeanDefinitionParser 实现。
其中,DubboNamespaceHandler 扩展了 Spring 的 NamespaceHandlerSupport,通过重写它的 init() 方法给各个标签注册对应的解析器:
public class DubboNamespaceHandler extends NamespaceHandlerSupport {
static {
Version.checkDuplicate(DubboNamespaceHandler.class);
}
public void init() {
registerBeanDefinitionParser("application", new DubboBeanDefinitionParser(ApplicationConfig.class, true));
registerBeanDefinitionParser("module", new DubboBeanDefinitionParser(ModuleConfig.class, true));
registerBeanDefinitionParser("registry", new DubboBeanDefinitionParser(RegistryConfig.class, true));
registerBeanDefinitionParser("monitor", new DubboBeanDefinitionParser(MonitorConfig.class, true));
registerBeanDefinitionParser("provider", new DubboBeanDefinitionParser(ProviderConfig.class, true));
registerBeanDefinitionParser("consumer", new DubboBeanDefinitionParser(ConsumerConfig.class, true));
registerBeanDefinitionParser("protocol", new DubboBeanDefinitionParser(ProtocolConfig.class, true));
registerBeanDefinitionParser("service", new DubboBeanDefinitionParser(ServiceBean.class, true));
registerBeanDefinitionParser("reference", new DubboBeanDefinitionParser(ReferenceBean.class, false));
registerBeanDefinitionParser("annotation", new DubboBeanDefinitionParser(AnnotationBean.class, true));
}
}
而 DubboBeanDefinitionParser 实现了 Spring 的 BeanDefinitionParser,通过重写 parse() 方法实现将标签解析为对应的 JavaBean:
public class DubboBeanDefinitionParser implements BeanDefinitionParser {
public BeanDefinition parse(Element element, ParserContext parserContext) {
return parse(element, parserContext, beanClass, required);
}
@SuppressWarnings("unchecked")
private static BeanDefinition parse(Element element,ParserContext parserContext,Class<?> beanClass,boolean required) {
RootBeanDefinition beanDefinition = new RootBeanDefinition();
beanDefinition.setBeanClass(beanClass);
beanDefinition.setLazyInit(false);
//......省略
if (ProtocolConfig.class.equals(beanClass)) {
for (String name : parserContext.getRegistry().getBeanDefinitionNames()) {
BeanDefinition definition = parserContext.getRegistry().getBeanDefinition(name);
PropertyValue property = definition.getPropertyValues().getPropertyValue("protocol");
if (property != null) {
Object value = property.getValue();
if (value instanceof ProtocolConfig && id.equals(((ProtocolConfig) value).getName())) {
definition.getPropertyValues().addPropertyValue("protocol", new RuntimeBeanReference(id));
}
}
}
} else if (ServiceBean.class.equals(beanClass)) {
String className = element.getAttribute("class");
if(className != null && className.length() > 0) {
RootBeanDefinition classDefinition = new RootBeanDefinition();
classDefinition.setBeanClass(ReflectUtils.forName(className));
classDefinition.setLazyInit(false);
parseProperties(element.getChildNodes(), classDefinition);
beanDefinition.getPropertyValues().addPropertyValue("ref", new BeanDefinitionHolder(classDefinition, id + "Impl"));
}
} else if (ProviderConfig.class.equals(beanClass)) {
parseNested(element, parserContext, ServiceBean.class, true, "service", "provider", id, beanDefinition);
} else if (ConsumerConfig.class.equals(beanClass)) {
parseNested(element, parserContext, ReferenceBean.class, false, "reference", "consumer", id, beanDefinition);
}
//......省略
return beanDefinition;
}
}
2.4 串联部件
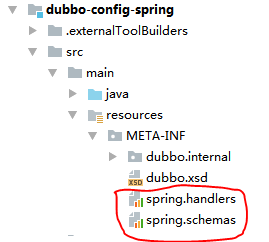
上面我们已经知道解析的实现类了,那么 Spring 又如何知道该用 DubboNamespaceHandler 来解析 Dubbo 标签呢?这通过编写 spring.handlers 文件实现。
spring.handlers 内容如下:
http\://code.alibabatech.com/schema/dubbo=com.alibaba.dubbo.config.spring.schema.DubboNamespaceHandler
然后,Spring 通过 spring.schemas 文件得知 Dubbo 标签的 Schema 是 dubbo.xsd,并以此校验应用 XML 配置文件的格式。
spring.schemas 文件内容如下:
http\://code.alibabatech.com/schema/dubbo/dubbo.xsd=META-INF/dubbo.xsd
文件位置如下:
2.5 应用配置
通过以上步骤,Dubbo 服务框架就完成了标签解析的功能,用户在应用程序中按照 dubbo.xsd 的格式配置 XML 即可。
Over.











