正文字数:8279 阅读时长:12分钟
2020年欧洲计算机视觉会议(ECCV)于8月23日至28日在网上举行,由1360篇论文组成,包括104场orals,160场spotlights以及1096篇posters,共进行有45场workshops和16场tutorials。与近年来的ML和CV会议一样,有时大量的论文可能不胜枚举。
作者 / Yassine
原文链接 / https://yassouali.github.io/ml-blog/eccv2020/
 往期阅读:ECCV 2020 亮点摘要(上)
往期阅读:ECCV 2020 亮点摘要(上)
半监督学习,无监督学习,迁移学习,表征学习以及小样本学习
Big Transfer (BiT): General Visual Representation Learning (paper)
(https://arxiv.org/abs/1912.11370)
在本文中,作者重新审视了迁移学习的简单范式:首先在一个大规模标记数据集(例如JFT-300M和ImageNet-21k数据集)上进行预训练,然后对目标任务上的每个训练权重进行精调任务,减少目标任务所需的数据量和优化时间。作者们拟议的迁移学习框架是BiT(大转移),由许多组件组成,包含了大量构建有效模型的必需组件,使其能够借助于大规模数据集学习到通用的、可迁移的特征表达。
在(上游)预训练方面,BiT包括以下内容:
对于非常大的数据集,由于Batch Normalization(BN)在测试结果期间使用训练数据中的统计信息会导致训练/测试差异,在这种情况下,训练损失可以正确优化和回传,但是验证损失非常不稳定。除了BN对批次大小的敏感性外。为了解决这个问题,BiT既使用了Group Norm,又使用了Weight Norm,而不是Batch Norm。
诸如ResNet 50之类的小型模型无法从大规模数据集中受益,因此模型的大小也需要相应地扩大规模,和数据集匹配。
对于(下游)目标任务,BiT建议以下内容:
使用标准SGD优化器,无需层冻结,dropout,L2正规化或任何适应梯度。别忘了把最后的预测层的权重初始化为0。
不用将所有输入缩放为固定大小,例如224。在训练过程中,输入图像会随机调整大小并裁剪为具有随机选择大小的正方形,并随机水平翻转。在测试阶段,图像会被缩放为固定大小,
尽管对于数据量充足的大规模数据集预训练来说,mixup 并没有多大用处,但BiT发现misup正则化对于用于下游任务的中型数据集训练非常有用。
Learning Visual Representations with Caption Annotations
(https://arxiv.org/abs/2008.01392)
在大规模标注的数据集上训练深度模型不仅可以使手头的任务表现良好,还可以使模型学习对于下游任务的有用特征形式。但是,我们是否可以在不使用如此昂贵且细粒度的标注数据的情况下获得类似的特征表达能力呢?本文研究了使用噪声标注(在这种情况下为图像标题)的弱监督预训练。
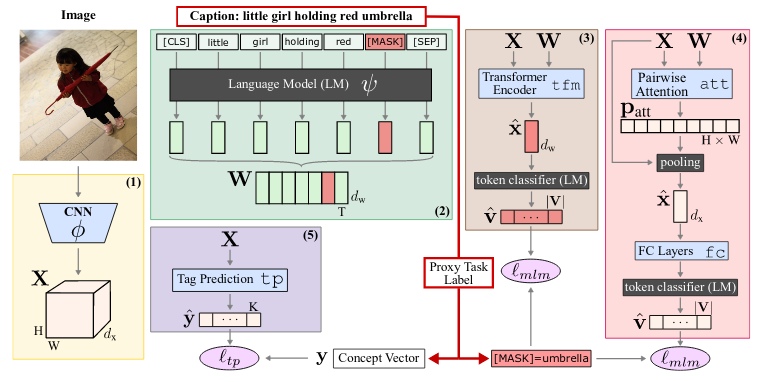
目标是用有限对图像与说明文字来学习视觉表达,那么,如何制定训练目标以推动图像及其标题之间的有效交互?基于BER模型随机掩盖15% 的输入字符,让模型根据 transformer 模型的编码器输出重建整个句子,该方法也随机对图像的文字说明进行掩码操作。论文提出了图像条件化的掩蔽语言建模(ICMLM),其中利用图像信息来重构其相应说明文字的掩码的字符。为了解决这个问题,作者提出了两种多模架构:(1)ICMLM tfm,使用一个卷积神经网络对原始图像进行编码得到图像特征,接着,经过BERT处理的被掩码的图像说明、原始图像说明以及图像特征被级联起来并通过一个 transformer 编码器,最终输出一个多模嵌入特征用于预估被掩码的字符。(2)首先生成ICMLM att + fc,说明和图像之间的相似度,接着经过一个成对注意力模块来整合图像与文字说明之间的信息。得到的特征会经过池化后再过一个全连接层来预测被掩码的字符。
Memory-augmented Dense Predictive Coding for Video Representation Learning
(https://arxiv.org/abs/2008.01065)
近期在自监督图像表征学习领域的进步在下游任务中展现出了令人印象深刻的效果。尽管视频的多模表征学习多有发展,然而不使用其他任何类似于文本与语音的模态信息,但使用视频流进行自监督学习还未有所发展。即使视频的时域信息为自监督地训练一个根据过去帧预测未来帧的模型提供了充足的监督信号。由于确切的未来并不存在,并且在给定的时间步长内,对于未来状态有许多可能和合理的假设(例如,当动作是“打高尔夫球”时,那么下一帧可能是手或者高尔夫俱乐部)。
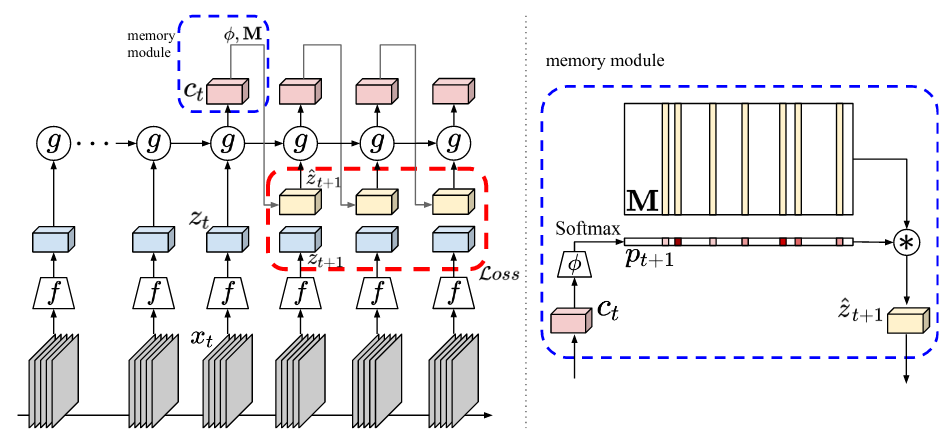
本文将对比学习与存储模块结合使用,以解决未来帧的预测问题。为了减少不确定性,该模型会在特征级别上预测未来,并使用对比损失进行训练以避免过度约束。为了处理多种假设,一个存储模块用于同时推断多个未来状态。给定一组连续帧,2d-3d CNN编码器(即ff)产生上下文特征,而GRU(即g)整合所有过去的信息,然后将其用于从共享存储模块中选择插槽。然后,将预测的未来状态作为所选存储插槽的凸组合生成。然后,使用对比损失将预测的未来状态与未来状态的真实特征向量进行比较。对于下游任务,将g产生的特征汇总起来,然后提供给分类器处理。
SCAN: Learning to Classify Images without Labels
(https://arxiv.org/abs/2005.12320 )
要将未标记的输入图像分组为语义上有意义的聚类,我们需要仅使用视觉相似性来找到解决方案。先前的工作之一是(1)使用自我监督的方法学习丰富的特征,然后对特征应用k均值以找到聚类,但这很容易导致性能退化。(2)端到端群集方法,这些方法可以利用CNN的功能进行深度聚类,也可以基于互信息最大化。但是,生成的聚类结果在很大程度上取决于初始化,并且很可能会陷入低级特征主导中。
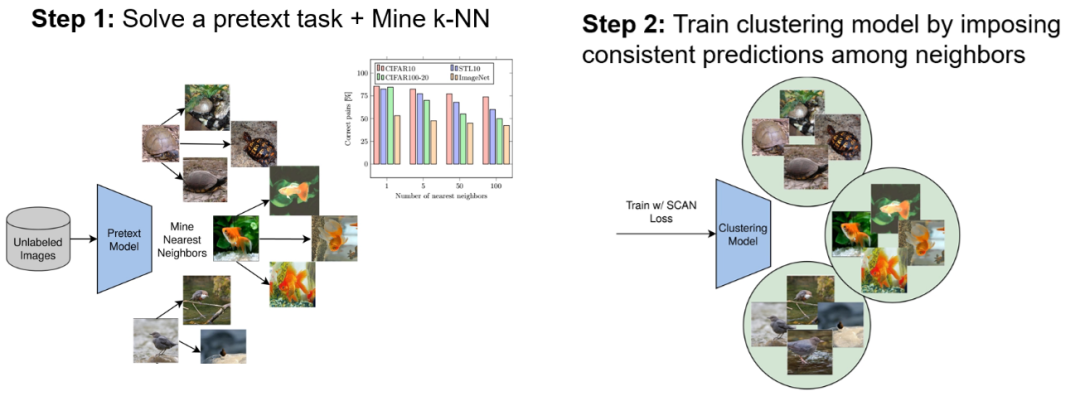
为了解决先前工作中发现的问题,本文提出了采用两步过程的SCAN(采用最邻方法的语义聚类)。第一步,通过前置任务学习特征表示,然后生成将语义上有意义的最近邻用作先验,以训练模型将每个图像及其对应的邻居分为一类。模型通过损失函数来优化,该函数会在 softmax 之后最大化输出向量的点积,从而迫使网络产生一致且有判别度的(one-hot 向量)预测。
GATCluster: Self-Supervised Gaussian-Attention Network for Image Clustering
(https://arxiv.org/abs/2002.11863)
聚类包括根据样本相似性将数据分为多个聚类。传统的方法是使用手工特征和特定于领域的距离函数来衡量相似度,但是这种手工制作的特征在表达能力上非常有限。随后的工作将深度表示和聚类算法结合起来,但是当输入数据很复杂时,深度聚类的性能还是会受到影响。有效的聚类在特征层面必须同时包含高层判别性特征并获取对象语义信息。在聚类步骤上,必须避免使用将样本分配到单个或少数几个集群的算法,并且聚类需要高效地应用于大尺寸图像。
本文提出了GATCluster,它直接输出语义聚类标签而无需进一步的后处理,其中学习到的特征是一个 one-hot 编码向量,以避免弱解。GATCluster在平移不变性、可分离性最大化、熵分析和注意力映射约束下,通过四个自学习任务以无监督的方式进行了训练。
Associative Alignment for Few-shot Image Classification
(https://arxiv.org/abs/1912.05094)
小样本图像分类的目标是在训练样本很少的情况下,生成一个能够学习识别新的图像类的模型。现在流行的方法之一是元学习,它从大量包含基类的标记数据中提取公共知识,并用于训练模型。然后训练该模型以仅用几个样本就可以对来自新颖概念的图像进行分类。元目标是找到一组良好的初始权重集合,这些初始权重在接受新概念训练时会迅速收敛。有趣的是,最近的研究表明,不使用元学习的标准转移学习,其中特征提取器首先在基类上进行了预训练,然后根据新的几个类别上在预训练的提取器之上对分类器进行了微调。,其性能和更复杂的元学习策略不相上下。但是为了避免过拟合,特征提取器对部分层的权重冻结会阻碍性能。
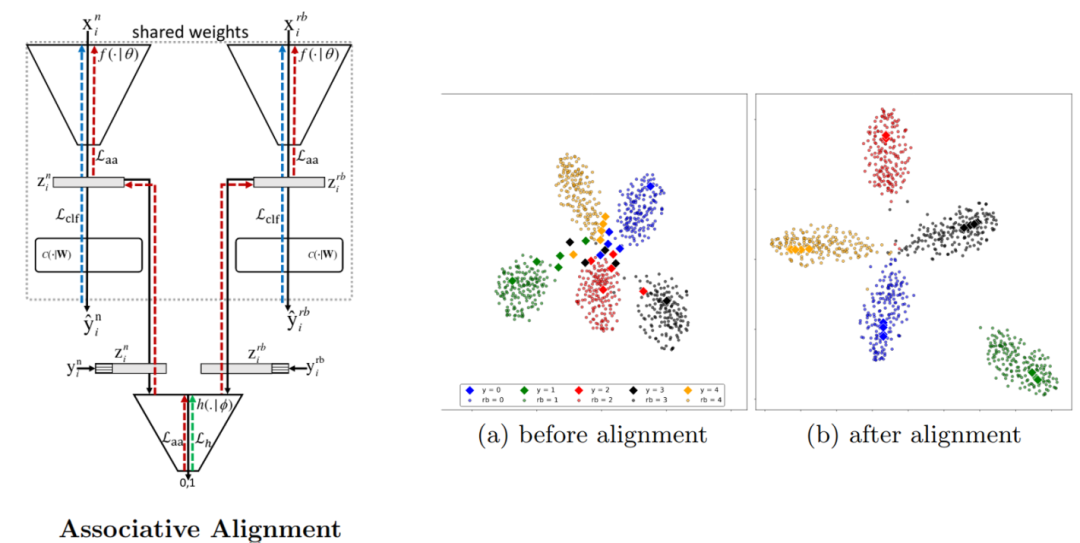
本文提出了一种两步法来解决这个问题。首先,特征提取器用于为新样本生成特征。然后,使用嵌入空间中的相似性度量将每个样本的特征映射到基类之一。第二步包括关联对齐,其中对特征提取器进行微调,以便将新图像的嵌入向量更靠近其相应基础图像的嵌入。这可以通过以下方法完成:在每个基类的中心与新类比之间的距离减小的质心对齐方式,也可以使用对抗性对齐,其中鉴别器迫使特征提取器在嵌入空间中对齐基础图像和新样本。
三维计算机视觉以及机器人学
NeRF: Representing Scenes as Neural Radiance Fields for View Synthesis
(https://arxiv.org/abs/2003.08934)
从2D图像合成3D视图是一个具有挑战性的问题,尤其是在稀疏地采样了输入2D图像的情况下。改目标的任务是是训练一个模型,该模型拍摄3D场景的2D图像集合(具有可选的相机姿势及其内参),然后,使用训练后的模型,我们可以渲染3D场景中未找到的新2D视图。种成功的方法是基于体素的表示法,该表示方法使用离散的网格表示3D场景。使用3D CNN可以预测3D体素中对应的RGB-alpha网格值。是,由于这种基于体素的方法复杂度与空间分辨率成三次比,难以优化并且无法平滑地对场景表面进行参数化,因此它们的存储效率不高。计算机视觉社区的最新趋势是使用全连接的神经网络将给定的3D场景表示为连续函数。因此,神经网络本身就是3D场景的压缩表示,使用2D图像集进行训练,然后用于渲染新的视图。但是,现有方法仍无法匹配现有基于voxed的方法。
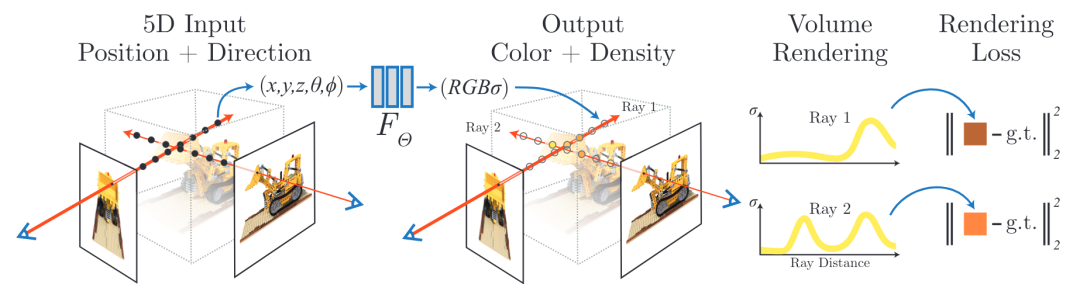
NeRF(神经辐射场)使用9个层和256个通道的全连接网络将场景表示为连续5D函数,其输入是单个连续5D函数,即3D空间位置(xx,yy,zz)和视角方向(θθ,ϕϕ),其输出为RGB颜色和不透明度(输出密度)。为了合成给定的视图,渲染过程包括沿摄像机光心所在的直线查询5D坐标,并使用经典的体素渲染技术将输出的颜色和密度投影到图像中。由于体素渲染是可以区分的,因此优化表示所需的唯一输入就是具有已知摄影机姿势参数的一组图像。这样,NeRF能够有效地优化神经辐射场,以渲染具有复杂几何形状和外观的场景的逼真视图,并且在渲染的图像和真实图像之间具有简单的重建损失,并证明其结果优于先前的神经渲染和视图工作合成研究。
Towards Streaming Perception
(https://arxiv.org/abs/2005.10420)
诸如自动驾驶汽车之类的实际应用需要类似于人类的快速反应时间,通常为200毫秒。在这种情况下,需要使用低延迟算法来确保安全运行。但是,即使经常研究计算机视觉算法的延迟,也仅主要在离线环境中进行了研究。在线视觉感知会带来完全不同的延迟需求。因为到了算法完成处理特定图像帧的时间(例如200毫秒后),周围的世界就发生了变化,如下图所示。这迫使感知最终预测了未来,这是人类视觉的基本属性(例如,当棒球运动员击中快球时,这是必需的)。
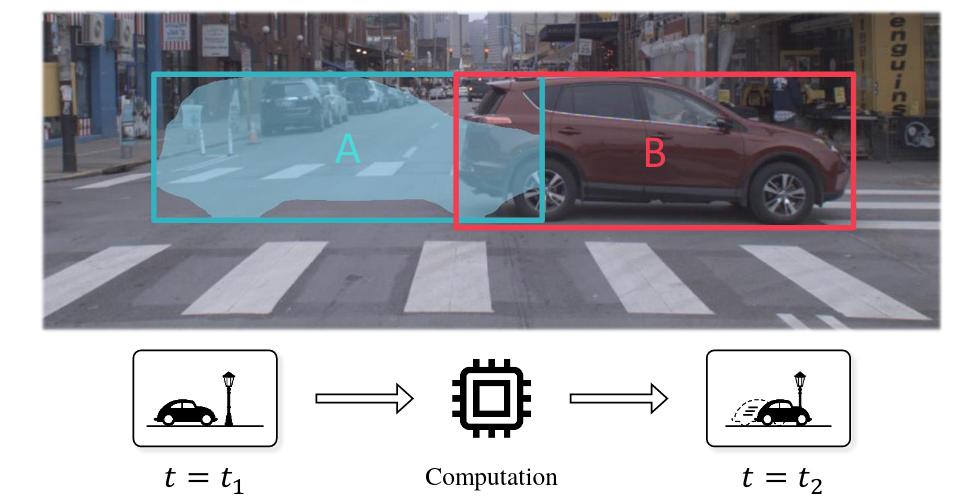
为了开发更好的基准以反映现实情况,并使现有方法的比较更加容易。本文介绍了流感知的目标,即实时在线感知,并提出了一种新的元基准,该基准将系统地将任何图像理解任务系统地转换为流图像理解任务。该基准基于基于以下 的几点提出了:流感知需要在任何时刻都了解世界的状态。因此,当新帧到达时,流算法必须报告世界的状态,即使它们尚未处理前一帧,也迫使它们考虑在进行计算时应忽略的流数据量。具体来说,当比较模型的输出和真实标签时,对齐是使用时间而不是输入索引来完成的,因此在处理相应的输入之前,模型需要对时间步t给出正确的预测,即验证模型需要Δt来处理输入并处理,它只能使用t-Δt之前的数据来预测在时间t对应于输入的输出。
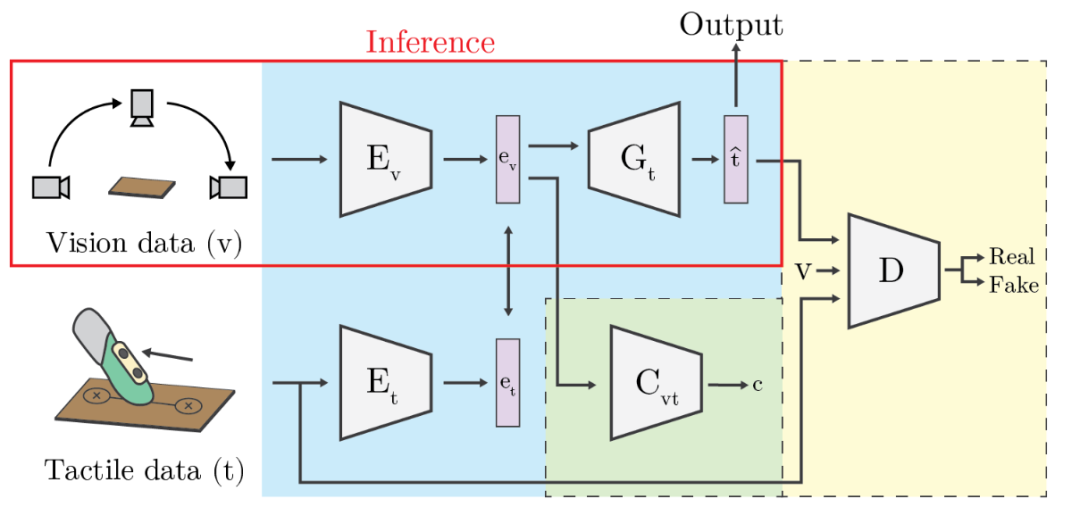
Teaching Cameras to Feel: Estimating Tactile Physical Properties of Surfaces From Images
(https://arxiv.org/abs/2004.14487)
人类能够在小时候就开始形成一种心理模型,该模型以对物体的感知和对应的触觉来映射,这是基于与不同物品互动时的先前经验。当与新对象进行交互时,尤其是当简单的对象类别无法提供足够的信息以准确估计触觉物理特性时,让具有这种心理模型的自主智能体成为非常有价值的工具。
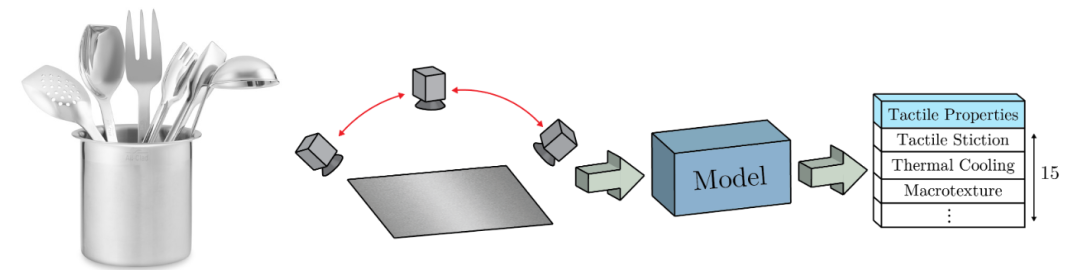
为了更直接地模拟这种心理模型,本文提出直接估计物理特性,从而允许直接利用对象的属性。首先,作者提出了包含400多个表面图像序列和触觉特性测量值的数据集。因为当估计表面特性时,人们经常不自觉地移动他们的头部,获取表面的多个视图,所以所捕获的图像序列包括每个材料表面的多个视角。然后,他们提出了一种跨模式框架,用于学习视觉提示到触觉特性的复杂映射。该模型的训练目标是在给定视觉信息的情况下生成精确的触觉特性估计。视觉和触觉信息都通过单独的编码器网络嵌入到共享的潜在空间中。然后,生成器函数根据嵌入的视觉矢量估算触觉属性值。鉴别器网络学习预测触觉-视觉对是真实的还是合成的例子。在推断期间,如果输入图像,则使用编码器-生成器对来推断触觉属性。
Convolutional Occupancy Networks
(https://arxiv.org/abs/2003.04618)
三维重建是计算机视觉中的一个重要问题,有着广泛的应用。对于三维几何图形的理想表示,我们需要能够达到以下几点:a)编码复杂的几何图形和任意拓扑结构,b)缩放到大型场景,c)封装局部和全局信息,以及d)在内存和计算方面易于处理。然而,现有的三维重建表示方法并不能满足所有这些要求。虽然最近的隐式神经表示在三维重建中表现出了令人印象深刻的性能,但是由于使用了一种简单的全连接的网络结构,这种结构不允许在观测值中集成局部信息,也不允许包含诸如平移等变的归纳偏差,因此它们有着一些局限性。
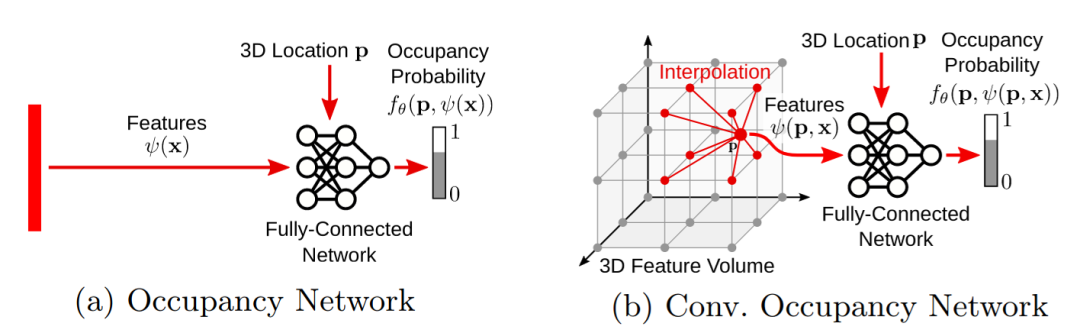
Convolutional Occupancy Networks卷积占用网络使用卷积编码器和隐式占用解码器结合来归纳偏差,并实现三维空间的结构化推理。从而得到单个对象进行隐式三维重建,具有扩展到大型室内场景的能力,并能很好地从合成数据推广到真实数据。
图像和视频合成
Transforming and Projecting Images into Class-conditional Generative Networks
(https://arxiv.org/abs/2005.01703)
GaNs能够从不同的类别中生成不同的图像。例如,BigGaN,一个类体哦阿健生成对抗网络GaN,给定一个噪声向量z和一个类嵌入向量c,该模型能够生成对应类的新的图像。然后,就可以通过编辑噪声向量的隐变量和类别嵌入向量来操纵图像。但反过来可能吗?例如,给定一幅输入图像,我们能找到与该图像最匹配的潜变量z和嵌入类向量c吗?这个问题仍然具有挑战性,因为许多输入图像不能由GaN生成。另外,由于目标函数具有多个局部极小值,搜索算法容易陷入此类局部极小值区域。
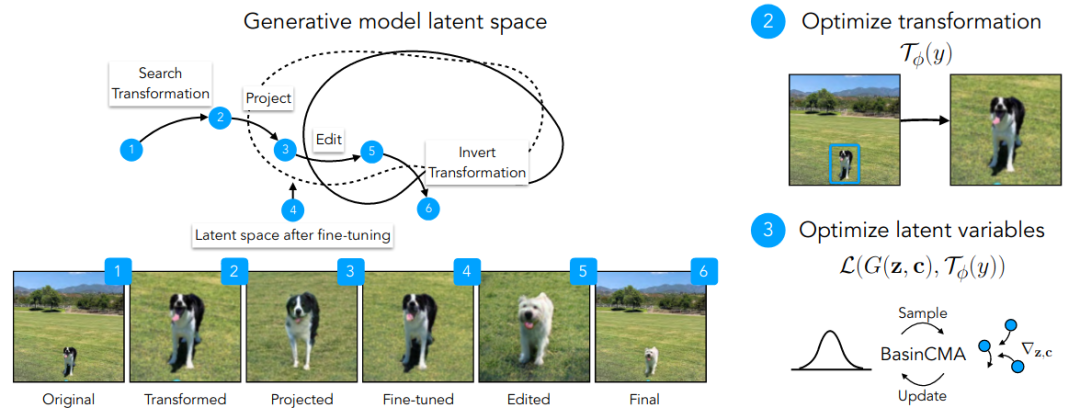
为了解决这些问题,本文提出了两种新的思路:估计输入图像的尺度变换,以及使用非局部搜索算法来寻找更好的解。如上所示,给定输入图像,pix2potent首先找到最佳仿射变换,使得变换后的输入可能由GaN生成,然后使用所提出的basicma优化方法将图像投影到隐空间中。然后对获得的隐变量进行编辑,将其投影回图像空间,获得编辑后的图像,然后可以使用初始仿射变换的逆运算对其进行变换并得到图像。
Contrastive Learning for Unpaired Image-to-Image Translation
(https://arxiv.org/abs/2007.15651)
给定两组不同属性和模式的图像对训练集,例如马和斑马的图像组合,非配对图像到图像的转换的目的是学习两种模图像式之间的变化函数,例如将马转换为斑马,反之亦然,同时保留诸如姿势或大小等敏感信息,而不必确保两种模式之间的一对一匹配集。现有的方法,如CycleGaN迫使模型能够将转换后的图像变换回原始图像。但是这样的方法假设一个双射变换,这通有太多限制,因为一个给定的变换后的图像可能有许多似是而非的源图像。一个理想的损失应该是在不同的样式下仍然保持不变的,不同的风格,但区分敏感信息。
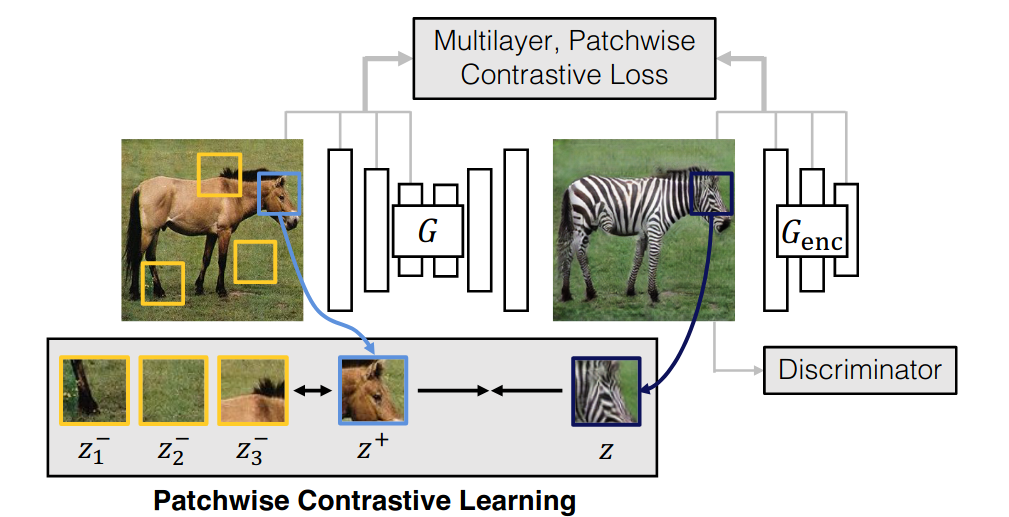
Contrastive Unpaired Translation(CUT)旨在学习这样一个嵌入空间。除了标准的GAN损失外,生成器被训练生成够真实的翻译图像,而鉴别器试图区分转换图像和真实图像。还要增加一个额外的损失,用来迫使网络对输入图像与转换图像的对应图像块生成相似的嵌入向量。该损失在优化时采用对比损失,即拉近两个对应图像块的嵌入向量的距离,同时拉远给定图像块和随机抽样图像块嵌入之间的距离(只使用同一输入图像的内部区块,其他图像的区块会降低性能)。
Rewriting a Deep Generative Model
(https://arxiv.org/abs/2007.15646)
GAN 能够对数据分布中丰富的语义和物理规则进行建模,但是到目前为止,这些规则是如何在网络中编码的,或者一个规则是如何被改变的我们还不是十分清楚。本文介绍了一种新的问题:操作由深度生成网络模型编码的特定规则。因此,给定一个生成模型,目标是调整其权重,使新的和修改后的模型遵循新的规则,并生成遵循新规则集的图像,如下所示。

通过将网络的每一层视为一个关联存储器,将潜在生成规则储存为隐藏特征上的一组键值关系。可以通过定义约束优化来编辑和修改模型,约束优化在关联性储存器中添加或编辑一个特定规则,同时尽可能保留模型中现有的语义关系。论文直接通过度量和操纵模型的内部结构来实现这一点,而不需要任何新的训练数据。
Learning Stereo from Single Images
(https://arxiv.org/abs/2008.01484)
给定一对对应的图像,视差匹配的目标是估计从第一视图到第二视图的每个像素的对应位置之间的每像素水平位移(即视差),反之亦然。虽然全监督的方法可以给出很好的结果,但一对视察图像之间精确的真实视差往往很难获得。一种可能的替代方法是对合成数据进行训练,然后对有限数量的实际标记数据进行微调。但是,如果没有一个带有足够标签的微调步骤,这样的模型就不能很好地生成真实的图像。
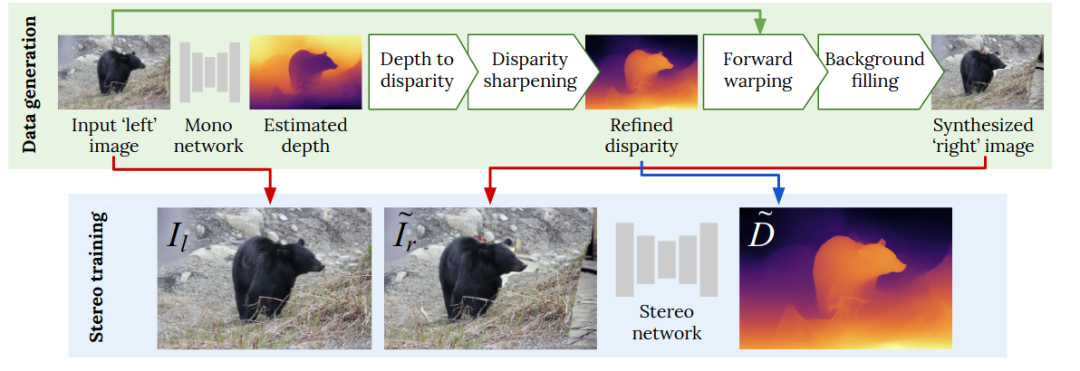
该文提出了一种新的、全自动的视差估计训练流程,通过使用图像深度估计网络,该方法可以由已知深度信息的非结构化单幅图像生成视差估计训练数据,这样就无需人工合成数据或真实视差图像对即可进行训练。。首先,通过使用深度视差的前向形变操作将给定的左输入图像转换为合成的右图像。然后,利用视差图像对,以有监督的方式对视差估计网络进行训练,得到一个泛化的模型。
What makes fake images detectable? Understanding properties that generalize
(https://arxiv.org/abs/2008.10588)
虽然GaN生成图像的质量已经达到了令人印象深刻的水平,但是经过训练的深度网络仍然可以检测到生成图像中的细微伪影,并且这种训练的网络还可以在不同数据集和不同方法上训练的多个模型中发现相同的伪影。本文旨在可视化和理解哪些工件在模型之间是共享的,并且容易在不同的场景中检测和转移。

由于全局面部结构在不同的生成器和数据集之间可能有所不同,因此生成的图像的局部面片更加确定,并且可能产生冗余的伪影。为此,本文采用了一种基于区块的全卷积分类器来关注局部区块而不是全局结构。然后可以使用路径级分类器来可视化和分类在各种测试数据集中最能指示真实或虚假图像的区块。另外,可以对生成的图像进行操作以夸大假图像的特征属性。
===
视觉和语言
Connecting Vision and Language with Localized Narratives
(https://arxiv.org/abs/1912.03098)
连接视觉和语言的一种流行方式是图像标题,其中每个图像都与人类编写的文本标题配对,但这种链接仅在完整的图像尺度范围内,其中的文本描述了整个图像。为了改进这种若的关联,有人尝试着将图片标题的特定部分和图像中的目标框联系起来。但是,这种关联仍然非常稀疏,大多数对象和单词都没有对应的目标框,且注释过程可能会非常昂贵。

本文提出了一种新的有效的多模态图像标注形式,称之为定位叙事。定位叙述是通过要求注释者用他们的声音描述一个图像,同时将鼠标悬停在他们描述的区域上而生成的。例如,如上图所示,注释者一边说“woman”,一边用鼠标指示她的空间范围,从而为这个名词提供了视觉基础。后来,他们把鼠标从女人身上移到气球上,跟着气球的绳子,说“holding”。这为这种关系提供了直接的视觉基础。它们还描述了“晴朗的蓝天”和“浅蓝色牛仔裤”等属性。由于语音与鼠标指针同步,因此可以确定描述中每个单词的图像位置。这以鼠标轨迹段的形式为每个单词提供了密集视觉基础。这一丰富的注释方法具有多种形式(图像、文本、语音和位置),可用于文本到图像生成、视觉问答和语音驱动的环境导航等不同的任务。或者,为了更精细地控制任务,可以在图像的特定部分设置条件化字幕,视力不理想的人可以通过将手指悬停在图像上来获得特定部分的描述。
UNITER: UNiversal Image-TExt Representation Learning
(https://arxiv.org/abs/1909.11740)
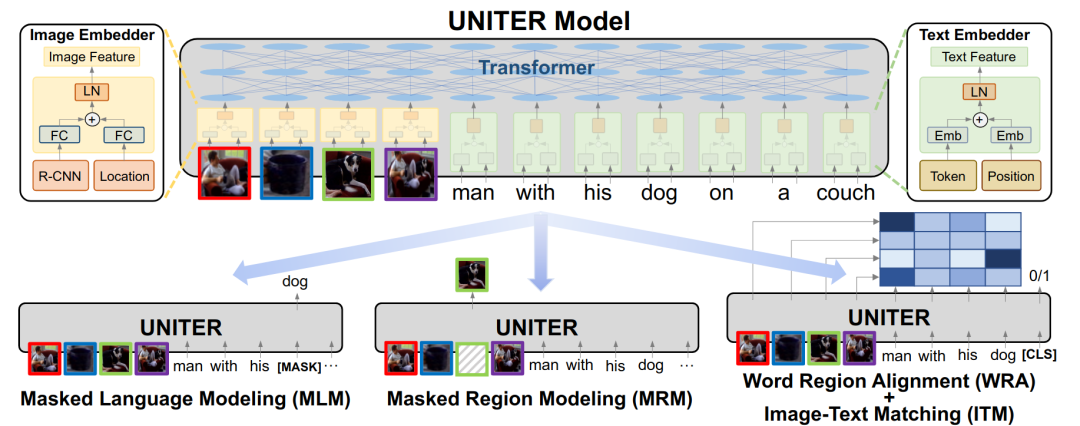
大多数视觉与语言任务(V&L)如视觉问答(VQA)依赖于多模态联合嵌入来弥补图像和文本中视觉和文本线索之间的语义鸿沟。但是这种表示通常是为特定的任务定制的,并且需要特定的体系结构。为了学习可用于所有V&L下游任务的通用联合嵌入。本文介绍了一种大规模联合多模态嵌入预训练模型 UNITER ,如下图所示。在transformer模型的基础上,对UNITER进行了4个任务的预训练:基于图像的蒙版语言建模(MLM),利用图像和文本特征恢复随机蒙版单词。以文本为条件的蒙版区域建模(MRM),即重构给定图像的某些区域;图像文本匹配(ITM),即预测图像和文本实例是否配对;以及单词区域对齐(WRA),即学习最佳变换找到单词和图像之间的最佳对齐。为了在下游任务中使用UNITER,首先将其重新表示为分类问题,然后使用交叉熵损失对添加在[CLS]特征上的分类器进行训练。
Learning to Learn Words from Visual Scenes
(https://arxiv.org/abs/1911.11237)
视觉和语言任务的标准方法是学习一个共同的嵌入空间,但是这种方法效率很低,通常需要数百万个例子来学习,对语言的自然构成结构的泛化很差,而且所学嵌入在推理时无法适应新词。因此,本文提出让网络尝试学习单词嵌入的过程,而不是学习单词嵌入。

该模型基于transformer模型,在每次迭代中,该模型接收一个图像语言对,然后元学习一个策略从该集中获取词表示。这就使得我们能够在推理时获得新单词的表示,并且能够更鲁棒地推广到新的描述任务中。具体来说,每一个任务都是一个语言习得任务或一个小插曲,由训练样本和测试样本组成,测试样本对从训练样本中获得的语言进行评价。例如,在上图中,模型需要从训练样本中获取单词“chair”,这是它以前从未见过的单词。元训练是在向前传递中完成的,并使得模型需要指向训练示例中正确的单词“chair”,并使用匹配损失来训练整个模型。经过多种事件和任务的训练,该模型能够很快适应推理过程中的新任务。
结语
让人感到遗憾的是,论文的数量使得总结任务变得困难和耗时。所以对于其余的论文,我将简单地列出一些我遇到的论文的标题,如果读者对这些主题感兴趣的话也方便自行查找研究(参考原文)。
LiveVideoStackCon 2021 ShangHai
这个世界没有准备好这一说
机会和技术不会主动敲开你的门

LiveVideoStackCon 2021 上海站
北京时间:2021年4月16日-4月17日
点击 【阅读原文】 了解大会详情
本文分享自微信公众号 - LiveVideoStack(livevideostack)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。