
有幸在2019KubeCon上海站听到Steve Flanders关于OpenTelemetry的演讲,之前Ops领域两个网红项目OpenTracing和OpenCensus终于走到了一起,可观察性统一的标准化已经扬帆起航。
这篇文章旨在抛砖引玉,希望能够和更多的同学一起交流可观察性相关的内容。
前世
OpenTracing
OpenTracing制定了一套平台无关、厂商无关的Trace协议,使得开发人员能够方便的添加或更换分布式追踪系统的实现。在2016年11月的时候CNCF技术委员会投票接受OpenTracing作为Hosted项目,这是CNCF的第三个项目,第一个是Kubernetes,第二个是Prometheus,可见CNCF对OpenTracing背后可观察性的重视。比如大名鼎鼎的Zipkin、Jaeger都遵循OpenTracing协议。
OpenSensus
大家可能会想,既然有了OpenTracing,OpenSensus又来凑什么热闹?对不起,你要知道OpenSensus的发起者可是谷歌,也就是最早提出Tracing概念的公司,而OpenSensus也就是Google Dapper的社区版。OpenSensus和OpenTracing最大的不同在于除了Tracing外,它还把Metrics也包括进来,这样也可以在OpenSensus上做基础的指标监控;还一点不同是OpenSensus并不是单纯的规范制定,他还把包括数据采集的Agent、Collector一股脑都搞了。OpenSensus也有众多的追随者,最近最大的新闻就是微软也宣布加入,OpenSensus可谓是如虎添翼。
OpenTracing vs OpenSensus
两套Tracing框架,都有很多追随者,都想统一对方,咋办?首先来PK啊,这里偷个懒,直接上Steve的图:
可以看到,OpenTracing和OpenCensus从功能和特性上来看,各有优缺点,半斤八两。OpenTracing支持的语言更多、相对对其他系统的耦合性要更低;OpenCensus支持Metrics、从API到基础框架都实现了个便。既然从功能和特性上分不出高下,那就从知名度和用户数上来PK吧:
好吧,又是半斤八两,OpenTracing有很多厂商追随(比如ElasticSearch、Uber、DataDog、还有国产的SkyWalking),OpenCensus背后Google和微软两个大佬就够撑起半边天了。
最终一场PK下来,没有胜负,怎么办?
OpenTelemetry
横空出世
所谓天下合久必分、分久必合,既然没办法分个高低,谁都有优劣势,咱们就别干了,统一吧。于是OpenTelemetry横空出世。
那么问题来了:统一可以,起一个新的项目从头搞吗?那之前追随我的弟兄们怎么办?不能丢了我的兄弟们啊。
放心,这种事情肯定不会发生的。要知道OpenTelemetry的发起者都是OpenTracing和OpenSensus的人,所以项目的第一宗旨就是:兼容OpenTracing和OpenSensus。对于使用OpenTracing或OpenSensus的应用不需要重新改动就可以接入OpenTelemetry。
核心工作
OpenTelemetry可谓是一出生就带着无比炫目的光环:OpenTracing支持、OpenSensus支持、直接进入CNCF sanbox项目。但OpenTelemetry也不是为了解决可观察性上的所有问题,他的核心工作主要集中在3个部分:
- 规范的制定,包括概念、协议、API,除了自身的协议外,还需要把这些规范和W3C、GRPC这些协议达成一致;
- 相关SDK、Tool的实现和集成,包括各类语言的SDK、代码自动注入、其他三方库(Log4j、LogBack等)的集成;
- 采集系统的实现,目前还是采用OpenSensus的采集架构,包括Agent和Collector。
可以看到OpenTelemetry只是做了数据规范、SDK、采集的事情,对于Backend、Visual、Alert等并不涉及,官方目前推荐的是用Prometheus去做Metrics的Backend、用Jaeger去做Tracing的Backend。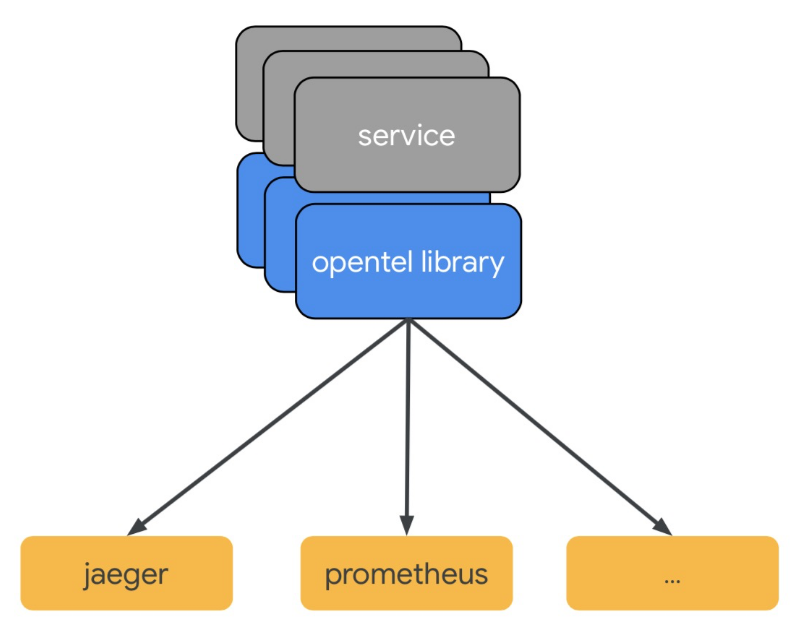
看了上面的图大家可能会有疑问:Metrics、Tracing都有了,那Logging为什么也不加到里面呢?
其实Logging之所以没有进去,主要有两个原因:
- 工作组目前主要的工作是在把OpenTracing和OpenSensus的概念尽早统一并开发相应的SDK,Logging是P2的优先级。
- 他们还没有想好Logging该怎么集成到规范中,因为这里还需要和CNCF里面的Fluentd一起去做,大家都还没有想好。
终极目标
OpenTelemetry的终态就是实现Metrics、Tracing、Logging的融合,作为CNCF可观察性的终极解决方案。
Tracing:提供了一个请求从接收到处理完毕整个生命周期的跟踪路径,通常请求都是在分布式的系统中处理,所以也叫做分布式链路追踪。
Metrics:提供量化的系统内/外部各个维度的指标,一般包括Counter、Gauge、Histogram等。
Logging:提供系统/进程最精细化的信息,例如某个关键变量、事件、访问记录等。
这三者在可观察性上缺一不可:基于Metrics的告警发现异常,通过Tracing定位问题(可疑)模块,根据模块具体的日志详情定位到错误根源,最后再基于这次问题调查经验调整Metrics(增加或者调整报警阈值等)以便下次可以更早发现/预防此类问题。
Metrics、Tracing、Logging融合的关键
实现Metrics、Tracing、Logging融合的关键是能够拿到这三者之间的关联关系.其中我们可以根据最基础的信息来聚焦,例如:时间、Hostname(IP)、APPName。这些最基础的信息只能定位到一个具体的时间和模块,但很难继续Digin,于是我们就把TraceID把打印到Log中,这样可以做到Tracing和Logging的关联。但这还是解决不了很多问题:
- 如何把Metrics和其他两者关联起来
- 如何提供更多维度的关联,例如请求的方法名、URL、用户类型、设备类型、地理位置等
- 关联关系如何一致,且能够在分布式系统下传播
在OpenTelemetry中试图使用Context为Metrics、Logging、Tracing提供统一的上下文,三者均可以访问到这些信息,由OpenTelemetry本身负责提供Context的存储和传播:
- Context数据在Task/Request的执行周期中都可以被访问到
- 提供统一的存储层,用于保存Context信息,并保证在各种语言和处理模型下都可以工作(例如单线程模型、线程池模型、CallBack模型、Go Routine模型等)
- 多种维度的关联基于Tag(或者叫meta)信息实现,Tag内容由业务确定,例如:通过TrafficType来区别是生产流量还是压测流量、通过DeviceType来分析各个设备类型的数据...
- 提供分布式的Context传播方式,例如通过W3C的traceparent/tracestate头、GRPC协议等
下面是Yuri Shkuro画的原型设计:
+----------------------------------------------------+
| |
+------------+ custom application logic or specialized frameworks |
| | |
| +-------------------------------------+--------------+
| |
| +---------+ +------+ +--------+ |
| | | | | | | |
| | metrics | | logs | | traces +---+ |
| | | | | | | | |
| +----+----+ +---+--+ +---+----+ | |
| ^ ^ ^ | |
| +-----+----------+--------+-----+ | |
| | | | |
+---> baggage | | |
| | | |
+---------------+---------------+ | |
| | |
+---------------------+------------------+-----------+-------------------+
Universal context propagation layer <-----> marshaling
plugins
当前状态以及后续路线
目前OpenTelemetry还处于策划和原型阶段,很多细节的点还在讨论当中,目前官方给的时间节奏是:
- 2019年9月,发布主要语言版本的SDK(Pre Release版)
- 2019年11月,OpenTracing和OpenSensus正式sunsetted(ReadOnly)
- 未来两年内,保证可以兼容OpenTracing和OpenSensus的SDK
总结
从Prometheus、OpenTracing、Fluentd到OpenTelemetry、Thanos这些项目的陆续进入就可以看出CNCF对于Cloud Native下可观察性的重视,而OpenTelemetry的出现标志着Metrics、Tracing、Logging有望全部统一。
但OpenTelemetry并不是为了解决客观性上的所有问题,后续还有很多工作需要进行,例如:
- 提供统一的后端存储,目前三类数据都是存储在不同系统中
- 提供计算、分析的方法和最佳实践,例如动态拓扑分析
- 统一的可视化方案
- AIOps相关能力,例如Anomaly Detection、Root Cause Analysis等
原文链接
本文为云栖社区原创内容,未经允许不得转载。












