大家好,我是皮皮。
一、前言
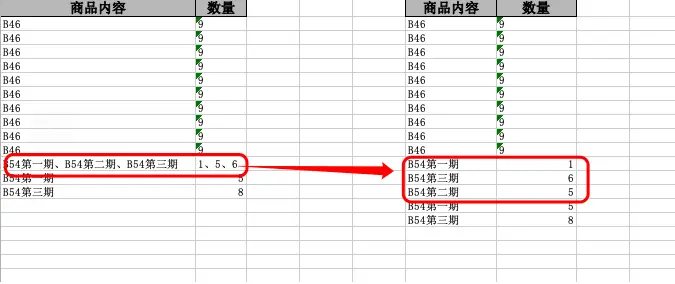
前几天在Python白银交流群【Jethro Shen】问了一个Pandas数据处理的问题。问题如下:各位大佬这种情况我怎么处理一下啊?标记的商品内容后后面的数量是一一对应的 想把它们铺开。
下面是他自己写的代码:
jigou_df = pd.read_excel(jigou_path)
data = {'商品内容':jigou_df['商品内容'],'数量':jigou_df['数量']}
df = pd.DataFrame(data)
df_expanded = df.assign(数量=df['数量'].astype(str).str.split(',')).explode('数量')
df_expanded.reset_index(drop=True, inplace=True)
df_expanded不过运行结果不是他想要的。
二、实现过程
后来【瑜亮老师】给了一个提示:先对两列执行split,然后再对两列explode,df = df.explode(['商品内容', '数量']).reset_index(drop=True)
这里【东哥】给出了具体的代码,如下所示:
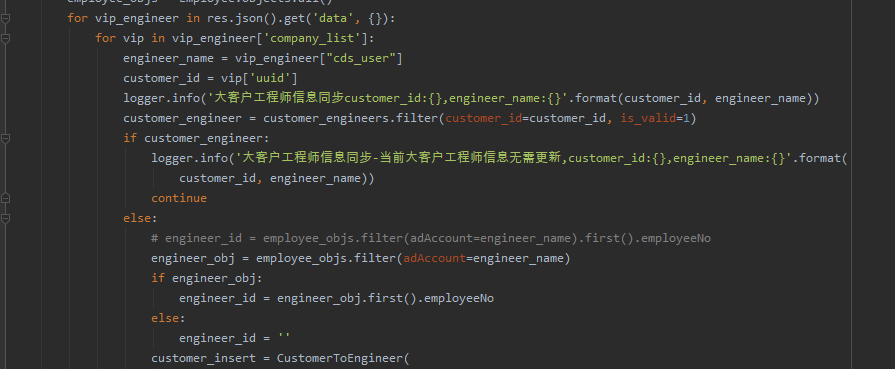
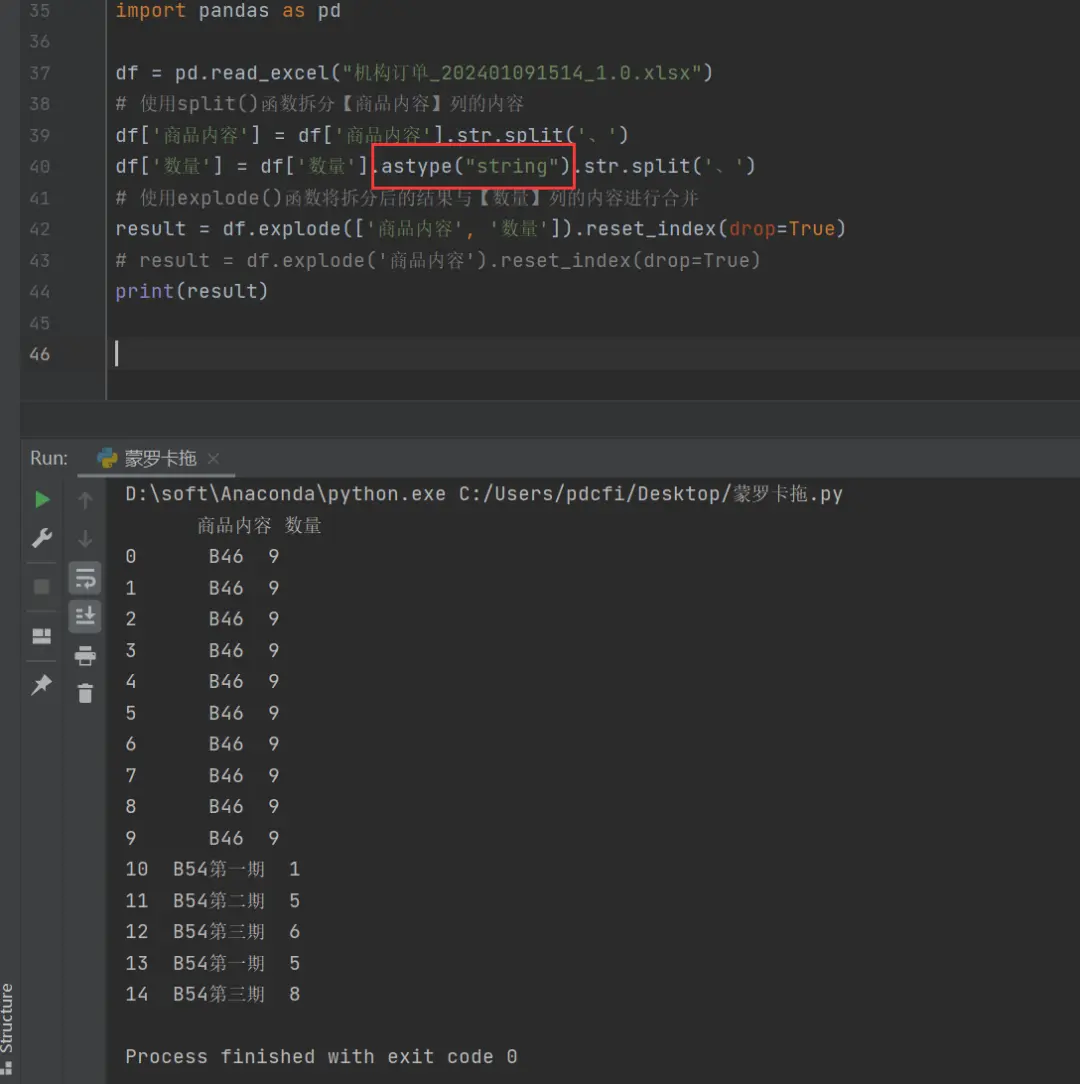
import pandas as pd
df = pd.read_excel("机构订单_202401091514_1.0.xlsx")
# 使用split()函数拆分【商品内容】列的内容
df['商品内容'] = df['商品内容'].str.split('、')
df['数量'] = df['数量'].str.split('、')
# 使用explode()函数将拆分后的结果与【数量】列的内容进行合并
result = df.explode(['商品内容', '数量']).reset_index(drop=True)
# result = df.explode('商品内容').reset_index(drop=True)
print(result)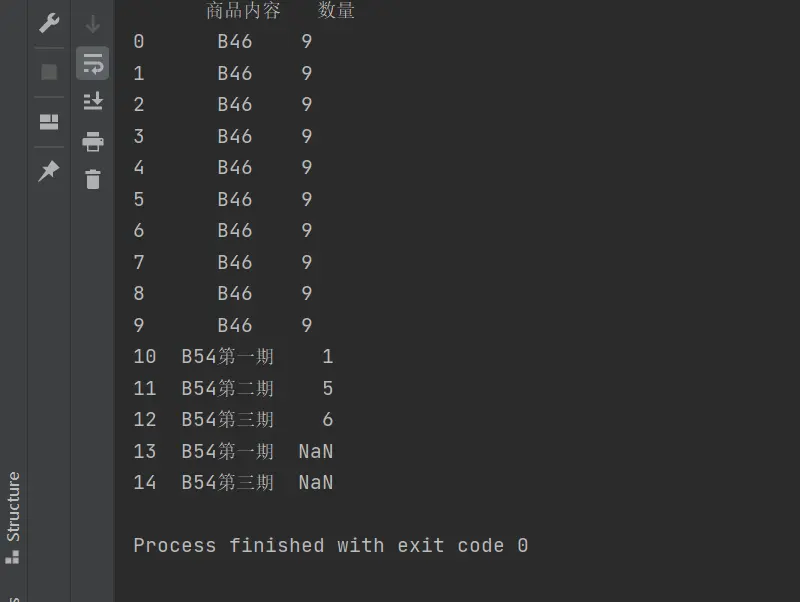
结果是可以出来的,不过最后两行却是nan,这个是为啥?我看excel中数据类型是数值,不是字符串,得到的结果就是nan。
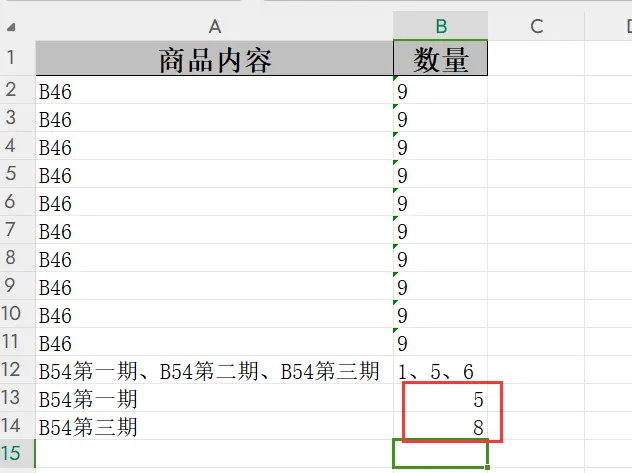
如果我把最后两行手动改为字符串格式的话,结果正常显示。
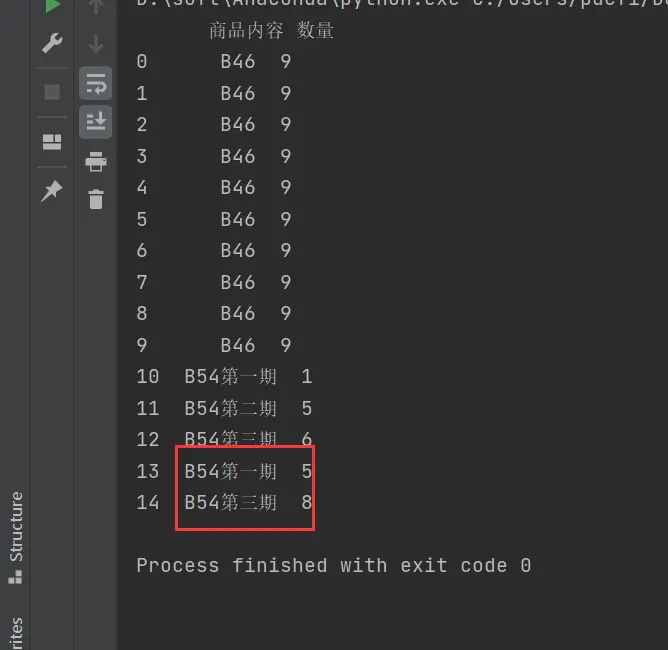
后来搞定了,df['数量'] = df['数量'].astype("string").str.split('、'),加一行转字符串就好了。
顺利地解决了粉丝的问题。也可以读取的时候直接dtype=str这样避免这类的问题,也可以用astype,还可以map的时候lambda中用str(x).split,反正方法很多,都可以避免这类的问题。
如果你也有类似这种数据分析的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Pandas数据处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【Jethro Shen】提出的问题,感谢【瑜亮老师】、【东哥】给出的思路,感谢【莫生气】、【冯诚】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。