
ELK+Filebeat+Kafka+ZooKeeper 构建海量日志分析平台
参考:http://www.tuicool.com/articles/R77fieA
我在做ELK日志平台开始之初选择为ELK+Redis直接构建,在采集nginx日志时一切正常,当我采集我司业务报文日志类后,logstash会报大量的redis connect timeout。换成redis cluster后也是同样的情况后,就考虑对消息中间件进行替换重新选型,经过各种刷文档,决定选用kafka来替换redis。根据网上找的一篇参考文档中的架构图如下:
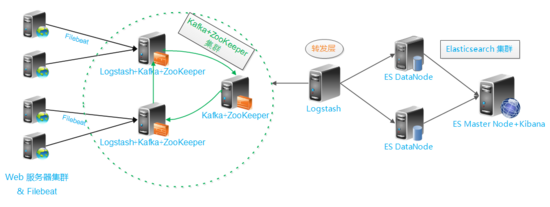
注:由于环境有限,在对该架构图中的elasticsearch集群与logstash转发层进行了合并在一台服务器上。
架构解读 : (整个架构从左到右,总共分为5层)(本文将第三层以下的进行了合并,无elasticsearch集群)
第一层、数据采集层
最左边的是业务服务器集群,上面安装了filebeat做日志采集,同时把采集的日志分别发送给两个logstash服务。
第二层、数据处理层,数据缓存层
logstash服务把接受到的日志经过格式处理,转存到本地的kafka broker+zookeeper 集群中。
第三层、数据转发层
这个单独的Logstash节点会实时去kafka broker集群拉数据,转发至ES DataNode。
第四层、数据持久化存储
ES DataNode 会把收到的数据,写磁盘,建索引库。
第五层、数据检索,数据展示
ES Master + Kibana 主要 协调 ES集群,处理数据检索请求,数据展示。
一、环境准备
操作系统环境:(测试环境统一为centos7;正式线上环境:采集层、处理缓存层为centos6.5,转发层、持久层、检索展示层为centos7)(本文以实验环境进行撰写)
服务器角色分配:
主机IP
角色
所属服务层
部署服务
192.168.11.11
日志生产
采集层
filebeat
192.168.11.12
日志缓存
数据处理层、缓存层
Zookeeper+kafka+logstash
192.168.11.13
192.168.11.14
日志展示
持久、检索、展示层
Logstash+elasticsearch+kibana
软件包版本:
jdk-8u112-linux-x64
filebeat-5.2.0-linux-x86_64
logstash-5.2.0
kafka_2.11-0.10.1.1
kibana-5.2.0-linux-x86_64
elasticsearch-5.2.0
zookeeper-3.4.9
二、部署安装
(一)、部署l****ogstash+elasticsearch+kibana(持久、检索、展示层)
1、jdk解压部署
[webapp@localhost ~]$ tar -xzf jdk-8u112-linux-x64.tar.gz -C /data/webapp/
2、配置jdk环境变量
[webapp@localhost ~]$ cat .bash_profile
# .bash_profile
# Get the aliases and functions
if [ -f ~/.bashrc ]; then
. ~/.bashrc
fi
# User specific environment and startup programs
export JAVA_HOME=/data/webapp/jdk1.8.0_112
PATH=$JAVA_HOME/bin:$PATH:$HOME/.local/bin:$HOME/bin
export PATH
3、系统调优
[webapp@localhost ~]$ vim /etc/sysctl.conf
fs.file-max=65536
vm.max_map_count = 262144
[webapp@localhost ~]$ vim /etc/security/limits.conf
* soft nofile 65535
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
4、解压部署logstash+elasticsearch+kibana
[webapp@localhost ~]$ unzip -d /data/webapp/ elasticsearch-5.2.0.zip
[webapp@localhost ~]$ tar -xzf logstash-5.2.0.tar.gz -C /data/webapp/
[webapp@localhost ~]$ tar -xzf kibana-5.2.0-linux-x86_64.tar.gz -C /data/webapp/
4.1、配置logstash的配置文件
[webapp@localhost ~]$ cd /data/webapp/logstash-5.2.0/config/
[webapp@localhost config]$ vim logstash_to_es.conf
input {
kafka {
bootstrap_servers => "192.168.11.12:9092,192.168.11.13:9092"
topics => ["ecplogs"]
}
}
output {
elasticsearch {
hosts => ["192.168.11.14:9200"]
index => "ecp-log-%{+YYYY.MM.dd}"
flush_size => 20000
idle_flush_time => 10
template_overwrite => true
}
}
注:["ecplogs"]此字段是kafka的消息主题,后边在部署kafka后需要创建
4.2、配置logstash的启动脚本
[webapp@localhost config]$ cd ../bin/
[webapp@localhost bin]$ vim start-logstash.sh
#!/bin/bash
export JAVA_HOME=/data/webapp/jdk1.8.0_112
export JRE_HOME=/data/webapp/jdk1.8.0_112/jre
export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
/data/webapp/logstash-5.2.0/bin/logstash -f /data/webapp/logstash-5.2.0/config/logstash_to_es.conf > /dev/null &
4.3、配置elasticsearch的配置文件
[webapp@localhost ~]$ cd /data/webapp/elasticsearch-5.2.0/config/
[webapp@localhost config]$ vim elasticsearch.yml
node.name:elk1
path.data:/data/webapp/elk_data
path.logs:/data/webapp/elk_data
network.host: 192.168.11.14
http.port: 9200
4.4、配置JVM(正式环境不需要,测试环境内存较小需要更改,将2g改为512M)
[webapp@localhost config]$ vim jvm.options
-Xms512m
-Xmx512m
4.5、配置Kibana的配置文件
[webapp@localhost ~]$ cd /data/webapp/kibana-5.2.0-linux-x86_64/config/
[webapp@localhost config]$ vim kibana.yml
server.port: 5601
server.host: "192.168.11.14"
elasticsearch.url: "http://192.168.11.14:9200"
(二)、部署Zookeeper+kafka+logstash(双机集群缓存处理层,正式环境建议三台)
1、部署zookeeper集群
[webapp@localhost ~]$ tar -xzf zookeeper-3.4.9.tar.gz -C /data/webapp/
[webapp@localhost ~]$ cd /data/webapp/zookeeper-3.4.9/conf/
[webapp@localhost conf]$ cp zoo_sample.cfg zoo.cfg
[webapp@localhost conf]$ vim zoo.cfg
dataDir=/data/webapp/zookeeper-3.4.9/zookeeper
server.1=192.168.11.12:12888:13888
server.2=192.168.11.13:12888:13888
[webapp@localhost conf]$ echo 1 > /data/webapp/zookeeper-3.4.9/zookeeper/myid
注:在另外一台配置文件相同,只需要将myid重置为2
[webapp@localhost conf]$ echo 2 > /data/webapp/zookeeper-3.4.9/zookeeper/myid
2、启动zookeeper服务(在两台服务器中都启动)
[webapp@localhost zookeeper-3.4.9]$ bin/zkServer.sh start
2.1、查看两台zookeeper集群状态
[webapp@localhost zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/webapp/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
[webapp@localhost zookeeper-3.4.9]$ bin/zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /data/webapp/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader
3、配置kafka集群
[webapp@localhost ~]$ tar -xzf kafka_2.11-0.10.1.1.tgz -C /data/webapp/
[webapp@localhost ~]$ cd /data/webapp/kafka_2.11-0.10.1.1/config/
[webapp@localhost config]$ vim server.properties
broker.id=1
port = 9092
host.name = 192.168.11.12
log.dirs=/data/webapp/kafka-logs
log.retention.hours=1
zookeeper.connect=192.168.11.12:2181,192.168.11.13:2181
default.replication.factor=2
注:两台集群配置只需要将broker.id、host.name进行修改,其它一致。
[webapp@localhost config]$ vim server.properties
broker.id=2
host.name = 192.168.11.13
4、启动kafka集群(在两台服务器中都启动)
[webapp@localhost kafka_2.11-0.10.1.1]$ bin/kafka-server-start.sh -daemon config/server.properties
4.1、创建消息主题
[webapp@localhost kafka_2.11-0.10.1.1]$ bin/kafka-topics.sh --create --zookeeper 192.168.11.11:2181 --replication-factor 1 --partitions 2 --topic ecplogs
4.2、测试消息生产与消费
在主机192.168.11.13上进行消息消费
[webapp@localhost kafka_2.11-0.10.1.1]$ /data/webapp/kafka_2.11-0.10.1.1/bin/kafka-console-consumer.sh --zookeeper 192.168.11.11:2181 --topic ecplogs --from-beginning
在主机192.168.11.12上进行消息生产:
[webapp@localhost kafka_2.11-0.10.1.1]$ bin/kafka-console-producer.sh --broker-list 192.168.11.11:9092 --topic ecplogs
在此终端中输入数据,会在192.168.11.13终端上进行显示出来。那么kafka功能正常。
5、配置logstash
5.1配置logstash的配置文件
[webapp@localhost ~]$ tar -xzf logstash-5.2.0.tar.gz -C /data/webapp/
[webapp@localhost ~]$ cd /data/webapp/logstash-5.2.0/config/
[webapp@localhost config]$ vim logstash_in_filebeat.conf
input {
beats {
port => 5044
}
}
output {
kafka {
bootstrap_servers => "192.168.11.12:9092,192.168.11.13:9092"
topic_id => "ecplogs"
}
}
5.2配置Logstash启动脚本(如4.2)
(三)、部署filebeat(日志采集)
1、解压部署
[webapp@localhost ~]$ tar -xzf filebeat-5.2.0-linux-x86_64.tar.gz -C /data/webapp/
2、配置filebeat配置文件
[webapp@localhost ~]$ cd /data/webapp/filebeat-5.2.0-linux-x86_64/
[webapp@localhost filebeat-5.2.0-linux-x86_64]$ vim filebeat.yml
filebeat.prospectors:
- input_type: log
paths:
- /data/logs/ecplog.log
multiline.pattern: ^请
multiline.negate: true
multiline.match: after
output.logstash:
hosts: ["192.168.11.13:5044"]
注解:该配置文件格式参照yml型,multiline.x配置项为多行合并规则,如无,可以不用配置
3、启动filebeat
[webapp@localhost filebeat-5.2.0-linux-x86_64]$ nohup ./filebeat -c filebeat.yml > /dev/null &
(四)各环节服务器启动与数据追踪
1、启动192.168.11.12/13服务器上的logstash
[webapp@localhost ~]$ /data/webapp/logstash-5.2.0/bin/start-logstash.sh
2、在192.168.11.12/13终端上进行日志消费测试
[webapp@localhost kafka_2.11-0.10.1.1]$ /data/webapp/kafka_2.11-0.10.1.1/bin/kafka-console-consumer.sh --zookeeper 192.168.11.11:2181 --topic ecplogs --from-beginning
注:如果配置正常,该两终端中会都会源源不断的输出/data/logs/ecplog.log的日志数据。
3、启动192.168.11.14服务器上的logstash+es+kibana
4、测试es数据索引
[webapp@localhost ~]$ curl "http://192.168.11.14:9200/ecplogs-2017.02.09"
注:如果配置正常,curl出来的是有数据的,而非404类
5、通过web展示,访问http://192.168.11.14:5601
6、Kibanad页面配置(略)











