数据分析与可视化概述
一、数据、信息与数据分析
- 数据:是指对客观事件进行记录并可以鉴别的符号,是对客观事物的性质、状态以及相互关系等进行记载的物理符号或这些物理符号的组合。它是可识别的、抽象的符号。
- 数据是信息的表现形式和载体,可以是符号、文字、数字、语音、图像、视频等
- 数据聚焦于数据的采集、清理、预处理、分析和挖掘,图形聚焦于解决对光学图像进行接收、提取信息、加工变换、模式识别及存储显示,可视化聚焦于解决将数据转换成图形,并进行交互处理。
- 信息:是数据的内涵,信息是加载于数据之上,对数据作具有含义的解释。
- 数据和信息是不可分离的,信息依赖数据来表达,数据则生动具体表达出信息。
- 数据是符号,是物理性的,信息是对数据进行加工处理之后得到、并对决策产生影响的数据,是逻辑性和观念性的;
- 数据是信息的表现形式,信息是数据有意义的表示。数据是信息的表达、载体,信息是数据的内涵,是形与质的关系。
- 数据本身没有意义,数据只有对实体行为产生影响时才成为信息。
- 数据分析:是指用适当的统计分析方法对收集来的大量数据进行分析,为提取有用信息和形成结论而对数据加以详细研究和概括总结的过程。
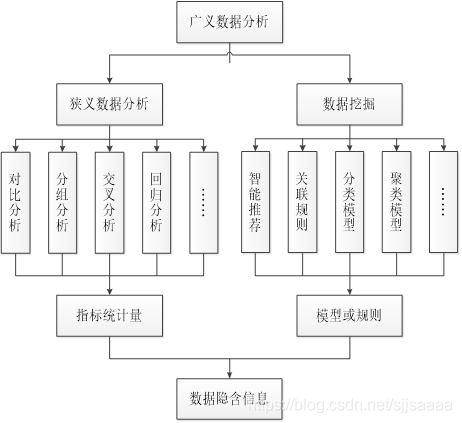
- 数据分析就是针对搜集来的数据运用基础探索、统计分析、深层挖掘等方法,发现数据中有用的信息和未知的规律与模式,进而为下一步的业务决策提供理论与实践依据。所以广义的数据分析就包含 了数据挖掘的部分
数据挖掘与数据分析:
- 数据分析是指根据分析目的,采用对比分析、分组分析、交叉分析和回归分析等分析方法,对收集来的数据进行处理与分析,提取有价值的信息,发挥数据的作用,得到一个特征统计量结果的过程。
- 数据挖掘则是从大量的、不完全的、有噪声的、模糊的、随机的实际应用数据中,通过应用聚类、分类、回归和关联规则等技术,挖掘潜在价值的过程。
二者区别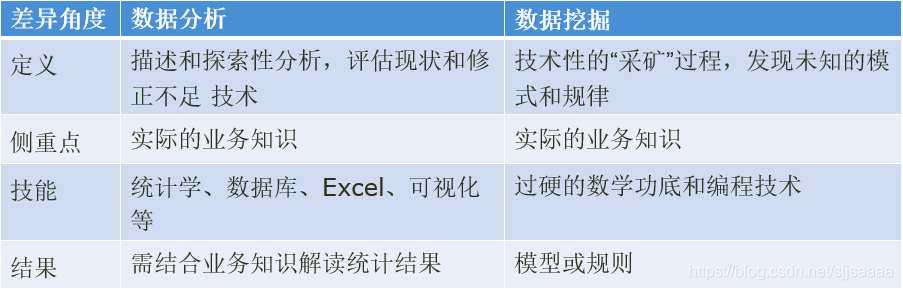
数据分析的流程: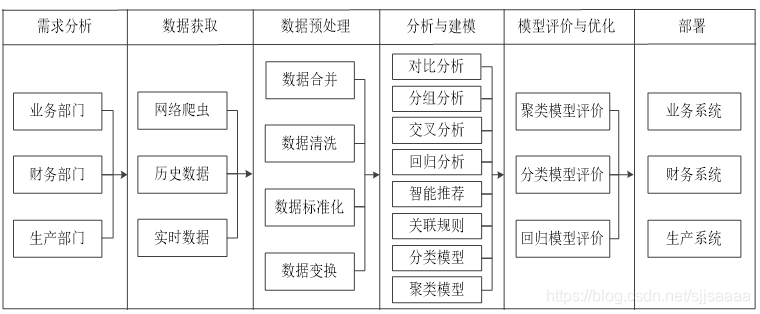
- 需求分析:数据分析中的需求分析也是数据分析环节的第一步和最重要的步骤之一,决定了后续的分析的方向、方法。
- 数据获取:数据是数据分析工作的基础,是指根据需求分析的结果提取,收集数据。
- 数据预处理:数据预处理是指对数据进行数据合并,数据清洗,数据变换和数据标准化,数据变换后使得整体数据变为干净整齐,可以直接用于分析建模这一过程的总称。
- 分析与建模:分析与建模是指通过对比分析、分组分析、交叉分析、回归分析等分析方法和聚类、分类、关联规则、智能推荐等模型与算法发现数据中的有价值信息,并得出结论的过程。
- 模型评价与优化:模型评价是指对已经建立的一个或多个模型,根据其模型的类别,使用不同的指标评价其性能优劣的过程。
- 部署:部署是指将通过了正式应用数据分析结果与结论应用至实际生产系统的过程。
二、数据可视化
- 数据可视化:是关于数据视觉表现形式的科学技术研究。其中,这种数据的视觉表现形式被定义为“一种以某种概要形式抽提出来的信息,包括相应信息单位的各种属性和变量”。
- 数据可视化主要是借助于图形化手段,清晰有效地传达与沟通信息。
数据:聚焦于解决数据的采集、清理、预处理、分析和挖掘
图形:聚焦于解决对光学图像进行接收、提取信息、加工变换、模式识别及存储显示
可视化:聚焦于解决将数据转换成图形,并进行交互处理
数据可视化方法:
- 面积&尺寸可视化
- 颜色可视化
- 图形可视化
- 概念可视化
注意:
- 做数据可视化时,几种方法经常是混合用的,尤其是做一些复杂图形和多维度数据的展示时。
- 做出的可视化图表一定要易于理解,在显性化的基础上越美观越好,切忌华而不实。
- 数据可视化要根据数据的特性,如时间和空间信息等,找到合适的可视化方式,将数据用直观地展现出来,以帮助人们理解数据,同时找出包含在海量数据中的规律或者信息。
三、数据分析与可视化常用工具
1.Microsoft Excel
2.R语言
3.Python语言
4.JavaScript
5.PHP
四、为何选用Python
Python语言是一种解释型、面向对象、动态数据类型的高级程序设计语言
Python语言是数据分析师的首选数据分析语言,也是智能硬件的首选语言
优点:
1.简单易学
Python是一种代表简单主义思想的语言,它有极简单的语法,极易上手。
2.集解释性与编译性于一体
Python语言写的程序不需要编译成二进制代码,可以直接从源代码运行程序,但是需要解释器,它也具有编译执行的特性。
3.面向对象编程
Python 即支持面向过程的编程也支持面向对象的编程。与其他主要的语言如C++ 、Java相比,Python以一种非常强大又简单的方式实现面向对象编程。
4.可扩展性和可嵌入性
可以把部分程序用C或C++编写,然后在Python程序中使用它们,也可以把Python嵌入到C/C++ 程序中,提供脚本功能。
5.程序的可移植性
绝大多数的的Python程序不做任何改变即可在主流计算机平台上运行。
6.免费、开源
可以自由地发布这个软件的拷贝、阅读它的源代码、对它做改动、把它的一部分用于新的自由软件中。

缺点:
Python的唯一缺点是与C和C++相比执行的效率还不够快,因为Python没有将代码编译成底层的二进制代码;
应用举例:
使用turtle画一只乌龟:
#!python
"""画一个小乌龟"""
import turtle as t;
t.pensize(2)
t.hideturtle()
t.colormode(255)
t.color((0,0,0),"Green")
t.setup(500,500)
t.speed(5)
t.penup()
t.goto(0,-100)
t.pendown()
t.circle(100)
t.penup()
t.goto(-20,35)
t.pendown()
t.begin_fill()
t.forward(40)
t.seth(-60)
t.forward(40)
t.seth(-120)
t.forward(40)
t.seth(-180)
t.forward(40)
t.seth(120)
t.forward(40)
t.seth(60)
t.forward(40)
t.end_fill()
t.seth(120)
t.color((0,0,0),(29,184,130))
for i in range(6):
t.begin_fill()
t.forward(60)
t.right(90)
t.circle(-100,60)
t.right(90)
t.forward(60)
t.right(180)
t.end_fill()
t.penup()
t.goto(-15,100)
t.seth(90)
t.pendown()
t.forward(15)
t.circle(-15,180)
t.forward(15)
for i in range(4):
t.penup()
t.goto(0,0)
if i==0:
t.seth(35);
if i==1:
t.seth(-25)
if i==2:
t.seth(-145)
if i==3:
t.seth(-205)
t.forward(100)
t.right(5)
t.pendown()
t.forward(10)
t.circle(-10,180)
t.forward(10)
t.penup()
t.goto(10,-100)
t.seth(-90)
t.pendown()
t.forward(10)
t.circle(-30,60)
t.right(150)
t.circle(30,60)
t.goto(-10,-100) 
五、Python常用类库
1. Numpy
NumPy软件包是Python生态系统中数据分析、机器学习和科学计算的主力军。它极大地简化了向量和矩阵的操作处理。
除了能对数值数据进行切片(slice)和切块(dice)外,使用NumPy还能为处理和调试上述库中的高级实例带来极大便利。
一般被很多大型金融公司使用,以及核心的科学计算组织如Lawrence Livermore、NASA用其处理一些本来使用C++、Fortran或Matlab等所做的任务。
2. SciPy
SciPy(http://scipy.org)是基于NumPy开发的高级模块,依赖于NumPy,提供了许多数学算法和函数的实现,可便捷快速地解决科学计算中的一些标准问题,例如数值积分和微分方程求解、最优化、甚至包括信号处理等。
作为标准科学计算程序库, SciPy它是Python科学计算程序的核心包,包含了科学计算中常见问题的各个功能模块,不同子模块适用于不同的应用。
3. Pandas
Pandas提供了大量快速便捷处理数据的函数和方法。它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas中主要的数据结构有Series、DataFrame和Panel。其中Series是一维数组,与NumPy中的一维array以及Python基本的数据结构List类似;DataFrame是二维的表格型数据结构,可以将DataFrame理解为Series的容器; Panel是三维的数组,可看作为DataFrame的容器。
4. Matplotlib
Matplotlib是Python 的绘图库,是用于生成出版质量级别图形的桌面绘图包,让用户很轻松地将数据图形化,同时还提供多样化的输出格式。
5. Seaborn
Seaborn在Matplotlib基础上提供了一个绘制统计图形的高级接口,为数据的可视化分析工作提供了极大的方便,使得绘图更加容易。
用Matplotlib最大的困难是其默认的各种参数,而Seaborn则完全避免了这一问题。一般来说,Seaborn能满足数据分析90%的绘图需求。
6. Scikit-learn
Scikit-learn是专门面向机器学习的Python开源框架,它实现了各种成熟的算法,容易安装和使用。
Scikit-learn的基本功能有分类、回归、聚类、数据降维、模型选择和数据预处理六大部分。
六、 数据科学计算平台—Anaconda
Anaconda是一个集成的Python数据科学环境,简单的说,Anaconda除了有Python外,还安装了180多个用于数据分析的第三方库,而且可以使用conda命令安装第三方库和创建多个环境。相对于只安装Python而言,避免了安装第三方库的麻烦。
网站:
https://mirror.tuna.tsinghua.edu.cn/help/anaconda/
Jupyter Notebook的使用:
Jupyter Notebook(Julia+Python+R = Jupyter)基于Web技术的交互式计算文档格式,支持Markdown和Latex语法,支持代码运行、文本输入、数学公式编辑、内嵌式画图和其他如图片文件的插入,是一个对代码友好的交互式笔记本。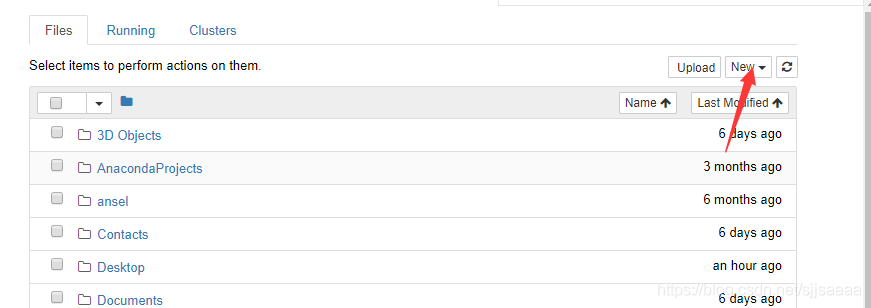
- Files 基本上列出了所有的文件,
- Running 显示了当前已经打开的终端和Notebooks,
- Clusters 由 IPython parallel 包提供,用于并行计算。
- 若要创建新的Notebook,只需单击页面右上角的New按钮,在下拉选项中选择python3,即可得到一个空的notebook界面
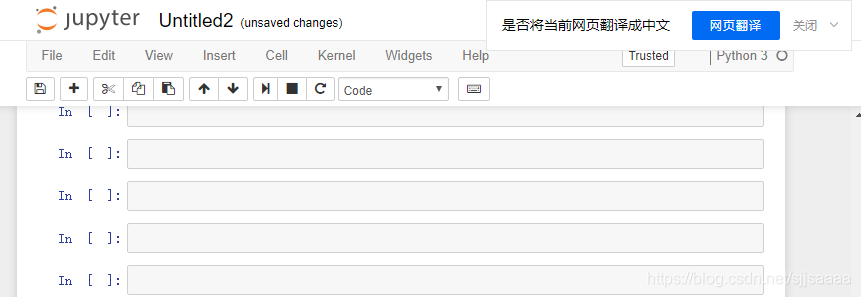
- 在编辑区可以看到一个个单元(cell)。如图所示,每个cell以“In[ ]”开头,可以输入正确的Python代码并执行。
- 例如,输入"python " + “program”,然后按“Shift+Enter”,代码将被运行后,编辑状态切换到新的cell
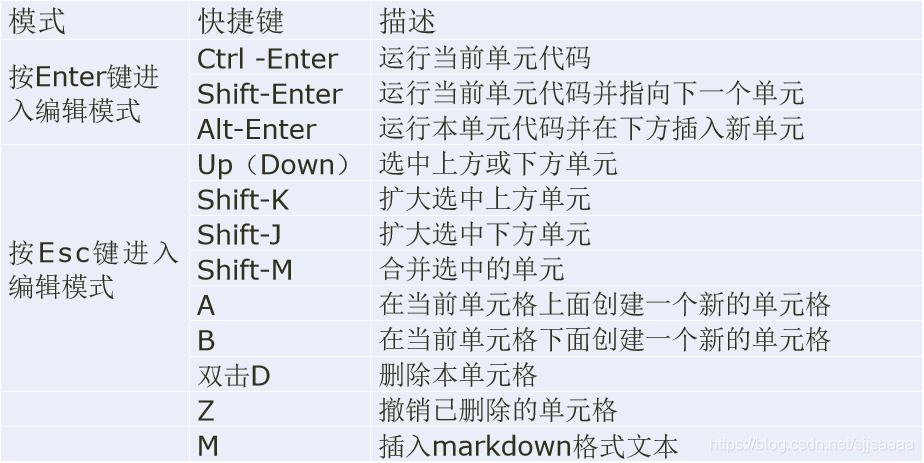
Jupyter notebook中的常用快捷方式: