
前期,我参与了公司开发的数据库数据迁移工具的工作,以及之前的对Page的分析记录,在此进一步将数据库的数据类型做一下分析记录。
一、数据库系统表pg_type
PostgreSQL的所有数据类型都存储在系统表pg_type中。
pg_type的表结构如下(这里是从源码中进行介绍的,源码可以点击pg_type.h):
CATALOG(pg_type,1247) BKI_BOOTSTRAP BKI_ROWTYPE_OID(71) BKI_SCHEMA_MACRO
{
NameData typname; /* type name */
Oid typnamespace; /* OID of namespace containing this type */
Oid typowner; /* type owner */
int16 typlen;
bool typbyval;
char typtype;
char typcategory; /* arbitrary type classification */
bool typispreferred; /* is type "preferred" within its category? */
bool typisdefined;
char typdelim; /* delimiter for arrays of this type */
Oid typrelid; /* 0 if not a composite type */
Oid typelem;
Oid typarray;
regproc typinput; /* text format (required) */
regproc typoutput;
regproc typreceive; /* binary format (optional) */
regproc typsend;
regproc typmodin;
regproc typmodout;
regproc typanalyze;
char typalign;
char typstorage;
bool typnotnull;
Oid typbasetype;
int32 typtypmod;
int32 typndims;
Oid typcollation;
#ifdef CATALOG_VARLEN /* variable-length fields start here */
pg_node_tree typdefaultbin;
text typdefault;
aclitem typacl[1];
#endif
} FormData_pg_type;
下面来简单介绍pg_type的各个字段含义。
typname、typnamespace、typowner 这三个字段名字上就可以看出来他们的含义。
typlen:这是标明类型的长度的,如果类型是定长的就是写明字段的长度(字节)。如果是变长的则是-1。比如int4也就是int或者integer,**typlen为4,占用4个字节,varchar则为-1。
typbyval:判断内部过程传递这个类型的数值时是通过传值还是传引用。如果该类型不是 1, 2, 4, 8 字节长将只能按应用传递,因此 typbyval 最好是假。 即使可以传值,typbyval 也可以为假。比如float4**就是如此。
typtype:对于基础类型是b, 对于复合类型是 c (比如,一个表的行类型)。对于域类型是d,对于伪类型是p.
本博文也是主要分析基础类型。
**typcategory**:这是对数据类型进行分类的,int2、int4、int8的typcategory都是N。typcategory的分类详看下表:
Code
Category
A
Array types
B
Boolean types
C
Composite types
D
Date/time types
E
Enum types
G
Geometric types
I
Network address types
N
Numeric types
P
Pseudo-types
R
Range types
S
String types
T
Timespan types
U
User-defined types
V
Bit-string types
X
unknown type
**typispreferred**:这个字段和 typcategory是一起工作的,表示是否在 typcategory分类中首选的。
**typisdefined**:这个字段是类型能否使用的前提,标识数据类型是否被定义,false的话,根本无法使用。(大家可以将int4的 typis的fined改为false,然后用int4作为表的字段类型建表,会直接报错type integer is only a shell)。
**typdelim**:当分析数组输入时,分隔两个此类型数值的字符请注意该分隔符是与数组元素数据类型相关联的,而不是和数组数据类型关联。
**typrelid**:如果是复合类型(见 typtype)那么这个字段指向 pg_class 中定义该表的行。对于自由存在的复合类型,pg_class 记录并不表示一个表,但是总需要它来查找该类型连接的 pg_attribute 记录。对于非复合类型为零。
**typelem**:如果不为 0 ,那么它标识 pg_type 里面的另外一行。当前类型可以当做一个产生类型为 typelem 的数组来描述。一个"真正的"数组类型是变长的(typlen = -1),但是一些定长的(typlen > 0)类型也拥有非零的 typelem(比如 name 和 point)。如果一个定长类型拥有一个 typelem ,那么他的内部形式必须是 typelem 数据类型的某个数目的个数值,不能有其它数据。变长数组类型有一个该数组子过程定义的头(文件)。
**typarray**:指向同类型的数组类型的Oid。
**typinput,typoutput**:类型的输入输出函数,数据库进行对数字进行存储或者输出,首先由客户端获取数据 (一般为字符串 )进行转化,变为数据库能够使用的数据类型。输出函数亦然。
**typreceive,typsend**:输入、输出转换函数,多用于二进制格式。
**typmodin,typmodout**:对于变长的数据的输入、输出,这里主要是指vachar、time、timestamp等。这个字段和系统表pg_attribute的atttypmod相关联。
**typanalyze**:自定义的 ANALYZE 函数,如果使用标准函数,则为 0。 **typalign**:当存储此类型的数值时要求的对齐性质。它应用于磁盘存储以及该值在 PostgreSQL 内部的大多数形式。如果数值是连续存放的,比如在磁盘上以完全的裸数据的形式存放时,那么先在此类型的数据前填充空白,这样它就可以按照要求的界限存储。对齐引用是该序列中第一个数据的开头。
可能的值有:
c = char 对齐,也就是不需要对齐。
s = short 对齐(在大多数机器上是 2 字节)
i = int 对齐(在大多数机器上是 4 字节)
d = double 对齐(在大多数机器上是 8 字节,但不一定是全部)
**typstorage**:告诉一个变长类型(那些有 typlen = -1)的)说该类型是否准备好应付非常规值,以及对这种属性的类型的缺省策略是什么。可能的值有:
p: 数值总是以简单方式存储
e: 数值可以存储在一个"次要"关系中
m: 数值可以以内联的压缩方式存储
x: 数值可以以内联的压缩方式或者在"次要"表里存储。
请注意 m 域也可以移到从属表里存储,但只是最后的解决方法(e 和 x 域先移走)。
**typnotnull**:代表在某类型上的一个 NOTNULL 约束。目前只用于域。
**typbasetype**:如果这是一个衍生类型(参阅 typtype),那么该标识作为这个类型的基础的类型。如果不是衍生类型则为零。
**typtypmod**:域使用 typtypmod 记录要作用到它们的基础类型上的 typmod (如果基础类型不使用 typmod 则为 -1)。如果这种类型不是域,那么为 -1 。
**typndims**:如果一个域是数组,那么 typndims 是数组维数的数值(也就是说,typbasetype 是一个数组类型;域的 typelem 将匹配基本类型的 typelem)。非域非数组域为零。
**typcollation**:指定类型的排序规则。如果类型不支持的排序规则,这将是零。支持排序规则基本类型都会有DEFAULT_COLLATION_OID这里。在一个collatable类型一个域可以有一些其他的排序规则的OID,如果已为域指定。
**typdefaultbin**:如果为非 NULL ,那么它是该类型缺省表达式的 nodeToString() 表现形式。目前这个字段只用于域。 **typdefault**:如果某类型没有相关缺省值,那么 typdefault 是 NULL 。如果 typdefaultbin 不是 NULL ,那么 typdefault 必须包含一个 typdefaultbin 代表的缺省表达式的人类可读的版本。如果 typdefaultbin 为 NULL 但 typdefault 不是,那么 typdefault 是该类型缺省值的外部表现形式,可以把它交给该类型的输入转换器生成一个常量。
**typacl**[1]:用户对类型的权限。
rolename=xxxx -- privileges granted to a role
=xxxx -- privileges granted to PUBLIC
r -- SELECT ("read")
w -- UPDATE ("write")
a -- INSERT ("append")
d -- DELETE
D -- TRUNCATE
x -- REFERENCES
t -- TRIGGER
X -- EXECUTE
U -- USAGE
C -- CREATE
c -- CONNECT
T -- TEMPORARY
arwdDxt -- ALL PRIVILEGES (for tables, varies for other objects)
* -- grant option for preceding privilege
/yyyy -- role that granted this privilege
以上就是对系统表pg_type的介绍。下面主要针对每一个基础数据类型分析。
二、类型详解:
1、整数类型
(1)整数类型:
首先是整数类型int2、int4(等价integer)、int8。
为了方便说明,用下表来说明一下:
PostgreSQL类型名
占位(字节)
C\C++类型名
Java类型名
取值范围
int2(samllint)
2
short int
short
-32,768到32,767
int4(int、integer)
4
int
int
-2,147,483,648到2,147,483,647
int8(bigint)
8
long int
long
-9,223,372,036,854,775,808到9,223,372,036, 854,775,807
在数据库物理文件存储的整数数字是以二进制的形式存储的。下面做一下小实验:
highgo=# create table aa(a1 int2, a2 int4, a3 int8);
CREATE TABLE
highgo=# insert into aa values (204,56797,2863311530);
INSERT 0 1
highgo=# checkpoint ;
CHECKPOINT
通过hexdump(输出16进制 )对二进制文件进行查看:
[root@localhost 12943]# hexdump 16385
0000000 0000 0000 1420 018a 0000 0000 001c 1fd8
0000010 2000 2004 0000 0000 9fd8 0050 0000 0000
0000020 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fd0 0000 0000 0000 0000 069b 0000 0000 0000
0001fe0 0000 0000 0000 0000 0001 0003 0800 0018
0001ff0 00cc 0000 dddd 0000 aaaa aaaa 0000 0000
0002000
cc、dddd、aaaaaaaa正好是我插入的三个数字204, 56797, 2863311530。
(2)浮点数
float4、float8:这两个类型有些不同,先看看范围:
float4(real)
4
float
float
6 位十进制数字精度
float8(double precision)
8
double
double
15 位十进制数字精度
在源码中为:
typedef float float4;
typedef double float8;
存储方式和C\C++中是相同的。可以看一下示例:
postgres=# create table floatdouble(f1 float4, d1 float8);
CREATE TABLE
postgres=# insert into floatdouble values (12345, 12345);
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
看一下物理文件存储的数据(这里都是以16进制显示的):
[root@localhost 12814]# hexdump 16399
0000000 0000 0000 9bc0 0188 0000 0000 001c 1fd8
0000010 2000 2004 0000 0000 9fd8 0050 0000 0000
0000020 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fd0 0000 0000 0000 0000 06b9 0000 0000 0000
0001fe0 0000 0000 0000 0000 0001 0002 0800 0018
0001ff0 e400 4640 0000 0000 0000 0000 1c80 40c8
0002000
12345变为了 e400 4640(float4),12345变为了 1c80 40c8。
现在简单介绍一下float,它的存储方式为:
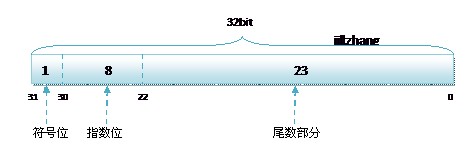
共计32位,折合4字节。由最高到最低位分别是第 31、30、29、……、0位。31位是符号位,1表示该数为负,0反之。30-23位,一共8位是指数位。22-0位,一共23 位是尾数位。
现在让我们按照IEEE浮点数表示法,一步步的将float型浮点数12345转换为十六进制代码。首先数字是正整数,所以符号位为0,接下来12345的二进制表示为11000000111001,小数点向左移,一直移到离最高位只有1位,就是最高位的1。即1.1000000111001*2^13,所有的二进制数字最前边都有一个1,所以可以去掉,那么尾数位的精确度其实可以为24 bit。再来看指数位,因为是有8 bit,所以只为能够表示的为0255,也可以说是-128127,所以指数为为正的话,必须加上127,即13+127=140,即10001100。好了,所有的数据都整理好了,现在表示12345的float存储方式即01000110010000001110010000000000,现在把它转化为16进制,即4640 e400,而存储文件是从下向上写入的,所以表示为 e400 4640。
double,它的存储方式为:
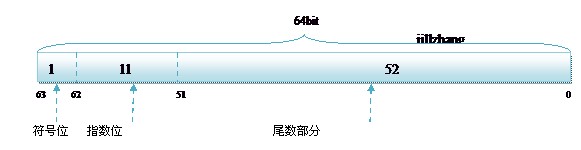
指数位与尾数部分都要比float增加了长度,所以计算方法还是同上,只不过现在的指数位要加的是1023,尾数部分自动补更多的零。
注:PostgreSQL 还支持 SQL 标准表示法 float 和 float(p) 用于声明非精确的数值类型。其中的 p 声明以二进制位表示的最低可接受精度。在选取 real 类型的时候,PostgreSQL 接受 float(1) 到 float(24),在选取 double precision 的时候,接受 float(25) 到 float(53) 。在允许范围之外的 p 值将导致一个错误。没有声明精度的 float 将被当作 double precision 。
(3)Numeric
数字类型还有一种便是numeric(decimal),这种数据类型是数字当中最为复杂的一种了,他是一种结构体,在源码中为:
typedef int16 NumericDigit;
struct NumericShort
{
uint16 n_header; /* Sign + display scale + weight */
NumericDigit n_data[1]; /* Digits */
};
struct NumericLong
{
uint16 n_sign_dscale; /* Sign + display scale */
int16 n_weight; /* Weight of 1st digit */
NumericDigit n_data[1]; /* Digits */
};
union NumericChoice
{
uint16 n_header; /* Header word */
struct NumericLong n_long; /* Long form (4-byte header) */
struct NumericShort n_short; /* Short form (2-byte header) */
};
struct NumericData
{
int32 vl_len_; /* varlena header (do not touch directly!) */
union NumericChoice choice; /* choice of format */
};
因为这里使用的是union,所以我们可以对struct重新定义一下,按照在内存中的表现形式:
struct NumericShort_memory
{
int32 vl_len_;
uint16 n_header;
NumericDigit n_data[1];
};
struct NumericLong_memory
{
int32 vl_len_;
uint16 n_sign_dscale;
int16 n_weight;
NumericDigit n_data[1];
};
还有一个比较重要的结构体,它的作用是最为char*和numeric之间进行转化的中间体:
typedef struct NumericVar
{
int ndigits; /* # of digits in digits[] - can be 0! */
int weight; /* weight of first digit */
int sign; /* NUMERIC_POS, NUMERIC_NEG, or NUMERIC_NAN */
int dscale; /* display scale */
NumericDigit *buf; /* start of palloc'd space for digits[] */
NumericDigit *digits; /* base-NBASE digits */
} NumericVar;
组成numeric的结构体就有四个,比较复杂,而且基本上都是通过数组进行存储的,他的范围为小数点前为131072位,小数点后为16383位。
首先要讲的是NumericVar,这是将数据变为numeirc的第一步,现在以‘12345.678’为例子讲一下答题过程,具体的函数以后可能会继续讲一下。数据库首先读取字符串'12345.678',然后将字符串变为NumericVar,要说明的是,数据都是存储到buf(这应该是在物理文件中的补齐所设置的,不过不是特别确定)和digits中的,比如'12345.678',是这样存储的 0000 0001 2345 6780,这些都是数字存入到数组中。ndigits是指的digits数组元素的个数,这里就是3,而weight表示的是整数部分所占用的数组元素个数,不过进行了一系列的运算,在保证有整数部分, weight = (整数部分个数 + 4 - 1)/4 - 1。sign,这是对数字进行标记的,有正负标记。dscale则表示的是小数部分数字个数。
下面主要讲一下NumericData,按照上面的顺序说明一下各个结构体的结构,
NumericShort,这是数据库对小数据进行存储用的格式。其中n_header是对数据的标记,根据正负、类型(指的是数字大小类型:NUMERIC_SIGN_MASK、NUMERIC_POS、NUMERIC_NEG、NUMERIC_SHORT、NUMERIC_NAN)weight进行运算得到一个标记。n_data和NumericVar中的digits是相同的。
标记的运算:
result->choice.n_short.n_header =
(sign == NUMERIC_NEG ? (NUMERIC_SHORT | NUMERIC_SHORT_SIGN_MASK)
: NUMERIC_SHORT)
| (var->dscale << NUMERIC_SHORT_DSCALE_SHIFT)
| (weight < 0 ? NUMERIC_SHORT_WEIGHT_SIGN_MASK : 0)
| (weight & NUMERIC_SHORT_WEIGHT_MASK);
NumericLong,这是数据库对大数据进行存储用的格式。其中n_sign_dscale是对数据的标记,根据正负、类型(指的是数字大小类型:NUMERIC_SIGN_MASK、NUMERIC_POS、NUMERIC_NEG、NUMERIC_SHORT、NUMERIC_NAN)进行运算得到一个标记。weight和NumericVar的是相同的。n_data和NumericVar中的digits是相同的。
标记的运算:
result->choice.n_long.n_sign_dscale =
sign | (var->dscale & NUMERIC_DSCALE_MASK);
result->choice.n_long.n_weight = weight;
NumericChoice,这是union,这能引用同一个存储块。然后最后总的NumericData,这里的vl_len_是对数据所占位计算而来的,计算方法见下。
在Java中可以用getBigDecimal来读取数据。
下面看一下物理存储:
postgres=# create table numerictest (n1 numeric);
CREATE TABLE
postgres=# select pg_relation_filepath('numerictest');
pg_relation_filepath
----------------------
base/12892/16390
(1 row)
postgres=# insert into numerictest values (123),(1234),(12345),(12345.678),(12345.6789),(12345.678901),(12345.123456789);
INSERT 0 7
postgres=# checkpoint ;
CHECKPOINT
[root@localhost 12892]# hexdump 16390
0000000 0000 0000 91b0 0173 0000 0000 0038 1ee0
0000010 2000 2004 0000 0000 9fe0 003a 9fc0 003a
0000020 9fa0 003e 9f78 0042 9f50 0042 9f28 0046
0000030 9f00 004a 9ee0 0036 0000 0000 0000 0000
0000040 0000 0000 0000 0000 0000 0000 0000 0000
*
0001ee0 06a0 0000 0000 0000 0000 0000 0000 0000
0001ef0 0008 0001 0802 0018 0007 0080 0000 0000
0001f00 069f 0000 0000 0000 0000 0000 0000 0000
0001f10 0007 0001 0802 0018 811b 0184 2900 d209
0001f20 2e04 2816 0023 0000 069f 0000 0000 0000
0001f30 0000 0000 0000 0000 0006 0001 0802 0018
0001f40 0117 0183 2900 8509 641a 0000 0000 0000
0001f50 069f 0000 0000 0000 0000 0000 0000 0000
0001f60 0005 0001 0802 0018 0113 0182 2900 8509
0001f70 001a 0000 0000 0000 069f 0000 0000 0000
0001f80 0000 0000 0000 0000 0004 0001 0802 0018
0001f90 8113 0181 2900 7c09 001a 0000 0000 0000
0001fa0 069f 0000 0000 0000 0000 0000 0000 0000
0001fb0 0003 0001 0802 0018 010f 0180 2900 0009
0001fc0 069f 0000 0000 0000 0000 0000 0000 0000
0001fd0 0002 0001 0802 0018 000b d280 0004 0000
0001fe0 069f 0000 0000 0000 0000 0000 0000 0000
0001ff0 0001 0001 0802 0018 000b 7b80 0000 0000
0002000
这里列一个表具体的看一下(这里只说一下short类型的):
数值
ndigits
digits
16进制
标记
文件存储
123
1
0123
7b
0x8000
000b 7b80 _00_00
1234
1
1234
04d2
0x8000
000b d280 _00_04
12345
2
0001 2345
0001 0929
0x8001
010f 0180 2900 _00_09
12345.678
3
0001 2456 6780
0001 0929 1a7c
0x8181
8113 0181 2900 7c09 _00_1a
12345.6789
3
0001 2345 6789
0001 0929 1a85
0x8201
0113 0182 2900 8509 001a 0000
12345.678901
4
0001 2345 6789 0100
0001 0929 1a85 0064
0x8301
0117 0183 2900 8509 641a 0000 0000
12345.123465789
5
0001 2345 1234 5678 9000
0001 0929 04d2 162e 2328
0x8481
811b 0184 2900 d209 2e04 2816 0023 0000
0
0
0000
0000
0x8000
0007 _00_80
注:这里的16进制是按照digits内存储的整数转换的,比如12345在数组digits内为0001,2345,转化为16进制为0001 0929。
再比如带有小数的数字例如,12345.678,在数组中为0001,2345,6780,转化为16进制为0001 0929 1a7c。 这上面的存储的前两个字节中的第一个(看起来是第二个),这个值和数据长度vl_len_是相关的,它的计算公式为:
正常的计算为:
Short:
len = NUMERIC_HDRSZ_SHORT + n * sizeof(NumericDigit);
Long:
len = NUMERIC_HDRSZ + n * sizeof(NumericDigit);
SET_VARSIZE(result, len);
#define SET_VARSIZE(PTR, len) SET_VARSIZE_4B(PTR, len)
#define SET_VARSIZE_4B(PTR,len) \
(((varattrib_4b *) (PTR))->va_4byte.va_header = (((uint32) (len)) << 2))
当数据库向物理文件进行写入的时候,数据将会发生改变,计算公式如下:
else if (VARLENA_ATT_IS_PACKABLE(att[i]) &&
VARATT_CAN_MAKE_SHORT(val))
{
/* convert to short varlena -- no alignment */
data_length = VARATT_CONVERTED_SHORT_SIZE(val);
SET_VARSIZE_SHORT(data, data_length);
memcpy(data + 1, VARDATA(val), data_length - 1);
}
注: 一个 numeric 类型的标度(scale)是小数部分的位数,精度(precision)是全部数据位的数目,也就是小数点两边的位数总和。因此数字 23.5141 的精度为 6 而标度为 4 。你可以认为整数的标度为零。
2、货币类型
数字类型中的money,也不能说它完全是数字类型,还能够支持‘$1000.00’,这种格式。在C\C++和Java中都没有对应的数字类型。他的范围是-92233720368547758.08 to +92233720368547758.07,int8是它的100倍,它在物理文件存储为:
postgres=# create table moneytable(m1 money);
CREATE TABLE
postgres=# insert into moneytable values ('$1')
;
INSERT 0 1
postgres=# select * from moneytable ;
m1
-------
$1.00
(1 row)
postgres=# checkpoint ;
CHECKPOINT
postgres=# select pg_relation_filepath('moneytable');
pg_relation_filepath
----------------------
base/12814/16467
(1 row)
postgres=# insert into moneytable values ('2')
;
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
postgres=# insert into moneytable values ('100')
;
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
[root@localhost 12814]# hexdump 16467
0000000 0000 0000 68e0 019e 0000 0000 0024 1fa0
0000010 2000 2004 0000 0000 9fe0 0040 9fc0 0040
0000020 9fa0 0040 0000 0000 0000 0000 0000 0000
0000030 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fa0 06eb 0000 0000 0000 0000 0000 0000 0000
0001fb0 0003 0001 0800 0018 2710 0000 0000 0000
0001fc0 06ea 0000 0000 0000 0000 0000 0000 0000
0001fd0 0002 0001 0800 0018 00c8 0000 0000 0000
0001fe0 06e9 0000 0000 0000 0000 0000 0000 0000
0001ff0 0001 0001 0900 0018 0064 0000 0000 0000
0002000
每个值都变为原来的100倍。 这也是为什么能表示两位小数的原因。
3、字符类型
字符类型有:char、char(n)、bpchar、bpchar(n)、character(n) 、varchar、varchar(n)、character varying(n)、text、name、cstring。
(1)一般字符类型
char、char(n) 、character(n)、bpchar、bpchar(n), 这些(这些类型都是bpchar的马甲)是同一种类型,使用的是同一个输入输出函数。
character(n) 、varchar、varchar(n)、character varying(n),这些(这些类型都是varchar的马甲)是同一种类型,使用的是相同的输入输出函数。
text是一种非SQL标准类型,它和上边除了char单字节外,用的都是相同的结构体:
typedef struct varlena bytea;
typedef struct varlena text;
typedef struct varlena BpChar; /* blank-padded char, ie SQL char(n) */
typedef struct varlena VarChar; /* var-length char, ie SQL varchar(n) */
struct varlena
{
char vl_len_[4]; /* Do not touch this field directly! */
char vl_dat[1];
};
这里还要说一个类型cstring,这个类型,在C中为char*。不能作为一个类型对字段进行定义。它和text的关系比较近。
在textin中是这么定义的:
Datum
textin(PG_FUNCTION_ARGS)
{
char *inputText = PG_GETARG_CSTRING(0);
PG_RETURN_TEXT_P(cstring_to_text(inputText));
}
text *
cstring_to_text(const char *s)
{
return cstring_to_text_with_len(s, strlen(s));
}
text *
cstring_to_text_with_len(const char *s, int len)
{
text *result = (text *) palloc(len + VARHDRSZ);
SET_VARSIZE(result, len + VARHDRSZ);
memcpy(VARDATA(result), s, len);
return result;
}
这里对text的处理只是在cstring基础上加了一个长度而已。其他的类型处理还是比较多的。
这里bpchar对数据的存储为当声明长度的时候,输入函数会对输入的数据进行判断,当长度大于声明的长度时,数据库会中断请求,报错。当小于时,函数会对数据进行填补空格,直到达到长度为止。
varchar的输入函数不会对数据进行补白,但是当声明长度时,超过时,同样会报错。
text不需要进行长度声明,它的存储几乎没有限制。
但是,这些存储确实是有限制的:
if (*tl > MaxAttrSize)
ereport(ERROR,
(errcode(ERRCODE_INVALID_PARAMETER_VALUE),
errmsg("length for type %s cannot exceed %d",
typename, MaxAttrSize)));
#define MaxAttrSize (10 * 1024 * 1024)
这里的限制大小是10GB,但是还有一个数据库本身对文件的限制:
Maximum size for a database? unlimited (32 TB databases exist)
Maximum size for a table? 32 TB
Maximum size for a row? 400 GB
Maximum size for a field? 1 GB
Maximum number of rows in a table? unlimited
Maximum number of columns in a table? 250-1600 depending on column types
Maximum number of indexes on a table? unlimited
所以目前对字段最大存储为1GB。
下面介绍一下在物理文件存储的格式:
建立表test:
postgres=# create table test(t1 char, t2 char(10), t3 varchar, t4 varchar(10), t5 bpchar, t6 text);
CREATE TABLE
postgres=# checkpoint ;
CHECKPOINT
postgres=# select pg_relation_filepath('test');
pg_relation_filepath
----------------------
base/12892/16490
(1 row)
插入数值:
postgres=# insert into test values ('a','a','a','a','a','a');
INSERT 0 1
postgres=# insert into test values ('b','b','b','b','b','b');
INSERT 0 1
postgres=# insert into test values ('a','aa','aa','aa','aa','aa');
INSERT 0 1
postgres=# insert into test values ('b','bb','bb','bb','bb','bb');
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
postgres=# select * from test;
t1 | t2 | t3 | t4 | t5 | t6
----+------------+----+----+----+----
a | a | a | a | a | a
b | b | b | b | b | b
a | aa | aa | aa | aa | aa
b | bb | bb | bb | bb | bb
(4 rows)
看一下物理文件:
[root@localhost 12892]# hexdump 16490
0000000 0000 0000 ab48 0189 0000 0000 0028 1f30
0000010 2000 2004 0000 0000 9fd0 005a 9fa0 005a
0000020 9f68 0062 9f30 0062 0000 0000 0000 0000
0000030 0000 0000 0000 0000 0000 0000 0000 0000
*
0001f30 06de 0000 0000 0000 0000 0000 0000 0000
0001f40 0004 0006 0802 0018 6205 6217 2062 2020
0001f50 2020 2020 0720 6262 6207 0762 6262 6207
0001f60 0062 0000 0000 0000 06dd 0000 0000 0000
0001f70 0000 0000 0000 0000 0003 0006 0802 0018
0001f80 6105 6117 2061 2020 2020 2020 0720 6161
0001f90 6107 0761 6161 6107 0061 0000 0000 0000
0001fa0 06dc 0000 0000 0000 0000 0000 0000 0000
0001fb0 0002 0006 0802 0018 6205 6217 2020 2020
0001fc0 2020 2020 0520 0562 0562 0562 0062 0000
0001fd0 06db 0000 0000 0000 0000 0000 0000 0000
0001fe0 0001 0006 0802 0018 6105 6117 2020 2020
0001ff0 2020 2020 0520 0561 0561 0561 0061 0000
0002000
字段类型
文本内容
物理文件内容
文本内容
物理文件内容
文本内容
物理文件内容
文本内容
物理文件内容
char
a
0x6105
b
0x6205
a
0x6105
b
0x626207
char(10)
a
0x6117 2020 2020 2020 2020 20
b
0x6217 2020 2020 2020 2020 20
aa
0x6117 2062 2020 2020 2020 20
bb
0x6217 2062 2020 2020 2020 20
varchar
a
0x6105
b
0x6205
aa
0x626207
bb
0x626207
varchar(10)
a
0x6105
b
0x6205
aa
0x626207
bb
0x626207
bpchar
a
0x6105
b
0x6205
aa
0x626207
bb
0x626207
text
a
0x6105
b
0x6205
aa
0x626207
bb
0x626207
这里的数据都受到SET_VARSIZE_SHORT的影响,表示长度的位置标为1字节,然后进行计算。
还要说明的是,当数据达到一定长度时,数据库会对数据进行压缩,主要是采用的TOAST机制。采用了一种LZ压缩算法,这是一种无损压缩算法,该算法在函数toast_compress_datum 中进行了具体实现。简单来说,LZ压缩算法被认为是基于字符串匹配的算法。LZ算法压缩算法的详情,可以参阅相关文献,这里就不多展开了。
(2)name
name:基础类型, 在C\C++中没有直接对应的类型,在源码中是这样定义的:
typedef struct nameData
{
char data[NAMEDATALEN];
} NameData;
typedef NameData *Name;
,在物理文件的存储如下:
postgres=# create table nametable(n1 name);
CREATE TABLE
postgres=# insert into nametable values ('liu');
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
postgres=# select pg_relation_filepath('nametable');
pg_relation_filepath
----------------------
base/12814/16461
(1 row)
[root@localhost 12814]# hexdump 16461
0000000 0000 0000 5528 019b 0000 0000 001c 1fa8
0000010 2000 2004 0000 0000 9fa8 00b0 0000 0000
0000020 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fa0 0000 0000 0000 0000 06de 0000 0000 0000
0001fb0 0000 0000 0000 0000 0001 0001 0800 0018
0001fc0 696c 0075 0000 0000 0000 0000 0000 0000
0001fd0 0000 0000 0000 0000 0000 0000 0000 0000
*
0002000
liu = 6c 69 75(16进制)。
4、日期时间类型
这里列举数据库支持的日期类型的大概信息:
名字
存储空间(单位:字节)
描述
最低值
最高值
Resolution
timestamp [ (p) ] [ without time zone ]
8
日期和时间
4713 BC
294276 AD
1 microsecond / 14 digits
timestamp [ (p) ] with time zone
8
日期和时间,带时区
4713 BC
294276 AD
1 microsecond / 14 digits
date
4
只用于日期
4713 BC
5874897 AD
1 day
time [ (p) ] [ without time zone ]
8
只用于一日内时间
00:00:00
24:00:00
1 microsecond / 14 digits
time [ (p) ] with time zone
12
只用于一日内时间,带时区
00:00:00+1459
24:00:00-1459
1 microsecond / 14 digits
interval [ fields ] [ (p) ]
12
时间间隔
-178000000 years
178000000 years
1 microsecond / 14 digits
(1)date
这里首先要说明的是date类型,它的定义其实很简单:
typedef int32 DateADT;
PostgreSQL按照儒略日(Julian day,JD),即公元前4713年1月1日作为起始,具体的原因这里就不去探究了。
它其实是一个整型数字,之所以能够表示 'yyyy-mm-dd'的原因主要是date类型的输入输出函数。它对输入的字符,即格式为'yyyy-mm-dd'或'yyyy:mm:dd'或'yyyy.mm.dd'的字符串进行读取,然后进行一系列的运算然后得到一个32bits的数字,存入到物理文件中。比如'2012-12-08'存入数据库中为4725。
postgres=# create table datetest(d1 date);
CREATE TABLE
postgres=# insert into datetest values ('2012-12-8');
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
postgres=# select pg_relation_filepath('datetest');
pg_relation_filepath
----------------------
base/12892/16499
(1 row)
[root@localhost 12892]# hexdump 16499
0000000 0000 0000 5380 018c 0000 0000 001c 1fe0
0000010 2000 2004 0000 0000 9fe0 0038 0000 0000
0000020 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fe0 06e4 0000 0000 0000 0000 0000 0000 0000
0001ff0 0001 0001 0800 0018 1275 0000 0000 0000
0002000
0x1275即4725。
(2)time和time with time zone
这里的time和time with time zone,表示时间的部分和date类似都是整型。为了增加时区,这里有新的结构体TimeTzADT,它们的源码为:
#ifdef HAVE_INT64_TIMESTAMP
typedef int64 TimeADT;
#else
typedef float8 TimeADT;
#endif
typedef struct
{
TimeADT time; /* all time units other than months and years */
int32 zone; /* numeric time zone, in seconds */
} TimeTzADT;
这里对事件的存储,是按照秒数来计算的,并且由于能够表示到小数点后6位,在此扩大了1000000倍。即,10:10:10.000001表示为数字36610000001。
还有对时区的存储也是表示为秒数,比如正八区(+8:00:00)为-28800,即0xFFFF8F80。
postgres=# create table timeandtimetz(t1 time, t2 timetz);
CREATE TABLE
postgres=# insert into timeandtimetz values ('10:10:10.000001', '10:10:10.000001 +8:00:00');
the y is 2014 , the m is 4 , the d is 21
the century is 68
the julian1 is 2454943
the julian2 is 2456595
the julian3 is 2456769
the time_in time is 36610000001
the timetz_in time is 36610000001
the timetz_in tz is -28800
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
postgres=# select pg_relation_filepath('timeandtimetz');
pg_relation_filepath
----------------------
base/12892/16508
(1 row)
[root@localhost 12892]# hexdump 16508
0000000 0000 0000 1308 018f 0000 0000 001c 1fd0
0000010 2000 2004 0000 0000 9fd0 0058 0000 0000
0000020 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fd0 06ec 0000 0000 0000 0000 0000 0000 0000
0001fe0 0001 0002 0800 0018 4481 8620 0008 0000
0001ff0 4481 8620 0008 0000 8f80 ffff 0000 0000
0002000
(3)timestamp 和 timestamp with time zone
这两个类型都包含了日期与时间,唯一不同的地方便是timestamp with time zone带有时区,它们的定义为:
typedef int64 Timestamp;
typedef int64 TimestampTz;
同样是经过一系列的转换,公式,将格式为'yyyy-mm-dd hh:mm:ss +/-hh:mm:ss',变为一个长整型。比如:'2013-1-1 20:00:00.000001',为410385600000001;'2013-1-1 20:00:00.000001 +8:00:00'为410356800000001。
postgres=# create table timesandtimestz(t1 timestamp(6), t2 timestamptz(6));
CREATE TABLE
postgres=# insert into timesandtimestz values ('2013-1-1 20:00:00.000001', '2013-1-1 20:00:00.000001 +8:00:00');
the y is 2013 , the m is 1 , the d is 1
the century is 68
the julian1 is 2454213
the julian2 is 2455865
the julian3 is 2456294
the y is 2013 , the m is 1 , the d is 1
the century is 68
the julian1 is 2454213
the julian2 is 2455865
the julian3 is 2456294
timestamp_in timestamp is 410385600000001
the y is 2013 , the m is 1 , the d is 1
the century is 68
the julian1 is 2454213
the julian2 is 2455865
the julian3 is 2456294
timestamptz_out timestamptz is 410356800000001
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
postgres=# select pg_relation_filepath('timesandtimestz');
pg_relation_filepath
----------------------
base/12892/16528
(1 row)
[root@localhost 12892]# hexdump 16528
0000000 0000 0000 0488 0196 0000 0000 001c 1fd8
0000010 2000 2004 0000 0000 9fd8 0050 0000 0000
0000020 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fd0 0000 0000 0000 0000 06fc 0000 0000 0000
0001fe0 0000 0000 0000 0000 0001 0002 0800 0018
0001ff0 b001 57e8 753e 0001 9001 a34b 7537 0001
0002000
(4)interval
interval,时间间隔类型,这个反而是所有时间类型当中最复杂的数据类型。
typedef struct
{
TimeOffset time; /* all time units other than days, months and
* years */
int32 day; /* days, after time for alignment */
int32 month; /* months and years, after time for alignment */
} Interval;
typedef int64 TimeOffset;
这里只是一个混合的结构体。
注:这里的时间类型格式还有其他形式,我这就不一一列举了,大体过程类似,都是将日期变为数字,进行存储。
5、对象标识符类型
oid:基础类型,占位4字节。下面是Oid的定义:
typedef unsigned int Oid;
完全按照ascii码表示的。
postgres=# create table oidt(o1 oid);
CREATE TABLE
postgres=# insert into oidt values (1);
INSERT 0 1
postgres=# insert into oidt values (2);
INSERT 0 1
postgres=# insert into oidt values (1);
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
postgres=# select pg_relation_filepath('oidt');
pg_relation_filepath
----------------------
base/12892/16522
(1 row)
[root@localhost 12892]# hexdump 16522
0000000 0000 0000 cf08 0193 0000 0000 0024 1fa0
0000010 2000 2004 0000 0000 9fe0 0038 9fc0 0038
0000020 9fa0 0038 0000 0000 0000 0000 0000 0000
0000030 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fa0 06f8 0000 0000 0000 0000 0000 0000 0000
0001fb0 0003 0001 0800 0018 0001 0000 0000 0000
0001fc0 06f7 0000 0000 0000 0000 0000 0000 0000
0001fd0 0002 0001 0800 0018 0002 0000 0000 0000
0001fe0 06f6 0000 0000 0000 0000 0000 0000 0000
0001ff0 0001 0001 0800 0018 0001 0000 0000 0000
0002000
6、布尔型
bool:基础类型,占位1字节。以0、1来表示false, true。
postgres=# create table boolt(b1 bool);
CREATE TABLE
postgres=# insert into boolt values ('t'),('f');
INSERT 0 2
postgres=# checkpoint ;
CHECKPOINT
postgres=# select pg_relation_filepath('boolt');
pg_relation_filepath
----------------------
base/12892/16525
(1 row)
[root@localhost 12892]# hexdump 16522
0000000 0000 0000 cf08 0193 0000 0000 0024 1fa0
0000010 2000 2004 0000 0000 9fe0 0038 9fc0 0038
0000020 9fa0 0038 0000 0000 0000 0000 0000 0000
0000030 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fa0 06f8 0000 0000 0000 0000 0000 0000 0000
0001fb0 0003 0001 0800 0018 0001 0000 0000 0000
0001fc0 06f7 0000 0000 0000 0000 0000 0000 0000
0001fd0 0002 0001 0800 0018 0002 0000 0000 0000
0001fe0 06f6 0000 0000 0000 0000 0000 0000 0000
0001ff0 0001 0001 0800 0018 0001 0000 0000 0000
0002000
7、二进制类型
bytea,二进制类型,和text等用的相同的结构体,同样受到数据库的限制。
typedef struct varlena bytea;
postgres=# create table byteat(b1 bytea);
CREATE TABLE
postgres=# insert into byteat values ('ab');
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
postgres=# select pg_relation_filepath('byteat');
pg_relation_filepath
----------------------
base/12892/16516
(1 row)
postgres=# insert into byteat values ('abcde');
the data_length is 6
INSERT 0 1
postgres=# checkpoint ;
CHECKPOINT
[root@localhost 12892]# hexdump 16516
0000000 0000 0000 b558 0192 0000 0000 0020 1fc0
0000010 2000 2004 0000 0000 9fe0 0036 9fc0 003c
0000020 0000 0000 0000 0000 0000 0000 0000 0000
*
0001fc0 06f4 0000 0000 0000 0000 0000 0000 0000
0001fd0 0002 0001 0802 0018 610d 6362 6564 0000
0001fe0 06f3 0000 0000 0000 0000 0000 0000 0000
0001ff0 0001 0001 0802 0018 6107 0062 0000 0000
0002000
三、总结
在这里只是介绍了比较简单的几种数据类型,其中的用法上写的都比较简单,但是基本上都是如此。若有什么不对的地方请及时和我交流,希望和大家共同学习。












