
PostgreSQL数据库中有许多内部函数,这次对系统表pg_proc以及函数代码进行分析记录(这里是针对9.3进行介绍的)。
一、数据库系统表pg_proc
数据库中所有内部函数信息都存储在系统表pg_proc.
内部函数都是在编译之前写好并存储在pg_proc.h文件中。
下面来看一下pg_proc的表结构,首先是看源码中的结构体:
CATALOG(pg_proc,1255) BKI_BOOTSTRAP BKI_ROWTYPE_OID(81) BKI_SCHEMA_MACRO
37 {
38 NameData proname; /* procedure name */
39 Oid pronamespace; /* OID of namespace containing this proc */
40 Oid proowner; /* procedure owner */
41 Oid prolang; /* OID of pg_language entry */
42 float4 procost; /* estimated execution cost */
43 float4 prorows; /* estimated # of rows out (if proretset) */
44 Oid provariadic; /* element type of variadic array, or 0 */
45 regproc protransform; /* transforms calls to it during planning */
46 bool proisagg; /* is it an aggregate? */
47 bool proiswindow; /* is it a window function? */
48 bool prosecdef; /* security definer */
49 bool proleakproof; /* is it a leak-proof function? */
50 bool proisstrict; /* strict with respect to NULLs? */
51 bool proretset; /* returns a set? */
52 char provolatile; /* see PROVOLATILE_ categories below */
53 int16 pronargs; /* number of arguments */
54 int16 pronargdefaults; /* number of arguments with defaults */
55 Oid prorettype; /* OID of result type */
56
57 /*
58 * variable-length fields start here, but we allow direct access to
59 * proargtypes
60 */
61 oidvector proargtypes; /* parameter types (excludes OUT params) */
62
63 #ifdef CATALOG_VARLEN
64 Oid proallargtypes[1]; /* all param types (NULL if IN only) */
65 char proargmodes[1]; /* parameter modes (NULL if IN only) */
66 text proargnames[1]; /* parameter names (NULL if no names) */
67 pg_node_tree proargdefaults;/* list of expression trees for argument
68 * defaults (NULL if none) */
69 text prosrc; /* procedure source text */
70 text probin; /* secondary procedure info (can be NULL) */
71 text proconfig[1]; /* procedure-local GUC settings */
72 aclitem proacl[1]; /* access permissions */
73 #endif
74 } FormData_pg_proc;
下面来简单介绍pg_type的各个字段含义:
proname、pronamespace、proowner分别是函数名(sql调用的名字)、存在的模式(oid)、所属用户(oid),这里就不多说了。
prolang:实现语言或该函数的调用接口,目前在系统中定义的为(internal,12),(c、13),(sql,14),数据库中主要用的是internal和sql。
procost:估计执行成本,这里和执行计划相关联。
prorows:结果行估计数。
provariadic:可变数组参数类型,这是9.1之后加入的,这是能够然函数定义不再受限于参数个数。这个类型可以参照一下函数concat和concat_ws这两个函数。这个地方在这里对concat说明,在函数concat这个参数是这样写的2276,这 个函数是拼接字符串,而2276正是any,在这里填写后,表示这个函数可以接收多个any类型的参数,而不用像以前那样每多一个参数就得写一个定义。
protransform:可以替代被调用的简化函数。可以参看varbit函数。这里写的是varbit_transform,而通过查看代码,可以知道varbit_transform只有一个参数,也就是说当只有一个参数的时候调用varbit实际上执行的是varbit_transform。
proisagg:这是不是一个聚集函数。
proiswindow:是否为窗口函数。窗口函数(RANK,SUM等) 可以对一组相关的记录进行操作。
prosecdef:函数是一个安全定义器(也就是一个"setuid"函数)。
proleakproof:有无其他影响。
proisstrict:遇到NULL值是否直接返回NULL,这里要说明的是,数据库中有一个数组专门来存储这个值,当为true时,数据库对参数为NULL的qi。
proretset:函数返回一个集合(也就是说,指定数据类型的多个数值)。
provolatile:告诉该函数的结果是否只倚赖于它的输入参数,或者还会被外接因素影响。对于"不可变的"(immutable)函数它是 i ,这样的函数对于相同的输入总是产生相同的结果。对于"稳定的"(stable)函数它是 s ,(对于固定输入)其结果在一次扫描里不变。对于"易变"(volatile)函数它是 v ,其结果可能在任何时候变化。v 也用于那些有副作用的函数,因此调用它们无法得到优化。
pronargs:参数个数。
pronargdefaults:默认参数的个数。
prorettype:返回参数类型的oid。
proargtypes:一个存放函数参数的数据类型的数组。
proargmodes:一个保存函数参数模式的数组,编码如下:i 表示 IN 参数, o 表示 OUT 参数, b 表示 INOUT 参数。如果所有参数都是 IN 参数,那么这个字段为空。请注意,下标对应的是 proallargtypes 的位置,而不是 proargtypes。
proargnames:一个保存函数参数的名字的数组。没有名字的参数在数组里设置为空字符串。如果没有一个参数有名字,这个字段将是空。请注意,此数组的下标对应 proallargtypes 而不是 proargtypes。
proargdefaults:表达式树(以nodeToString()形式表示)的默认值。这是pronargdefaults元素的列表,对应的最后N个输入参数(即最后N proargtypes位置)。如果没有的参数有默认值,这个领域将是空的。
prosrc:这个字段告诉函数处理器如何调用该函数。它实际上对于解释语言来说就是函数的源程序,或者一个链接符号,一个文件名,或者是任何其它的东西,具体取决于语言/调用习惯的实现。
probin:关于如何调用该函数的附加信息。同样,其含义也是和语言相关的。
proconfig:在运行时配置变量函数的局部设置。
proacl:访问权限。
以上就是对系统表pg_proc的介绍,下面对如何阅读和编写内部函数作一下介绍。
二、函数基础
1、函数的使用:
在数据库中函数的使用是非常简单的。
用法为:
select FunctionName(args);
select FunctionName(columnname) from tablename;
……
(具体可以去查找文档,这里不做一一介绍了)
2、使用的函数名
这里的函数名(Functionname)就是系统表pg_proc中的proname了。
3、函数的定义
一般能看到的定义有两种。
第一种:
CREATE OR REPLACE FUNCTION date_part(text, time with time zone)
RETURNS double precision AS
'timetz_part'
LANGUAGE internal IMMUTABLE STRICT
COST 1;
data_part就是我们调用的函数的名称。
(text, time with time zone)即我们输入参数的类型。
double precision是我们返回的数据类型。
'timetz_part'是我们源码中命名的函数名,调用date_part其实是调用函数timetz_part。
internal是我们规定的函数语言。
1是我们估计的时间成本。
第二种:
CREATE OR REPLACE FUNCTION date_part(text, abstime)
RETURNS double precision AS
'select pg_catalog.date_part($1, cast($2 as timestamp with time zone))'
LANGUAGE sql STABLE STRICT
COST 1;
ALTER FUNCTION date_part(text, abstime) OWNER TO highgo;
COMMENT ON FUNCTION date_part(text, abstime) IS 'extract field from abstime';
这里基本和第一种相同。不同之处在于:
这里没有写源码中命名的函数,而是用一条SQL语句替代了,在这里执行的时候又在执行的上边的date_part,然后再去调用的 timetz_part。
这里的函数语言是SQL。
第三种:
CREATE OR REPLACE FUNCTION concat(VARIADIC "any")
RETURNS text AS
'text_concat'
LANGUAGE internal STABLE
COST 1;
ALTER FUNCTION concat("any")
OWNER TO postgres;
COMMENT ON FUNCTION concat("any") IS 'concatenate values';
这里不同的就是在参数上添加了VARIADIC,这是说明这个类型是一个可变数组。其他的都类似,就不说明了。
第四种:
CREATE OR REPLACE FUNCTION varbit(bit varying, integer, boolean)
RETURNS bit varying AS
'varbit'
LANGUAGE internal IMMUTABLE STRICT
COST 1;
这里是看起来和第一种是一样的,这里拿过来主要是说明一下,pg_proc中的 protransform字段,应该不能通过SQL定义的方式填写。这个函数在proc中protransform的定义有varbit_transform。这段定义是admin反向出来的。
4、定义自己的函数(主要指的用SQL定义)
这个可以去看文档。
5、函数的源码
如果要进行学习函数的源码学习,那么必须首先要阅读src/include/fmgr.h,这里对函数的制定了一揽子的宏定义。
首先呢,要说明的是,能够直接用SQL语句调用的函数(prosrc),他的参数必须是PG_FUNCTION_ARGS。
下面是对PG_FUNCTION_ARGS的定义:
#define PG_FUNCTION_ARGS FunctionCallInfo fcinfo
typedef struct FunctionCallInfoData *FunctionCallInfo;
typedef Datum (*PGFunction) (FunctionCallInfo fcinfo);
typedef struct Node *fmNodePtr; typedef uintptr_t Datum;
typedef struct Node
{
NodeTag type; //NodeTag 这是一个枚举类型
} Node;
typedef struct FmgrInfo
{
PGFunction fn_addr; /* pointer to function or handler to be called */
Oid fn_oid; /* OID of function (NOT of handler, if any) */
short fn_nargs; /* number of input args (0..FUNC_MAX_ARGS) */
bool fn_strict; /* function is "strict" (NULL in => NULL out) */
bool fn_retset; /* function returns a set */
unsigned char fn_stats; /* collect stats if track_functions > this */
void *fn_extra; /* extra space for use by handler */
MemoryContext fn_mcxt; /* memory context to store fn_extra in */
fmNodePtr fn_expr; /* expression parse tree for call, or NULL */
} FmgrInfo;
typedef struct FunctionCallInfoData
{
FmgrInfo *flinfo; /* ptr to lookup info used for this call */
fmNodePtr context; /* pass info about context of call */
fmNodePtr resultinfo; /* pass or return extra info about result */
Oid fncollation; /* collation for function to use */
bool isnull; /* function must set true if result is NULL */
short nargs; /* # arguments actually passed */
Datum arg[FUNC_MAX_ARGS]; /* Arguments passed to function */
bool argnull[FUNC_MAX_ARGS]; /* T if arg[i] is actually NULL */
} FunctionCallInfoData;
上面是很复杂的一个结构体,这就是调用函数生成的结构体。
三、函数在数据库中的历程
现在我以一个函数使用的SQL语句去解读一下函数。
1、执行函数
首先,在命令行下输入一条SQL语句,在此主要介绍函数,主要对函数运行进行介绍(其他的内存上下文、执行计划之类的,这里就不做介绍了,在下才疏学浅,有待进一步的学习后会做相应介绍),所以直接输入参数作为介绍,为了更好地说明,这里用concat作为函数例子进行介绍。进入客户端,调用函数。
postgres=# select concat('su','re');
2、进入到服务端
数据库客户端会根据前后端协议将用户查询将信息发送到服务端,进入函数PostgresMain,然后进入exec_simple_query,exec_simple_query函数主要分为两部分,第一部分是查询分析,第二部分是查询执行,下面以下图进行说明查询分析:
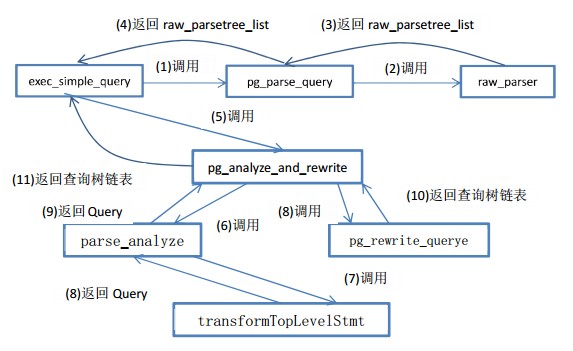
(1)首先exec_simple_query函数会将得到的SQL语句通过调用pg_parse_query进入词法和语法分析的主题处理过程,然后函数pg_parse_query调用词法和语法分析的入口函数raw_parse生成分析树。 raw_parse函数通过分词与语法引擎进行对SQL语句的识别,其中执行函数时会调用makeFuncCall,初始化FuncCall。这是执行函数所必须调用的。 raw_parse函数通过分词与语法引擎进行对SQL语句的识别,其中执行函数时会调用makeFuncCall,初始化FuncCall。这是执行函数所必须调用的。
typedef struct FuncCall
{
NodeTag type;
List *funcname; /* qualified name of function */
List *args; /* the arguments (list of exprs) */
List *agg_order; /* ORDER BY (list of SortBy) */
Node *agg_filter; /* FILTER clause, if any */
bool agg_star; /* argument was really '*' */
bool agg_distinct; /* arguments were labeled DISTINCT */
bool func_variadic; /* last argument was labeled VARIADIC */
struct WindowDef *over; /* OVER clause, if any */
int location; /* token location, or -1 if unknown */
} FuncCall;
(2)函数pg_parse_query返回分析树给外部函数。
(3)exec_simple_query接着调用函数pg_analyze_and_rewrite进行语义分析和查询重写。首先调用parse_analyze进行语义分析并生成查询树,其中parse_analyze会调用transformTopLevelStmt等(见下图)
进行一系列的转化。 之 后 会 将 查 询 树 传 递 给 函 数pg_rewrite_querye对查询进行重写,对执行计划进行优化。

上面这一系列函数都是对函数pg_parse_query返回的分析树,进行一系列的转化,通过判定和选择对应函数,最终通过对系统表pg_proc进行查找、判定最优函数,并执行函数ParseFuncOrColumn来确认并找到函数,添加到执行计划中。否则返回错误,告知用户并无此函数(这里吐槽一下pg,函数的定义的非常死板,不够灵活,常常发生有对应函数,却找不到的情况,问题在于,数据库查找用户执行的函数时,会对参数类型进行确认,然后去寻找,当然这里主要是数据类型无法隐式转化的原因,当参数类型无法转化时,数据库就会报错,无法找到函数)。这里的transformTopLevelStmt、transformStmt、transformSelectStmt、transformTargetList、transformTargetList、transformExpr、transformExprRecurse、transformFuncCall都是进行转化的,而ParseFuncOrColumn函数的功能是详细寻找函数,而make_const是对参数进行处理的。
以下图来详细说明ParseFuncOrColumn的工作原理:
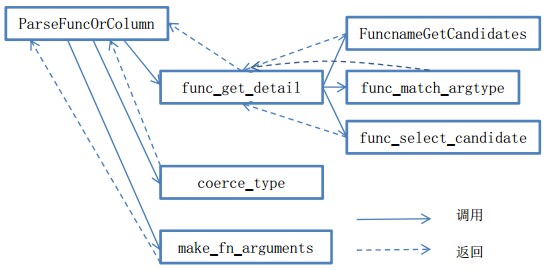
(1)ParseFuncOrColumn调用函数func_get_detail来确认函数是否存在,存在则返回函数oid号,否则返回错误。
(a)func_get_detail函数调用FuncnameGetCandidates通过函数名、参数个数在系统表pg_proc中得到候选函数列表。没有则返回错误。
(b)func_get_detail函数调用func_match_argtypes对参数类型进行匹配,其中会调用can_coerce_type来判定当前参数类型能否进行隐式转换。进而缩小范围。
(c)func_get_detail函数调用func_select_candidate最终确认函数参数类型(可转换的),返回类型、函数oid。
(2)ParseFuncOrColumn会调用coerce_type对参数表达式进行转换。
(3)ParseFuncOrColumn调用函数make_fn_arguments对参数进行转化,变为函数能够使用的参数。
上述过程是创建并优化执行计划,这里仅仅是计划,真正执行的地方是查询执行。下面以图简单说明一下:

这里有一个很重要的结构体Portal:
typedef struct PortalData *Portal;
typedef struct PortalData
{
/* Bookkeeping data */
const char *name; /* portal's name */
const char *prepStmtName; /* source prepared statement (NULL if none) */
MemoryContext heap; /* subsidiary memory for portal */
ResourceOwner resowner; /* resources owned by portal */
void (*cleanup) (Portal portal); /* cleanup hook */
SubTransactionId createSubid; /* the ID of the creating subxact */
/*
* if createSubid is InvalidSubTransactionId, the portal is held over from
* a previous transaction
*/
/* The query or queries the portal will execute */
const char *sourceText; /* text of query (as of 8.4, never NULL) */
const char *commandTag; /* command tag for original query */
List *stmts; /* PlannedStmts and/or utility statements */
CachedPlan *cplan; /* CachedPlan, if stmts are from one */
ParamListInfo portalParams; /* params to pass to query */
/* Features/options */
PortalStrategy strategy; /* see above */
int cursorOptions; /* DECLARE CURSOR option bits */
/* Status data */
PortalStatus status; /* see above */
bool portalPinned; /* a pinned portal can't be dropped */
/* If not NULL, Executor is active; call ExecutorEnd eventually: */
QueryDesc *queryDesc; /* info needed for executor invocation */
/* If portal returns tuples, this is their tupdesc: */
TupleDesc tupDesc; /* descriptor for result tuples */
/* and these are the format codes to use for the columns: */
int16 *formats; /* a format code for each column */
/*
* Where we store tuples for a held cursor or a PORTAL_ONE_RETURNING or
* PORTAL_UTIL_SELECT query. (A cursor held past the end of its
* transaction no longer has any active executor state.)
*/
Tuplestorestate *holdStore; /* store for holdable cursors */
MemoryContext holdContext; /* memory containing holdStore */
/*
* atStart, atEnd and portalPos indicate the current cursor position.
* portalPos is zero before the first row, N after fetching N'th row of
* query. After we run off the end, portalPos = # of rows in query, and
* atEnd is true. If portalPos overflows, set posOverflow (this causes us
* to stop relying on its value for navigation). Note that atStart
* implies portalPos == 0, but not the reverse (portalPos could have
* overflowed).
*/
bool atStart;
bool atEnd;
bool posOverflow;
long portalPos;
/* Presentation data, primarily used by the pg_cursors system view */
TimestampTz creation_time; /* time at which this portal was defined */
bool visible; /* include this portal in pg_cursors? */
} PortalData;
这是查询执行中所必需的Portal ,存储的信息为查询计划树链表以及最后选中的执行策略等信息。上图中大部分都是在进行策略的选择。
调用CreatePortal创建空白的Portal,调用PortalStart进行初始化,调用函数PortalRun执行Portal,清理Portal。
其中PortalRun是真正执行用户需要的函数。他的大体步骤以下图为例:
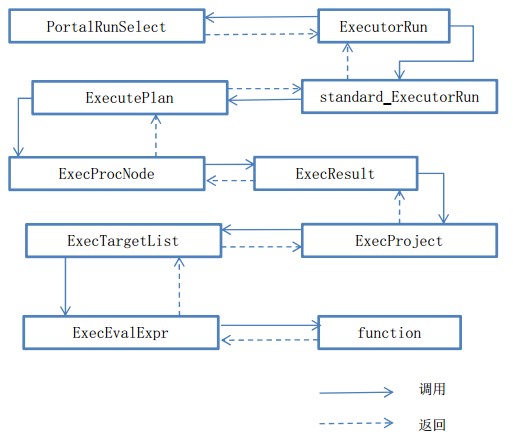
这样,一个简单函数的调用结束了。最主要的两步为查询分析与查询执行。










