


转载本文需注明出处:微信公众号EAWorld,违者必究。
前言:
近些年来,DevOps的理念已经逐渐深入人心,随着容器、Docker、Kubernetes、OpenShift等概念不断走进我们的视野,越来越多的企业开始在生产中运用这些技术。在这些技术和理念带来的便利性不断为软件开发赋能的同时,有人可能会产生这样的疑问,Kubernetes和OpenShift这样的技术如何加入DevOps的工具链大家族,进一步提高生产效率和生产质量。
今天,让我来带大家一起探究一下DevOps如何与OpenShift结合达成1+1>2的效果。
容器是什么?
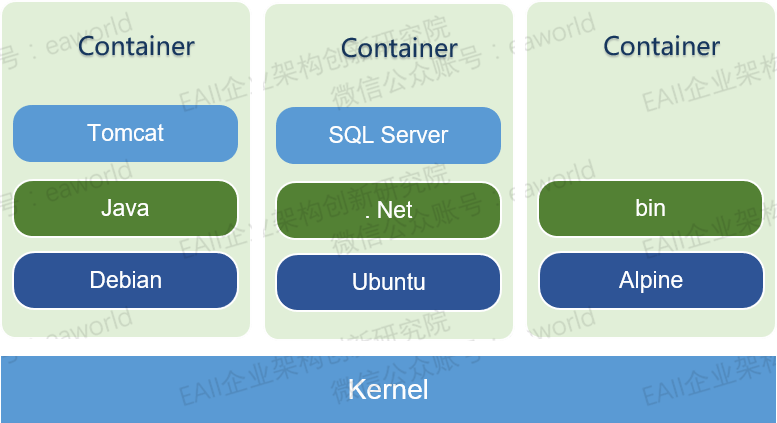
容器是一种内核轻量级的操作系统层虚拟化技术。
容器的本质,一句话解释,就是一组受到资源限制,彼此间相互隔离的进程
Docker属于容器服务的一种,是一个开源的应用容器引擎。
容器具有哪些特点?
1. 极其轻量 :只打包了必要的Bin/Lib;
2. 秒级部署 :根据镜像的不同,容器的部署大概在毫秒与秒之间(比虚拟机强很多);
3. 易于移植 :一次构建,随处部署;
4. 弹性伸缩 :Kubernetes、Swam、Mesos这类开源、方便、易用的容器管理平台有着非常强大的弹性管理能力。
使用容器化技术能带来哪些好处?
在传统的开发场景下,开发测试团队和生产运维团队使用的是不同的基础设施,通常都会使用相同介质和不同的配置文件来区分环境,但是在环境的转换过程中,还是会出现一些由于团队协作或者环境依赖造成的问题。而容器化带来的最大便利就在于,他能够简化团队间的协作关系,容器镜像的构建打包的也不仅是应用,而是应用运行所在的全部运行环境,这种方式屏蔽了由于环境不同带来的问题。这样以来,无论是在什么环境下运行,这个应用所需要的环境、依赖都是高度一致的。
当容器的数量达到一定量级的时候,如何对容器进行高效的维护和管理呢?
答案是使用Kubernetes容器管理工具。
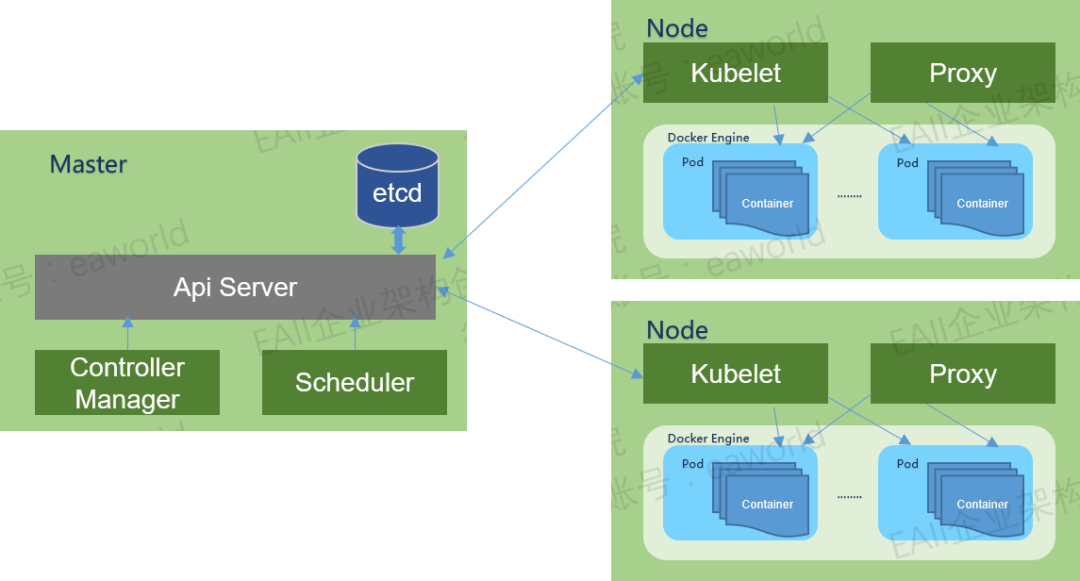
什么是Kubernetes?
Kubernetes,是一个容器集群管理系统,可以实现容器集群的自动化部署、自动扩缩容、维护等功能,保证应用的高可用。
通过Kubernetes你可以:
1. 快速部署应用
2. 快速扩展应用,对应用进行扩容
3. 无缝对接新的应用功能
4. 节省资源,优化硬件资源的使用
Kubernetes具有哪些特点?
1. 可移植 : 支持公有云,私有云,混合云,多重云
2. 可扩展 : 模块化, 插件化, 可挂载, 可组合
3. 自动化 : 自动部署,自动重启,自动复制,自动伸缩/扩展
OpenShift是什么?
OpenShift是一个基于主流的容器技术Docker和Kubernetes构建的云平台,OpenShift底层以docker作为容器引擎驱动,以Kubernetes作为容器编排引擎组件,同时,OpenShift提供了开发语言、中间件、自动化流程工具及界面等元素,提供了一套完整的基于容器的应用云平台。
你可以简单的把OpenShift理解为Kubernetes PRO PLUS所以我们如果可以对接了OpenShift,那么也就相当于对接了Kubernetes。
为什么需要通过
DevOps来管理OpenShift?
为了确保业务应用在测试环境预发环境生产环境表现的一致性,我们使用了一系列容器相关的工具,这些工具能够帮助我们减少上线时因为介质、环境等不一致带来的问题,可是随着这些工具的深入使用,我们也会希望能够进一步抽象,不论我们的业务应用是部署在云主机还是容器云上,我们都希望能使用同一种方式来进行部署,我们也希望能够进一步简化操作,真正实现一键部署,切实地提高生产效率和质量。
DevOps的核心价值就在于通过打通各个工具链来提高企业生产的效率以及质量,告别终日面对黑白相间的Linux界面,友好的可视化界面能几何倍数提升运维的操作体验;不再因为部署环境发愁,一套DevOps就可以轻松管理多个环境;也不用被繁多的配置文件打乱思绪,我们可以通过大量的模板进行足够灵活的自定义配置。
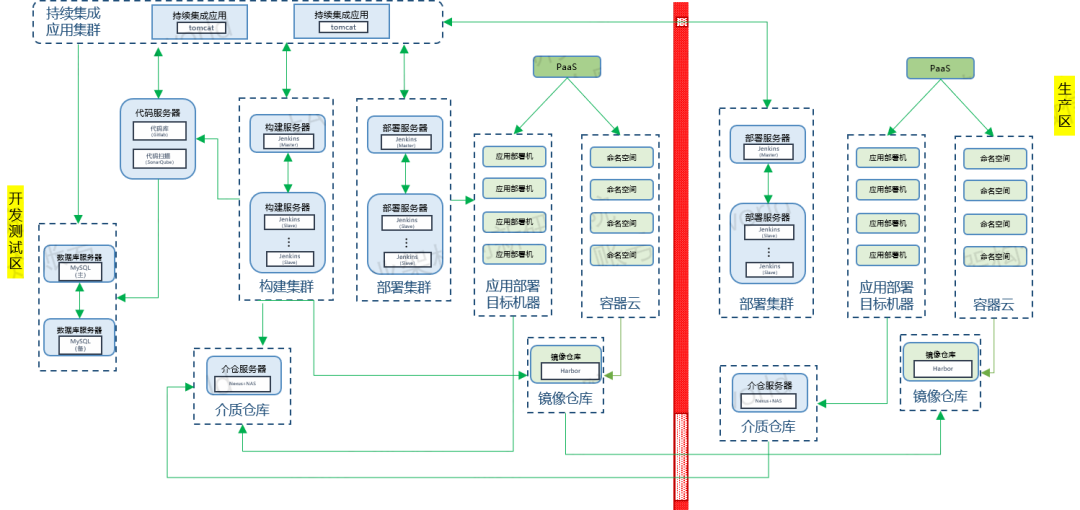
以上是DevOps实施时的系统架构部署图。通常我们的部署都会分为开发环境、测试环境、生产环境这样不同的部署区,这些不同部署区之间的资源都是相互隔离的,保证不会对彼此产生影响。
在我们的开发测试流水线中,首先,由开发人员提交代码,触发持续集成流水线,构建服务器会自动拉取代码、对代码进行质量扫描,然后编译产物,最后将产物上传到介质仓库。我们支持配置介质仓库的同步策略,如不同环境的介质仓库定时同步、定时推送或者拉取,这样能够保证不同环境部署介质的一致性。 对于镜像来说,镜像也是部署介质的一种类型,镜像在完成构建和上传之后,也支持同步到不同环境的镜像仓库。 当触发持续部署流程时,部署服务器将介质部署到应用部署机或者容器云环境 , 对于应用部署机来说,介质从介质仓库服务器获取,对于容器云来说,镜像来源于镜像仓库。
我们是如何进行设计和落地的?
我们进行持续集成与持续部署的总体设计思路是,在DevOps中进行设计,然后通过Jenkins执行,最后通过OpenShift进行部署。我们在DevOps中定义多个原子任务串成流水线,之后进行构建定义或部署架构的设计,生成Jenkins的Pipeline Job的配置文件;然后Jenkins根据这个动态生成的配置文件创建并执行Pipeline Job;在部署完成后,DevOps通过调用Jenkins的Rest API跟踪执行进度和结果,通过OpenShift的Rest API获取应用容器的实例状态以及对应用容器进行运维操作。
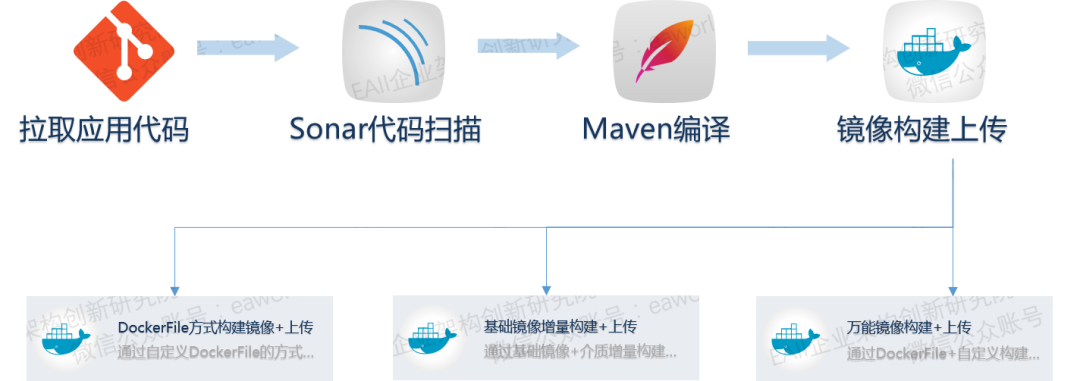
镜像构建和上传
在部署之前,我们需要准备好介质,DevOps提供了一系列任务能够帮助我们轻松完成镜像的构建和上传,对于Kubernetes和OpenShift来说,部署介质就是镜像,这意味着,无论是部署到Kubernetes还是部署到OpenShift,只要我们打通到镜像仓库的网络,就可以兼容不同类型的容器云。
DevOps提供了多种镜像构建任务,支持通过指定一个基础镜像进行构建,也支持通过DockerFile进行构建,使用方式上非常灵活。通常来说,企业都会在内网环境搭建私有镜像仓库,在构建之后,我们需要把镜像push到已授信的镜像仓库。
组件类型拓展
我们添加了OpenShift类型的组件进行扩展,组件是部署的最小单元,其中包含了部署介质的各种信息,向前可以对生产介质的代码、分支、构建流水号进行追溯,向后可以对部署之后的应用以及应用状态变更如升级、回滚等操作进行跟踪。组件还包含了它在各个环境中的部署信息以及实例的运行情况如访问地址、运行状态等。
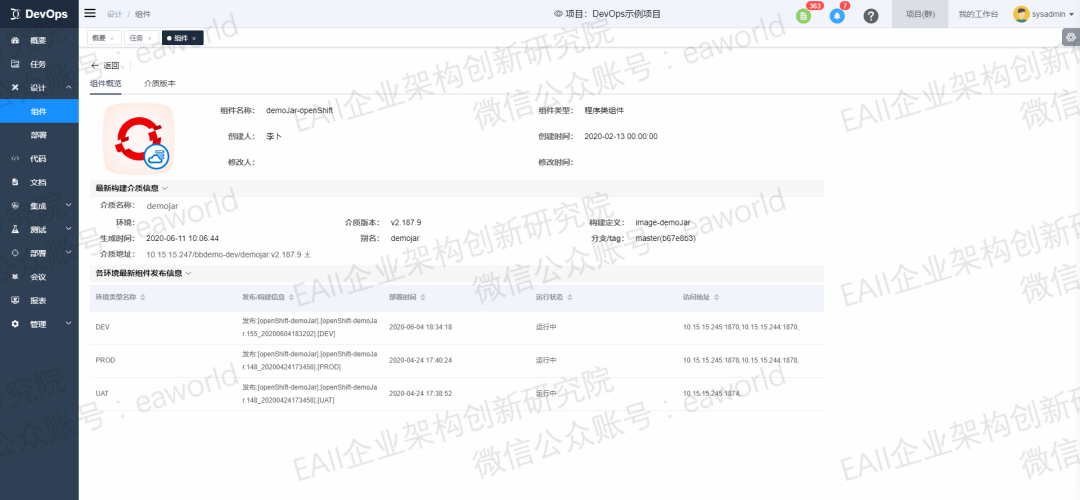
资源类型拓展
我们添加了OpenShift类型的部署资源,资源拥有和介质完全独立互斥的属性,他描述了我们的介质(镜像)需要部署到哪个环境(容器云),部署到该容器云的哪一个命名空间中去,资源还描述了访问容器云所需要的其他信息如用户名密码或者APIToken以及容器云服务器的证书等信息。
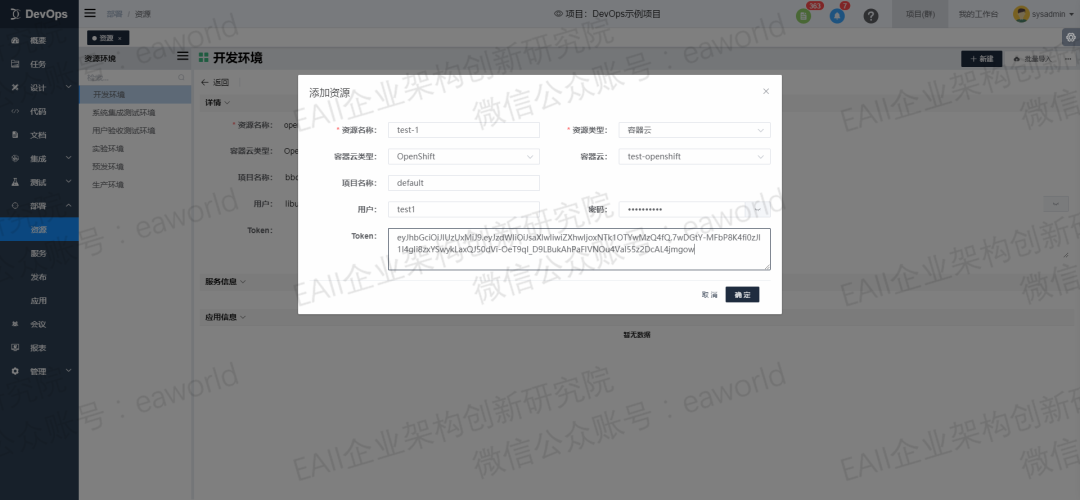
部署原子任务拓展
DevOps具有强大的拓展能力,可以通过在数据库添加OpenShift部署任务的原子任务以及原子任务的属性参数进行拓展,例如:镜像的名称及镜像版本、部署使用的yaml或者yaml模板、部署用到的OpenShift资源,拉取镜像所用的镜像仓库等。
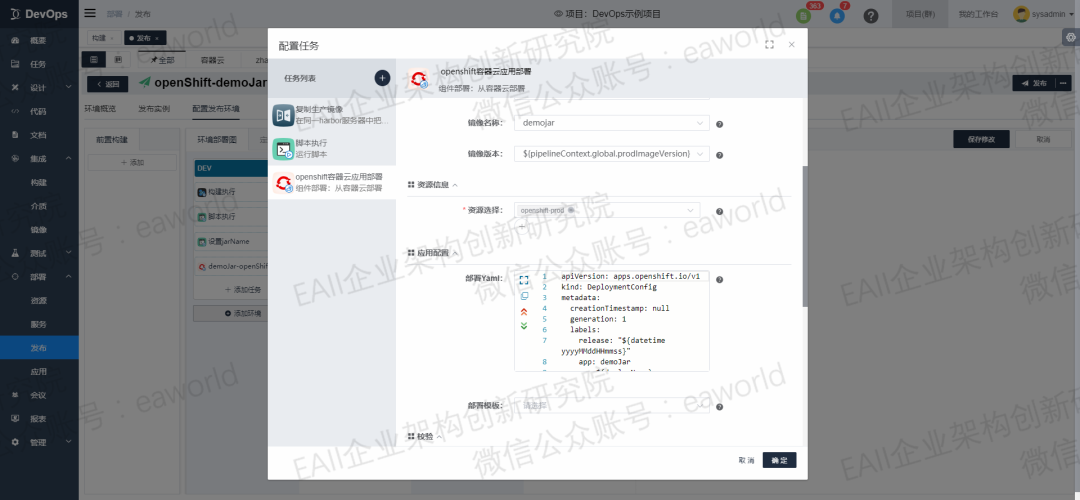
这种方式有什么好处?
DevOps流水线设计的优势显而易见,CICD可以减少大量开发、测试、部署过程中的重复性工作,同时减少了手工的错误,大大提高了功能验证的频率。开发测试人员能够更早的获取变更,更早的进入测试,更早的发现问题,缩短了开发周期,极大的降低了解决问题的成本。在这个过程中,开发人员能够更早发现错误,并且减少解决错误所需的工作量,如果在部署环节发现错误可以回退到上一版本,保证交付物始终有一个可用的版本。
OpenShift Client
插件介绍以及排坑
我们用到了Jenkins Plugin中的OpenShift Client用于对OpenShift进行操作,这个插件拥有简洁、全面、可读性强的特点,并且提供了流畅的Jenkins Pipeline语法与OpenShift服务器进行交互,接下来我将对使用这个插件遇到的一些问题进行排坑。
该插件利用了OpenShift命令行工具(oc),该脚本必须在执行脚本的节点上可用,所以要求我们的Jenkins Master和Node节点安装oc命令,并且配置环境变量,同时还要保证打通到我们要管理的OpenShift的网络。
插件要求我们配置OpenShift的证书和ApiToken,证书我们可以直接从OpenShift服务器的安装目录/etc/origin/master/ca.crt拷贝。关于ApiToken的获取,我总结了以下两种方式:
1. 通过命令行
oc login -u -p
2. 通过命令行
curl -u admin:abc123 -kv -H "X-CSRF-Token: xxx" 'https://master.example.com:8443/oauth/authorize?client_id=OpenShift-challenging-client&response_type=token'
从返回的Response Header中获取。
从插件的使用上来说,他的Groovy语法糖非常契合OpenShift命令行的使用习惯,学习难度很低,因此熟悉kubectl或者oc命令的运维人员能够在很短时间内掌握。
例如以下三行命令:
oc create -f templateYaml
可以简单写成

应用容器的部署、升级、停止、扩容操作都可以用简明清晰的语法操作,以下是代码示例:

镜像部署到OpenShift之后, DevOps会自动创建好对应的应用,同时,通过Jenkins回调DevOps返回的数据,我们可以获取应用的一些基础信息。可是对于应用的监控和运维来说,这些信息不够有效,于是我们封装了OpenShift提供的RestApi,提供了OpenShift应用运维常用的几个接口。
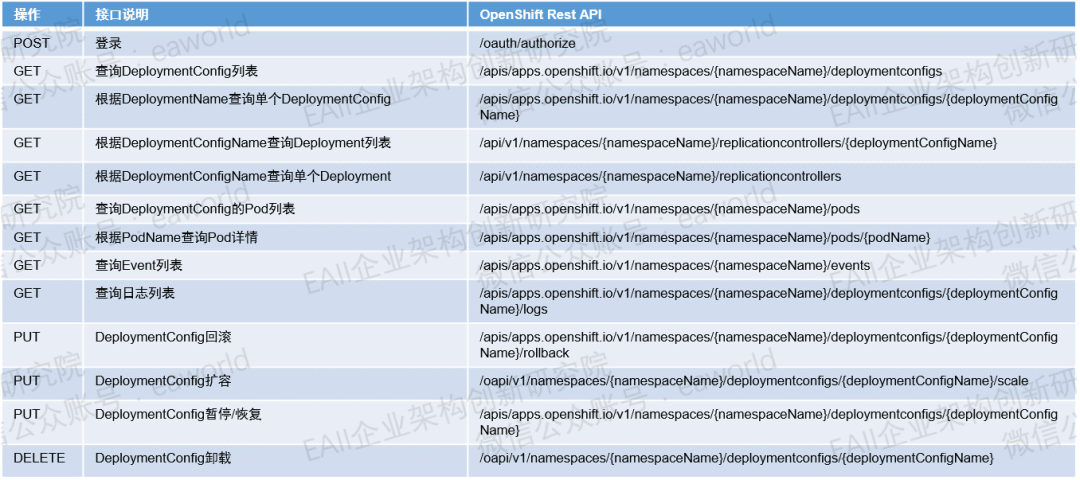
当我们通过DevOps将构建好的镜像成功部署到OpenShift之后,只做到这一步是远远不够的,从某种方面来说,我们还没有完全解放运维人员的压力,对于应用部署之后漫长的运维周期,运维人员为了解决应用问题仍然需要面对黑白相间的linux控制台以及敲入各种复杂的命令。
DevOps在OpenShift的
应用运维方面做了哪些工作?
镜像部署到OpenShift之后, DevOps会自动创建好对应的应用,同时,通过Jenkins回调DevOps返回的数据,我们可以获取应用的一些基础信息。可是对于应用的监控和运维来说,这些信息不够有效,于是我们封装了OpenShift提供的RestApi,提供了OpenShift应用运维常用的几个接口,通过这些接口我们可以获取应用容器的pods,events,logs,应用访问地址以及端口等详细信息。

那么在软件开发前期,开发测试人员能够通过DevOps快速构建出应用进行部署并且能很方便的获取到访问地址进行功能验证,这样可以大幅缩短功能验证的周期,提高生产效率。
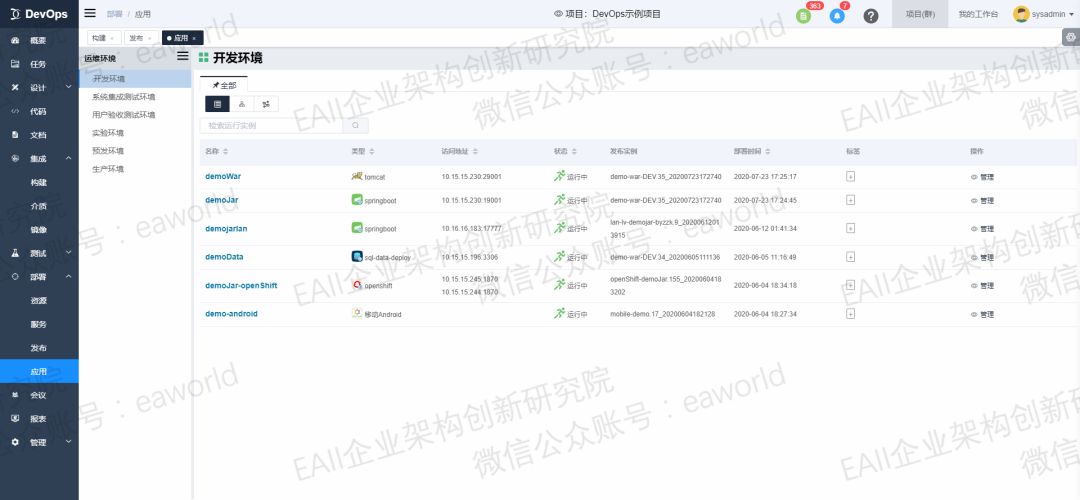
同时,DevOps在应用的界面提供了应用运维的一些基本能力,如应用的伸缩扩容、启动、停止、回滚,查看POD日志等。运维人员通过界面就能够获取到当前应用的详细信息,也可以很方便的进行应用的运维操作,这样可以大大减轻运维的压力。
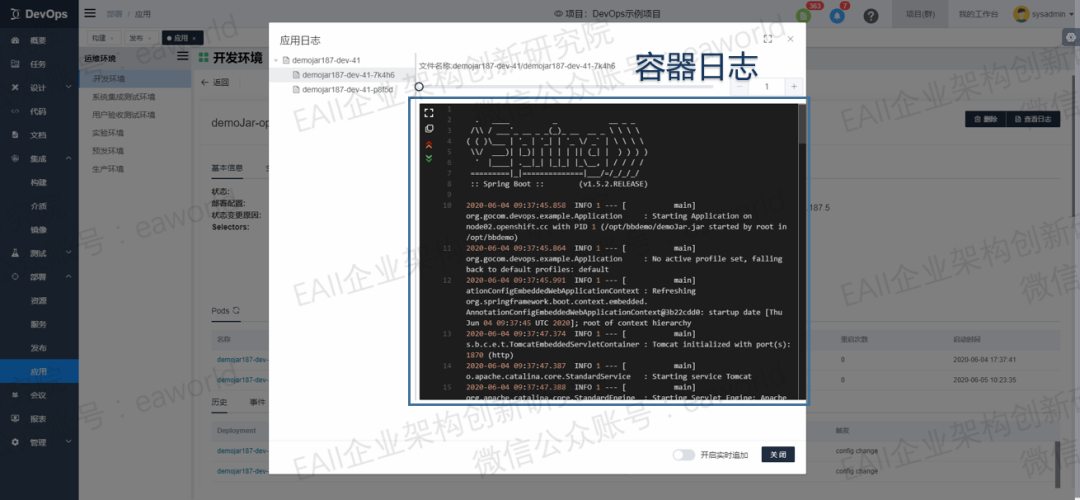
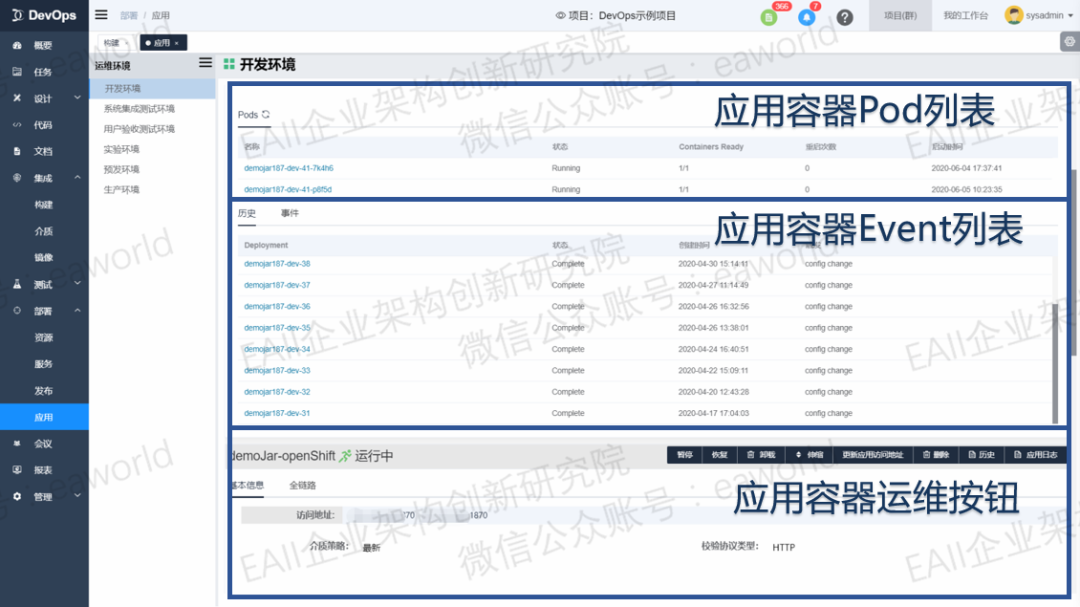
总结和展望
DevOps和OpenShift结合能够产生巨大的动能,在提升效率的同时可以提高交付的质量,自动化程度的提升可以几何倍提升对业务需求变动带来的相应能力。
伴随互联网的发展与赋能,行业竞争日益激烈,越来越多的企业开始技术创新和战略转型,经营模式从“以产品为中心”转向“以用户为中心”,营销模式从“粗放营销”转向“精准营销”,服务模式从“标准化服务”转向“个性化服务”,基于此,每个企业都有自己的理念和方法来运用容器云等工具,而所有新技术的加持都要基于企业能够融合创新并适应市场、优化业务流程以及改善用户体验。
但目前,企业在创新型业务交付的过程中,从收集和明确用户需求、开发代码和测试到最终生产上线交付业务,存在浪费时间和成本的问题从而影响交付速度的问题,而DevOps恰恰是为企业提高交付速度进一步优化用户体验的最佳解决方案。
推荐阅读
 关于作者:脸盆,普元研发工程师,擅长微服务、容器、DevOps等相关领域技术,目前负责DevOps容器云相关的设计和开发。算法定义软件,数据驱动产品,技术改变未来。
关于作者:脸盆,普元研发工程师,擅长微服务、容器、DevOps等相关领域技术,目前负责DevOps容器云相关的设计和开发。算法定义软件,数据驱动产品,技术改变未来。
 关于EAWorld:微服务,DevOps,数据治理,移动架构原创技术分享。长按二维码关注!
关于EAWorld:微服务,DevOps,数据治理,移动架构原创技术分享。长按二维码关注!
课程预告! 8月6日(周四)下午14:30普元云计算和大数据产品部架构师川枫为大家分享《数据治理之数据脱敏研究》,敬请期待!

分享、赞、在看,点点点

本文分享自微信公众号 - EAWorld(eaworld)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。











