
Hash算法解决冲突的方法一般有以下几种常用的解决方法
1, 开放定址法:
所谓的开放定址法就是一旦发生了冲突,就去寻找下一个空的散列地址,只要散列表足够大,空的散列地址总能找到,并将记录存入
公式为:fi(key) = (f(key)+di) MOD m (di=1,2,3,……,m-1)
※ 用开放定址法解决冲突的做法是:当冲突发生时,使用某种探测技术在散列表中形成一个探测序列。沿此序列逐个单元地查找,直到找到给定的关键字,或者
碰到一个开放的地址(即该地址单元为空)为止(若要插入,在探查到开放的地址,则可将待插入的新结点存人该地址单元)。查找时探测到开放的地址则表明表
中无待查的关键字,即查找失败。
比如说,我们的关键字集合为{12,67,56,16,25,37,22,29,15,47,48,34},表长为12。 我们用散列函数f(key) = key mod l2
当计算前S个数{12,67,56,16,25}时,都是没有冲突的散列地址,直接存入:

计算key = 37时,发现f(37) = 1,此时就与25所在的位置冲突。
于是我们应用上面的公式f(37) = (f(37)+1) mod 12 = 2。于是将37存入下标为2的位置: 
2, 再哈希法:
再哈希法又叫双哈希法,有多个不同的Hash函数,当发生冲突时,使用第二个,第三个,….,等哈希函数
计算地址,直到无冲突。虽然不易发生聚集,但是增加了计算时间。
3, 链地址法:
链地址法的基本思想是:每个哈希表节点都有一个next指针,多个哈希表节点可以用next指针构成一个单向链表,被分配到同一个索引上的多个节点可以用这个单向
链表连接起来,如:
键值对k2, v2与键值对k1, v1通过计算后的索引值都为2,这时及产生冲突,但是可以通道next指针将k2, k1所在的节点连接起来,这样就解决了哈希的冲突问题 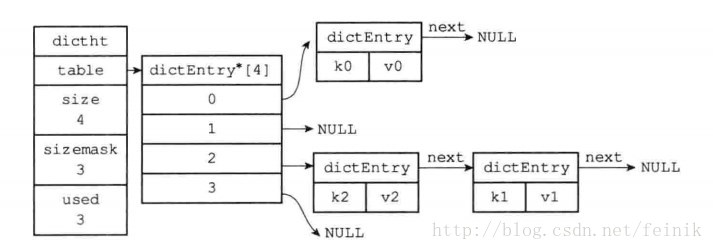
4, 建立公共溢出区:
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表










