
一、项目概述
这是一个被我称之为“没有枪、没有炮,硬着头皮自己造”的项目。项目是和其它公司合作的三个核心模块开发。
使用ES的目的是:
1)、采集数据、网站数据清洗后存入ES;
2)、对外提供精确检索、通配符检索、模糊检索、分词检索、全文检索接口等二次封装接口。
二、项目架构
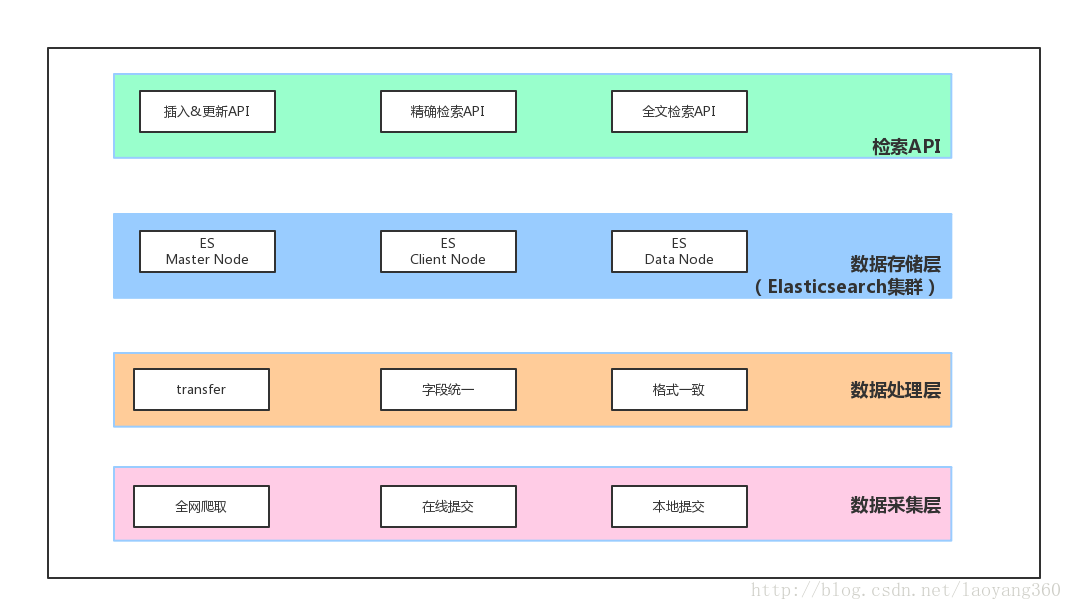
如上图所示,ES作为中间层,一方面存储数据清洗后存储的数据,另一方面对外提供插入、更新、删除、检索接口的。
三、ES使用小结
3.1 ES版本选型
1.X,2.X版本有太多局限性,5.X做了较大性能提升的改进。比如:string字段类型分成了keyword和text两种类型,keyword用于精确匹配,text结合设定的分词器用于全文检索。
选择5.X需要勇气,实践证明当时“向前一小步”的正确性。
3.2 ES安装部署
ELK都有安装。
ES安装了head插件,用途:查看集群状态、查看索引信息、查看mapping信息、查看每个索引下数据信息、进行简单字段查询操作;
安装了ik分词插件,用途:分词,实现全文检索。
安装了Kibana,用途:数据对接展示;用DevTool替代postman执行DSL验证,以验证增、删、改、查功能。
安装了logstash,用途:借助“logstash-input-jdbc”实现数据库到ES之间的同步。
3.3 ES API选型与使用
调研了ES提供的原生API以及Jest等,最终选择Jest。将Maven工程相关jar包导出到项目中使用。
3.4 后端框架选型
play new 工程名
play eclipsify 工程名
play clean
play deps
play run 测试模式
play start release模式
3.5 ES分页处理
ES Java接口能返回的默认的最大记录数为10000行。如果想返回超过1W+条的记录,需要做如下设置:
PUT ting_index/_settings
{
"max_result_window" : 500000
}
- 1
- 2
- 3
- 4
- 5
3.6 如何只删除数据,而不删除索引
类似Mysql等关系型数据库的delete from mtable操作,而不是drop掉表,参考如下:
POST my_store/products/_delete_by_query
{
"query": {
"match_all": {}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
参考:https://www.elastic.co/guide/en/elasticsearch/reference/master/docs-delete-by-query.html
3.7 Jest update更新操作
数据前添加doc一层,如下所示:
strJson = “{” + ” \”doc\” :” + strJson + “}”;
3.8 集群中所有节点都安装ik分词器
集群里每一个实例都要安装ik插件。
否则,当我们更新包含指定分词的mapping的时候会报错。
3.9 最大字节数限制
报错信息如下:“whose UTF8 encoding is longer than the max length 32766 “,
这个问题是某个字段size过大导致lucence不能索引引起的。
如果要存储超过32766字节的数据,那么需要在mapping中设置字段时,添加ignore_above = 256就可以了。
举例,新增Mapping的操作如下:
POST tingindex/tingtype/_mapping
{
"tingtype":{
"properties":{
"content":{
"type":"text", "analyzer":"ik_max_word", "search_analyzer":"ik_max_word", "fields":{ "keyword":{ "ignore_above":256, "type":"keyword" } } }, "publish_time":{ "type":"date", "format":"YYYY-MM-dd HH:mm:ss" }, "author":{ "ignore_above":256, "type":"keyword" }, } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/5.5/ignore-above.html
3.10 出现未分派, elasticsearch集群,在新增节点调整分片数时,出现UNASSIGNED。
排查方案:
GET /_cluster/allocation/explain
3.11 kibana修改时区
kibana->management->advanced setting->dateFormat:tz, 编辑,改成GMT +0。
3.12 ES检索(URL访问方式)
不指定索引的全文检索举例:
http://192.168.11.174:9200/_search?pretty&q=北京
指定索引的全文检索举例:
http://192.168.11.174:9200/articles/articles_info/_search?pretty&q=北京
指定字段检索举例:
http://192.168.11.174:9200/articles/articles_info/_search?pretty&q=title:我爱北京天安门
3.13 ES高性能配置(from ES中文社区)
【1】分词对性能的影响:
索引过程中,分词会对索引速度有所影响,建议你可以优化一下你的mapping,不必要的就不必分词,甚至不必设成可搜索的了。
举例:5.X中不必要分词的设置为keyword类型。
【2】分片和副本对性能影响:
分片和副本的设计,应该根据节点数来调整,正常情况下 节点数= (副本数+1)*分片数,若是你希望提高搜索性能,可是适当提高副本数。
【3】内存对性能的影响:
1).节点的内存分配的不能太少了。
ES其实很占内存,大部分的操作都是建立在内存足够的基础上。
举例:你的数据量应该在150G-200G左右,我觉得可以把内存调整到10G左右。
2). ES的内存使用分为两部分ES缓存和Lucene通过内核缓存加速一些数据。
3). 如果服务器内存 nG > 64G,ES的内存尽量设置低于32G,建议最大31G.
因为es使用“内存指针压缩”技术,一旦内存内存大于32G这项技术将失效,内存有效使用只有原来的60%~70%。
你不必为内存浪费而担心,因为lucene会通过系统把一些聚合和排序的数据缓存起来方便你快速查询使用。
4) .如果服务器内存 nG < 64G,建议给ES分配 内存 (n-2)/2G. 首先2G是给系统预留,然后es和lucene。
5) . 如果你想继续你的实时查询,尽量不要使用swap(交换分区),建议关闭系统swap使用
【4】ES线程设置
线程数方法:线程数:=(内核数*3)/2+1
举例:检索服务器是24核,所以:线程池的大小=(24*3)/2+1=37 。
参考:
https://www.elastic.co/guide/en/elasticsearch/reference/current/modules-threadpool.html
四、项目整体小结
4.1、需求要细化
切记:
1)不要拿到合同或需求就开发。
2)欲速则不达。
3)需求细化后形成《需求规格说明书》,并一定邮件或电话或当面找用户确认。
对于需求,由顶向下知道需要实现的核心功能,团队核心敲定分几个模块?
逐个模块细化需求点。
4.2、预研要充分
对于新的技术点,在项目启动后的需求细化阶段即可同步进行。
作为项目经理的我,没有事必躬亲,多关注预研点方案选型、预研难点、预研报告,小细节如:下载、安装部署、参数验证、英文翻译安排团队其它成员执行。
4.3、文档要跟进
需求有需求文档,设计根据项目需要和进度安排有概要设计或详细设计文档。
设计文档千万不能少,设计的过程就是开发“路演”的过程。
设计文档一定要梳理清楚架构图、模块图、数据流图、流程图。
需求文档是设计的基础,需求和设计文档是开发的基础。
4.4、思维要活跃
技术方案的选型很重要,大的方面包括:
1)检索存储集群部署,集群节点个数选择等。
2)前后端选型,前端用jquery,jsp还是js? 后端使用spring,tomcat,还是play框架?
3)开源方案选型,要提早预研可用性、需求点覆盖程度、二次开发或封装难度等。
4)前后端接口对接格式敲定。
5)对外提供检索服务接口名称,参数敲定。
思维活跃主要体现在:
1)方案选型、技术调研快刀斩乱麻,时间紧,不纠结。此路不通,另寻他路。
2)自己不能解决,不要太拖沓,及时google,stackoverflow解决或者和架构师讨论解决。
4.5、开发要同步
1)接口对接沟通要充分。
接口提供方和接口使用方,要反复多花时间沟通业务,要定义好数据接口。
此时的耗时,事后你会发现是好事,沟通越充分要好。
2)接口对接要实时同步。
一方修改了,要第一时间告诉对方。
五、项目管理小结
5.1、多方沟通要邮件
邮件是证据,避免不必要赖账或扯皮。
qq沟通和微信都不是好方式,最主要原因是不利于查看聊天记录、不利于快速检索。
5.2、进度汇报要详细
包含但不限于项目整体情况、本周已完成、下周计划、项目风险与应对。
5.3、任务分工要明确
团队成员特点不同,切记口头分工。团队人少,我用excel做了详细记录。
5.4、每周例会要及时
周例会起到承上启下的作用,有效协调控制项目进度、团队成员工作饱和度。
六、后记
1、ES要学习的东西非常多。不纠结,多去官网、官方论坛、stackoverflow、Google检索答案,
相信我,你并不孤独。
2、ES还有很长的路要走,继续精进阅读与思考,继续加油!
——————————————————————————————————
更多ES相关实战干货经验分享,请扫描下方【铭毅天下】微信公众号二维码关注。
(每周至少更新一篇!)

和你一起,死磕Elasticsearch!
——————————————————————————————————
2017年09月03日 16:09 于家中床前
作者:铭毅天下
转载请标明出处,原文地址:
http://blog.csdn.net/laoyang360/article/details/77623013
如果感觉本文对您有帮助,请点击‘喜欢’支持一下,并分享出去,让更多的人受益。您的支持是我坚持写作最大的动力,谢谢!











