
Java - J.U.C体系进阶
作者:Kerwin
说到做到,就是我的忍道!
juc-collections 集合框架
ConcurrentHashMap
ConcurrentHashMap 是线程安全的,用法和HashMap基本一致,原理部分可参考以下文章:
ConcurrentSkipListSet
ConcurrentSkipListSet是对ConcurrentHashMap 的一个补充,有点像TreeMap,LinkedHashMap对HashMap的补充一样,注意的点如下:
ConcurrentSkipListSet俗称 “跳表”,数据结构如下:
每个节点有随机算法概率性的为链表加层(也可以理解为索引),有参数约束了最大层的数量,因此在查询的时候就像是在跳跃一样,跳表的名称由此而来,这种数据结构实现远比红黑树简单,且查询修改删除的效率都较快
常用方法:
put,get,containsKey,containsValue,keySet等常用方法
还有如下:
firstKey()
lastKey()
firstEntry()
lastEntry()
subMap(fromKey, toKey)...
CopyOnWriteArrayList
大多数业务场景都是一种“读多写少”的情形,CopyOnWriteArrayList就是为适应这种场景而诞生的。
CopyOnWriteArrayList,运用了一种“写时复制”的思想。通俗的理解就是当我们需要修改(增/删/改)列表中的元素时,不直接进行修改,而是先将列表Copy,然后在新的副本上进行修改,修改完成之后,再将引用从原列表指向新列表。
这样做的好处是读/写是不会冲突的,可以并发进行,读操作还是在原列表,写操作在新列表。仅仅当有多个线程同时进行写操作时,才会进行同步
CopyOnWriteArrayList提供了三种不同的构造器 :
- CopyOnWriteArrayList() 空构造器
- CopyOnWriteArrayList(Collection<? extends E> c) 集合构造器
- CopyOnWriteArrayList(E[] toCopyIn) 数组构造器
最终都是创建了一个CopyOnWriteArrayList集合
核心方法:
// get方法
public E get(int index) {
return get(getArray(), index);
}
private E get(Object[] a, int index) {
return (E) a[index];
}
// add方法
public boolean add(E e) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray(); // 旧数组
int len = elements.length;
Object[] newElements = Arrays.copyOf(elements, len + 1); // 复制并创建新数组
newElements[len] = e; // 将元素插入到新数组末尾
setArray(newElements); // 内部array引用指向新数组
return true;
} finally {
lock.unlock();
}
}
// remove方法
public E remove(int index) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
Object[] elements = getArray();
int len = elements.length;
E oldValue = get(elements, index); // 获取旧数组中的元素, 用于返回
int numMoved = len - index - 1; // 需要移动多少个元素
if (numMoved == 0) // index位置刚好是最后一个元素
setArray(Arrays.copyOf(elements, len - 1));
else {
Object[] newElements = new Object[len - 1];
System.arraycopy(elements, 0, newElements, 0, index);
System.arraycopy(elements, index + 1, newElements, index, numMoved);
setArray(newElements);
}
return oldValue;
} finally {
lock.unlock();
}
}
1. 内存的使用
由于CopyOnWriteArrayList使用了“写时复制”,所以在进行写操作的时候,内存里会同时存在两个array数组,如果数组内存占用的太大,那么可能会造成频繁GC,所以CopyOnWriteArrayList并不适合大数据量的场景。2. 数据一致性
CopyOnWriteArrayList只能保证数据的最终一致性,不能保证数据的实时一致性——读操作读到的数据只是一份快照。所以如果希望写入的数据可以立刻被读到,那CopyOnWriteArrayList并不适合。
ConcurrentLinkedQueue和ConcurrentLinkedDeque
ConcurrentLinkedQueue和ConcurrentLinkedDeque都是基于CAS操作的无锁,非阻塞队列,本文重点讲一下ConcurrentLinkedQueue的应用
当许多线程共享访问一个公共集合时,ConcurrentLinkedQueue 是一个恰当的选择
注意点如下:
- ConcurrentLinkedQueue 是无锁,但利用CAS操作保证线程安全的队列
- ConcurrentLinkedQueue 是无阻塞队列
- 适用场景:单生产者 ,多消费者 ,多生产者 ,多消费者 —> 即多消费者模式下适应ConcurrentLinkedQueue
- ConcurrentLinkedQueue 多用于消息队列
Demo如下:
// 我们假设有很多接口请求,有的正常,有的失败了,失败了一定要打日志,但是打日志又涉及到流,较为耗时,所以我们可以把code码标识为错误的信息拿出来,塞到队列里,然后另起一定的线程去专门打印日志,场景可能不对,但就是这个意思,或者处理订单等等,一个道理
public class TestConcurrentLinkedQueue {
private static Integer totalSize = 500;
private static ConcurrentLinkedQueue<String> lQueue = new ConcurrentLinkedQueue<String>();
private static CountDownLatch latch = new CountDownLatch(totalSize);
public static void main(String[] args) throws InterruptedException {
for (int i = 0; i < totalSize; i++) {
final int k = i;
new Thread(new Runnable() {
@Override
public void run() {
latch.countDown();
int num = (int) (Math.random() * 10);
if (num < 5) {
lQueue.offer("mytest-" + num);
}
}
}).start();
}
latch.await();
while (true) {
System.out.println(lQueue.poll());
Thread.sleep(50);
}
}
}
// 核心方法:
offer 入队 --- 如果队列满了,返回false
poll 出队 --- 如果队列为null,返回null
注意点:
- offer,poll方法都保证了原子性,所以是线程安全的
- if (!lQueue.isEmpty) {lQueue.poll…}, 先判断集合是否为空再去取,无法保证其原子性
- size方法会遍历整个集合,所以要用也是用isEmpty来判断大小等,size方法耗时会非常久
- 上述处理线程可以配合定时线程池,考虑业务场景,隔一段时间再处理,避免资源浪费
BlockingQueue
BlockingQueue是一个阻塞队列接口,下面是具体的实现
- 单生产者,单消费者 用 LinkedBlockingqueue
- 多生产者,单消费者 用 LinkedBlockingqueue
- 单生产者 ,多消费者 用 ConcurrentLinkedQueue
- 多生产者 ,多消费者 用 ConcurrentLinkedQueue
BlockingQueue是阻塞队列,适用于任务队列,由一个线程去处理数据等等,比如发快递,有很多人发快递,但是快递员只有一个,如果没活干,快递员就等着,如果有活,就开干
核心方法:
public interface BlockingQueue<E> extends Queue<E> {
//将给定元素设置到队列中,如果设置成功返回true, 否则返回false。如果是往限定了长度的队列中设置值,推荐使用offer()方法。
boolean add(E e);
//将给定的元素设置到队列中,如果设置成功返回true, 否则返回false. e的值不能为空,否则抛出空指针异常。
boolean offer(E e);
//将元素设置到队列中,如果队列中没有多余的空间,该方法会一直阻塞,直到队列中有多余的空间。
void put(E e) throws InterruptedException;
//将给定元素在给定的时间内设置到队列中,如果设置成功返回true, 否则返回false.
boolean offer(E e, long timeout, TimeUnit unit)
throws InterruptedException;
//从队列中获取值,如果队列中没有值,线程会一直阻塞,直到队列中有值,并且该方法取得了该值。
E take() throws InterruptedException;
//在给定的时间里,从队列中获取值,时间到了直接调用普通的poll方法,为null则直接返回null。
E poll(long timeout, TimeUnit unit)
throws InterruptedException;
//获取队列中剩余的空间。
int remainingCapacity();
//从队列中移除指定的值。
boolean remove(Object o);
//判断队列中是否拥有该值。
public boolean contains(Object o);
//将队列中值,全部移除,并发设置到给定的集合中。
int drainTo(Collection<? super E> c);
//指定最多数量限制将队列中值,全部移除,并发设置到给定的集合中。
int drainTo(Collection<? super E> c, int maxElements);
}
注意:
BlockingQueue在使用的时候不要去进行各种是否为空,或者满了等等的判断,另外这是阻塞队列,凡是涉及到前台页面交互的,需要快点得到结果的都不应该直接使用阻塞队列,否则会导致假死的情况
ArrayBlockingQueue
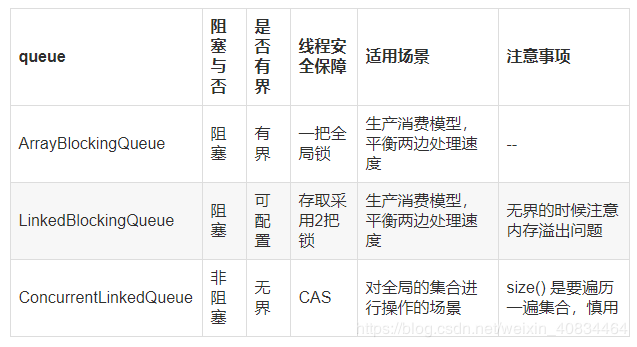
ArrayBlockingQueue利用了ReentrantLock来保证线程的安全性,针对队列的修改都需要加全局锁。在一般的应用场景下已经足够。对于超高并发的环境,由于生产者-消息者共用一把锁,可能出现性能瓶颈
ArrayBlockingQueue维护了一把全局锁,无论是出队还是入队,都共用这把锁,这就导致任一时间点只有一个线程能够执行。那么对于“生产者-消费者”模式来说,意味着生产者和消费者不能并发执行
构造方法:
构造方法
public ArrayBlockingQueue(int capacity)
构造指定大小的有界队列
public ArrayBlockingQueue(int capacity, boolean fair)
构造指定大小的有界队列,指定为公平或非公平锁
public ArrayBlockingQueue(int capacity, boolean fair, Collection<? extends E> c)
构造指定大小的有界队列,指定为公平或非公平锁,指定在初始化时加入一个集合
LinkedBlockingQueue
LinkedBlockingQueue是一种近似有界阻塞队列,为什么说近似?因为LinkedBlockingQueue既可以在初始构造时就指定队列的容量,也可以不指定,如果不指定,那么它的容量大小默认为
Integer.MAX_VALUE。LinkedBlockingQueue除了底层数据结构(单链表)与ArrayBlockingQueue不同外,另外一个特点就是:
它维护了两把锁——takeLock和putLock。takeLock用于控制出队的并发,putLock用于入队的并发。这也就意味着,同一时刻,只能只有一个线程能执行入队/出队操作,其余入队/出队线程会被阻塞;但是,入队和出队之间可以并发执行,即同一时刻,可以同时有一个线程进行入队,另一个线程进行出队,这样就可以提升吞吐量
基本方法和上文一致,只不过内部实现不一样而已
PriorityBlockingQueue
PriorityBlockingQueue是一种无界阻塞队列,在构造的时候可以指定队列的初始容量。具有如下特点:
- PriorityBlockingQueue与之前介绍的阻塞队列最大的不同之处就是:它是一种优先级队列,也就是说元素并不是以FIFO的方式出/入队,而是以按照权重大小的顺序出队;
- PriorityBlockingQueue是真正的无界队列(仅受内存大小限制),它不像ArrayBlockingQueue那样构造时必须指定最大容量,也不像LinkedBlockingQueue默认最大容量为
Integer.MAX_VALUE; - 由于PriorityBlockingQueue是按照元素的权重进入排序,所以队列中的元素必须是可以比较的,也就是说元素必须实现
Comparable接口; - 由于PriorityBlockingQueue无界队列,所以插入元素永远不会阻塞线程;
- PriorityBlockingQueue底层是一种基于数组实现的堆结构。
核心方法基本一致,重点在于其使用场景,即有优先级的阻塞队列,可以用作,会员特权场景? 嘻嘻
SynchronousQueue
Java 6的并发编程包中的SynchronousQueue是一个没有数据缓冲的BlockingQueue,生产者线程对其的插入操作put必须等待消费者的移除操作take,反过来也一样。
不像ArrayBlockingQueue或LinkedListBlockingQueue,SynchronousQueue内部并没有数据缓存空间,你不能调用peek()方法来看队列中是否有数据元素,因为数据元素只有当你试着取走的时候才可能存在,不取走而只想偷窥一下是不行的,当然遍历这个队列的操作也是不允许的。队列头元素是第一个排队要插入数据的线程,而不是要交换的数据。数据是在配对的生产者和消费者线程之间直接传递的,并不会将数据缓冲数据到队列中。可以这样来理解:生产者和消费者互相等待对方,握手,然后一起离开。
特点:
- 不能在同步队列上进行 peek,因为仅在试图要取得元素时,该元素才存在;
- 除非另一个线程试图移除某个元素,否则也不能(使用任何方法)添加元素;也不能迭代队列,因为其中没有元素可用于迭代。队列的头是尝试添加到队列中的首个已排队线程元素; 如果没有已排队线程,则不添加元素并且头为 null。
- 对于其他 Collection 方法(例如 contains),SynchronousQueue 作为一个空集合。此队列不允许 null 元素。
- 它非常适合于传递性设计,在这种设计中,在一个线程中运行的对象要将某些信息、事件或任务传递给在另一个线程中运行的对象,它就必须与该对象同步。
- 对于正在等待的生产者和使用者线程而言,此类支持可选的公平排序策略。默认情况下不保证这种排序。 但是,使用公平设置为 true 所构造的队列可保证线程以 FIFO 的顺序进行访问。 公平通常会降低吞吐量,但是可以减小可变性并避免得不到服务。
- SynchronousQueue的以下方法:
- iterator() 永远返回空,因为里面没东西
- peek() 永远返回null
- put() 往queue放进去一个element以后就一直wait直到有其他thread进来把这个element取走
- offer() 往queue里放一个element后立即返回,如果碰巧这个element被另一个thread取走了,offer方法返回true,认为offer成功;否则返回false
- offer(2000, TimeUnit.SECONDS) 往queue里放一个element但是等待指定的时间后才返回,返回的逻辑和offer()方法一样
- take() 取出并且remove掉queue里的element(认为是在queue里的。。。),取不到东西他会一直等。
- poll() 取出并且remove掉queue里的element(认为是在queue里的。。。),只有到碰巧另外一个线程正在往queue里offer数据或者put数据的时候,该方法才会取到东西。否则立即返回null
- poll(2000, TimeUnit.SECONDS) 等待指定的时间然后取出并且remove掉queue里的element,其实就是再等其他的thread来往里塞
- isEmpty()永远是true
- remainingCapacity() 永远是0
- remove()和removeAll() 永远是false
SynchronousQueue 内部没有容量,但是由于一个插入操作总是对应一个移除操作,反过来同样需要满足。那么一个元素就不会再SynchronousQueue 里面长时间停留,一旦有了插入线程和移除线程,元素很快就从插入线程移交给移除线程。也就是说这更像是一种信道(管道),资源从一个方向快速传递到另一方 向。显然这是一种快速传递元素的方式,也就是说在这种情况下元素总是以最快的方式从插入着(生产者)传递给移除着(消费者),这在多任务队列中是最快处理任务的方式。在线程池里的一个典型应用是Executors.newCachedThreadPool()就使用了SynchronousQueue,这个线程池根据需要(新任务到来时)创建新的线程,如果有空闲线程则会重复使用,线程空闲了60秒后会被回收
所以总结就是,一般情况用不到,必要的时候再去研究就好











