

大赛简介

帝国理工学院联合爱奇艺、格灵深瞳、深见网络科技举办了轻量级人脸识别竞赛(Lightweight Face Recognition Challenge ),它是今年ICCV的一项重要竞赛,吸引了来自全球的292支竞赛队伍参加。
此次ICCV LFR挑战赛一共分为四项任务,每项竞赛都有各自的限制和侧重点:
Protocol-1 (DeepGlint-Light)图像人脸识别轻量级识别模型,运算复杂度小于1Gflops,模型大小小于20MB,数据类型float32,特征维度512 (FPR@1e-8);
Protocol-2 (DeepGlint-Large)图像人脸识别大型级识别模型,运算复杂度小于30Gflops,数据类型float32,特征维度512 (FPR@1e-8);
Protocol-3 (iQIYI-Light) 视频人脸识别轻量级识别模型,运算复杂度小于1Gflops,数据类型float32,特征维度512 (FPR@1e-4);
Protocol-4 (iQIYI-Large) 视频人脸识别大型识别模型,运算复杂度小于30Gflops,数据类型float32,特征维度512 (FPR@1e-4)。
赛题的社会价值
ICCV LFR(Lightweight Face Recognition Challenge )轻量级人脸识别挑战赛的设立是为了寻找一个可以在无限制的动态监控视频场景下有优异表现的轻量级高精度的模型来应对大数据库人脸识别应用。这对于进一步推动非受限场景下的人脸识别技术的研究以及提升相关学术成果的转化效果具有重要意义。

冠军方案解读
本次竞赛中格灵深瞳有两个竞赛赛道,分别为 DeepGlint-Light 与 DeepGlint-Large:
DeepGlint-Light赛道的冠军团队,来自地平线 (HorizonRobotics)公司,以0.8878精度的成绩获得第一名。
DeepGLint-Large赛道的冠军团队,来自自动化所模式识别实验室和Winsense,以0.9419精度的成绩获得第一名。
爱奇艺有两个竞赛赛道,分别为 iQIYI-Light 与 iQIYI-Large(爱奇艺视频人脸识别轻量级识别模型与爱奇艺视频人脸识别大型识别模型)。
iQIYI-Light 赛道的冠军团队,来自微软亚洲研究院,以0.6323精度的成绩获得第一名;
iQIYI-Large 赛道的冠军团队, 来自商汤和香港中文大学,以0.7298精度的成绩获得第一名。
不同于其他人脸识别比赛,ICCV LFR挑战赛严格限制了训练数据和测试数据。在如此严格的限制条件下,在292个参赛队伍中脱颖而出变得异常艰难。我们来看看各个赛道的优胜者们,是如何杀出重围,喜获桂冠的呢?通过下面的解析,大家也许能够找到答案。
01 iQIYI Large 冠军
- 团队组成及分工
Trojans团队由香港中文大学多媒体实验室的刘宇和Sensetime X-Lab的宋广录、刘吉豪、张满园、周彧聪、闫俊杰组成。其中前四位队员负责主干模型设计与搜索、数据分析,质量评估模型设计以及实验调参,周彧聪负责了整个过程训练平台的搭建和维护。而闫俊杰是团队的顾问。
- 模型思路
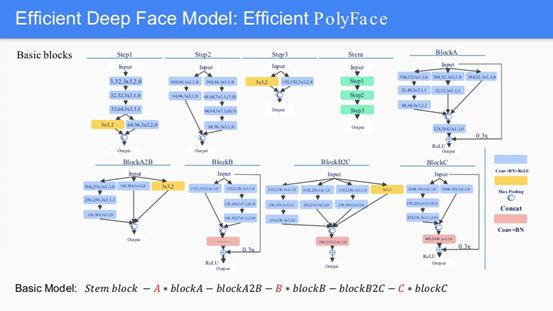
模型思路分为主干网络和帧融合策略两个部分。 由于比赛约束了总运算量不超过30GFlops的限制,他们选择通过类似MNasNet和EfficientNet的方式搜索在30GFlops附近的帕累托最优模型。 同时,设计了一个新损失函数,这使得单模型结果提升了0.8。 对于帧融合方式,他们提出了鉴别力分布假设。 该假设认为每一帧特征的融合权重应该由主干特征网络来决定——对于特征网络具有区分度的特征应该越具有更高的权重。 就是这些设计帮助他们在视频人脸识别的大模型赛道中获得了第一的成绩。 他们已将模型和代码放在GitHub(https://github.com/sciencefans/trojans-face-recognizer)中,供大家参考。
- 不足之处
这个模型也并非完美,他们觉得还有可改进的空间。在搜索主干网络结构的过程中,由于时间关系,出现了搜索空间比较小的问题。同时,他们也没有考虑augmentation,domain gap等方面。这些都是他们觉得能够进一步提升性能的点。
02 DeepGlint Large 冠军
- 团队组成及分工
该团队由自动化所模式识别实验室CBSR组的博士生刘浩,助理研研究员朱翔昱,雷震研究员,李子青研究员和赢识科技的张帆 易东老师组成。其中,刘浩主要负责代码和实验,其他成员主要给予方法上的指导。

- 模型思路
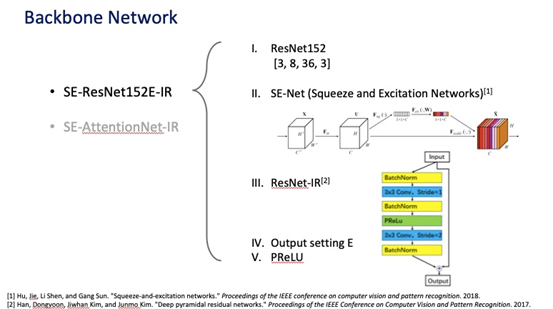
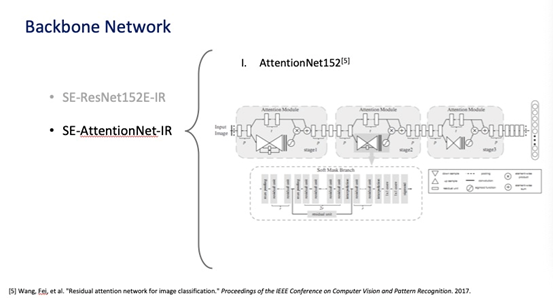
由于本次竞赛的训练集、切图方式是固定的,所以团队主要着眼于网络架构和损失函数的设计。 针对他们们参加的DeepGlint Large 赛道,计算量限制30gflops,他们分别设计了Resnet和AttentionNet架构下两个网络,resnet152 AttentionNet152,其中AttentionNet152的计算量为29.5GFLOPs,充分利用了规则允许计算量,是他们取得高性能的关键。 在损失函数方面,他们认为目前最先进的人脸损失函数CosFace,ArcFace在本质上几乎一样,他们的关键几乎在于margin的设置,所以他们只选用了CosFace,重点调整了margin,最终取得了冠军。 关于代码,他们使用的技术其实都是有开源代码的,大家可以按照他们的方案组合在一起即可。
- 不足之处
方案的不足之处主要就是里面使用的技术都是现有的,他们没能提出一些新的方案或改进。另外,目前AutoML正在引发新一轮变革,没能使用AutoML在网络架构和损失函数上带来进一步的提升,希望日后能借助AutoML在人脸识别上带来新一轮的进步。
03 DeepGlint Light 冠军
- 团队组成及分工
该团队来自地平线 (Horizon Robotics)公司. 主要由三位研究员/工程师组成。从训练策略探索,网络结构调优,KD(KnowledgeDistillation)算法调优这几个方面进行探索。
- 模型思路
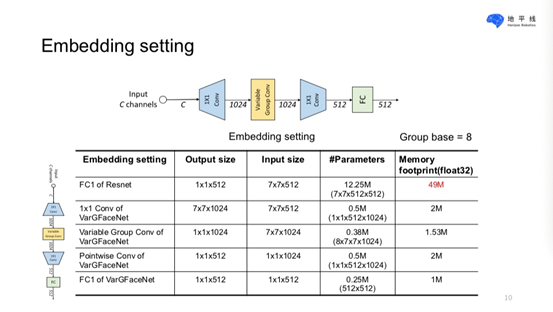
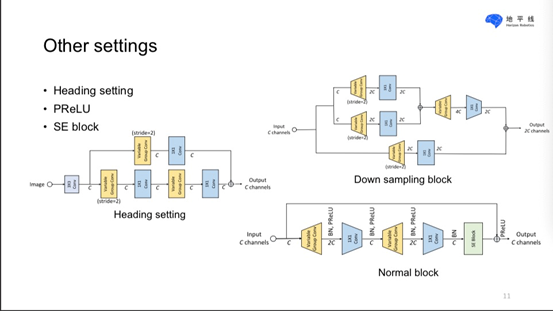
他们主要是基于VarGNet进行large scale的face recognition,其中对embedding setting和head setting进行了修改,然后对block进行了修改,以及修改了网络的堆叠方式以满足受限Flops。 最后使用了KD的方法进行调优。
- 不足之处
相对于其他的队伍,他们的方法更为直接,不需要很多的finetune,没有太多的tricks,复现起来也比较方便。 改进方面的话主要是两个方面,一个是网络结构可以针对需要的硬件平台使用NAS进行设计。 另一个是在KD方面,他们现在使用的KD方法比较简单,后面可以继续探索使用KD进行泛化能力的迁移等。 除此之外,在FR tasks上面,也可以尝试去除与身份信息不太相关的信息,比如年龄,地域等。
本文来源 雷锋网
end
也许你还想看
2018年视频人物识别挑战赛冠军是如何养成的?

扫一扫下方二维码,更多精彩内容陪伴你!

本文分享自微信公众号 - 爱奇艺技术产品团队(iQIYI-TP)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。









