
前言
网关是流量请求的入口,在微服务架构中承担了非常重要的角色,网关高可用的重要性不言而喻。在使用网关的过程中,为了满足业务诉求,经常需要变更配置,比如流控规则、路由规则等等。因此,网关动态配置是保障网关高可用的重要因素。那么,Soul 网关又是如何支持动态配置的呢?
使用过 Soul 的同学都知道,Soul 的插件全都是热插拔的,并且所有插件的选择器、规则都是动态配置,立即生效,不需要重启服务。但是我们在使用 Soul 网关过程中,用户也反馈了不少问题
- 依赖
zookeeper,这让使用etcd、consul、nacos注册中心的用户很是困扰 - 依赖
redis、influxdb,我还没有使用限流插件、监控插件,为什么需要这些
因此,我们对 Soul 进行了局部重构,历时两个月的版本迭代,我们发布了 2.0 版本
- 数据同步方式移除了对
zookeeper的强依赖,新增http 长轮询以及websocket - 限流插件与监控插件实现真正的动态配置,由之前的
yml配置,改为admin后台用户动态配置
1.可能有人会问我,配置同步为什么不使用配置中心呢?
答:首先,引入配置中心,会增加很多额外的成本,不管是运维,而且会让 Soul 变得很重;另外,使用配置中心,数据格式不可控,不便于 soul-admin 进行配置管理。
2.可能还有人会问?动态配置更新?每次我查数据库,或者redis不就行了吗?拿到的就是最新的,哪里那么多事情呢?
答:soul作为网关,为了提供更高的响应速度,所有的配置都缓存在JVM的Hashmap中,每次请求都走的本地缓存,速度非常快。所以本文也可以理解为分布式环境中,内存同步的三种方式。
原理分析
先来张高清无码图,下图展示了 Soul 数据同步的流程,Soul 网关在启动时,会从从配置服务同步配置数据,并且支持推拉模式获取配置变更信息,并且更新本地缓存。而管理员在管理后台,变更用户、规则、插件、流量配置,通过推拉模式将变更信息同步给 Soul 网关,具体是 push 模式,还是 pull 模式取决于配置。关于配置同步模块,其实是一个简版的配置中心。 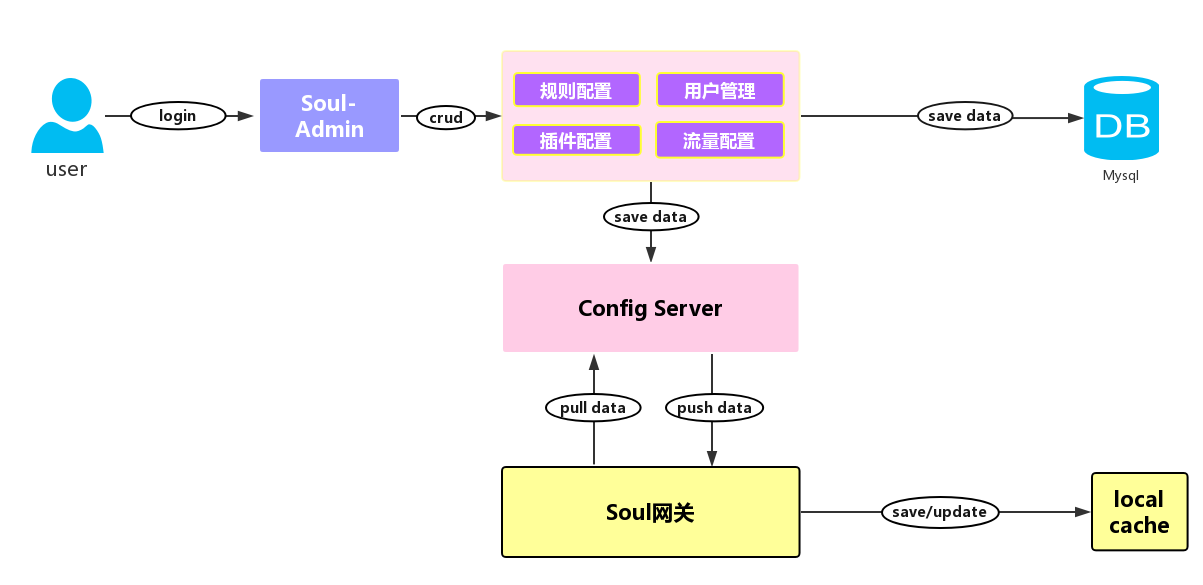
在 1.x 版本中,配置服务依赖 zookeeper 实现,管理后台将变更信息 push 给网关。而 2.x 版本支持 webosocket、http、zookeeper,通过 soul.sync.strategy 指定对应的同步策略,默认使用 http 长轮询同步策略,可以做到秒级数据同步。但是,有一点需要注意的是,soul-web 和 soul-admin 必须使用相同的同步机制。
如下图所示,soul-admin 在用户发生配置变更之后,会通过 EventPublisher 发出配置变更通知,由 EventDispatcher 处理该变更通知,然后根据配置的同步策略(http、weboscket、zookeeper),将配置发送给对应的事件处理器
- 如果是
websocket同步策略,则将变更后的数据主动推送给soul-web,并且在网关层,会有对应的WebsocketCacheHandler处理器处理来处admin的数据推送 - 如果是
zookeeper同步策略,将变更数据更新到zookeeper,而ZookeeperSyncCache会监听到zookeeper的数据变更,并予以处理 - 如果是
http同步策略,soul-web主动发起长轮询请求,默认有 90s 超时时间,如果soul-admin没有数据变更,则会阻塞 http 请求,如果有数据发生变更则响应变更的数据信息,如果超过 60s 仍然没有数据变更则响应空数据,网关层接到响应后,继续发起 http 请求,反复同样的请求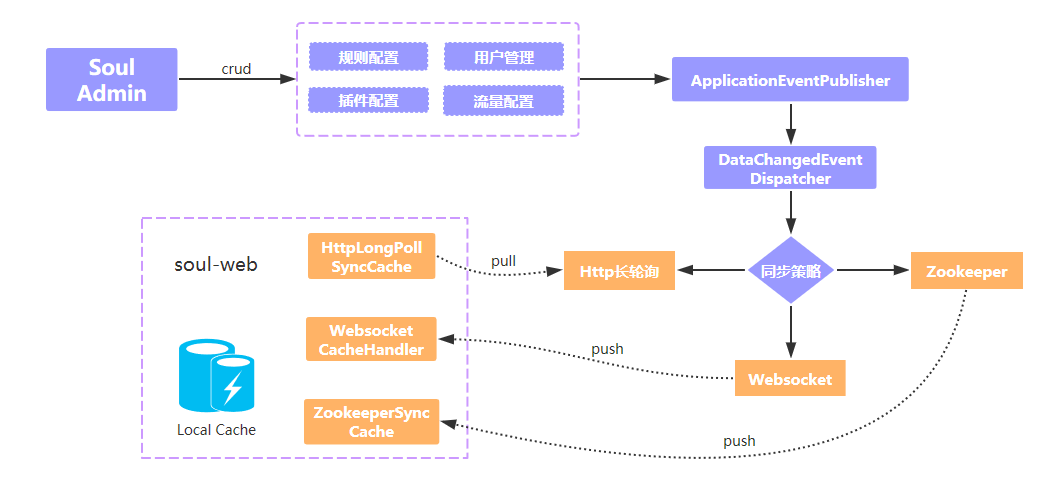
zookeeper同步
基于 zookeeper 的同步原理很简单,主要是依赖 zookeeper 的 watch 机制,soul-web 会监听配置的节点,soul-admin 在启动的时候,会将数据全量写入 zookeeper,后续数据发生变更时,会增量更新 zookeeper 的节点,与此同时,soul-web 会监听配置信息的节点,一旦有信息变更时,会更新本地缓存。
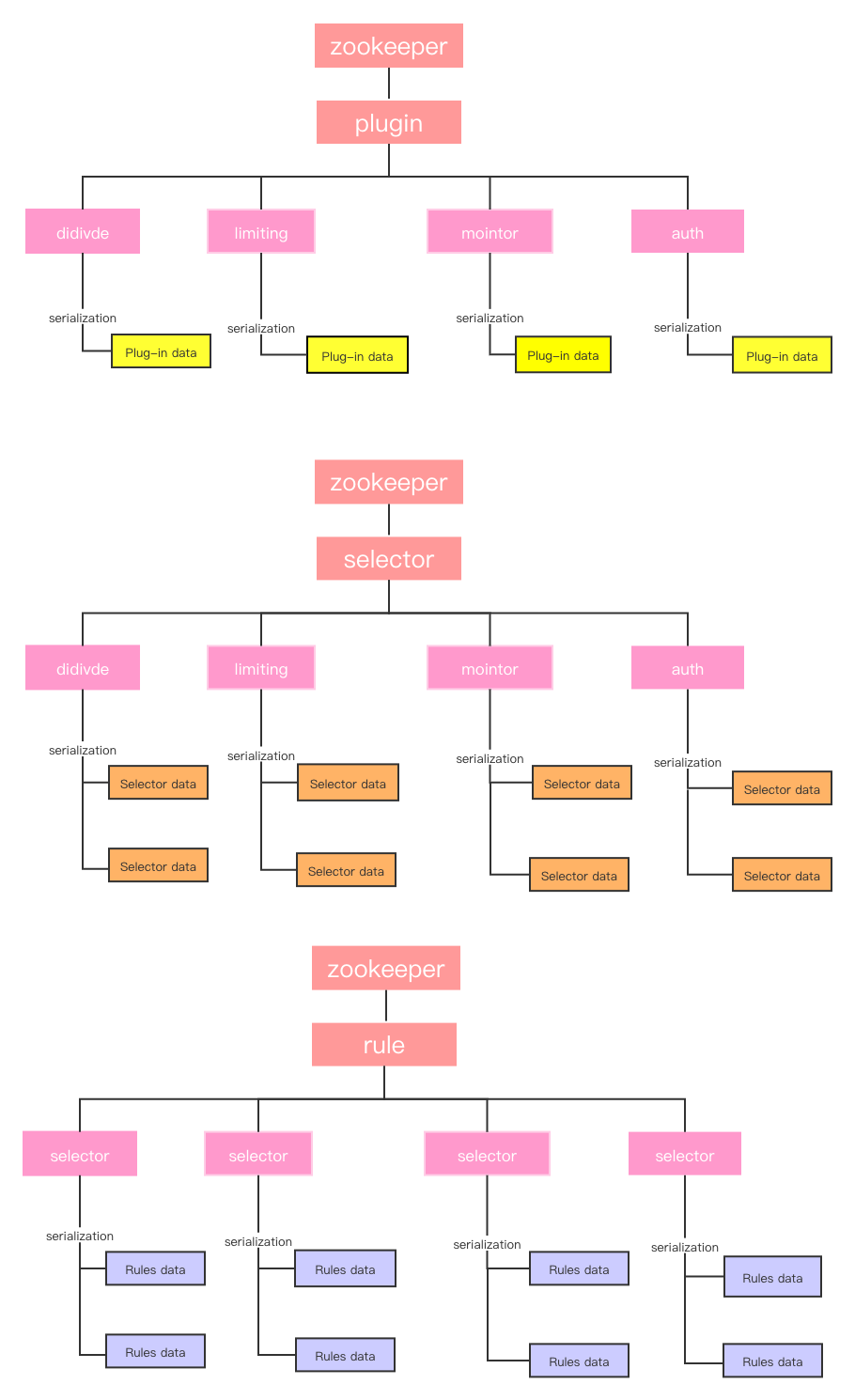
soul 将配置信息写到zookeeper节点,是通过精细设计的。
websocket同步
websocket 和 zookeeper 机制有点类似,将网关与 admin 建立好 websocket 连接时,admin 会推送一次全量数据,后续如果配置数据发生变更,则将增量数据通过 websocket 主动推送给 soul-web
使用websocket同步的时候,特别要注意断线重连,也叫保持心跳。soul使用java-websocket 这个第三方库来进行websocket连接。
public class WebsocketSyncCache extends WebsocketCacheHandler {
/**
* The Client.
*/
private WebSocketClient client;
public WebsocketSyncCache(final SoulConfig.WebsocketConfig websocketConfig) {
ScheduledThreadPoolExecutor executor = new ScheduledThreadPoolExecutor(1,
SoulThreadFactory.create("websocket-connect", true));
client = new WebSocketClient(new URI(websocketConfig.getUrl())) {
@Override
public void onOpen(final ServerHandshake serverHandshake) {
//....
}
@Override
public void onMessage(final String result) {
//....
}
};
//进行连接
client.connectBlocking();
//使用调度线程池进行断线重连,30秒进行一次
executor.scheduleAtFixedRate(() -> {
if (client != null && client.isClosed()) {
client.reconnectBlocking();
}
}, 10, 30, TimeUnit.SECONDS);
}
http长轮询
zookeeper、websocket 数据同步的机制比较简单,而 http 同步会相对复杂一些。Soul 借鉴了 Apollo、Nacos 的设计思想,取决精华,自己实现了 http 长轮询数据同步功能。注意,这里并非传统的 ajax 长轮询!

http 长轮询机制如上所示,soul-web 网关请求 admin 的配置服务,读取超时时间为 90s,意味着网关层请求配置服务最多会等待 90s,这样便于 admin 配置服务及时响应变更数据,从而实现准实时推送。
http 请求到达 sou-admin 之后,并非立马响应数据,而是利用 Servlet3.0 的异步机制,异步响应数据。首先,将长轮询请求任务 LongPollingClient 扔到 BlocingQueue 中,并且开启调度任务,60s 后执行,这样做的目的是 60s 后将该长轮询请求移除队列,即便是这段时间内没有发生配置数据变更。因为即便是没有配置变更,也得让网关知道,总不能让其干等吧,而且网关请求配置服务时,也有 90s 的超时时间。
public void doLongPolling(final HttpServletRequest request, final HttpServletResponse response) {
// 因为soul-web可能未收到某个配置变更的通知,因此MD5值可能不一致,则立即响应
List<ConfigGroupEnum> changedGroup = compareMD5(request);
String clientIp = getRemoteIp(request);
if (CollectionUtils.isNotEmpty(changedGroup)) {
this.generateResponse(response, changedGroup);
return;
}
// Servlet3.0异步响应http请求
final AsyncContext asyncContext = request.startAsync();
asyncContext.setTimeout(0L);
scheduler.execute(new LongPollingClient(asyncContext, clientIp, 60));
}
class LongPollingClient implements Runnable {
LongPollingClient(final AsyncContext ac, final String ip, final long timeoutTime) {
// 省略......
}
@Override
public void run() {
// 加入定时任务,如果60s之内没有配置变更,则60s后执行,响应http请求
this.asyncTimeoutFuture = scheduler.schedule(() -> {
// clients是阻塞队列,保存了来处soul-web的请求信息
clients.remove(LongPollingClient.this);
List<ConfigGroupEnum> changedGroups = HttpLongPollingDataChangedListener.compareMD5((HttpServletRequest) asyncContext.getRequest());
sendResponse(changedGroups);
}, timeoutTime, TimeUnit.MILLISECONDS);
//
clients.add(this);
}
}
如果这段时间内,管理员变更了配置数据,此时,会挨个移除队列中的长轮询请求,并响应数据,告知是哪个 Group 的数据发生了变更(我们将插件、规则、流量配置、用户配置数据分成不同的组)。网关收到响应信息之后,只知道是哪个 Group 发生了配置变更,还需要再次请求该 Group 的配置数据。有人会问,为什么不是直接将变更的数据写出?我们在开发的时候,也深入讨论过该问题,因为 http 长轮询机制只能保证准实时,如果在网关层处理不及时,或者管理员频繁更新配置,很有可能便错过了某个配置变更的推送,安全起见,我们只告知某个 Group 信息发生了变更。
// soul-admin发生了配置变更,挨个将队列中的请求移除,并予以响应
class DataChangeTask implements Runnable {
DataChangeTask(final ConfigGroupEnum groupKey) {
this.groupKey = groupKey;
}
@Override
public void run() {
try {
for (Iterator<LongPollingClient> iter = clients.iterator(); iter.hasNext(); ) {
LongPollingClient client = iter.next();
iter.remove();
client.sendResponse(Collections.singletonList(groupKey));
}
} catch (Throwable e) {
LOGGER.error("data change error.", e);
}
}
}
当 soul-web 网关层接收到 http 响应信息之后,拉取变更信息(如果有变更的话),然后再次请求 soul-admin 的配置服务,如此反复循环。
快速使用
get
soul-admin.jarstart
soul-admin.jarjava -jar soul-admin.jar -Dspring.datasource.url="your mysql url"
-Dspring.datasource.username='you username' -Dspring.datasource.password='you password'visit : http://localhost:8887/index.html username:admin password :123456
get
soul-bootstrap.jarstart
soul-bootstrap.jarjava -jar soul-bootstrap.jar
仓库地址
github: https://github.com/Dromara/soul
gitee: https://gitee.com/shuaiqiyu/soul
项目主页上还有视频教程,有需要的朋友可以去观看。
最后
此文介绍了soul作为一个高可用的微服务网关,为了优化响应速度,在对配置规则选择器器数据进行本地缓存的三种方式,学了此文,我相信你对现在比较流行的配置中心有了一定的了解,看他们的代码也许会变得容易,我相信你也可以自己写一个分布式配置中心出来。3.0版本已经在规划中,肯定会给大家带来惊喜。













