
TiDB 压力测试报告
(转载自公众号DBATech)
一、测试环境
1、tidb 集群架构:
测试使用最基本的TiDB架构。即 3个tidb-server节点+ 3个tikv节点 + 3个pd节点。
2、tidb集群的部署环境(混合部署):
192.168.xx.A 1*server +1*PD +1*tikv
192.168.xx.B 1*server +1*PD +1*tikv
192.168.xx.C 1*server +1*PD+1*tikv
IDC机器环境:
0S :CentOS7
CPU :Intel(R) Xeon(R) CPU E5-2620 v3 @ 2.40GHz *24
RAM :48GB
DISK :SSD, 480GB RAID0
TiDB 重要配置参数
以下这些参数都是会对tidb造成性能影响的参数。设置尽量折中。较少对性能的影响。
tidb-server节点的设置:
[log]
level = "warn"
[prepared-plan-cache]
enabled = true
log-level = "warning"
[raftstore]
sync-log = false
tikv节点的设置:
log-level = "warning"
[rocksdb.defaultcf]
[rocksdb.writecf]
block-cache-size = "6GB" #关于写的缓存块大小 大概设置为读的1/3
max-background-jobs = 8 #后台线程,用于压缩数据与刷新数据
[raftstore]
sync-log = false
[storage.block-cache]
capacity = "20GB" # 3.0之后 tikv的缓存,包括 rocksdb.defaultcf rocksdb.writecf rocksdb.lockcf raftdb.defaultcf 都由改参数设置,缓存共享。
集群正常启动后,在每个节点执行以下语句,关闭 失败事务重试。
set global tidb_disable_txn_auto_retry = off
3、sysbench client:
6 台机器 sysbench client (配置与tidb-server机器一模一样)。每次测试6个机器同时发起6个sysbench进程。sysbech client 均匀连接到 3 tidb-server节点上(每2台sysbench client 连接一个tidb-server节点)
由于测试由6个机器并发发起,因此执行结果的 TPS QPS error reconnects 是 6 个sysbench client 之和。min max 为 6个节点的最小于最大值。avg 95th 为6个节点值的平均值。
sysbench 压测语句如下:
sysbench /usr/share/sysbench/oltp_read_write.lua --mysql-host=xxxx --mysql-port=xxxx --mysql-user=xxxx --mysql-password=xxxx --mysql-db=sysbench --db-driver=mysql --tables=50 --table-size=10000000 --report-interval=1 --threads=[线程从2-24变化] --rand-type=uniform --time=300 --max-requests=0 run
说明:每个sysbech client一次发起长达300秒测试。--max-requests=0 表示不限制测试达到的总qps。
测试数据准备:
sysbench /usr/share/sysbench/oltp_read_write.lua --mysql-host=xxxx --mysql-port=xxxx --mysql-user=xxxx --mysql-password=xxxx --mysql-db=sysbench --db-driver=mysql --tables=50 --table-size=10000000 --report-interval=100 --threads=24 --rand-type=uniform --time=0 --max-requests=0 prepare
数据量:50张表,每个表1000万数据。大约200GB数据。缓存参数capacity为20GB。缓存与持久化数据比例 大约为1:10
5 测试脚本:
本猿编写一小py小脚本( https://github.com/jiasirVan/dbtool/blob/master/bench2.py ) 。
配置文件sysbench.cnf:
[mysql]
ip=192.168.xx.x
port=xxxx
user=xxxx
password=xxxx
dbname=sysbench
[sysbench]
#生成的表数量
table_amount=50
#限制总的执行时间(秒) 0表示不限制
exectime=300
#每个表初始化多少行数据
rows=10000000
#请求的最大数目。默认为1000000,0代表不限制
max_request=0
#每n秒输出一次测试进度报告
interval=10
#指定sysbench的输出日志目录
logdir=/tmp/log
##并发压测的线程数
threadnumber=2,4,6,8,10,12,14,16,18,20,22,24
#指定用哪个lua脚本测试
lua_script=/usr/share/sysbench/oltp_update_index.lua
执行脚本:./bench2.py -c sysbench.cnf -r -f
测试结果直接格式化输出,大约如下(每一行为配置文件的一个threadnumber值,例如以下的2,4,6线程的输出)。
输出结果:
TPS QPS error/s reconnects/s min avg max 95th
110.98 1775.60 0.00 0.00 10.95 18.02 164.74 23.10
250.54 4008.68 0.00 0.00 9.72 15.96 243.09 19.65
415.15 6642.39 0.00 0.00 9.04 14.45 281.74 18.28
二、sysbench测试说明:
sysbench mysql 的测试类型:
#1. bulk_insert.lua 批量写入操作
#2. oltp_delete.lua 写入和删除并行操作
#3. oltp_insert.lua 纯写入操作
#4. oltp_point_select.lua 只读操作,条件为唯一索引列
#5. oltp_read_only.lua 只读操作,包含聚合,去重等操作 大多数情况用于统计的压测
#6. oltp_read_write.lua 读写混合操作,最常用的脚本 用于oltp系统的压测。
#7. oltp_update_index.lua 更新操作,通过主键进行更新
#8. oltp_update_non_index.lua 更新操作,不通过索引列
#9. oltp_write_only.lua 纯写操作,常用脚本,包括insert update delete
#10. select_random_points.lua 随机集合只读操作,常用脚本,聚集索引列的selete in操作
#11. select_random_ranges.lua 随机范围只读操作,常用脚本,聚集索引列的selete between操作
注:因为sysbench测试客户端机器与tidb服务器都在同机房。网络ping延迟大约为0.08ms 。可以忽略不计。
三 、开始测试
说明:所有的tidb-server与 sysbench 测试机器在同机房,多次ping 网络延迟大约在0.08ms左右,可以忽略不计。
1、唯一索引只读压测:
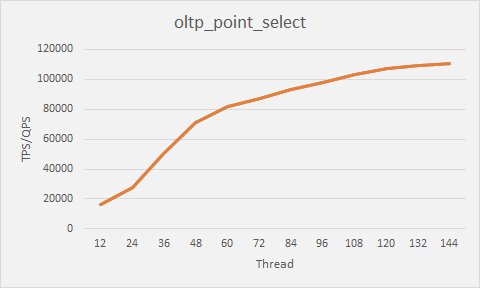
结论: 唯一索引读是数据库最高效的查询操作。从上图看,唯一索引select 的qps 在 client thread 并发达到 108 之后增长趋于平缓。大约qps在10万左右。平均时延也相对较低。在1ms以下。越大的并发,平均qps时延增加。
2、只读压测(包括聚合,去重,关联等复杂查询
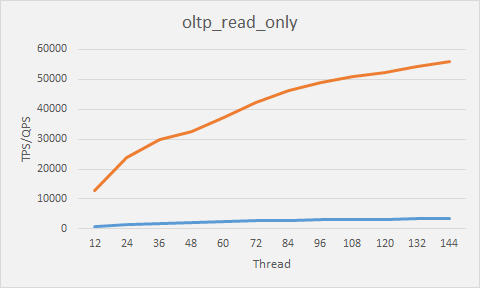
结论:以上是各类读操作,包括 聚合,关联,去重等复杂的select操作的压测结果。比较符合分析系统型压测。根据上图压测,QPS 在 client thread 108 之后增长趋于平缓。QPS 大约在55000左右。
3、读写混合测试(读写比例为默认的7:3):
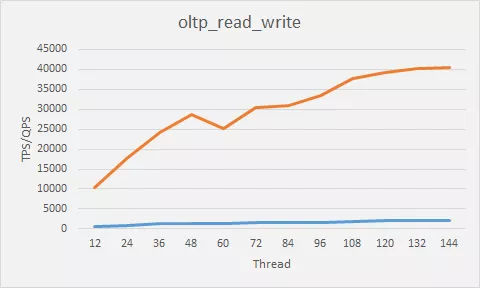
结论:读写混合压测针对OLTP在线系统,压测结果展示 ,大约在 client thread 为108并发之后,QPS增长趋于平缓。在 40000左右。时延随着并发数的增加不断的增大。
4、总结:
通过以上压测。架构为 3 tikv + 3 tidb-server+ 3 pd 架构的tidb分布式集群 在给定环境的下性能表现很好。client thread 并发支持在108 线程达到最大。继续增大并发,QPS 增长并不明显,会增大操作时延。在读写混合型的oltp系统中,QPS 达到 40000万左右。并发上比mysql更优,得益于tidb的分布式架构。但对于单个简单查询语句,mysql的响应时间更快。在大部分OLTP 系统上,都是简单select操作,tidb的响应时间在1毫秒一下。与mysql 相差不大。但 tidb 的分布式架构 支持更好的横向扩展。











