GIT 存储格式与运用
在 GIT 的实现规范中,存储格式是非常简单而且高效的,一个代码托管平台通常需要 基于这些特性实现一非常有意思的功能。在本文中,将介绍基于 GIT 存储库格式实现的 仓库体积限制与大文件检查。
存储库的布局
正常的 GIT 存储库布局应当遵循 GIT 规范 Git Repository Layout 一个 GIT 仓库包括如下两种风格:
.git目录存在于工作目录的根目录中。<project>.git这种是一个裸仓库,没有工作目录,服务器上存储的就是这种。
特别注意的是,如果是一个 子模块 (submodule) .git 回是一个文件,文件内容为 gitdir:/path/to/gitdir
下文是一个表格,关于目录结构和描述信息。
路径
目录(D)\ 文件 (F)
描述
objects
D
松散对象和包文件
refs
D
引用,包括头引用,标签引用,和远程引用
packed-refs
F
打包的引用,通常运行 git gc 后产生
HEAD
F
当前指向的引用或者 oid,例如 ref: refs/heads/master
config
F
存储库的配置,可以覆盖全局配置
branches
D
-
hooks
D
请查看 Documentation/githooks.txt
index
F
git index file, Documentation/technical/index-format.txt
sharedindex.<SHA-1>
F
-
info
D
存储库信息,哑协议依赖 info/refs
remotes
D
-
logs
D
运行 git log 可以查看提交记录
shallow
F
-
commondir
D
-
modules
D
子模块的 git 目录
worktrees
D
工作目录,更新后的文档与 git 多个工作目录有关
对于一些实际上使用非常少的路径,我就没有添加说明了。
松散文件格式
在 objects 目录中,有 00,01,...ff 这样的目录,目录下存储着文件名长度为38的二进制文件,这些文件就是松散文件, git 创建提交时,修改的文件,更新的目录树,以及提交内容会被压缩后写入到这些目录中,成为一个个松散文件,当需要传输 或者运行 gc 时,这些文件就会被写入到 pack 文件中。
对象文件使用的压缩算法是 deflate,增加一个新的对象文件时,先要计算这个文件的 hash 值(原始长度 20,16 进制长度 40 个字符), 这个根据这个值查找文件是否存在这些个目录或者 pack 文件中,不存在则创建前缀目录(hash 值 16 进制字符串前两个),然后、 将原始文件的类型以及长度信息以及内容一起压缩,写入到磁盘,文件名是 hash 值的 16 进制的后 38 个字符。
通过解压缩可以得到符合下面格式的文件:
type SP digest NUL body
其中类型是 commit blob tree 而长度则是 10 进制的数字,以字节为单位。后面的 body 就是各种类型文件的内容。
commit 内容是纯文本的,有 tree ,这个 tree 也就是根的 tree,然后有 一个 到多个 parent,这与 git merge 方向有关, 还有作者,提交者,以及提交信息。这里的 oid 是 16 进制的。
tree bbe101c40b962d8b8977b34d0eb8bf12bb9e9679
parent 789808fe48670f2fce59da45a82a2a18f489e300
author Junio C Hamano <gitster@pobox.com> 1467837778 -0700
committer Junio C Hamano <gitster@pobox.com> 1467837778 -0700
Third batch of topics for 2.10
Signed-off-by: Junio C Hamano <gitster@pobox.com>
blob 就是真实的文件。
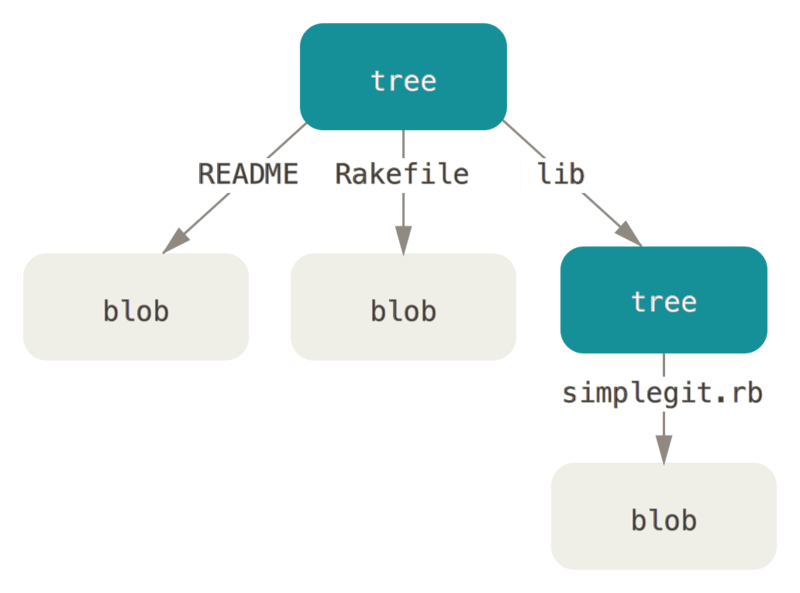
而 tree 就是将文件按目录结构和属性组织起来,在 tree 中每一个 tree entry 可能是 blob, 也可能是 tree,也有可能是 commit,在有 submodule 的情况下就有 commit。commit 指向的是一个提交, 仅通过此 commit 并不能获取完整的资源,在工作目录的根下,当项目存在 submodule 时,会有一个 .gitmodules git submodule 在先要注册到 git config 中,然后克隆到 .git/modules 目录,然后 git 依据 tree 中的 commit 检出。 如果是新增的 submodule 将会检出对应仓库的 HEAD 指向的引用。
这里的 oid 是原始的。可执行的 blob 和普通的 blob 存储时并无大的差别,主要的差别体现在 tree 的 unix 目录项。
100644 blob 33d07c06bd90833ce56bc64c13bdc08c1997c3fb .gitattributes
100644 blob 6483b21cbfc73601602d628a2c609d3ca84f9e53 .gitignore
100755 blob a88b6824b908d89ee185b84ed92b9c122b0118dd GIT-VERSION-GEN
100644 blob 4f00bdd3d69babe8a58c4989406eaa6fb5f36a50 Makefile
100755 blob 4277f30c4116faf2788243af4ec23f1d077698e8 git-gui--askpass
100755 blob 11048c7a0e94f598b168de98d18fda9aea420c7d git-gui.sh
040000 tree 1ead6a96af286100752067ea1849d49b35ce1d35 lib
040000 tree 452280d7fa4a155bd311a7cce7e327964267b792 macosx
040000 tree 2294a6a975b861ecdb5b03d091877c14ec696621 po
040000 tree ae99a38593d127e47f956d96abf3d6a40d3aff66 windows
在 Git-SCM 中,有例图显示了这种结构:
如何解压对象文件?大多数语言都绑定了 zlib,放心去使用即可。
比如 C# 有 System.IO.Compression 有 System.IO.Compression.DeflateStream 类,就可以拿过来使用。 如果是 C++ 直接使用 zlib 中 z_stream 即可,Linux Unix 都带了,然后 Visual Studio 可以使用 NuGet 安装到项目中,可以使用。
那么计算 HASH 呢?OpenSSL 提供了 hash 函数,大多数 Linux 和 Unix 都带了,可以使用,在 Windows 中也可以使用 OpenSSL, 当然也可以使用 Windows 自带的加密算法动态库 bcrypt.dll,你也可以在网上找到一个 SHA-1 算法的实现。
Pack 文件格式
Pack 文件的设计使得 git 仓库可以更好的节省磁盘空间,有利于服务器之间传输数据。
Pack 文件
文档地址:Git pack format
pack 文件的第一部分是签名 {'P','A','C','K'} 4 字节,正如 zip 文件带有 PK 一样。
第二部分是 4 字节(网络字节序)版本号,这里需要使用 ntohl 来转成本机的,x86\amd64 是小端的。
第三部分是 4 字节(网络字节序)对象数目。
然后就是对象条目,3 bit 类型,然后根据类型判断长度字符串的 bit 长度。然后计算长度。 其中类型包括松散对象的所有类型,还包括
(undeltified representation)
n-byte type and length (3-bit type, (n-1)*7+4-bit length)
compressed data
(deltified representation)
n-byte type and length (3-bit type, (n-1)*7+4-bit length)
20-byte base object name if OBJ_REF_DELTA or a negative relative
offset from the delta object's position in the pack if this
is an OBJ_OFS_DELTA object
compressed delta data
最后,是 20-byte SHA-1 校验码。
Idx 文件
如果直接去解析 pack 文件是很麻烦的一件事,而我们只需要将大文件扫描出来,并不需要做其他工作, 所以,我们可以了解 idx 文件格式,然后做出一些取舍。
idx 文件的格式也在 pack 文件格式文档中。
idx 文件有两个版本,第一版基本不怎么使用了,所以这里讲的是第二版。
第一部分是 魔数 \377tOc 4-byte
第二部分是 版本号 网络字节序,目前是 2。
第三部分是 256 个扇出表 (fan-out table),这个与版本 1 一致。每一个是 4 byte 网络字节序。 比如第一个代表 前缀 00 的 对象有多少个, 前 255 个都是对应的对象序号有多少个,并没有 ff 对应的 有多少个对象,最后一项表示所有的对象数目。扇出表总共占用 256*4 字节。
第四部分是 按顺序排列的 20 字节对象 sha-1,每一个 占用 20-byte,共计 total*20-byte。
第五部分是 按顺序排列的 4 字节 crc 校验马,总共 total*4-byte。
第六部分是 按顺序排列的 4 字节 pack 偏移(网络字节序),总共 total*4-byte 这就意味着普通的 pack 文件 无法存储超过 4 GB 大小的文件。
第七部分是 8 字节偏移条目,大多数不要参照此文件。
最后依然是校验码。
仓库大小限制和文件大小检测
首先讲的是仓库大小,对于 git 而言,最重要的数据是 objects 和 refs,只要拥有这些数据,就可以恢复出一个完整的仓库。 而对仓库做大小限制,则只需要检测 objects 目录大小即可。
通常来说在 linux 中,可以使用 du -sh 查看目录占用磁盘空间大小。在 Windows 中有多种方式,可以使用 Sysinternals 的 du 工 具,运行 du -sh 一样 OK。 (Sysinternals 创始人之一 Mark Russinovich 现是 Microsoft Azure CTO)
这里值得注意的是在 Linux 中,目录同样占用空间,4096 字节,无论是目录还是文件,占用的的大小一定是块大小的整倍数。 即 S_BLKSIZE,这里是 512。
下面有两段代码,分别是 unix like 和 Windows 扫描目录大小。
在 Unix/Linux 或者 Bash On Windows 中,可以使用下面这个例子
class ScanningFolder {
public:
bool FolderSizeResolve(const std::string &dir__) {
DIR *dir = opendir(dir__.c_str());
if (dir == nullptr) {
fprintf(stderr, "opendir: %s\n", strerror(errno));
return false;
}
// folder self
size_ += 4096;
dirent *dirent_ = nullptr;
while ((dirent_ = readdir(dir))) {
if (dirent_->d_type & DT_REG) {
std::string file = dir__ + "/" + dirent_->d_name;
struct stat stat_;
if (stat(file.c_str(), &stat_) != 0) {
fprintf(stderr, "ERROR: %s\n", strerror(errno));
closedir(dir);
return false;
} else {
// S_BLKSIZE 512
size_ += stat_.st_blocks * S_BLKSIZE;
}
} else if (dirent_->d_type & DT_DIR) {
if (strcmp(dirent_->d_name, ".") == 0 ||
strcmp(dirent_->d_name, "..") == 0) {
continue;
}
std::string newdir = dir__ + "/" + dirent_->d_name;
if (!FolderSizeResolve(newdir)) {
closedir(dir);
return false;
}
}
}
closedir(dir);
return true;
}
uint64_t Size() const { return this->size_; }
private:
uint64_t size_ = 0;
};
当然也可以使用 ftw 这样的函数,不过并不一定高效,比如 libc musl 就是使用 opendir 来 实现的 ftw。这样一来性能反而下降了。
在 Windows 中,遍历目录可以使用 FindFirstFile/FindNextFile 这个两个 API。
class FolderSize {
public:
FolderSize(const std::wstring &dir) : size_(-1) {}
int64_t Size() const { return size_; }
private:
bool TraverseFolder(const std::wstring &dir) {
WIN32_FIND_DATAW find_data;
HANDLE hFind = FindFirstFileW(dir.c_str(), &find_data);
if (hFind == INVALID_HANDLE_VALUE) {
return false;
}
while (true) {
if (find_data.dwFileAttributes & FILE_ATTRIBUTE_DIRECTORY) {
if (wcscmp(find_data.cFileName, L".") != 0) {
std::wstring xdir = dir;
xdir.push_back('\\');
xdir.append(find_data.cFileName);
TraverseFolder(xdir);
}
} else {
size_ +=
((int64_t)find_data.nFileSizeHigh << 32 + find_data.nFileSizeLow);
}
if (!::FindNextFileW(hFind, &find_data)) {
break;
}
}
FindClose(hFind);
return true;
}
int64_t size_;
};
然后就是文件大小检测,通常有两个指标,一个是压缩前的大小,一个是压缩后的大小。
对于松散文件,不依赖第三方库,我们可以使用 zlib 去查看松散对象的大小。如果只要检测压缩后的大小,实际上在遍历目录的 时候就可以使用 stat 的 st_size 参数获得实际大小。
对于 pack 文件中的大小,通常计算起来比较麻烦,由于我们对文件大小的差异容忍度很高,我们实际上可以使用 idx 偏移值去计算。 先取得 pack 文件大小,然后读取 idx 中所有的 sha 值与偏移值。然后对偏移值使用 sort 排序,由大到小,最后使用 前一个偏移值 减去后一个偏移值即可得到近似大小。其中,第一个要使用 (packsize-20) 去减。比如码云限制文件大小,警告是 50M,错误时 100 M, 由于 pack 得到的时压缩后的大小,实际上误差也就可以忽略不计了。如果需要使用原始大小可以使用 libgit2 去实现。
偏移值计算时,数据结构的使用非常重要,在 fan-out table 的最后一个中,已经得知所有对象的数目,便可以使用 vector 之类的容器, 与 list 相比,笔者在扫描 2 GB 的 FreeBSD 仓库对象,共计 300 W 个对象,其中使用 list 是 7s,而 vector 是 3s,运行环境是 12 年笔记本。 i3 处理器,机械硬盘。Windows(Bash On Windows)。
关于实际大小和压缩后的大小,zlib 的压缩可大可小,一般而言传输和存储时都是压缩后的文件,所以在实现代码托管业务时, 限制大小的策略应当侧重于压缩后的大小。
最后
关于 GIT 存储的研究是作为 Native-Hook 的一部分,与钩子相关的内容本次就没有写了。
关于本文的 git pages: http://ipvb.oschina.io/git/2016/07/10/GitStorage/