
1.起点Hello World
val sc = new SparkContext("spark://...", "Hello World", "SPARK_HOME路径", "APP_JAR路径")
val file = sc.textFile("hdfs:///root/Log")
val filterRDD = file.filter(_.contains("Hello World"))
filterRDD.cache()
filterRDD.count()
第 1 行:在Spark中做任何操作,首先要创建一个Spark的上下文。
第 2 行:通过sc变量,利用textFile接口从HDFS文件系统读入Log文件,返回一个变量file。
第 3 行:对file变量进行过滤操作。判断每一行字符串是否包含“Hello World”字符串,生成新的变量filterRDD。
第 4 行:对filterRDD进行cache操作,以便后续操作重用filterRDD这个变量。
第 5 行:对filterRDD进行count计数操作,最后返回包含“Hello World”字符串的文本行数。
短短五行程序,却包含了Spark中很多重要的概念。下面逐一介绍Spark编程中的重要概念。
弹性分布式数据集RDD(Resilient Distributed DataSets):程序中的file和filterRDD变量都是RDD。
创建操作(creation operation):RDD的初始创建都是由SparkContext来负责的,将内存中的集合或者外部文件系统作为输入源。
转换操作(transformation operation):将一个RDD通过一定的操作变换成另一个RDD,比如file通过filter操作变换成filterRDD,所以filter就是一个转换操作。
控制操作(control operation):对RDD进行持久化。可以让RDD保存在磁盘或者内存中,以便后续重复使用。比如cache接口默认将filterRDD缓存在内存中。
行动操作 (action operation):由于Spark是惰性计算(lazy computing)的,所以对于任何RDD进行操作,都会出发Spark作业的运行,从而产生最终的结果。例如对filterRDD进行的count操作就是一个行动操作。Spark中的行动操作基本分为两类,一类操作结果变成Scala集合或者标量,另一类就将RDD保存到外部文件或者数据库系统中。
对于一个Spark数据处理程序而言,一般情况下RDD与操作之间的关系如下图所示,经过创建操作、转换操作、控制操作、行动操作来完成一个作业。当然在一个Spark应用程序中,可以有多个行动操作,也就是有多个作业存在。

2.RDD的五个接口
=============
RDD是弹性分布式数据集,即一个RDD代表一个被分区的只读数据集。一个RDD的生成只有两种来源,在Hello World中已有所提现:
来自内存集合和外部存储系统
通过转换操作来自于其他RDD
RDD没必要随时被实例化。由于RDD的接口只支持粗粒度的操作(即一个操作会被应用到RDD的所有数据上),所以只要通过记录下这些作用在RDD上的转换操作,来构建RDD的继承关系(lineage),就可以有效的进行容错处理,而不需要将实际的RDD数据进行拷贝。这对于RDD来说是一项非常强大的功能。也即是在一个Spark应用程序中,我们所用到的每个RDD,在丢失或者操作失败后都是可以重建的。
应用程序开发者还可以对RDD进行另外两个方面的控制操作:持久化和分区。
开发者可以指明需要重用哪些RDD,选择一种存储策略(例如in-memory storage)将它们保存起来,以备使用。
开发者还可以让RDD根据记录中的键值在集群的机器之间重新分区。这对于RDD的位置优化是非常有作用的。例如让将要进行join操作的两个数据集以同样的方式进行哈希分区。
如何表示这样一个分区、高效容错、支持持久化的分布式数据集呢?一般情况下抽象的RDD需要包含以下五个接口:
partition
分区,一个RDD会有一个或者多个分区
preferredLocations(p)
对于分区p而言,返回数据本地化计算的节点
dependencies()
RDD的依赖关系
compute(p, context)
对于分区p而言,进行迭代计算
partitioner()
RDD的分区函数
2.1RDD分区(partitions)
对于一个RDD而言,分区的多少涉及对这个RDD进行并行计算的粒度,每一个RDD分区的计算操作都在一个单独的任务中被执行。
对于RDD分区而言,用户可以自行指定多少分区,如果未指定就会使用默认值。可以利用RDD的成员变量partitions所返回的partition数组的大小来查询一个RDD被划分的分区数。例如,我们利用spark-shell交互式命令终端测试一下:
指定分区数的情况:
scala> val rdd = sc.parallelize(1 to 100, 2)
scala> rdd.partitions.size

未指定分区数的情况:(系统默认的分区数是这个程序所分配到的资源的CPU核的个数)
scala> val rdd = sc.parallelize(1 to 100)
scala> rdd.partitions.size

2.2RDD优先位置(preferredLocations)
RDD优先位置属性与Spark中的调度有关,返回的是此RDD的每个partition所存储的位置,按照“移动数据不如移动计算”的理念,在Spark进行任务调度的时候,尽可能的将任务分配到数据块所存储的位置。
以从Hadoop中读取数据生成RDD为例,preferredLocations返回每一个数据块所在的机器名或者IP地址,如果每一块数据是多份存储的,那么就会返回多个机器地址。
scala> var rdd = sc.textFile("hdfs://master:9000/input/wordcount.txt")
scala> val hadoopRDD = rdd.dependencies(0).rdd
scala> hadoopRDD.partitions.size
scala> hadoopRDD.preferredLocations(hadoopRDD.partitions(0))

2.3RDD依赖关系(dependencies)
由于RDD是粗粒度的操作数据集,每一个转换操作都会生成一个新的RDD,所以RDD之间就会形成类似于流水线一样的前后依赖关系。在Spark中存在两种类型的依赖:窄依赖(Narrow Dependencies)、宽依赖(Wide Dependencies)。
窄依赖:每一个父RDD的分区最多只被子RDD的一个分区所使用。
宽依赖:多个子RDD的分区依赖于同一个父RDD的分区。

在Spark中明确区分这两种依赖关系有两个方面的原因:
窄依赖可以在集群的一个节点上如流水线般执行,可以计算所有父RDD的分区;
宽依赖需要取得父RDD的所有分区上的数据进行计算,将会执行类似于MapReduce一样的Shuffle操作。
窄依赖在节点计算失败后的恢复会更加有效,只需重新计算对应的父RDD的分区,而且可以在其它节点并行计算;
在宽依赖的继承关系中,一个节点的失败将会导致其父RDD的多个分区重新计算,这个代价是非常高的。

2.4RDD分区计算(compute)
对于Spark中每个RDD的计算都是以partition(分区)为单位的,而且RDD中的compute函数都是在对迭代器进行复合,不需要保存每次计算的结果。
在下面程序中,rdd变量是一个被分成两个分区的1~10集合,在rdd上连续进行转换操作map和filter,由于compute函数只返回相应分区数据的迭代器,所以只有最终实例化时才能显示出两个分区的最终计算结果。
?
2.5RDD分区函数(partitioner)
在Spark中目前实现了两种类型的分区函数:HashPartitioner(哈希分区)和RangePartitioner(区域分区)。需要注意的是partitioner这个属性只存在于(K, V)类型的RDD中,对于非(K, V)类型的partitioner的值就是None。partitioner函数既决定了RDD本身的分区数量,也可以作为父RDD Shuffle输出(MapOutPut)中每个分区进行数据切割的依据。
下面以HashPartitioner为例说明partitioner的功能。
?
3.RDD的四种操作
=============
3.1创建操作
集合创建操作:RDD可以由内部集合来生成,Spark提供了两类函数来实现:parallelize和makeRDD。
存储创建操作:Spark整个生态系统与Hadoop完全兼容,Hadoop支持的文件类型或者数据库类型,它同样支持。
3.2转换操作
基本转换操作:
**map[U: classTag](f: T => U): RDD(U)**:将RDD中类型为T的元素一对一地映射为类型为U的元素。
**distinct(): RDD[T]**:返回RDD中所有不一样的元素。
**flatMap[**U: classTag**](f: T => TraversableOnce[U]): RDD[U]**:将RDD中的每一个元素进行一对多转换。
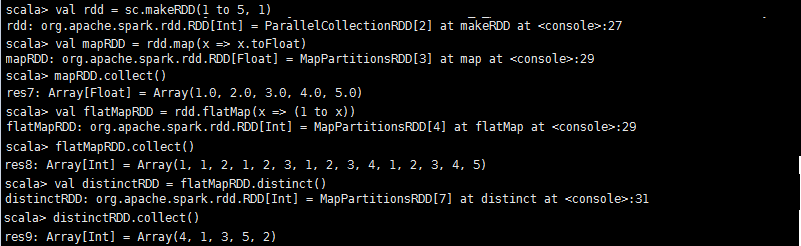
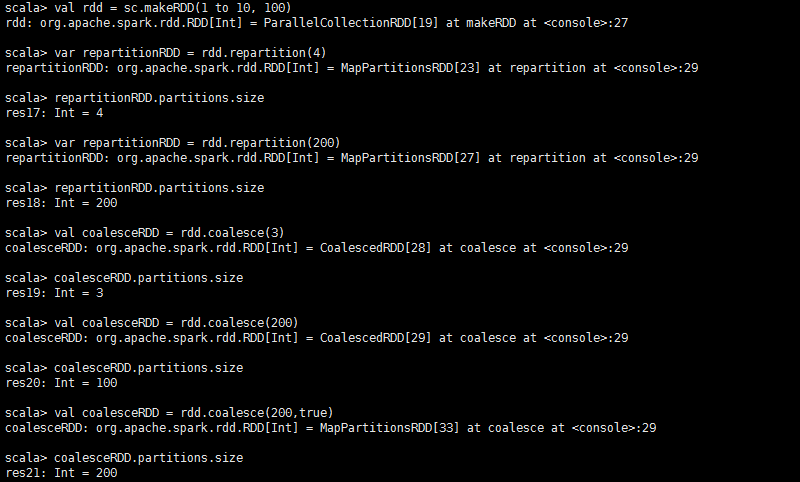
**repartition(numPartitions: Int): RDD[T]**:相当于coalesce函数中shuffle=true时的简易实现。
coalesce(******numPartitions: Int,shuffle: Boolean=false): RDD[T]**:对RDD的分区进行重新分区。
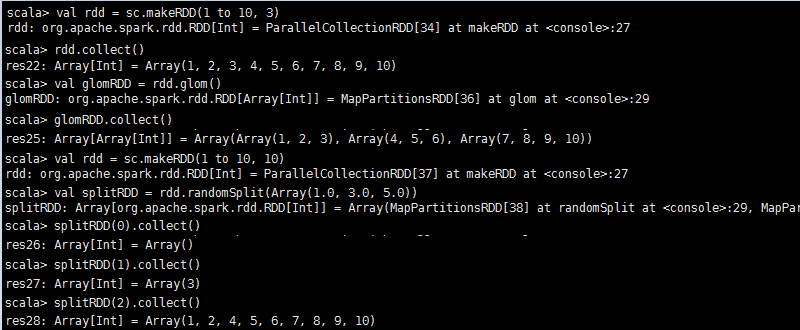
**randomSplit(weights: Array[Double],seed: Long=System.nanoTime): Array[RDD[T]]**:根据weights权重将一个RDD切分成多个RDD。
**glom():RDD[Array[T]]**:将RDD每一个分区中类型为T的元素转换成Array[T],这样每一个分区就只有一个数组元素。
**union(other: RDD[T]): RDD[T]**:将两个RDD集合中的数据进行合并,不会去重。
intersection(other: RDD[T]): RDD[T]****:返回两个RDD集合中的数据的交集,不含重复元素。
intersection(other: RDD[T], partitioner: Partitioner): RDD[T]****:同上
****subtract(other: RDD[T]): RDD[T]****:返回在主RDD集合中出现但不在other中出现的元素。
subtract(other: RDD[T], partitioner: Partitioner): RDD[T]****:同上

mapPatitions[U: ClassTag](f: Iterator[T] => Iterator[U], preservesPartiton: Boolean=false): RDD[U]
mapPatitionsWithIndex[U: ClassTag](f: (Int, Iterator[T]) => Iterator[U], preservesPartiton: Boolean=false): RDD[U]
?
**zip[U: ClassTag](other: RDD[U]): RDD[(T,U)]**:将两个RDD组成Key/Value形式的RDD,但它们的分区数量和元素数量必须相同,否则相同系统会抛出异常
**zipPartitons(参数分多种情况,不一一列举了)**:将多个RDD按照分区组成新的RDD,分区数相同,元素数没有要求。
?
**zipWithIndex(): RDD[(T,Long)]**:将RDD中的元素和这个元素的ID组成键/值对。
**zipWithUniqueId(): RDD[(T,Long)]**:将RDD中的元素和一个唯一的ID组成键/值对。
键值RDD转换操作
**partitionBy(partitioner: Partitioner): RDD[(K,V)]**:根据partitioner函数生成新的ShuffledRDD,原RDD重新分区
**mapValues[U](f: V=>U): RDD[(K,U)]**:针对[K,V]中的V进行map操作。
**flatMapValues[U](f: V=>TraversableOnce[U]): RDD[(K,U)]**:针对[K,V]中的V进行flatMap操作。
combineByKey(3个方法参数不同):
**foldByKey(3个方法参数不同)**:
**reduceByKey(3个方法参数不同)**:
**groupByKey(3个方法参数不同)**:
cogroup**(3个方法参数不同)**:
join(3个方法参数不同):
leftOuterJoin(3个方法参数不同):
rightOuterJoin(3个方法参数不同):
subtractByKey(3个方法参数不同):
3.3控制操作
**cache(): RDD[T]**:
persist(): RDD[T]****:
**persist(level: StorageLevel): RDD[T]**:
在Spark中对RDD进行持久化操作是一项非常重要的功能,可以将RDD持久化在不同层次的存储介质中,以便后续的操作能够重复使用,这对iterative(迭代)和interactive(交互)的应用来说会极大的提高性能。
checkpoint:
checkpoint接口是将RDD持久化在HDFS中,与persist(如果也持久化在磁盘上)的一个区别是checkpoint将会切断此RDD之前的依赖关系,而persist接口依然保留着RDD的依赖关系。checkpoint的主要作用有如下两点:
(1)如果一个Spark程序会长时间驻留运行(如Spark Streaming一般会7*24小时运行),过长的依赖将会占用很多系统资源,定期将RDD进行checkpoint操作,能够有效地节省系统资源。
(2)维护过长的依赖关系还会出现一个问题,如果Spark在运行过程中出现节点失败的情况,那么RDD进行容错重算的成本会非常高。
3.4行动操作
行动操作是和转换操作相对应的一种对RDD的操作类型,在Spark程序中每调用一次行动操作,都会触发一次Spark的调度 并返回相应的结果。从API来看,行动操作可以分为两种类型:
行动操作将标量或者集合返回给Spark的客户端程序,比如返回RDD中数据集的数量或者一部分符合条件的数据。
first:返回RDD中的第一个元素。
count:返回RDD中元素的个数。
**reduce(f: (T,T)=>T)**:对RDD中的元素进行二元计算,返回计算结果。
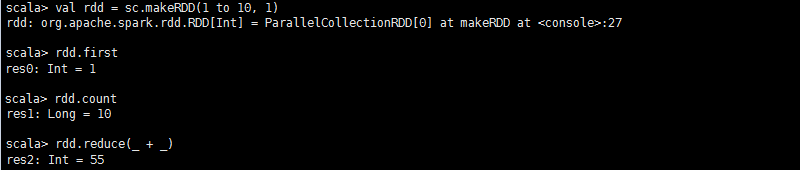
**collect()/toArray()**:以集合形式返回RDD的元素。
**take(num: Int)**:将RDD作为集合,返回集合中[0, num-1]下标的元素。
**top(num: Int)**:按照默认的或者指定的排序规则,返回前num个元素。
**takeOrdered(num: Int)**:以与top相反的排序规则,返回前num个元素。

**aggregate[U](zeroValue: U)(seqOp: (U,T)=>U, combOp(U,U)=>U)**:aggregate行动操作中主要需要提供两个函数。一个是seqOp函数,其将RDD(元素类型为T,可以和U为同一类型)中的每一个分区的数据聚合成类型为U的值。另一个函数combOp将各个分区聚合起来的值合并在一起得到最终类型为U的返回值。
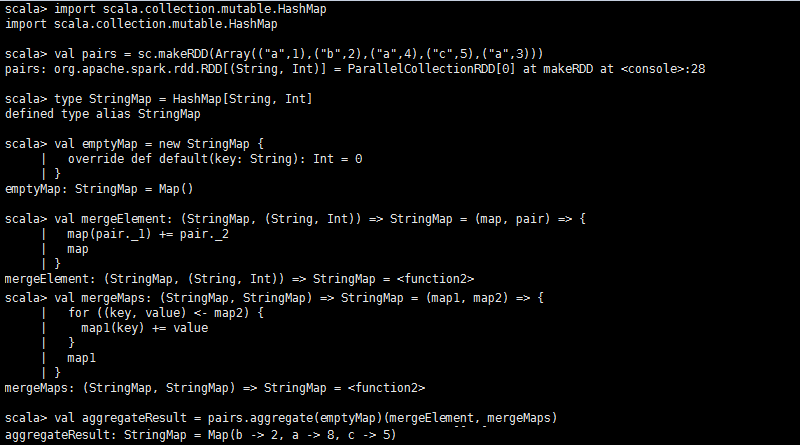
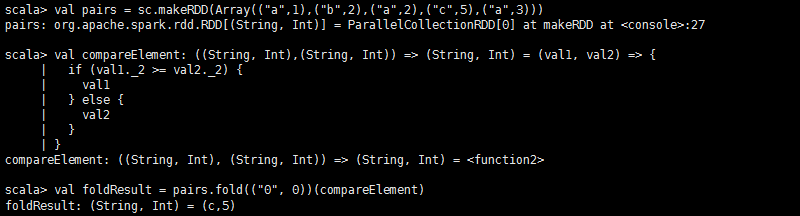
**fold(zeroValue: T)(op: (T,T)=>T)**:aggregate的便利接口,op操作既是seqOp操作,也是combOp操作。
lookup(key: K): Seq[V]:lookup是针对(K,V)类型RDD的行动操作,对于给定的键值,返回与此键值对应的所有值。

行动操作将RDD直接保存到外部文件系统或者数据库中,比如HDFS文件系统中。
**saveAsTextFile(path: String)**:
**saveAsTextFile(path: String, codec: Class[_<:CompressionCodec])**:
**saveAsObjectFile(path: String)**:
**saveAsHadoopFile[F<:OutputFormat[K,V]](path: String)**:
**saveAsHadoopFile[F<:OutputFormat[K,V]](path: String, codec: Class[_<:CompressionCodec])**:
**saveAsHadoopFile(path: String, keyClass: Class[_], valueClass: class[_], outputFormatClass: Class[]......)**:
**saveAsHadoopDataset(conf: JobConf)**:
这是旧版本API中提供的七个将RDD存储到外部介质的函数,前六个都是saveAsHadoopDataset的简易实现版本,仅支持将RDD存储到HDFS中,而saveAsHadoopDataset的参数类型是JobConf,所以它还可以将RDD保存到其它数据库中,例如Hbase、MongoDB、Cassandra等。
Spark针对新版本Hadoop API提供了三个行动操作函数。
**saveAsNewAPIHadoopFile[F<:NewOutputFormat[K,V]](path: String)(implicit fm: ClassTag[F])**:
**saveAsNewAPIHadoopFile(path: String, keyClass: Class[_],......)**:
**saveAsNewAPIHadoopDataset(conf: Configuration)**:
前两个API支持将RDD保存到HDFS中,第三个则支持所有MapReduce兼容的输入输出类型。












