
1. 问题背景
某核心JAVA长连接服务使用mongodb作为主要存储,客户端数百台机器连接同一mongodb集群,短期内出现多次性能抖动问题,此外,还出现一次“雪崩”故障,同时流量瞬间跌零,无法自动恢复。本文分析这两次故障的根本原因,包括客户端配置使用不合理、mongodb内核链接认证不合理、代理配置不全等一系列问题,最终经过多方努力确定问题根源。
该集群有十来个业务接口访问,每个接口部署在数十台业务服务器上面,访问该mongodb机器的客户端总数超过数百台,部分请求一次拉取数十行甚至百余行数据。
该集群为2机房同城多活集群(选举节不消耗太多资源,异地的第三机房来部署选举节点),架构图如下:
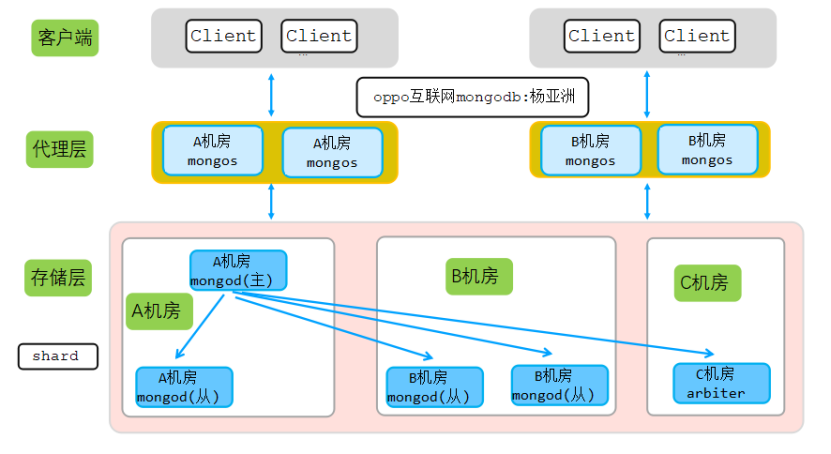
从上图可以看出,为了实现多活,在每个机房都部署有对应代理,对应机房客户端链接对应机房的mongos代理,每个机房多个代理。代理层部署IP:PORT地址列表(注意:不是真实IP地址)如下:
- A机房代理地址列表:1.1.1.1:111,2.2.2.2:1111,3.3.3.3:1111
- B机房代理地址列表:4.4.4.4:1111,4.4.4.4:2222
A机房三个代理部署在三台不同物理机,B机房2个代理部署在同一台物理机。此外,A机房和B机房为同城机房,跨机房访问时延可以忽略。
集群存储层和config server都采用同样的架构:A机房(1主节点+1从节点) + B机房(2从节点)+C机房(1个选举节点arbiter),即2(数据节点)+2(数据节点)+1(选举节点)模式。
该机房多活架构可以保证任一机房挂了,对另一机房的业务无影响,具体机房多活原理如下:
- 如果A机房挂掉,由于代理是无状态节点,A机房挂掉不会影响B机房的代理。
- 如果A机房挂掉,同时主节点在A机房,这时候B机房的2个数据节点和C机房的选举节点一共三个节点,可以保证新选举需要大于一半以上节点这个条件,于是B机房的数据节点会在短时间内选举出一个新的主节点,这样整个存储层访问不受任何影响。
本文重点分析如下6个疑问点:
- 为什么突发流量业务会抖动?
- 为什么数据节点没有任何慢日志,但是代理负载缺100%?
- 为何mongos代理引起数小时的“雪崩”,并且长时间不可恢复?
- 为何一个机房代理抖动,对应机房业务切到另一个机房后,还是抖动?
- 为何异常时候抓包分析,客户端频繁建链断链,并且同一个链接建链到断链间隔很短?
- 理论上代理就是七层转发,消耗资源更少,相比mongod存储应该更快,为何mongod存储节点无任何抖动,mongos代理缺有抖动?
2. 故障过程
2.1 业务偶尔流量高峰,业务抖动?
该集群一段时间内有多次短暂的抖动,当A机房客户端抖动后,发现A机房对应代理负载很高,于是切换A机房访问B机房代理,但是切换后B机房代理同样抖动,也就是多活切换没有作用,具体过程分析如下。
2.1.1 存储节点慢日志分析
首先,分析该集群所有mongod存储节点系统CPU、MEM、IO、load等监控信息,发现一切正常,于是分析每个mongod节点慢日志(由于该集群对时延敏感,因此慢日志调整为30ms),分析结果如下:



从上图可以看出,存储节点在业务抖动的时候没有任何慢日志,因此可以判断存储节点一切正常,业务抖动和mongod存储节点无关。
2.1.2 Mongos代理分析
存储节点没有任何问题,因此开始排查mongos代理节点。由于历史原因,该集群部署在其他平台,该平台对QPS、时延等监控不是很全,造成早期抖动的时候监控没有及时发现。抖动后,迁移该平台集群到oppo自研的新管控平台,新平台有详细的监控信息,迁移后QPS监控曲线如下:
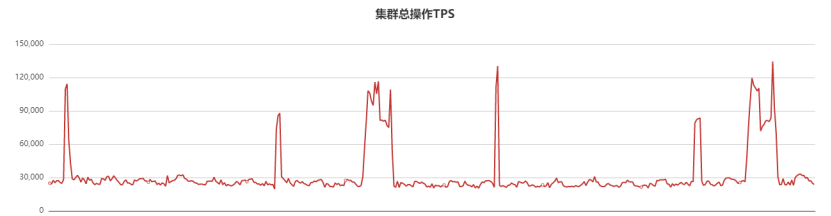
每个流量徒增时间点,对应业务监控都有一波超时或者抖动,如下:
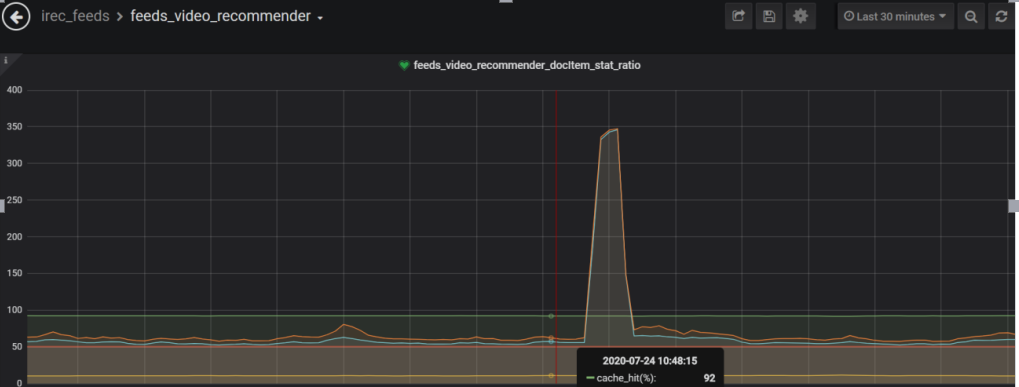
分析对应代理mongos日志,发现如下现象:抖动时间点mongos.log日志有大量的建链接和断链接的过程,如下图所示:

从上图可以看出,一秒钟内有几千个链接建立,同时有几千个链接断开,此外抓包发现很多链接短期内即断开链接,现象如下(断链时间-建链时间=51ms, 部分100多ms断开):

对应抓包如下:

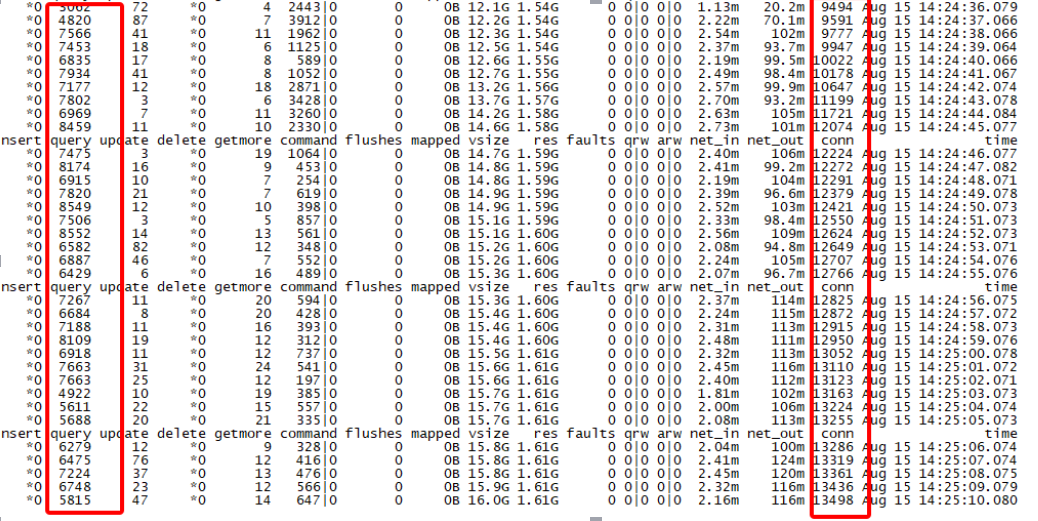
此外,该机器代理上客户端链接低峰期都很高,甚至超过正常的QPS值,QPS大约7000-8000,但是conn链接缺高达13000,
mongostat获取到监控信息如下:
2.1.3 代理机器负载分析
每次突发流量的时候,代理负载很高,通过部署脚本定期采样,抖动时间点对应监控图如下图所示:
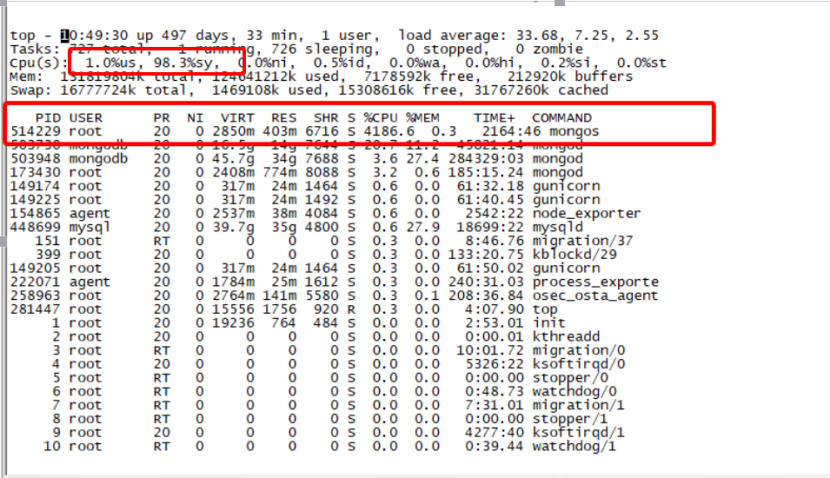
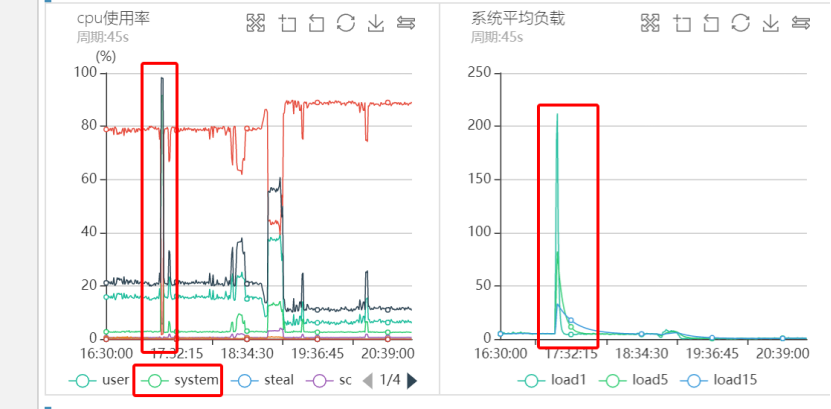
从上图可以看出,每次流量高峰的时候CPU负载都非常的高,而且是sy%负载,us%负载很低,同时Load甚至高达好几百,偶尔甚至过千。
2.1.4 抖动分析总结
从上面的分析可以看出,某些时间点业务有突发流量引起系统负载很高。根因真的是因为突发流量吗?其实不然,请看后续分析,这其实是一个错误结论。没过几天,同一个集群雪崩了。
于是业务梳理突发流量对应接口,梳理出来后下掉了该接口,QPS监控曲线如下:
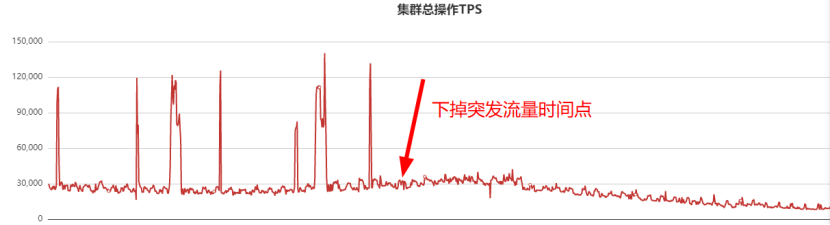
为了减少业务抖动,因此下掉了突发流量接口,此后几个小时业务不再抖动。当下掉突发流量接口后,我们还做了如下几件事情:
- 由于没找到mongos负载100%真正原因,于是每个机房扩容mongs代理,保持每个机房4个代理,同时保证所有代理在不同服务器,通过分流来尽量减少代理负载。
- 通知A机房和B机房的业务配置上所有的8个代理,不再是每个机房只配置对应机房的代理(因为第一次业务抖动后,我们分析mongodb的java sdk,确定sdk均衡策略会自动剔除请求时延高的代理,下次如果某个代理再出问题,也会被自动剔除)。
- 通知业务把所有客户端超时时间提高到500ms。
但是,心里始终有很多疑惑和悬念,主要在以下几个点:
- 存储节点4个,代理节点5个,存储节点无任何抖动 ,反而七层转发的代理负载高?
- 为何抓包发现很多新连接几十ms或者一百多ms后就断开连接了?频繁建链断链?
- 为何代理QPS只有几万,这时代理CPU消耗就非常高,而且全是sy%系统负载? 以我多年中间件代理研发经验,代理消耗的资源很少才对,而且CPU只会消耗us%,而不是sy%消耗。
2.2 同一个业务几天后”雪崩”了
好景不长,业务下掉突发流量的接口没过几天,更严重的故障出现了,机房B的业务流量在某一时刻直接跌0了,不是简单的抖动问题,而是业务直接流量跌0,系统sy%负载100%,业务几乎100%超时重连。
2.2.1 机器系统监控分析
机器CPU和系统负载监控如下:
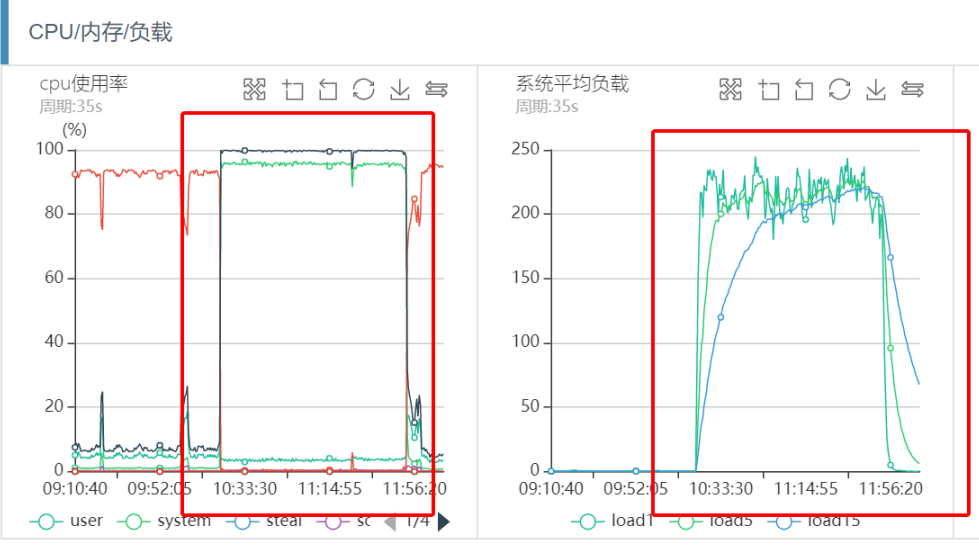
从上图可以看出,几乎和前面的突发流量引起的系统负载过高现象一致,业务CPU sy%负载100%,load很高。登陆机器获取top信息,现象和监控一致。

同一时刻对应网络监控如下:
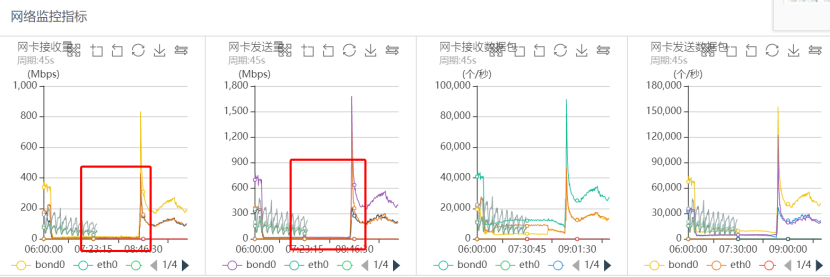
磁盘IO监控如下:
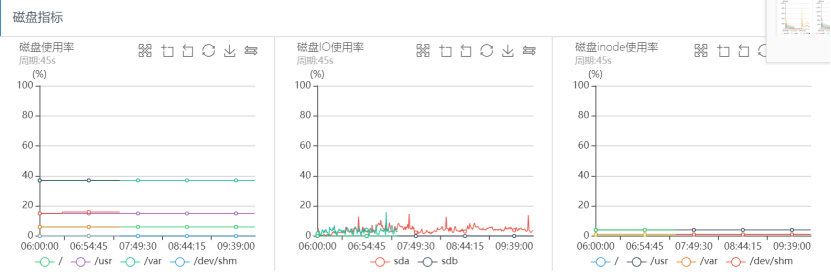
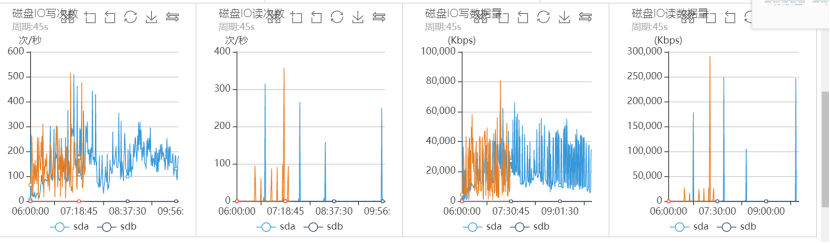
从上面的系统监控分析可以看出,出问题的时间段,系统CPU sy%、load负载都很高,网络读写流量几乎跌0,磁盘IO一切正常,可以看出整个过程几乎和之前突发流量引起的抖动问题完全一致。
2.2.2 业务如何恢复
第一次突发流量引起的抖动问题后,我们扩容所有的代理到8个,同时通知业务把所有业务接口配置上所有代理。由于业务接口众多,最终B机房的业务没有配置全部代理,只配置了原先的两个处于同一台物理机的代理(4.4.4.4:1111,4.4.4.4:2222),最终触发mongodb的一个性能瓶颈(详见后面分析),引起了整个mongodb集群”雪崩”
最终,业务通过重启服务,同时把B机房的8个代理同时配置上,问题得以解决。
2.2.3 mongos代理实例监控分析
分析该时间段代理日志,可以看出和2.1同样得现象,大量的新键连接,同时新连接在几十ms、一百多ms后又关闭连接。整个现象和之前分析一致,这里不在统计分析对应日志。
此外,分析当时的代理QPS监控,正常query读请求的QPS访问曲线如下,故障时间段QPS几乎跌零雪崩了:
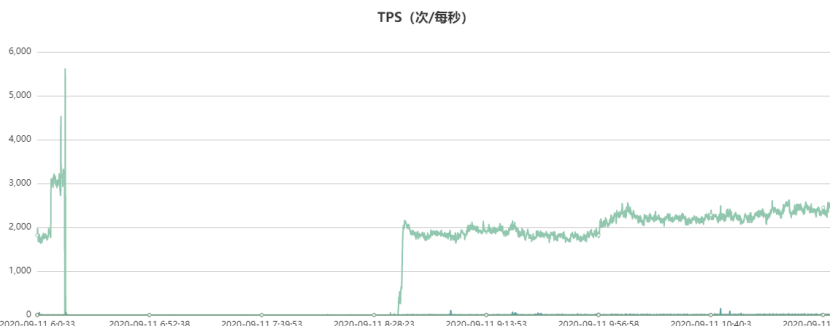
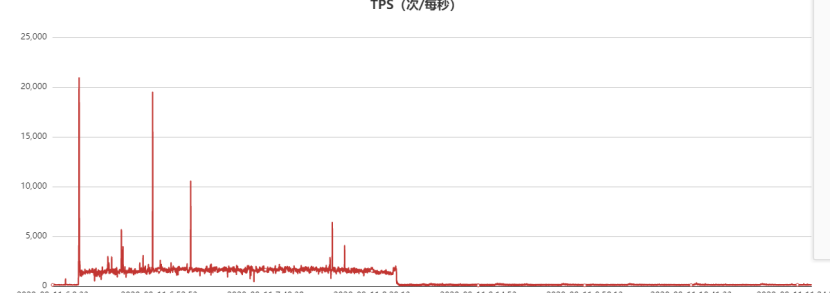
从上面的统计可以看出,当该代理节点的流量故障时间点有一波尖刺,同时该时间点的command统计瞬间飙涨到22000(实际可能更高,因为我们监控采样周期30s,这里只是平均值),也就是瞬间有2.2万个连接瞬间进来了。Command统计实际上是db.ismaster()统计,客户端connect服务端成功后的第一个报文就是ismaster报文,服务端执行db.ismaster()后应答客户端,客户端收到后开始正式的sasl认证流程。
正常客户端访问流程如下:
- 客户端发起与mongos的链接
- Mongos服务端accept接收链接后,链接建立成功
- 客户端发送db.isMaster()命令给服务端
- 服务端应答isMaster给客户端
- 客户端发起与mongos代理的sasl认证(多次和mongos交互)
- 客户端发起正常的find()流程
客户端SDK链接建立成功后发送db.isMaster()给服务端的目的是为了负载均衡策略和判断节点是什么类型,保证客户端快速感知到访问时延高的代理,从而快速剔除往返时延高的节点,同时确定访问的节点类型。
此外,通过提前部署的脚本,该脚本在系统负载高的时候自动抓包,从抓包分析结果如下图所示:
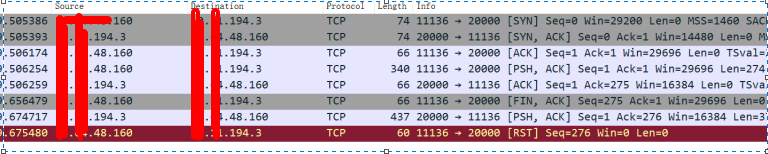
上图时序分析如下:
- 11:21:59.506174链接建立成功
- 11:21:59.506254 客户端发送db.IsMaster()到服务端
- 11:21:59.656479 客户端发送FIN断链请求
- 11:21:59.674717 服务端发送db.IsMaster()应答给客户端
- 11:21:59.675480 客户端直接RST
第3和第1个报文之间相差大约150ms,最后和业务确定该客户端IP对应的超时时间配置,确定就是150ms。此外,其他抓包中有类似40ms、100ms等超时配置,通过对应客户端和业务确认,确定对应客户端业务接口超时时间配置的就是40ms、100ms等。因此,结合抓包和客户端配置,可以确定当代理超过指定超时时间还没有给客户端db.isMaster()返回值,则客户端立马超时,超时后立马发起重连请求。
总结:通过抓包和mongos日志分析,可以确定链接建立后快速断开的原因是:客户端访问代理的第一个请求db.isMaster()超时了,因此引起客户端重连。重连后又开始获取db.isMaster()请求,由于负载CPU 100%, 很高,每次重连后的请求都会超时。其中配置超时时间为500ms的客户端,由于db.isMaster()不会超时,因此后续会走sasl认证流程。
因此可以看出,系统负载高和反复的建链断链有关,某一时刻客户端大量建立链接(2.2W)引起负载高,又因为客户端超时时间配置不一,超时时间配置得比较大得客户端最终会进入sasl流程,从内核态获取随机数,引起sy%负载高,sy%负载高又引起客户端超时,这样整个访问过程就成为一个“死循环”,最终引起mongos代理雪崩。
2.3 线下模拟故障
到这里,我们已经大概确定了问题原因,但是为什么故障突发时间点那一瞬间2万个请求就会引起sy%负载100%呢,理论上一秒钟几万个链接不会引起如此严重的问题,毕竟我们机器有40个CPU。因此,分析反复建链断链为何引起系统sy%负载100%就成为了本故障的关键点。
2.3.1 模拟故障过程
模拟频繁建链断链故障步骤如下:
- 修改mongos内核代码,所有请求全部延时600ms
- 同一台机器起两个同样的mongos,通过端口区分
- 客户端启用6000个并发链接,超时时间500ms
通过上面的操作,可以保证所有请求超时,超时后客户端又会立马开始重新建链,再次建链后访问mongodb还会超时,这样就模拟了反复建链断链的过程。此外,为了保证和雪崩故障环境一致,把2个mongos代理部署在同一台物理机。
2.3.2 故障模拟测试结果
为了保证和故障的mongos代理硬件环境一致,因此选择故障同样类型的服务器,并且操作系统版本一样(2.6.32-642.el6.x86_64),程序都跑起来后,问题立马浮现:

由于出故障的服务器操作系统版本linux-2.6过低,因此怀疑可能和操作系统版本有问题,因此升级同一类型的一台物理机到linux-3.10版本,测试结果如下:

从上图可以看出,客户端6000并发反复重连,服务端压力正常,所有CPU消耗在us%,sy%消耗很低。用户态CPU消耗3个CPU,内核态CPU消耗几乎为0,这是我们期待的正常结果,因此觉得该问题可能和操作系统版本有问题。
为了验证更高并反复建链断链在Linux-3.10内核版本是否有2.6版本同样的sy%内核态CPU消耗高的问题,因此把并发从6000提升到30000,验证结果如下:
测试结果:通过修改mongodb内核版本故意让客户端超时反复建链断链,在linux-2.6版本中,1500以上的并发反复建链断链系统CPU sy% 100%的问题即可浮现。但是,在Linux-3.10版本中,并发到10000后,sy%负载逐步增加,并发越高sy%负载越高。
总结:linux-2.6系统中,mongodb只要每秒有几千的反复建链断链,系统sy%负载就会接近100%。Linux-3.10,并发20000反复建链断链的时候,sy%负载可以达到30%,随着客户端并发增加,sy%负载也相应的增加。Linux-3.10版本相比2.6版本针对反复建链断链的场景有很大的性能改善,但是不能解决根本问题。
2.4 客户端反复建链断链引起sy% 100%根因
为了分析%sy系统负载高的原因,安装perf获取系统top信息,发现所有CPU消耗在如下接口:
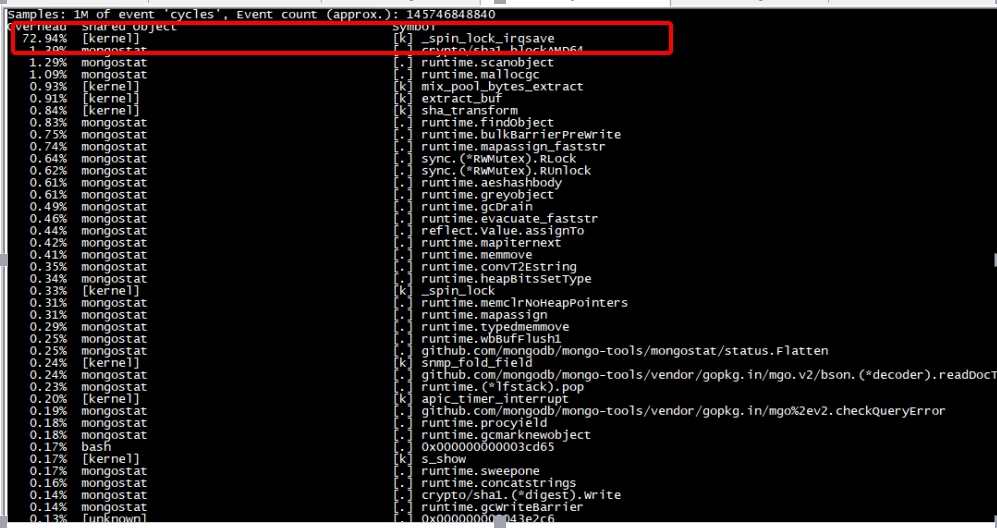
从perf分析可以看出,cpu 消耗在_spin_lock_irqsave函数,继续分析内核态调用栈,得到如下堆栈信息:
- 89.81% 89.81% [kernel] [k] _spin_lock_irqsave ▒
- _spin_lock_irqsave ▒
- mix_pool_bytes_extract ▒
- extract_buf ▒
extract_entropy_user ▒
urandom_read ▒
vfs_read ▒
sys_read ▒
system_call_fastpath ▒
0xe82d
上面的堆栈信息说明,mongodb在读取 /dev/urandom ,并且由于多个线程同时读取该文件,导致消耗在一把spinlock上。
到这里问题进一步明朗了,故障root case 不是每秒几万的连接数导致sys 过高引起。根本原因是每个mongo客户端的新链接会导致mongodb后端新建一个线程,该线程在某种情况下会调用urandom_read 去读取随机数/dev/urandom ,并且由于多个线程同时读取,导致内核态消耗在一把spinlock锁上,出现cpu 高的现象。
2.5 mongodb内核随机数优化
2.5.1 mongodb内核源码定位分析
上面的分析已经确定,问题根源是mongodb内核多个线程读取/dev/urandom随机数引起,走读mongodb内核代码,发现读取该文件的地方如下:
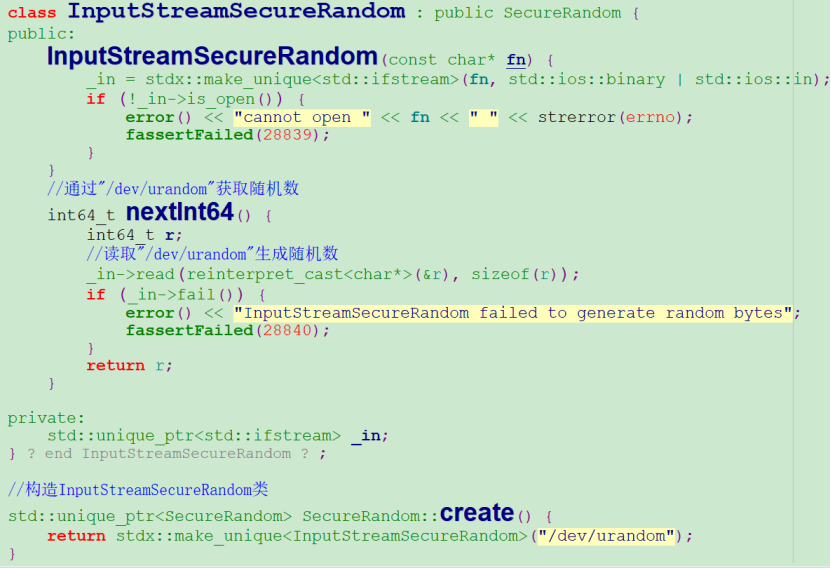
上面是生成随机数的核心代码,每次获取随机数都会读取”/dev/urandom”系统文件,所以只要找到使用该接口的地方即可即可分析出问题。
继续走读代码,发现主要在如下地方:
//服务端收到客户端sasl认证的第一个报文后的处理,这里会生成随机数
//如果是mongos,这里就是接收客户端sasl认证的第一个报文的处理流程
Sasl_scramsha1_server_conversation::_firstStep(...) {
... ...
unique_ptr
binaryNonce[0] = sr->nextInt64();
binaryNonce[1] = sr->nextInt64();
binaryNonce[2] = sr->nextInt64();
... ...
}
//mongos相比mongod存储节点就是客户端,mongos作为客户端也需要生成随机数
SaslSCRAMSHA1ClientConversation::_firstStep(...) {
... ...
unique_ptr
binaryNonce[0] = sr->nextInt64();
binaryNonce[1] = sr->nextInt64();
binaryNonce[2] = sr->nextInt64();
... ...
}
2.5.2 mongodb内核源码随机数优化
从2.5.1分析可以看出,mongos处理客户端新连接sasl认证过程都会通过"/dev/urandom"生成随机数,从而引起系统sy% CPU过高,我们如何优化随机数算法就是解决本问题的关键。
继续分析mongodb内核源码,发现使用随机数的地方很多,其中有部分随机数通过用户态算法生成,因此我们可以采用同样方法,在用户态生成随机数,用户态随机数生成核心算法如下:
class PseudoRandom {
... ...
uint32_t _x;
uint32_t _y;
uint32_t _z;
uint32_t _w;
}

该算法可以保证产生的数据随机分布,该算法原理详见:
http://en.wikipedia.org/wiki/Xorshift
也可以查看如下git地址获取算法实现:
总结:通过优化sasl认证的随机数生成算法为用户态算法后,CPU sy% 100%的问题得以解决,同时代理性能在短链接场景下有了数倍/数十倍的性能提升。
- 问题总结及疑问解答
从上面的分析可以看出,该故障由多种因素连环触发引起,包括客户端配置使用不当、mongodb服务端内核极端情况异常缺陷、监控不全等。总结如下:
- 客户端配置不统一,同一个集群多个业务接口配置千奇百怪,超时配置、链接配置各不相同,增加了抓包排查故障的难度,超时时间设置太小容易引起反复重连。
- 客户端需要配全所有mongos代理,这样当一个代理故障的时候,客户端SDK默认会剔除该故障代理节点,从而可以保证业务影响最小,就不会存在单点问题。
- 同一集群多个业务接口应该使用同一配置中心统一配置,避免配置不统一。
- Mongodb内核的新连接随机算法存在严重缺陷,在极端情况下引起严重性能抖动,甚至业务“雪崩”。
分析到这里,我们可以回答第1章节的6个疑问点了,如下:
为什么突发流量业务会抖动?
答:由于业务是java业务,采用链接池方式链接mongos代理,当有突发流量的时候,链接池会增加链接数来提升访问mongodb的性能,这时候客户端就会新增链接,由于客户端众多,造成可能瞬间会有大量新连接和mongos建链。链接建立成功后开始做sasl认证,由于认证的第一步需要生成随机数,就需要访问操作系统"/dev/urandom"文件。又因为mongos代理模型是默认一个链接一个线程,所以会造成瞬间多个线程访问该文件,进而引起内核态sy%负载过高。
为何mongos代理引起“雪崩”,流量为何跌零不可用?
答:原因客户端某一时刻可能因为流量突然有增加,链接池中链接数不够用,于是增加和mongos代理的链接,由于是老集群,代理还是默认的一个链接一个线程模型,这样瞬间就会有大量链接,每个链接建立成功后,就开始sasl认证,认证的第一步服务端需要产生随机数,mongos服务端通过读取"/dev/urandom"获取随机数,由于多个线程同时读取该文件触发内核态spinlock锁CPU sy% 100%问题。由于sy%系统负载过高,由于客户端超时时间设置过小,进一步引起客户端访问超时,超时后重连,重连后又进入sasl认证,又加剧了读取"/dev/urandom"文件,如此反复循环持续。
此外,第一次业务抖动后,服务端扩容了8个mongos代理,但是客户端没有修改,造成B机房业务配置的2个代理在同一台服务器,无法利用mongo java sdk的自动剔除负载高节点这一策略,所以最终造成”雪崩”
为什么数据节点没有任何慢日志,但是代理负载却CPU sy% 100%?
答:由于客户端java程序直接访问的是mongos代理,所以大量链接只发生在客户端和mongos之间,同时由于客户端超时时间设置太短(有接口设置位几十ms,有的接口设置位一百多ms,有的接口设置位500ms),就造成在流量峰值的时候引起连锁反应(突发流量系统负载高引起客户端快速超时,超时后快速重连,进一步引起超时,无限死循环)。Mongos和mongod之间也是链接池模型,但是mongos作为客户端访问mongod存储节点的超时很长,默认都是秒级别,所以不会引起反复超时建链断链。
为何A机房代理抖动的时候,A机房业务切到B机房后,还是抖动?
答:当A机房业务抖动,业务切换到B机房的时候,客户端需要重新和服务端建立链接认证,又会触发大量反复建链断链和读取随机数"/dev/urandom"的流程,所以最终造成机房多活失败。
为何异常时候抓包分析,客户端频繁建链断链,并且同一个链接建链到断链间隔很短?
答:频繁建链断链的根本原因是系统sy%负载高,客户端极短时间内建立链接后又端口的原因是客户端配置超时时间太短。
理论上代理就是七层转发,消耗资源更少,相比mongod存储应该更快,为何mongod存储节点无任何抖动,mongos代理却有严重抖动?
答:由于采用分片架构,所有mongod存储节点前面都有一层mongos代理,mongos代理作为mongod存储节点的客户端,超时时间默认秒级,不会出现超时现象,也就不会出现频繁的建链断链过程。
如果mongodb集群采用普通复制集模式,客户端频繁建链断链是否可能引起mongod存储节点同样的”雪崩”?
答:会。如果客户端过多,操作系统内核版本过低,同时超时时间配置过段,直接访问复制集的mongod存储节点,由于客户端和存储节点的认证过程和与mongos代理的认证过程一样,所以还是会触发引起频繁读取"/dev/urandom"文件,引起CPU sy%负载过高,极端情况下引起雪崩。
- “雪崩”解决办法****
从上面的一系列分析,问题在于客户端配置不合理,加上mongodb内核认证过程读取随机数在极端情况下存在缺陷,最终造成雪崩。如果没有mongodb内核研发能力,可以通过规范化客户端配置来避免该问题。当然,如果客户端配置规范化,同时mongodb内核层面解决极端情况下的随机数读取问题,这样问题可以得到彻底解决。
4.1 JAVA SDK客户端配置规范化
在业务接口很多,客户端机器很多的业务场景,客户端配置一定要做到如下几点:
- 超时时间设置为秒级,避免超时时间设置过端引起反复的建链断链。
- 客户端需要配置所有mongos代理地址,不能配置单点,否则流量到一个mongos很容易引起瞬间流量峰值的建链认证。
- 增加mongos代理数量,这样可以分流,保证同一时刻每个代理的新键链接尽可能的少,客户端在多代理配置时,默认是均衡流量分发的,如果某个代理负载高,客户端会自动剔除。
如果没有mongodb内核源码研发能力,可以参考该客户端配置方法,同时淘汰linux-2.6版本内核,采用linux-3.10或者更高版本内核,基本上可以规避踩同样类型的坑。
4.2 mongodb内核源码优化(摈弃内核态获取随机数,选择用户态随机数算法)
详见2.5.2 章节。
4.3 PHP短链接业务,如何规避踩坑
由于PHP业务属于短链接业务,如果流量很高,不可避免的要频繁建链断链,也就会走sasl认证流程,最终多线程频繁读取"/dev/urandom"文件,很容易引起前面的问题。这种情况,可以采用4.1 java客户端类似的规范,同时不要使用低版本的Linux内核,采用3.x以上内核版本,就可以规避该问题的存在。
5. Mongodb内核源码设计与实现分析
本文相关的Mongodb线程模型及随机数算法实现相关源码分析如下:











