
一.主从复制原理
利用MySQL提供的Replication,其实就是Slave从Master获取Binary log文件,然后再本地镜像的执行日志中记录的操作。由于主从复制的过程是异步的,因此Slave和Master之间的数据有可能存在延迟的现象,此时只能保证数据最终的一致性。
在master与slave之间实现整个复制过程主要由三个线程来完成:
1.Slave SQL thread线程,在slave端
2.Slave I/O thread线程,在slave端
3.Binlog dump thread线程(也可称为IO线程),在master端
注意:如果一台主服务器配两台从服务器那主服务器上就会有两个Binlog dump 线程,而每个从服务器上各自有两个线程。
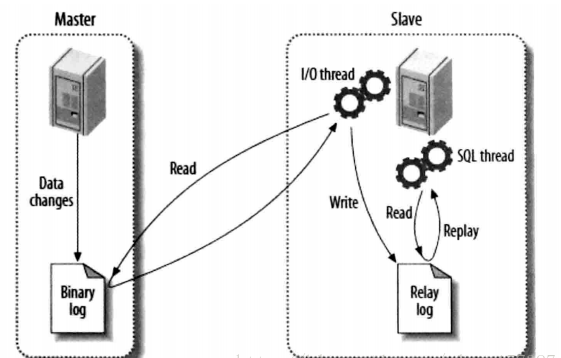
网络上找的一张很清晰的交互图,流程可以详细描述为:
1、slave端的IO线程连接上master端,并请求从指定binlog日志文件的指定pos节点位置(或者从最开始的日志)开始复制之后的日志内容。
2、master端在接收到来自slave端的IO线程请求后,通知负责复制进程的IO线程,根据slave端IO线程的请求信息,读取指定binlog日志指定pos节点位置之后的日志信息,然后返回给slave端的IO线程。该返回信息中除了binlog日志所包含的信息之外,还包括本次返回的信息在master端的binlog文件名以及在该binlog日志中的pos节点位置。
3、slave端的IO线程在接收到master端IO返回的信息后,将接收到的binlog日志内容依次写入到slave端的relaylog文件(mysql-relay-bin.xxxxxx)的最末端,并将读取到的master端的binlog文件名和pos节点位置记录到master-info(该文件存slave端)文件中,以便在下一次读取的时候能够清楚的告诉master“我需要从哪个binlog文件的哪个pos节点位置开始,请把此节点以后的日志内容发给我”。
4、slave端的SQL线程在检测到relaylog文件中新增内容后,会马上解析该log文件中的内容。然后还原成在master端真实执行的那些SQL语句,并在自身按顺丰依次执行这些SQL语句。这样,实际上就是在master端和slave端执行了同样的SQL语句,所以master端和slave端的数据完全一样的。
二.如何实现?
这里在本地虚拟机模拟演示:
准备工作:两个虚拟机:我这里用的是CentOS5.5,IP地址分别是192.168.1.101 和192.168.1.105;
步骤:1.修改mysql的配置文件,打开二进制日志功能。 命令:# vi /etc/my.cnf 增加以下三行配置
log-bin=mysql-bin //将mysql二进制日志取名为mysql-bin
binlog_format=mixed //二进制日志的格式,有三种:statement/row/mixed,具体分别不多做解释,这里使用mixed
server-id=101 //为服务器设置一个独一无二的id便于区分,这里使用ip地址的最后一位充当server-id
然后修改从服务器的my.cnf文件,也添加以上内容,不过server-id的值为从服务器的标识。然后分别重启主、从mysql。
2.在主服务器为从服务器分配用户。命令:GRANT replication slave ON *.* TO 'slave'@'%' IDENTIFIED BY '111111';

3.查看主服务器BIN日志的信息(执行完之后记录下这两值,然后在配置完从服务器之前不要对主服务器进行任何操作,因为每次操作数据库时这两值会发生改变)。命令:show master status;

4.进入从服务器,执行以下命令设置master。
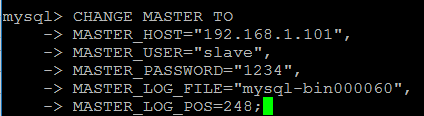
MASTER_HOST : 设置要连接的主服务器的ip地址
MASTER_USER : 设置要连接的主服务器的用户名
MASTER_PASSWORD : 设置要连接的主服务器的密码
MASTER_LOG_FILE : 设置要连接的主服务器的bin日志的日志名称,即第3步得到的信息
MASTER_LOG_POS : 设置要连接的主服务器的bin日志的记录位置,即第3步得到的信息,(这里注意,最后一项不需要加引号。否则配置失败)
然后执行start slave;命令启动从服务器。
5.查看是否配置成功。命令:show slave status;

上面两项为Yes说明配置成功。可以在主库更新数据测试从库是否会同步。












