
消息中间件的性能好坏,它的消息存储的机制是衡量该性能的最重要指标之一,而 Kafka 具有高性能、高吞吐、低延时的特点,动不动可以上到几十上百万 TPS,离不开它优秀的消息存储设计。下面我按照自己的理解为大家讲解 Kafka 消息存储设计的那些事。
在 Kafka 的设计思想中,消息的存储文件被称作日志,我们 Java 后端绝大部分人谈到日志,一般会联想到项目通过 log4j 等日志框架输出的信息,而 Kafka 的消息日志类似于数据库中的提交记录,他们会按照时间顺序进行追加,Kafka 的消息也是严格按照时间顺序并已一定的格式写入日志文件中,有意思的是 Kafka 的消息不叫 Message,而是叫作 Record:

Kafka 将消息封装成一个个 Record,并以自定义的格式序列化成二进制字节数组进行保存:
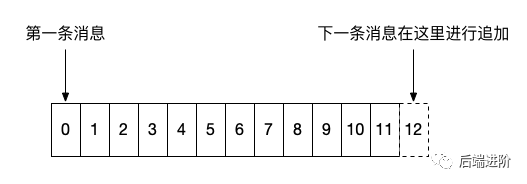
如上图所示,消息严格按照顺序进行追加,一般来说,左边的消息存储时间都要小于右边的消息,需要注意的一点是,在 0.10.0.0 以后的版本中,Kafka 的消息体中增加了一个用于记录时间戳的字段,而这个字段可以有 Kafka Producer 端自定义,意味着客户端可以打乱日志中时间的顺序性。
Kafka 的消息存储会按照该主题的分区进行隔离保存,即每个分区都有属于自己的的日志,在 Kafka 中被称为分区日志(partition log),每条消息在发送前计算到被发往的分区中,broker 收到日志之后把该条消息写入对应分区的日志文件中:
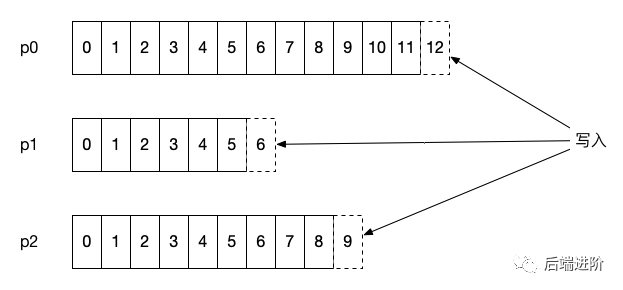
以上简单介绍了 Kafka 的消息是如何追加存储的,那么在具体的存储文件中,日志的文件是怎么样的呢?
如果每个分区只存在一个日志文件,对于消息的过期清除和检索都是一个大难题,因此 Kafka 会将每个分区的日志文件继续细分成若干个日志文件,这些日志文件也称作日志段文件(log segment file),每个日志段文件都会伴随一个索引文件和时间戳索引文件,在 broker 所属节点打开对应分区日志的目录,可以看到相关文件:

每个日志段包含了 .log/.index/timeindex 三个文件,而且名字都是相同的。
1、log 文件
.log 后缀文件保存了 Kafka 消息的记录,而且每个 log 文件都有对应的消息记录范围,名字的数字代表了消息记录的初始位移值,并且随着消息数量的增多而增大,因此,每个新创建的分区一定会包含 0 的 log 文件。Kafka 文件名字使用了 20 位来标识位移,对于实际的生产环境已经足够用了。
每个 log 文件的默认大小为 1 GB,可以通过 log.segment.bytes 参数进行控制,每当 log 文件被填满后,Kafka 会自动创建一组新的日志文件和索引文件,也就是说日志段文件一旦被填满后,就不会再继续写入新消息,而是写到新的日志段文件中,而当前可被写入消息的日志段文件也称作当前日志段文件,它是一种特殊的日志段文件,它不会受到 Kafka 任何后台任务的影响,比如日志过期清除、日志 compaction 等任务。
2、索引文件
每个 log 文件都会包含两个索引文件,分别是 .index 和 .timeindex,在 Kafka 中它们分别被称为位移索引文件和时间戳索引文件,位移索引文件可根据消息的位移值快速地从查询到消息的物理文件位置,时间戳索引文件可根据时间戳查找到对应的位移信息。
Kafka 的索引文件按照稀疏索引文件的思想进行设计的,每个索引文件包含若干条索引项,之前在文章「kill -9 导致 Kakfa 重启失败的惨痛经历!」中有分析过。稀疏索引的核心即不会为每个记录都保存索引,而是写入一定的记录之后才会增加一个索引值,具体这个间隔有多大则通过 log.index.interval.bytes 参数进行控制,默认大小为 4 KB,意味着 Kafka 至少写入 4KB 消息数据之后,才会在索引文件中增加一个索引项。
需要注意的一点是,消息大小还会影响 Kakfa 索引的插入频率,假设每个消息大小均大于 4 KB,会导致每次追加消息的时候,都会伴随一次索引项的增加。因此 log.index.interval.bytes 也是 Kafka 调优一个重要参数值。
那么既然有了索引文件,Kafka 是如何根据索引文件进行快速检索的呢?由于索引文件也是按照消息的顺序性进行增加索引项的,位移索引文件按照位移顺序保存,而时间戳索引文件则按照时间顺序保存索引项,因此 Kafka 可以利用二分查找算法来搜索目标索引项,把时间复杂度降到了 O(lgN),大大减少了查找的时间。
每个日志段的索引文件可通过 log.index.size.max.bytes 参数控制,默认大小为 10 MB。
1)位移索引文件
位移索引文件的索引项结构如下:
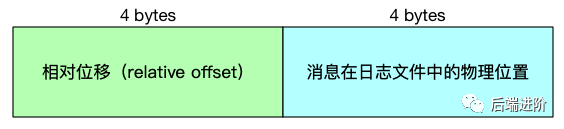
可以看出,每个索引项的大小为 8 bytes,源码 kafka.log.OffsetIndex#entrySize = 8 限定了索引项的大小。
需要注意的是,索引文件大小必须是索引项的整数倍,假设 log.index.size.max.bytes = 500,则 Kafka 会创建一个大小为 496 bytes 的索引文件。
相对位移:保存于索引文件名字上面的起始位移的差值,假设一个索引文件为:00000000000000000100.index,那么起始位移值即 100,当存储位移为 150 的消息索引时,在索引文件中的相对位移则为 150 - 100 = 50,这么做的好处是使用 4 字节保存位移即可,可以节省非常多的磁盘空间。
文件物理位置:消息在 log 文件中保存的位置,也就是说 Kafka 可根据消息位移,通过位移索引文件快速找到消息在 log 文件中的物理位置,有了该物理位置的值,我们就可以快速地从 log 文件中找到对应的消息了。
下面我用图来表示 Kafka 是如何快速检索消息:
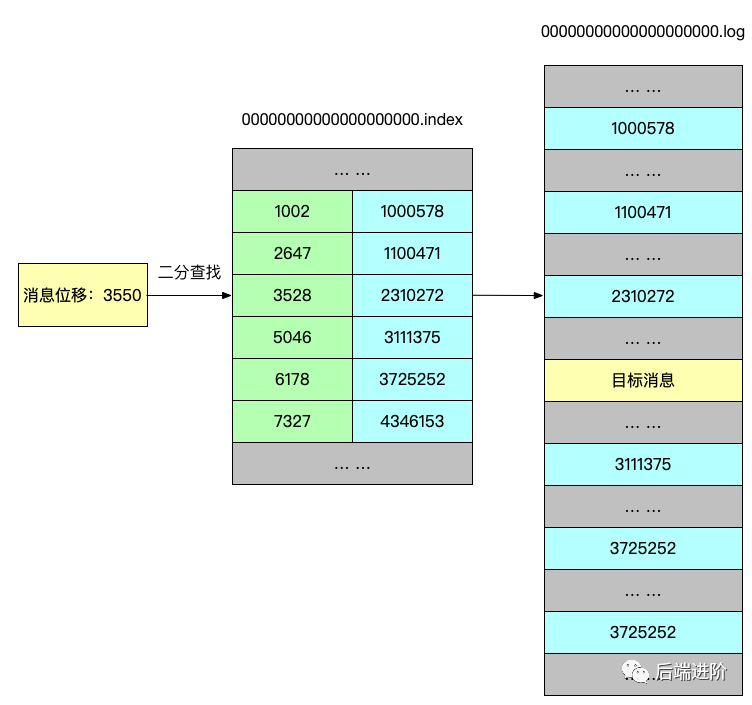
假设 Kafka 需要找出位移为 3550 的消息,那么 Kafka 首先会使用二分查找算法找到小于 3550 的最大索引项:[3528, 2310272],得到索引项之后,Kafka 会根据该索引项的文件物理位置在 log 文件中从位置 2310272 开始顺序查找,直至找到位移为 3550 的消息记录为止。
2)时间戳索引文件
Kafka 在 0.10.0.0 以后的版本当中,消息中增加了时间戳信息,为了满足用户需要根据时间戳查询消息记录,Kafka 增加了时间戳索引文件,时间戳索引文件的索引项结构如下:
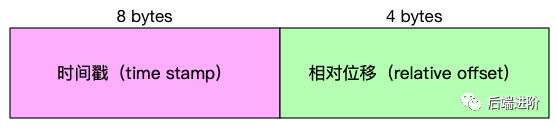
可以看出,每个索引项的大小为 12 bytes,源码 kafka.log.TimeIndex#entrySize = 12 限定了索引项的大小。
同样地,时间戳索引文件大小也必须为索引项的整数倍大小,计算方式与位移索引文件相同。
下面我用图来表示 Kafka 是如何快速检索消息:
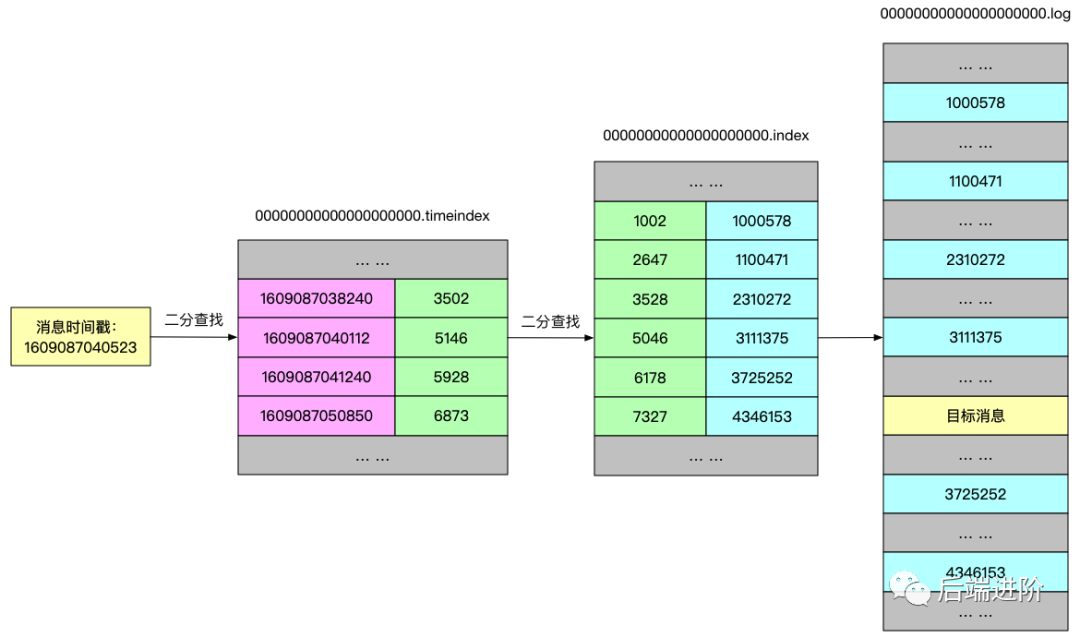
使用时间戳查找消息的流程与使用位移查找消息的流程的一些细节少有不同,下面我结合源码与例子,解释上图的流程:
kafka.log.LogSegment#findOffsetByTimestamp
def findOffsetByTimestamp(timestamp: Long, startingOffset: Long = baseOffset): Option[TimestampAndOffset] = { // Get the index entry with a timestamp less than or equal to the target timestamp val timestampOffset = timeIndex.lookup(timestamp) val position = offsetIndex.lookup(math.max(timestampOffset.offset, startingOffset)).position // Search the timestamp Option(log.searchForTimestamp(timestamp, position, startingOffset)) }
假设要查询时间戳为 1609087040523 附近的消息,从源码逻辑,根据二分算法找到时间戳索引项 [1609087040112, 5146],然后根据根据位移值从位移索引文件中找到小于 5146 位移的最大索引项[5046, 3111375]。
org.apache.kafka.common.record.FileRecords#searchForTimestamp
public TimestampAndOffset searchForTimestamp(long targetTimestamp, int startingPosition, long startingOffset) { for (RecordBatch batch : batchesFrom(startingPosition)) { if (batch.maxTimestamp() >= targetTimestamp) { // We found a message for (Record record : batch) { long timestamp = record.timestamp(); if (timestamp >= targetTimestamp && record.offset() >= startingOffset) return new TimestampAndOffset(timestamp, record.offset(), maybeLeaderEpoch(batch.partitionLeaderEpoch())); } } } return null; }
根据查到的索引项位移值 5046 开始查询,当消息时间戳最接近目标搜索的时间戳并且位移大于等于搜索起始位移时,则该消息即是满足该时间戳条件的消息。
近期热文
**Kafka Producer 异步发送消息居然也会阻塞?
**
**图解 DataX 核心设计原理
**

扫一扫订阅「后端进阶」
定期分享后端技术实战干货!
原创不易,如果对你有帮助,麻烦各位读者帮忙点个「在看」或者「转发」一下文章!
再次感谢你的阅读!
本文分享自微信公众号 - 后端进阶(objcoding)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。












