大家好,我是Python进阶者。
一、前言
前几天在Python铂金交流群【逆光】问了一个Python自动化办公的问题,问题如下:问题 我现在有两个表a、b ,for 循环a、b ,如果a的条件满足b,则把b的值赋给a ,目前a有7万条数据,b有300条。我写的代码20分钟都没跑完。这是代码,请问改怎么解决?

二、实现过程
这里【瑜亮老师】给了个思路如下:
【瑜亮老师】:数据是在df中?
【逆光 】嗯嗯,是的
【瑜亮老师】:那你不能这么写,熊猫一见for循环,思路基本就玩完。
【逆光 】:请问那咋整呢?
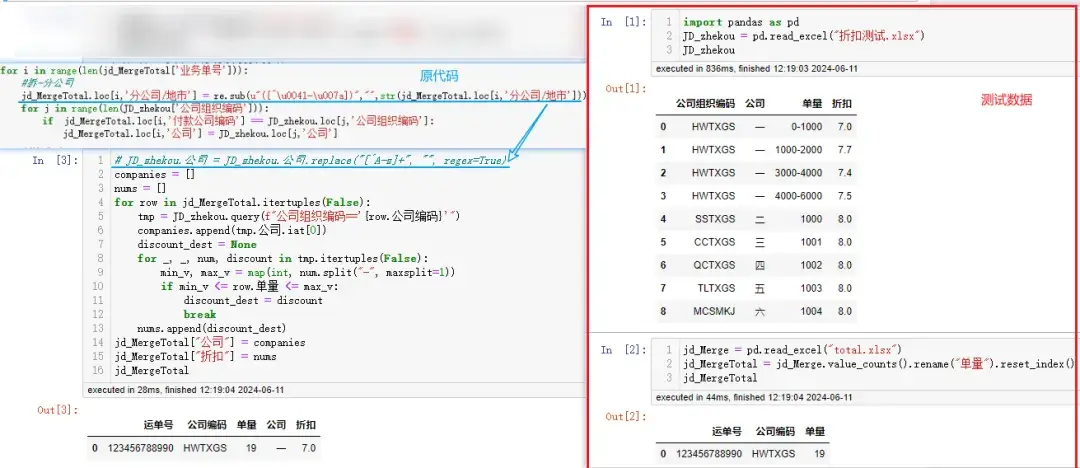
【瑜亮老师】:你的需求是根据jd mergeTotal['付款公司编码']列中元素 在 JD_zhekou中查找对应的公司名。结果保存在jd_mergeTotal['公司']列中,Total['付款公司编码']列是和zhekou['公司组织编码']对应的,都是公司的组织编码。
【逆光 】:对的,本来可以用merge 但是后期可能会添加total的单量满足折扣的条件才能匹配,所以我用了for循环。
【瑜亮老师】:先merge,后期如果需要添加条件,只需要加一行对结果的筛选即可。
【逆光 】:对结果的筛选?
【瑜亮老师】:先筛选,后merge。这样可以减少运算时间。而先merge后筛选,可以复用merge后的df,做更多筛选动作。看你的需求了。
【逆光 】:因为我是初学哈,我不是很懂,如果先merge 那不是一对多了吗?
【瑜亮老师】:什么一对多?
【逆光 】:第二个表,可能是这样啊,如果加入单量条件的话,主键编号就不是唯一的了。如果是多个关键字连接的话,单量是个范围,怎么弄进行判断呢?
【瑜亮老师】:远程吧,或者你发一个脱敏的两个表的数据。最好是你发一个脱敏数据。
【不上班能干啥!】:如果先merge,就匹配完再筛选。先筛选再匹配跟上面的结果是一样的,只是先merge过程产生的数据会多。别说加一个单量条件了,你加很多的条件也是这样的,总之先merge。
【瑜亮老师】:是的,先筛选省时,先merge可多次筛选。
【逆光 】:先merge ,后再筛选,咋个筛选呢?
【瑜亮老师】:主要是根据需求。如果只是筛选一次,那就先筛选。如果后期还是会有各种筛选,那就先merge。你发一个脱敏数据吧。无非是两行代码先后顺序的问题,这个不用纠结。
【逆光 】:我不知道怎么弄筛选?
【不上班能干啥!】:new_df = df1.merge(df2) new_df = new_df[new_df['判断列'] = 条件],不就这样吗,等于,大于,小于,包含,没别的了。
【逆光 】:我好像懂你的意思了,我去试一试。
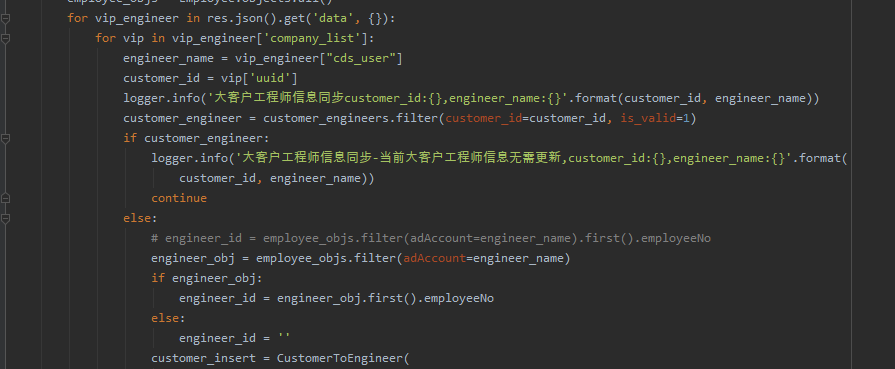
【小小明】:你发个测试数据,我可以帮你写。。。你可以想个可能出现的条件,可以不用merge。给出的具体代码如下:
companies = []
nums = []
for row in jd_MergeTotal.itertuples(False):
tmp = JD_zhekou.query(f"公司组织编码=='{row.公司编码}'")
companies.append(tmp.公司.iat[0])
discount_dest = None
for _, _, num, discount in tmp.itertuples(False):
min_v, max_v = map(int, num.split("-", maxsplit=1))
if min_v <= row.单量 <= max_v:
discount_dest = discount
break
nums.append(discount_dest)
jd_MergeTotal["公司"] = companies
jd_MergeTotal["折扣"] = nums
jd_MergeTotal[图片上传失败...(image-d60847-1718599326279)]
顺利地解决了粉丝的问题。
如果你也有类似这种Python相关的小问题,欢迎随时来交流群学习交流哦,有问必答!
三、总结
大家好,我是Python进阶者。这篇文章主要盘点了一个Python自动化办公的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【斌】提出的问题,感谢【瑜亮老师】、【不上班能干啥!】、【小小明】给出的思路,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。