大家好,我是皮皮。
一、前言
前几天在Python最强王者群【维哥】问了一个Python自动化办公处理的问题,一起来看看吧。
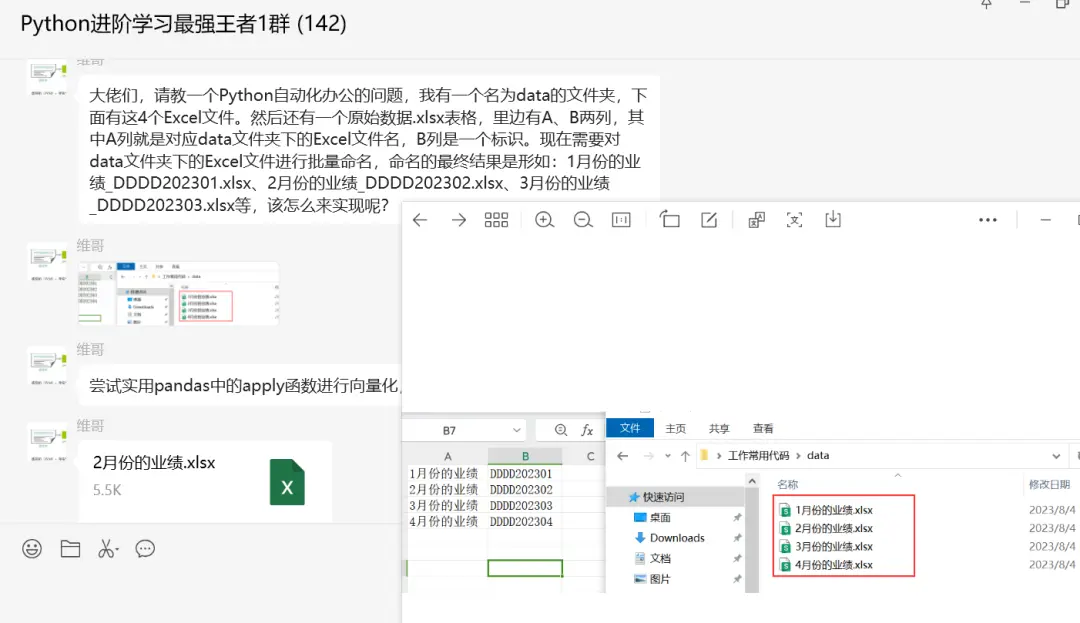
大佬们,请教一个Python自动化办公的问题,我有一个名为data的文件夹,下面有这4个Excel文件。然后还有一个原始数据.xlsx表格,里边有A、B两列,其中A列就是对应data文件夹下的Excel文件名,B列是一个标识。现在需要对data文件夹下的Excel文件进行批量命名,命名的最终结果是形如:1月份的业绩_DDDD202301.xlsx、2月份的业绩_DDDD202302.xlsx、3月份的业绩_DDDD202303.xlsx等,该怎么来实现呢?
二、实现过程
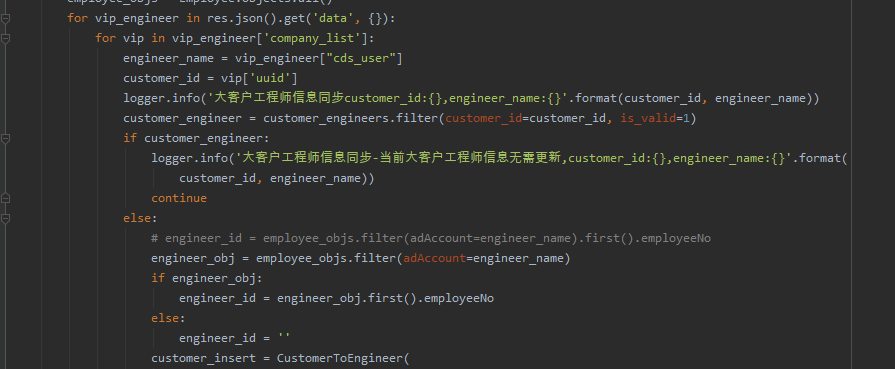
这个问题挺有意思的,而且是工作过程中时常会遇到的工作场景,非常实用,这里给大家一起分享下方法。这里【东哥】提供了一个解决办法,代码如下所示:
import os
import pandas as pd
# 读取原始数据.xlsx文件
df = pd.read_excel('原始数据.xlsx')
# 遍历data文件夹下的Excel文件
data_path = './data/'
files = os.listdir(data_path)
for file in files:
if file.endswith('.xlsx'):
# 获取文件名和文件后缀
file_name, file_ext = os.path.splitext(file)
# 获取月份信息
month = file_name[:2]
# 获取标识信息
id_num = df[df['文件名'] == file_name]['标识'].values[0]
# 新文件名
new_file_name = month + '份的业绩_' + id_num + file_ext
# 文件重命名
os.rename(data_path + file, data_path + new_file_name)代码运行之后,测试无误。
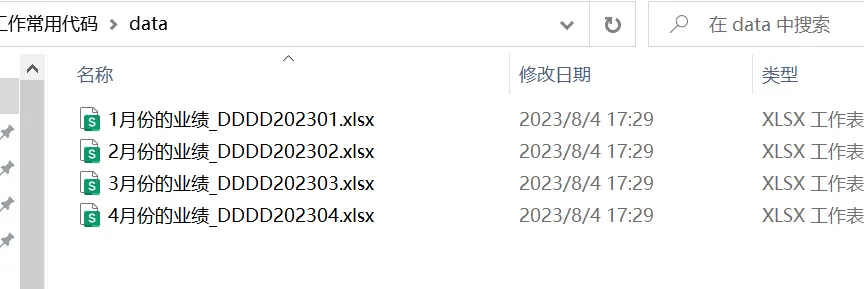
顺利地解决了粉丝的问题。

不过后来【吴超建】发现了一个问题,要是10月11月12月就有问题了,因为取值那块写死了,固定取的[:2],下一篇文章我们一起来看另外一个优化方法,顺利的解决当前的小问题。
三、总结
大家好,我是皮皮。这篇文章主要盘点了一个Python自动化办公Excel列删除处理的问题,文中针对该问题,给出了具体的解析和代码实现,帮助粉丝顺利解决了问题。
最后感谢粉丝【维哥】提问,感谢【吴超建】、【东哥】给出的思路和代码解析,感谢【莫生气】等人参与学习交流。
【提问补充】温馨提示,大家在群里提问的时候。可以注意下面几点:如果涉及到大文件数据,可以数据脱敏后,发点demo数据来(小文件的意思),然后贴点代码(可以复制的那种),记得发报错截图(截全)。代码不多的话,直接发代码文字即可,代码超过50行这样的话,发个.py文件就行。