
作者:京东零售 刘一达
前言
2006年之后SUN公司决定将JDK进行开源,从此成立了OpenJDK组织进行JDK代码管理。任何人都可以获取该源码,并通过源码构建一个发行版发布到网络上。但是需要一个组织审核来确保构建的发行版是有效的, 这个组织就是JCP(Java Community Process)。2009年,SUN公司被Oracle公司"白嫖"(参考2018年Google赔款),此时大家使用的JDK通常都是Oracle公司的OpenJDK构建版本-OracleJDK。但是,Oracle公司是一个明显只讲商业而不管情怀的公司,接手Java商标之后,明显加快了JDK的发布版本。2018年9月25日,JDK11成功发布,这是一个LTS版本,包含了17个JEP的更新。与此同时,Oracle把JDK11起以往的商业特性全部开源给OpenJDK(例如:ZGC和Flight Recorder)。根据Oracle的官方说法(Oracle JDK Releases for Java 11 and Later),从JDK11之后,OracleJDK与OpenJDK的功能基本一致。然后,Oracle宣布以后将会同时发行两款JDK:1. 一个是以GPLv2+CE协议下,由Oracle发行OpenJDK(简称为Oracle OpenJDK);2. 另一个是在OTN协议下的传统OracleJDK。这两个JDK共享绝大多数源码,核心差异在于前者可以免费在开发、测试和生产环境下使用,但是只有半年时间的更新支持。后者各个人可以免费使用,但是生产环境中商用就必须付费,可以有三年时间的更新支持。
2021年9月14日,Oracle JDK17发布,目前也是最新的Java LTS版本。有意思的是,Oracle竟然"朝令夕改",OracleJDK17竟然是免费的开源协议,并支撑长达8年的维护计划。目前公司内部使用的OracleJDK8最高版本为1.8.0.192,而Oracle在JDK8上开源协议支持的最高免费版本为jdk1.8.0_202。2022年Spring6和SpringBoot3相继推出,而支持的最低版本为JDK17。综上所述,JDK8为目前绝大多数以稳定性为主的系统第一选择,但是升级到高版本JDK也只是时间问题。下面图表展示了JDk8到JDK17的每个版本升级的JEP个数。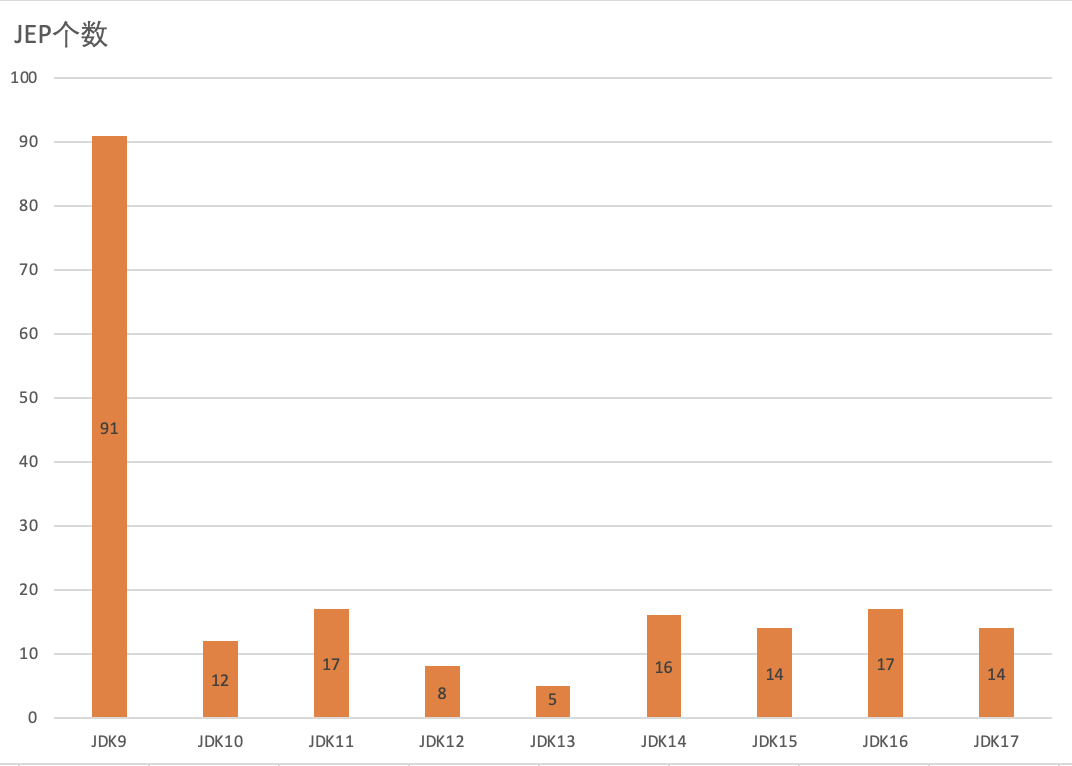
通过以上图表,我们可以得出结论,JDK8到JDK17包含大量新特性,为Oracle在Java近5年来的智慧结晶。目前市面上的公司还是只有少数系统会选择JDK11或者JDK17作为线上技术选型,如果选择从JDK8升级到JDK17必然会有非常大的挑战和较多需要填的坑。本文主要介绍JDK8到JDk17近200个JEP中比较有价值的新特性(按照价值从高到低排序),这里有一部分特性作者也在线上环境使用过,也会将其中的使用心得分享给大家。
核心JEP功能及原理介绍
一、Java平台模块化系统(Jigsaw项目)
JDK9最耀眼的新特性就是Java平台模块化系统(JPMS,Java Platform Module System),通过Jigsaw项目实施。Jigsaw项目是Java发展过程的一个巨大里程碑,Java模块系统对Java系统产生非常深远的影响。与JDK的函数式编程和 Lamda表达式存在本质不同 ,Java模块系统是对整个Java生态系统做出的改变。
同时也是JDK7到JDK9的第一跳票王项目。Jigsaw项目本计划于在2010年伴随着JDK7发布,随着Sun公司的没落及Oracle公司的接手,Jigsaw项目从JDK7一直跳票到JDK9才发布。前后经历了前后将近10年的时间。即使在2017JDK9发布前夕,Jigsaw项目还是差点胎死腹中。原因是以IBM和Redhat为首的13家企业在JCP委员会上一手否决了Jigsaw项目作为Java模块化规范进入JDK9发布范围的规划。原因无非就是IBM希望为自己的OSGI技术在Java模块化规范中争取一席之地。但是Oracle公司没有任何的退让,不惜向JCP发去公开信,声称如果Jigsaw提案无法通过,那么Oracle将直接自己开发带有Jigsaw项目的java新版本。经历了前后6次投票,最终JDK9还是带着Jigsaw项目最终发布了。但是,令人失望的是,Java模块化规范中还是给Maven、Gradle和OSGI等项目保留了一席之地。对于用户来说,想要实现完整模块化项目,必须使用多个技术相互合作,还是增加了复杂性。如果大家想要对模块化技术有更多深入了解,推荐阅读书籍《Java9模块化开发:核心原则与实践》
1、什么是Java模块化?
简单理解,Java模块化就是将目前多个包(package)组成一个封装体,这个封装体有它的逻辑含义 ,同时也存在具体实例。同时模块遵循以下三个核心原则:
强封装性:一个模块可以选择性的对其他模块隐藏部分实现细节。
定义良好的接口:一个模块只有封装是不够的,还要通过对外暴露接口与其他模块交互。因此,暴露的接口必须有良好的定义。
显示依赖:一个模块通常需要协同其他模块一起工作,该模块必须显示的依赖其他模块 ,这些依赖关系同时也是模块定义的一部分。
2、为什么要做模块化?
模块化是分而治之的一个重要实践机制,微服务、OSGI和DDD都可以看到模块化思想的影子。现在很多大型的Java项目都是通过maven或者gradle进行版本管理和项目构建,模块的概念在Maven和gradle中早就存在,两者的不同下文也会说到。现在让我们一起回顾一下目前在使用JDK搭建复杂项目时遇到的一些问题:
2.1 如何使得Java SE应用程序更加轻量级的部署?
java包的本质只不过是类的限定名。jar包的本质就是将一组类组合到一起。一旦将多个Jar包放入ClassPath,最终得到只不过是一大堆文件而已。如何维护这么庞大的文件结构?目前最有效的方式,也是只能依赖mave或者gradle等项目构建工具。那最底层的Java平台的Jar包如何维护?如果我只是想部署一个简答的 helloworld应用,我需要一个JRE和一个用户编译的Jar包,并将这个Jar包放到classpath中去。JDK9以前,JRE的运行依赖我们的核心java类库-rt.jar。rt.jar是一个开箱即用的全量java类库,要么不使用,要么使用全部。直到JDK8,rt.jar的大小为60M,随着JDK的持续发展,这个包必然会越来越大。而且全量的java类库,给JRE也带来了额外的性能损耗。Java应用程序如果能选择性的加载rt.jar中的文件该多好?
2.2 在暴露的JAR包中,如何隐藏部分API和类型?
在使用Dubbo等RPC框架中,provider需要提供调用的接口定义Jar包,在该Jar包中包含一个共该Jar包内部使用的常量聚合类Constannt,放在constant包内。如何才能暴露JAR包的同时,隐藏常量聚合类Constant?
2.3 一直遭受NoClassDefFoundError的折磨
通过什么方式,可以知道一个Jar包依赖了哪些其他的 Jar包?JDK本身目前没有提供,可以通过Maven工具完成。那为什么不让Java平台自身就提供这些功能?
3、JPMS如何解决现有问题?
JPMS具有两个重要的目标:
强封装(Strong encapsulation): 每一个模块都可以声明了哪些包是对外暴露的,java编译和运行时就可以实施这些规则来确保外部模块无法使用内部类型。
可靠配置(Reliable configuration):每一模块都声明了哪些是它所需的,那么在运行时就可以检查它所需的所有模块在应用启动运行前是否都有。
Java平台本身就是必须要进行模块化改造的复杂项目,通过Jigsaw项目落地。
3.1 Project Jigsaw
Modular development starts with a modular platform. —Alan Bateman 2016.9
模块化开始于模块化平台 。Project Jigsaw 有如下几个目标:
可伸缩平台(Scalable platform):逐渐从一个庞大的运行时平台到有有能力缩小到更小的计算机设备。
安全性和可维护性(Security and maintainability):更好的组织了平台代码使得更好维护。隐藏内部API和更明确的接口定义提升了平台的安全性。
提升应用程序性能(Improved application performance):只有必须的运行时runtimes的更小的平台可以带来更快的性能。
更简单的开发体验Easier developer experience:模块系统与模块平台的结合使得开发者更容易构建应用和库。
对Java平台进行模块化改造是一个巨大工程,JDK9之前,rt.jar是个巨大的Java运行时类库,大概有60MB左右。JDK9将其拆分成90个模块左右 ,如下图所示(图片来源《Java 9模块化开发》):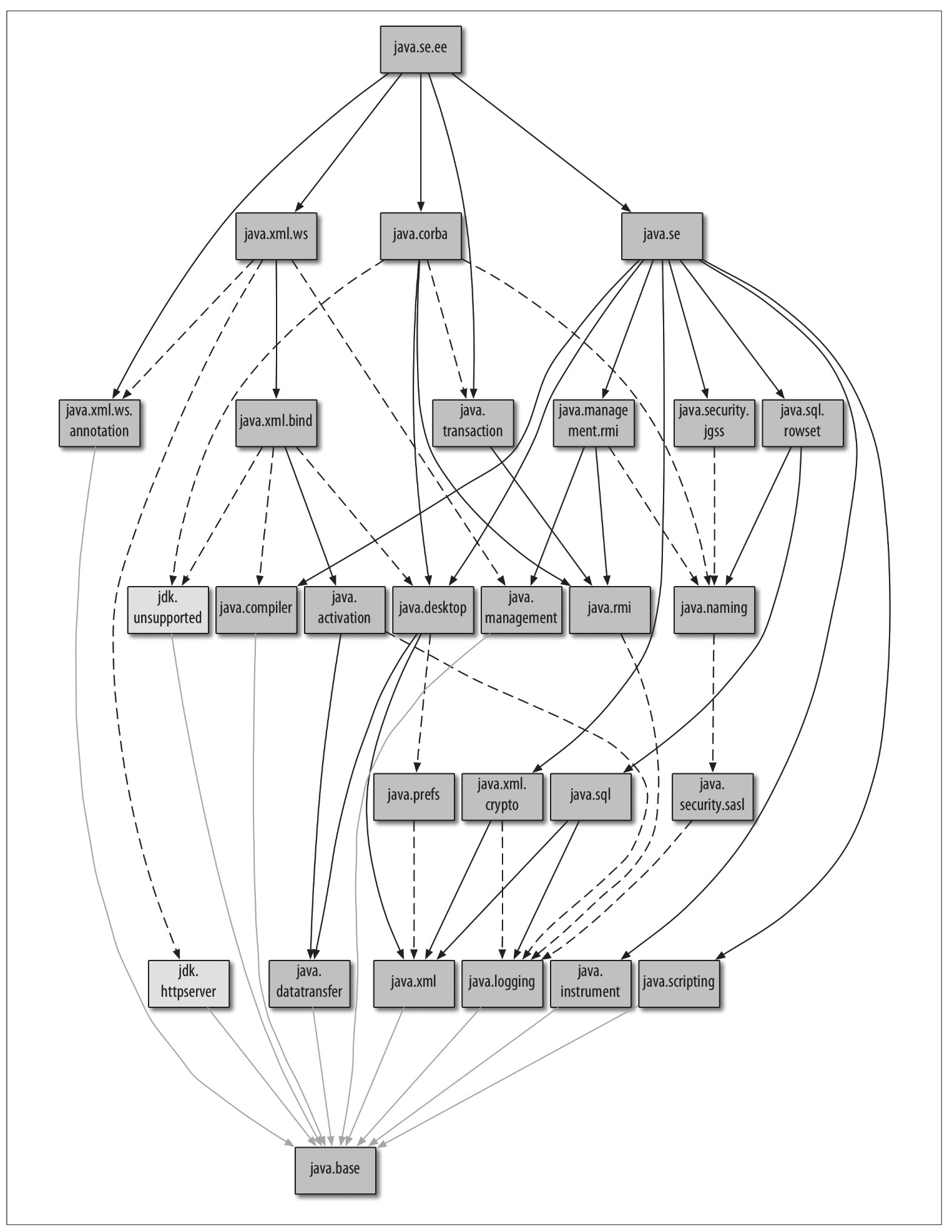
4 创建第一个Java模块
创建一个Java模块其实非常的简单。在目前Maven结构的项目下,只需要在java目录下,新建一个module-info.java文件即可。此时,当前目录就变成了一个Java模块及Maven模块。
--moudule1
---src
----main
-----java
------com.company.package1
------moudule-info.java
---pom.xml
5 模块化对现有应用的影响
5.1 你可以不用但是不能不懂
Java模块化目前并没有展现出其宣传上的影响,同时也鲜有类库正在做模块化的改造。甚至,本人在创建第一个模块的时候,就遇到了Lombook失效、深度反射失败、Spring启动失败以及无法动态部署的影响。因此,尽量不要尝试在线上环境使用模块化技术!不用,但是不代表你可以不懂!随着Java平台模块化的完成,运行在JDK9环境的Java程序就已经面临着Jar包和模块的协作问题。未雨绸缪,在发现问题的时候,模块化技术可以帮你快速的定位问题并解决问题。
例如,在从JDK8升级到JDK11时,我们经常会收到一下警告:
WARNING: An illegal reflective access operation has occurred
WARNING: Illegal reflective access by com.jd.jsf.java.util.GregorianCalendar_$$_Template_1798100948_0 (file:/home/export/App/deliveryorder.jd.com/WEB-INF/lib/jsf-1.7.2.jar) to field java.util.Calendar.fields
WARNING: Please consider reporting this to the maintainers of com.jd.jsf.java.util.GregorianCalendar_$$_Template_1798100948_0
WARNING: Use --illegal-access=warn to enable warnings of further illegal reflective access operations
WARNING: All illegal access operations will be denied in a future release
通过反射访问JDK模块内类的私有方法或属性,且当前模块并未开放指定类用于反射访问,就会出现以上告警。解决方式也必须使用模块化相关知识,可以使用遵循模块化之间的访问规则,也可以通过设置 –add-opens java.base/java.lang = ALL-UNNNAMED 破坏模块的封装性方式临时解决;
5.2 Java模块、Maven模块和OSGI模块的之间的关系。
Java模块化技术,理论上可以从Java底层解决模块和模块之间的模块依赖、多版本、动态部署等问题。 前文所述,在2017JDK9发布前夕,以IBM和Redhat为首的13家企业在JCP委员会上一手否决了Jigsaw项目作为Java模块化规范进入JDK9发布范围的规划。经过众多权衡,Java模块化规范中还是给Maven、Gradle和OSGI等项目保留了一席之地。目前,可以通过Java模块+Maven模块或者Java模块+OSGI模块的方式构建项目,可惜的是,使用多个技术相互合作,还是增加了复杂性。
5.3 模块化对类加载机制的影响
JDK9之后,首先取消了之前的扩展类加载器,这是清理之中,因为本身JRE扩展目录都已经不存在,取而代之的是平台类加载器。然后,类加载器的双亲委派模型机制进行了破坏,在子类将类委派给父类加载之前,会优先将当前类交给当前模块(Moudle)或层(Layer)的类加载器加载。所以会形成如下的类加载模型: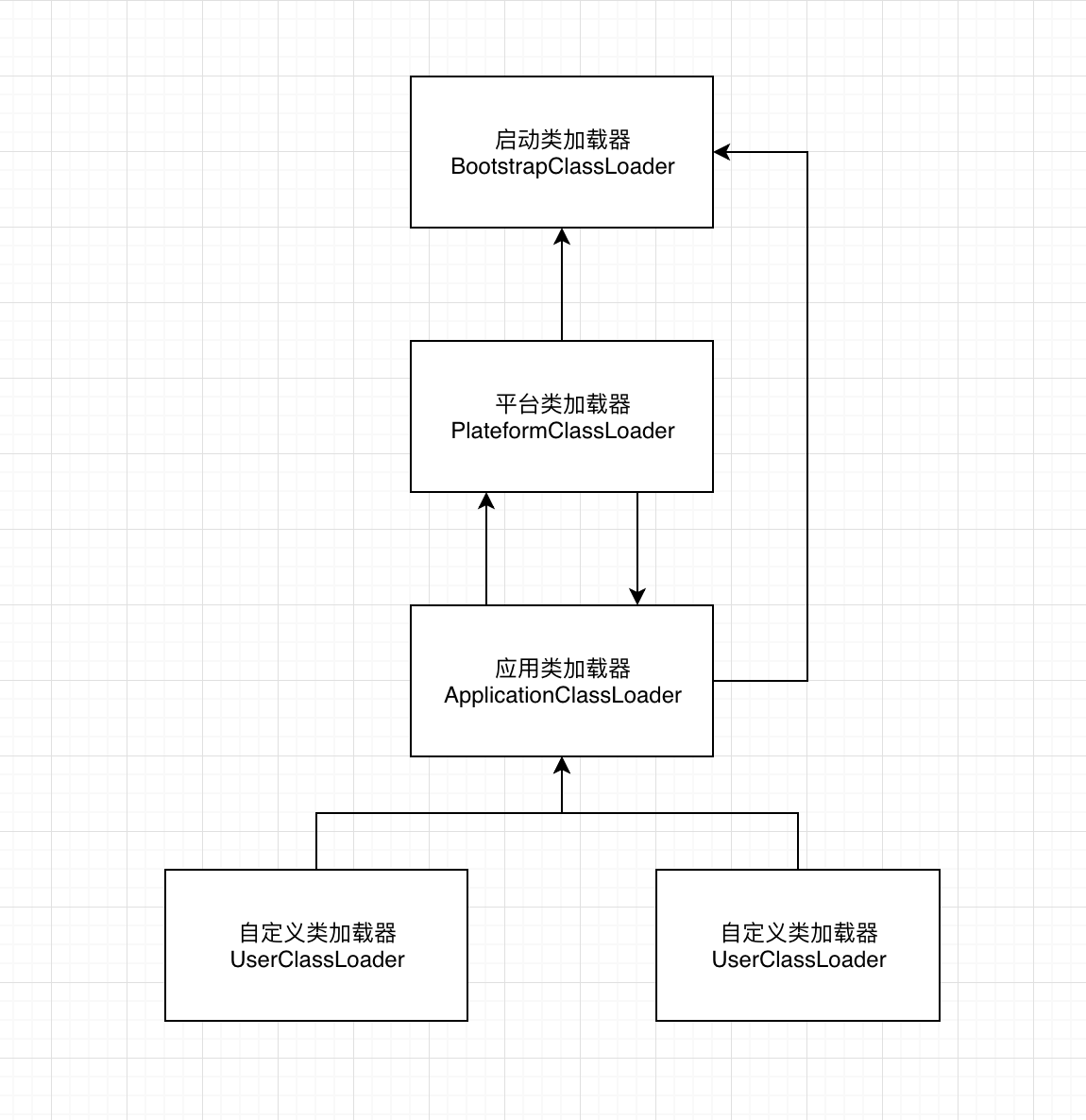
同时,在JDK9之后,引入的层(Layer)的概念,在Java程序启动时,会解析当前模块路径中的依赖关系,并形成一个依赖关系图包含在引导层(Bootstrap Layer)中,这个依赖关系图从此开始不再改变。因此,现在动态的新增模块要创建新的层,不同的层之间可以包含相同的模块。会形成如下所示的依赖关系(图片来源《Java 9模块化开发》):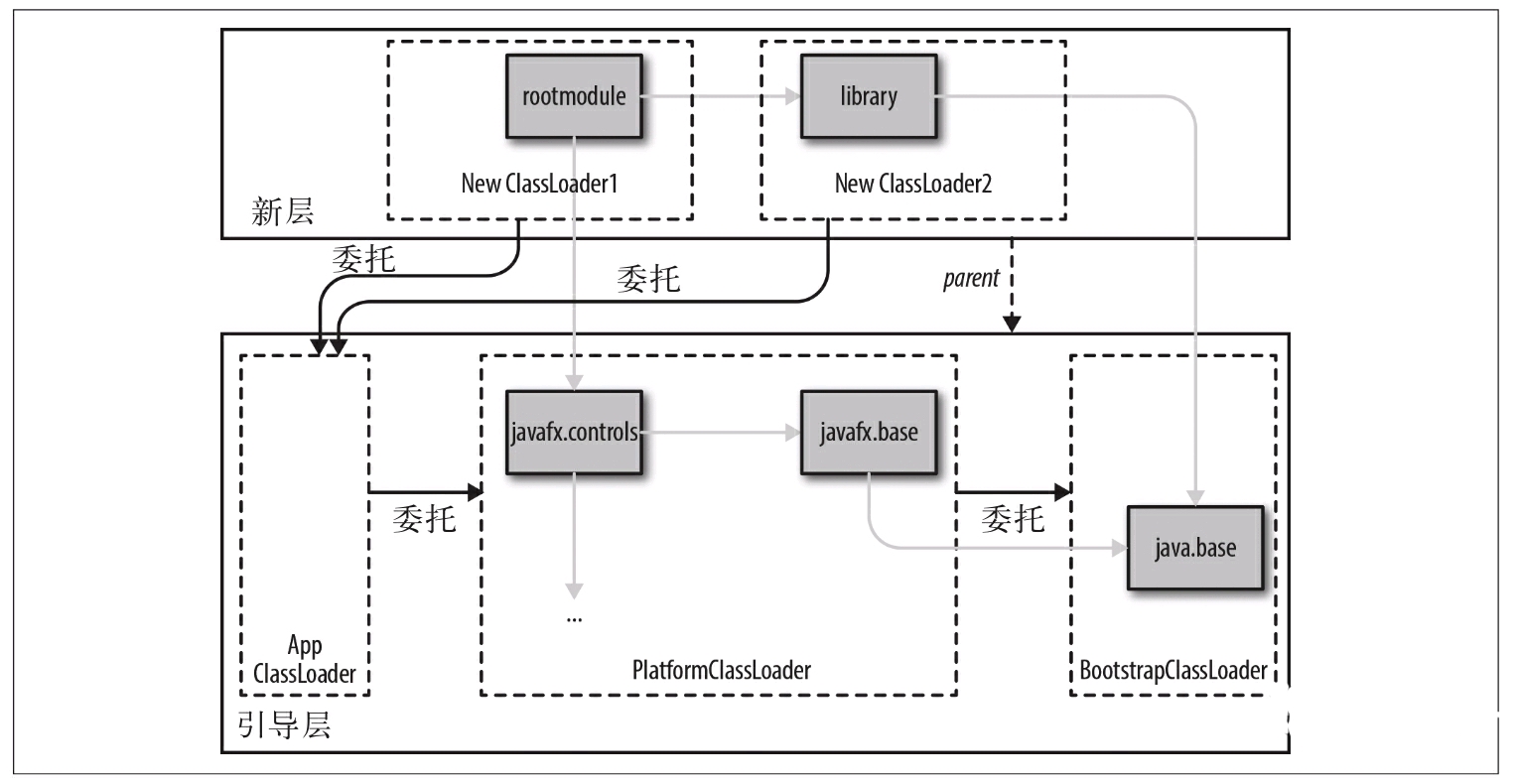
综上所述,模块化改造对于使用自定义类加载器进行功能动态变化的程序还是巨大的,一旦使用模块化,必然会导致这类功能受到巨大影响。当然模块化技术普及还需要很长一段时间,会晚但是不会不来,提前掌握相关技术还是很必要。
5.4 总结
下面是Java模块化相关技术的一些核心脑图,可以学习参考: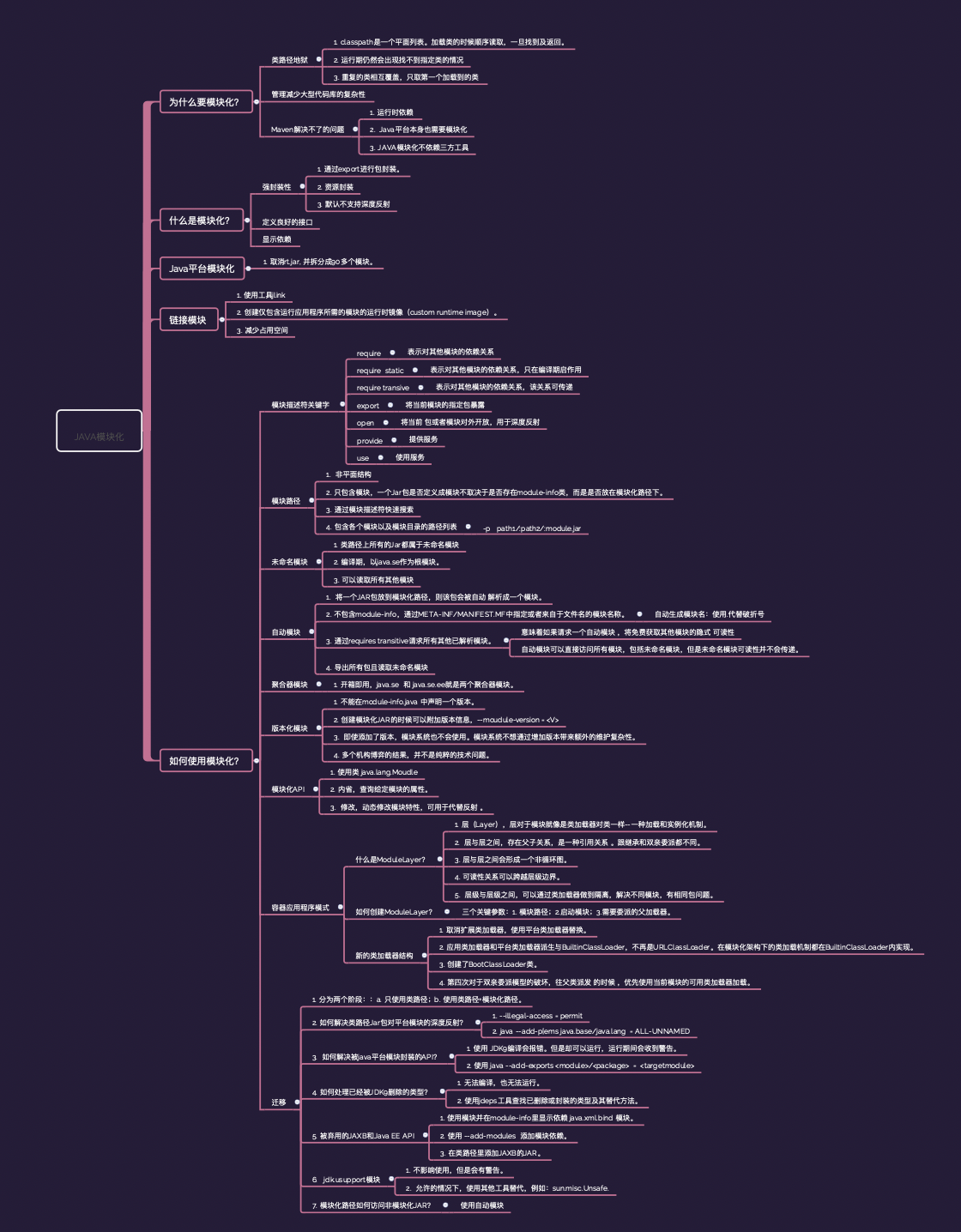
二、垃圾回收器的一系列优化措施
2.1、ZGC-新一代垃圾回收器
JDK11中,最耀眼的新特性就是ZGC垃圾回收器。作为实验性功能,ZGC的特点包括:
GC停顿时间不会超过10ms。
停顿时间不会随着堆的大小,或者活跃对象的大小而增加;
相对于G1垃圾回收器而言,吞吐量降低不超过15%;
支持Linux/x64、window和mac平台;
支持8MB~16TB级别的堆回收。
同时根据openJDK官方的性能测试数据显示(JEP333),ZGC的表现非常的出色:
在仅关注吞吐量指标下,ZGC超过了G1;
在最大延迟不超过某个设定值(10到100ms)下关注吞吐量,ZGC较G1性能更加突出。
在仅关注低延迟指标下,ZGC的性能高出G1将近两个数量级。99.9th仅为G1的百分之一。
也正是因为如此,ZGC简直是低延迟大内存服务的福音。话说如此,作者在尝试使用ZGC过程中还是发现一些问题:
因为整个ZGC周期基本都是并发执行,因此创建新对象的速度与垃圾回收的速度从一开始就在较量。如果创建新对象的速度更胜一筹,垃圾会将堆占满导致部分线程阻塞,直到垃圾回收完毕。
G1虽然是第一个基于全局的垃圾回收器,但是仍然存在新生代和老年代的概念。但是从ZGC开始,完全抛弃了新生代和老年代。但是新生代对象朝生夕灭的特性会给ZGC带来很大的压力。完全的并发执行,必然会造成一定的吞吐量降低。
在JDK11,G1垃圾回收器目前还只是实验性的功能,只支持Linux/x64平台。后续优化接改进,短时间内无法更新到JDK11中,所以可能会遇到一些不稳定因素。例如: 1. JDK12支持并发类卸载功能。2. JDK13将可回收内存从4TB支持到16TB。3. JDK14提升稳定性的同时,提高性能。4. JDK15从实验特性转变为可生产特性 。所以如果想要使用稳定的ZGC功能,只能升级到JDK17,横跨一个JDK11LTS版本,同时面临近200个JEP带来的功能更新。
实际线上生产环境,在订单商品等核心系统尝试使用ZGC。但是压测结果显示,在JDK11还是JDK17都差强人意。当然这并不是代表ZGC本身技术缺陷,而是需要根据不同的线上环境做更深度的调优和实践。因为数据保密等原因,这里没有给大家展示具体的压测数据,读者可以在各自环境进行不同程度的压测验证。
ZGC的原理介绍需要极大的篇幅,本文不打算对ZGC的底层技术展开大范围讨论。如果大家想要深入学习,作者推荐书籍《新一代垃圾回收器ZGC设计与实现》、Openjdk官网:ZGC介绍以及《深入理解Java虚拟机第五版》中的一些介绍。
2.2、G1垃圾回收器相关
总的来讲,得益于多个JEP优化,G1垃圾回收器无论是在JDK11还是JDK17都表现出了更强大的能力。随着CMS垃圾回收器的废弃,以及新生代ZGC的初出茅庐,G1垃圾回收器毫无疑问成了兼顾延迟和吞吐的最佳选择。通过多次压测结果观察,只是简单的提高JDK版本,就可以做到更低的GC时间、更短的GC间隔以及更少的CPU损耗。
| 场景 | JDK | 并发 | 基线参考 | TPS | TPM | TP99 | TP999 | TP9999 | MAX CPU |
|---|---|---|---|---|---|---|---|---|---|
| 1.8.0_192 | 20 | -Xms12g -Xmx12g -XX:+UseG1GC -XX:ParallelGCThreads=13 -XX:ConcGCThreads=4 | 1680 | 97640 | 10 | 28 | 31 | 32 | 50.07% |
| 11.0.8 | 20 | -Xms12g -Xmx12g -XX:+UseG1GC -XX:ParallelGCThreads=13 -XX:ConcGCThreads=4 | 1714 | 99507 | 10 | 23 | 27 | 29 | 49.35% |
2.2.1、G1的Full GC从串行改为并行(JEP307)
G1垃圾回收器,在 Mix GC回收垃圾的速度小于新对象分配的速度时,会发生Full GC。之前,发生Full GC时采用的是Serial Old算法,该算法使用单线程标记-清除-压缩算法,垃圾回收吞吐量较高,但是Stop-The-World时间变长。JDK10,为了减少G1垃圾回收器在发生Full GC时对应用造成的影响,Full GC采用并行标记-清除-压缩算法。该算法可以通过多线程协作 ,减少Stop-The-World时间。线程的数量可以由-XX:ParallelGCThreads选项来配置 ,但是这也会影响Young GC和Mixed GC线程数量。
2.2.2、可中断的Mixed-GC(JEP344)
G1垃圾回收器,通过一种名为CSet的数据结构辅助实现可预测停顿模型算法。CSet中存储了GC过程中可进行垃圾回收的Region集合。在本特性之前,CSet一旦被确定,就必须全部扫描并执行回收操作,这可能会导致超过预期的垃圾回收暂停时间。因此,JEP344针对这种问题进行了优化。Java12 中将把 Cset拆分为强制及可选两部分。有限执行强制部分的CSet,执行完成之后如果存在剩余时间,则继续处理可选Cset部分,从而让GC暂停时间更接近预期值。
2.2.3 G1支持NUMA技术(JEP345)
非统一内存访问架构(英语:non-uniform memory access,简称NUMA)是一种为多处理器的电脑设计的内存架构,内存访问时间取决于内存相对于处理器的位置。在NUMA下,处理器访问它自己的本地内存的速度比非本地内存(内存位于另一个处理器,或者是处理器之间共享的内存)快一些。ParallelGC在前几年已经开始支持NUMA技术,并且对于垃圾回收器性能有较大提升。可惜的是,G1垃圾回收器在JDK14之前一直不支持此项技术,现在可以通过参数+XX:+UseNUMA在使用G1垃圾回收器时使用NUMA技术。
2.3、废弃CMS垃圾回收器
CMS垃圾回收器在JDK9彻底被废弃,在JDK12直接被删除。目前,G1垃圾回收器是代替CMS的最优选择之一。
2.4、废弃ParallelScavenge + SerialOld 垃圾回收器组合
Java垃圾回收器有多种多样的组合和使用方式。下面这张图,我大概看过不差10遍,可是每次结果也是相同,记不住!!!!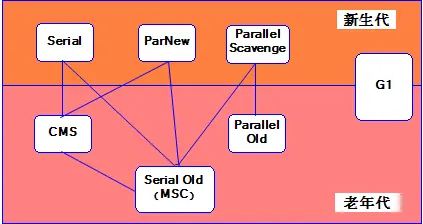
默认垃圾回收器是哪些?
-XX:+UseParallelGC -XX:-UseParallelOldGC -XX:+UseParallelGC -XX:+UseParNewGC 这几个参数有什么区别?
CMS垃圾回收器有哪些关键参数?浮动垃圾怎么处理?如何避免Full GC产生?
好消息!这些以后都不用记忆了,我们只需要专注攻克三款垃圾回收器原理:默认大哥G1、新晋新星ZGC、非亲儿子Shanondoah(了解)。这里也许有人会抬杠,小内存CMS会有更好的表现。ParNew仍然是高吞吐服务的首选。大道至简,简单易用才是王道。G1和ZGC必定是以后JVM垃圾回收器的重点发展方向,与其耗费精力记忆即将淘汰的技术,不如利出一孔,精通一门!
2.4、Epsilon:低开销垃圾回收器
Epsilon 垃圾回收器的目标是开发一个控制内存分配,但是不执行任何实际的垃圾回收工作。下面是该垃圾回收器的几个使用场景:性能测试、内存压力测试、极度短暂 job 任务、延迟改进、吞吐改进。
三、诊断和监控相关优化
3.1 Java Flight Recorder[JEP328]
Java Flight Recorder (JFR) 从正在运行的 Java 应用程序收集诊断和分析数据。 根据SPECjbb2015基准压测结果显示,JFR 对正在运行的 Java 应用程序的性能影响低于1%。 对于JFR的统计数据,可以使用 Java Mission Control (JMC) 和其他工具分析。 JFR 和 JMC 在 JDK 8 中是商业付费功能,而在 JDK11 中都是免费开源的。
3.2 Java Mission Control [JMS]
Java Mission Control (JMC) 可以分析并展示 Java Flight Recorder (JFR) 收集的数据,并且在 JDK 11 中是开源的。除了有关正在运行的应用程序的一般信息外,JMC 还允许用户深入了解数据。 JFR 和 JMC 可用于诊断运行时问题,例如内存泄漏、GC 开销、热点方法、线程瓶颈和阻塞 I/O。JMC可以作为现有JVM监控工具的一个补充,做到维度更多,监控更加实时(秒级),能从多个视角监控当前JVM进程的性能,更加更快速的定位并解决问题。
3.3 统一 JVM 日志(JEP158)
在以往的低版本中很难知道导致JVM性能问题和导致JVM崩溃的根本原因。不同的JVM对日志的使用是不同的机制和规则,这就使得JVM难以进行调试。
解决这个问题最佳的方法:对所有的JVM组件引入一个统一的日志框架,这些JVM组件支持细粒度的和易配置的JVM日志。 JDK8以前常用的打印GC日志方式:
-Xloggc:/export/Logs/gc.log //输出GC日志到指定文件
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
3.3.1 目标:
所有日志记录的通用命令行选项。
通过tag对日志进行分类,例如:compiler, gc, classload, metaspace, svc, jfr等。一条日志可能会含有多个 tag
日志包含多个日志级别:error, warning, info, debug, trace, develop。
可以将日志重定向到控制台或者文件。
error, warning级别的日志重定向到标准错误stderr.
可以根据日志大小或者文件数对日志文件进行滚动。
一次只打印一行日志,日志之间无交叉。
日志包含装饰器,默认的装饰器包括:uptime, level, tags,且装饰可配置。
3.3.2 如何使用
-Xlog[:option]
option := [][:[][:[][:]]]
'help'
'disable'
what := [,...]
selector := [*][=]
tag-set := [+...]
'all'
tag := name of tag
level := trace
debug
info
warning
error
output := 'stderr'
'stdout'
[file=]
decorators := [,...]
'none'
decorator := time
uptime
timemillis
uptimemillis
timenanos
uptimenanos
pid
tid
level
tags
output-options := [,...]
output-option := filecount=
filesize=
parameter=value
可以通过配置-Xlog:help参数,获取常用的JVM日志配置方式。
可以通过-Xlog:disable参数关闭JVM日志。
默认的JVM日志配置如下:
-Xlog:all=warning:stderr:uptime,level,tags - 默认配置 - 'all' 即是包含所有tag - 默认日志输出级别warning,位置stderr - 包含uptime,level,tags三个装饰可以参考使用如下配置:
JDK9之前参数-XX:+PrintGCDetails可参考:
-Xlog:safepoint,classhisto*=trace,age*,gc*=info:file=/export/Logs/gc-%t.log:time,tid,level,tags:filecount=5,filesize=50MB - safepoint表示打印用户线程并发及暂停执行时间 - classhisto表示full gc时打印堆快照信息 - age*,gc* 表示打印包括gc及其细分过程日志,日志级别info,文件:/export/Logs/gc.log。 - 日志格式包含装饰符:time,tids,level,tags - default output of all messages at level 'warning' to 'stderr' will still be in effect - 保存日志个数5个,每个日志50M大小查看GC前后堆、方法区可用容量变化,在JDK9之前,可以使用-XX::+PrintGeapAtGC,现在可参考:
-Xlog:gc+heap=debug:file=/export/Logs/gc.log:time,tids,level,tags:filecount=5,filesize=1M - 打印包括gc及其细分过程日志,日志级别info,文件:/export/Logs/gc.log。 - 日志格式包含装饰符:time,tids,level,tags - default output of all messages at level 'warning' to 'stderr' will still be in effect - 保存日志个数5个,每个日志1M大小
JDK9之前的GC日志:
2014-12-10T11:13:09.597+0800: 66955.317: [GC concurrent-root-region-scan-start]
2014-12-10T11:13:09.597+0800: 66955.318: Total time for which application threads were stopped: 0.0655753 seconds
2014-12-10T11:13:09.610+0800: 66955.330: Application time: 0.0127071 seconds
2014-12-10T11:13:09.614+0800: 66955.335: Total time for which application threads were stopped: 0.0043882 seconds
2014-12-10T11:13:09.625+0800: 66955.346: [GC concurrent-root-region-scan-end, 0.0281351 secs]
2014-12-10T11:13:09.625+0800: 66955.346: [GC concurrent-mark-start]
2014-12-10T11:13:09.645+0800: 66955.365: Application time: 0.0306801 seconds
2014-12-10T11:13:09.651+0800: 66955.371: Total time for which application threads were stopped: 0.0061326 seconds
2014-12-10T11:13:10.212+0800: 66955.933: [GC concurrent-mark-end, 0.5871129 secs]
2014-12-10T11:13:10.212+0800: 66955.933: Application time: 0.5613792 seconds
2014-12-10T11:13:10.215+0800: 66955.935: [GC remark 66955.936: [GC ref-proc, 0.0235275 secs], 0.0320865 secs]
JDK9统一日志框架输出的日志格式 :
[2021-02-09T21:12:50.870+0800][258][info][gc] Using G1
[2021-02-09T21:12:51.751+0800][365][info][gc] GC(0) Pause Young (Concurrent Start) (Metadata GC Threshold) 60M->5M(4096M) 7.689ms
[2021-02-09T21:12:51.751+0800][283][info][gc] GC(1) Concurrent Cycle
[2021-02-09T21:12:51.755+0800][365][info][gc] GC(1) Pause Remark 13M->13M(4096M) 0.959ms
[2021-02-09T21:12:51.756+0800][365][info][gc] GC(1) Pause Cleanup 13M->13M(4096M) 0.127ms
[2021-02-09T21:12:51.758+0800][283][info][gc] GC(1) Concurrent Cycle 7.208ms
[2021-02-09T21:12:53.232+0800][365][info][gc] GC(2) Pause Young (Normal) (G1 Evacuation Pause) 197M->15M(4096M) 17.975ms
[2021-02-09T21:12:53.952+0800][365][info][gc] GC(3) Pause Young (Concurrent Start) (GCLocker Initiated GC) 114M->17M(4096M) 15.383ms
[2021-02-09T21:12:53.952+0800][283][info][gc] GC(4) Concurrent Cycle
四、更加优雅的语法或者方法
4.1、集合工厂方法
List,Set 和 Map 接口中,新的静态工厂方法可以创建不可变集合。
// 创建只有一个值的可读list,底层不使用数组
static <E> List<E> of(E e1) {
return new ImmutableCollections.List12<>(e1);
}
// 创建有多个值的可读list,底层使用数组
static <E> List<E> of(E e1, E e2, E e3) {
return new ImmutableCollections.List12<>(e1, e2,e3);
}
// 创建单例长度为0的Set结合
static <E> Set<E> of() {
return ImmutableCollections.emptySet();
}
static <E> Set<E> of(E e1) {
return new ImmutableCollections.Set12<>(e1);
}
4.2、接口私有方法
Java 8, 接口可以有默认方法。Java9之后,可以在接口内实现私有方法实现。
public interface HelloService {
public void sayHello();
// 默认方法
default void saySomething(){
syaEngHello();
sayHello();
};
// 私有方法
private void syaEngHello(){
System.out.println("Hello!");
}
}
4.3、改进的 Stream API
Java 9 为 Stream 新增了几个方法:dropWhile、takeWhile、ofNullable,为 iterate 方法新增了一个重载方法。
// 循环直到第一个满足条件后停止
default Stream takeWhile(Predicate predicate);
// 循环直到第一个满足条件后开始
default Stream dropWhile(Predicate predicate);
// 根据表达式生成迭代器
static Stream iterate(T seed, Predicate hasNext, UnaryOperator next);
// 使用空值创建空的Stream,避免空指针
static Stream ofNullable(T t);
4.4、JShell
JShell 是 Java 9 新增的一个交互式的编程环境工具。它允许你无需使用类或者方法包装来执行 Java 语句。它与 Python 的解释器类似,可以直接 输入表达式并查看其执行结果。
4.5、局部类型推断(JEP286)
JDK10推出了局部类型推断功能,可以使用var作为局部变量类型推断标识符,减少模板代码的生成 ,本质还是一颗语法糖。同时var关键字的用于与lombok提供的局部类型推断功能也基本相同。
public static void main(String[] args) throws Exception {
var lists = List.of("a", "b", "c");
for (var word : lists) {
System.out.println(word);
}
}
var关键字只能用于可推断类型的代码位置,不能使用于方法形式参数,构造函数形式参数,方法返回类型等。标识符var不是关键字,它是一个保留的类型名称。这意味着var用作变量,方法名或则包名称的代码不会受到影响。但var不能作为类或则接口的名字。
var关键字的使用确实可以减少很多没必要的代码生成。但是,也存在自己的缺点:1. 现在很多IDE都存在自动代码生成的快捷方式,所以使不使用var关键字区别不大。2. 局部类型推断,不光是编译器在编译时期要推断,后面维护代码的人也要推断,会在一定程度上增加理解成本。
4.6、标准Java HTTP Client
使用过Python或者其他语言的HTTP访问工具的人,都知道JDK提供的HttpURLConnection或者Apache提供的HttpClient有多么的臃肿。简单对比一下。
python 自带的urllib工具:
response=urllib.request.urlopen('https://www.python.org') #请求站点获得一个HTTPResponse对象
print(response.read().decode('utf-8')) #返回网页内容
JDK:
HttpURLConnection connection = (HttpURLConnection) new URL("http://localhost:8080/demo/list?name=HTTP").openConnection();
connection.setRequestMethod("GET");
connection.connect();
int responseCode = connection.getResponseCode();
log.info("response code : {}", responseCode);
// read response
try (BufferedReader reader = new BufferedReader(new InputStreamReader(connection.getInputStream()))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} finally {
connection.disconnect();
}
Apache HttpClient:
CloseableHttpClient httpClient = HttpClientBuilder.create().build();
// 创建Get请求
HttpGet httpGet = new HttpGet("http://localhost:12345/doGetControllerOne");
// 响应模型
CloseableHttpResponse response = null;
// 由客户端执行(发送)Get请求
response = httpClient.execute(httpGet);
// 从响应模型中获取响应实体
HttpEntity responseEntity = response.getEntity();
System.out.println("响应状态为:" + response.getStatusLine());
Java 9 中引入了标准Http Client API 。并在 Java 10 中进行了更新的。 到了Java11,在前两个版本中进行孵化的同时,Http Client 几乎被完全重写,并且现在完全支持异步非阻塞。与此同时它是 Java 在 Reactive-Stream 方面的第一个生产实践,其中广泛使用了 Java Flow API。
HttpClient client = HttpClient.newHttpClient();
HttpRequest request = HttpRequest.newBuilder()
.uri(URI.create("http://openjdk.java.net/"))
.build();
client.sendAsync(request, BodyHandlers.ofString())
.thenApply(HttpResponse::body)
.thenAccept(System.out::println)
.join();
4.7、Helpful NullPointerExceptions(JEP358)
随着流式编程风格的流行,空指针异常成为了一种比较难定位的BUG。例如:
a.b.c.i = 99;
a[i][j][k] = 99;
在之前,我们只能收到以下异常堆栈信息,然后必须借助DEBUG工具调查问题:
Exception in thread "main" java.lang.NullPointerException
at Prog.main(Prog.java:5)
优化后,我们可以得到更加优雅的空指针异常提示信息:
Exception in thread "main" java.lang.NullPointerException:
Cannot read field "c" because "a.b" is null
at Prog.main(Prog.java:5)
Exception in thread "main" java.lang.NullPointerException:
Cannot load from object array because "a[i][j]" is null
at Prog.main(Prog.java:5)
4.8、更加优雅的instance of 语法(JEP394)
以下代码是每个Java开发工程师的一块心病:
if (obj instanceof String) {
String s = (String) obj; // grr...
...
}
上面的instanc of语法一共做了三件事:
判断是否为String类型;
如果是,转成String类型;
创建一个名为s的临时变量;
在JDK16中,使用模式匹配思想改进了instance of 用法,可以做到以下优化效果:
if (obj instanceof String s) {// obj是否为String类型,如果是创建临时变量s
// Let pattern matching do the work!
...
}
我们可以看到,整体代码风格确实优雅了很多。变量s的作用域为满足条件的判断条件范围之内。因此,以下使用也是合法的:
if (obj instanceof String s && s.length() > 5) {// 因为&&具有短路功能
flag = s.contains("jdk");
}
但是以下用法,则会报错:
if (obj instanceof String s || s.length() > 5) { // Error!
...
}
合理使用,则可以达到以下效果:
// 优化使用前
public final boolean equals(Object o) {
if (!(o instanceof Point))
return false;
Point other = (Point) o;
return x == other.x
&& y == other.y;
}
// 优化使用后:
public final boolean equals(Object o) {
return (o instanceof Point other)
&& x == other.x
&& y == other.y;
}
4.9、更加优雅的Switch用法
Java里有一句名言:可以用switch结构实现的程序都可以使用if语句来实现。而且Swtich语法在某些工程师眼里,根本没有if语句简洁。JDK14中提供了更加优雅的swtich语法,例如:
// 之前
switch (day) {
case MONDAY:
case FRIDAY:
case SUNDAY:
System.out.println(6);
break;
case TUESDAY:
System.out.println(7);
break;
case THURSDAY:
case SATURDAY:
System.out.println(8);
break;
case WEDNESDAY:
System.out.println(9);
break;
}
// 之后
switch (day) {
case MONDAY, FRIDAY, SUNDAY -> System.out.println(6);
case TUESDAY -> System.out.println(7);
case THURSDAY, SATURDAY -> System.out.println(8);
case WEDNESDAY -> System.out.println(9);
}
还可以把switch语句当成一个表达式来处理:
T result = switch (arg) {
case L1 -> e1;
case L2 -> e2;
default -> e3;
};
static void howMany(int k) {
System.out.println(
switch (k) {
case 1 -> "one";
case 2 -> "two";
default -> "many";
}
);
}
还可以配合关键字yield,在复杂处理场景里,返回指定值:
int j = switch (day) {
case MONDAY -> 0;
case TUESDAY -> 1;
default -> {
int k = day.toString().length();
int result = f(k);
yield result;
}
};
还有吗?其实在JDK17中,还提出了Swtich 模式匹配的预览功能,可以做到更优雅的条件判断:
// 优化前
static String formatter(Object o) {
String formatted = "unknown";
if (o instanceof Integer i) {
formatted = String.format("int %d", i);
} else if (o instanceof Long l) {
formatted = String.format("long %d", l);
} else if (o instanceof Double d) {
formatted = String.format("double %f", d);
} else if (o instanceof String s) {
formatted = String.format("String %s", s);
}
return formatted;
}
// 优化后
static String formatterPatternSwitch(Object o) {
return switch (o) {
case Integer i -> String.format("int %d", i);
case Long l -> String.format("long %d", l);
case Double d -> String.format("double %f", d);
case String s -> String.format("String %s", s);
default -> o.toString();
};
}
五、字符串压缩-Compact Strings(JEP254)
字符串是我们日常编程中使用最频繁的基本数据类型之一。目前,字符串类底层都使用了一个字符数组来实现,每个字符使用2个字节(16位)空间。实际上,大量的字符都属于Latin-1字符范围内,我们只需要一个字节就能存储这些数据,因此这里有巨大的可压缩空间;SPECjbb2005压测结果显示对于GC时间及GC时间间隔都有一定程度的提升。详细原理文档也可以参考【Oracle对CompackStrings分享】
六、 Java Flow API
Reactive Streams是一套非阻塞背压的异步数据流处理规范。从Java9开始,Java原生支持Reactive Streams编程规范。Java Flow API是对Reactive Streams编程规范的1比1复刻,同时意味着从Java9开始,JDK本身开始在Reactive Streams方向上进行逐步改造。
七、新一代JIT编译器 Graal
即时编译器在提高JVM性能上扮演着非常重要的角色。目前存在两JIT编译器:编译速度较快但对编译后的代码优化较低的C1编译器;编译速度较慢但编译后的代码优化较高的C2编译器。两个编译器在服务端程序及分层编译算法中扮演着非常重要的角色。但是,C2编译器已经存在将近20年了,其中混乱的代码以及部分糟糕的架构使其难以维护。JDK10推出了新一代JIT编译器Graal(JEP317)。Graal作为C2的继任者出现,完全基于Java实现。Graal编译器借鉴了C2编译器优秀的思想同时,使用了新的架构。这让Graal在性能上很快追平了C2,并且在某些特殊的场景下还有更优秀的表现。遗憾的是,Graal编译器在JDK10中被引入,但是在JDK17(JEP410)中被废除了,理由是开发者对其使用较少切维护成本太高。开发者也可以通过使用GraalVM来使用Graal编译器;
总结
本文介绍了JDK9-JDK17升级过的近200个JEP中作者狭隘角度认为价值较高的功能做了一个综述类介绍。主要目的有两个:
通过本文,大家可以对即将使用的JDK11及JDK17新特性有一个笼统的了解,希望可以看到一些Java预发最近几年的发展方向。
通过本文也可以看出,从JDK9到JDK17,Java生态还是生机勃勃。大量功能的更新意味着更优秀的性能及更高效的开发效率,积极主动的尝试高版本JDK;
当然,JDK8到JDK17还有需求优秀的新特性,例如:shanondoah垃圾回收器、Sealed Classes、Records; 鉴于本人能力有限,文中会出现一些漏洞,希望大家找出并指正,让本文成长为后续JDK17升级的扫盲手册;






