
本文翻译自 Superset 的官方文档:Toturial - Creating your first dashboard
最新版本的 Superset 界面与功能上与文档中提到的会有些许出入,以实际的为主。本文仅作翻译
入门教程-创建你的第一个看板
本教程的目标用户是那些想要在 Superset 中创建图表与看板的人。我们将会展示如何通过 Superset 去连接到一个新的数据库并且配置这个库中的一张表以用于分析。同时你也能够通过已经添加上来的数据库去探索数据,可以添加可视化的图表到看板中。通过本教程你能有一个端到端(end-to-end)的用户体验。
连接到一个新的数据库
假设你已经有一个配置好的数据库,并且能够通过正在运行 Superset 的环境中进行连接。如果你仅仅是想体验一下 Supertest 和探索一些样本数据,那么你可以加载 PostgreSQL样本数据集 到一个新的数据库中,或者配置我们在这节中将要使用到的 天气样本数据。
在数据源菜单下,选择_数据库_选项:
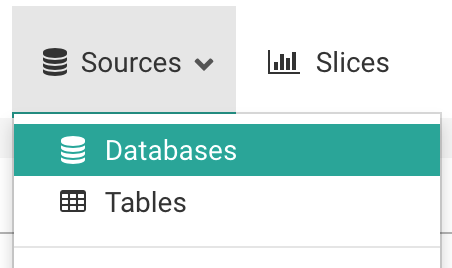
在跳转的结果页面中,选择右上角的绿色“+”号:
你可以在这个页面配置许多高级选项,但对于本教程来说,你只需要配置如下两项就好了:
- 给要添加进来的数据库起个名字:

- 输入 SQLAlchemy 连接 URI 并且测试连接:

上图展示了连接用于测试的天气数据库的连接。如 URI 下面的文本所示,你可以参考 SQLAlchemy 文档中的 创建新的连接 URI 来连接目标数据库。
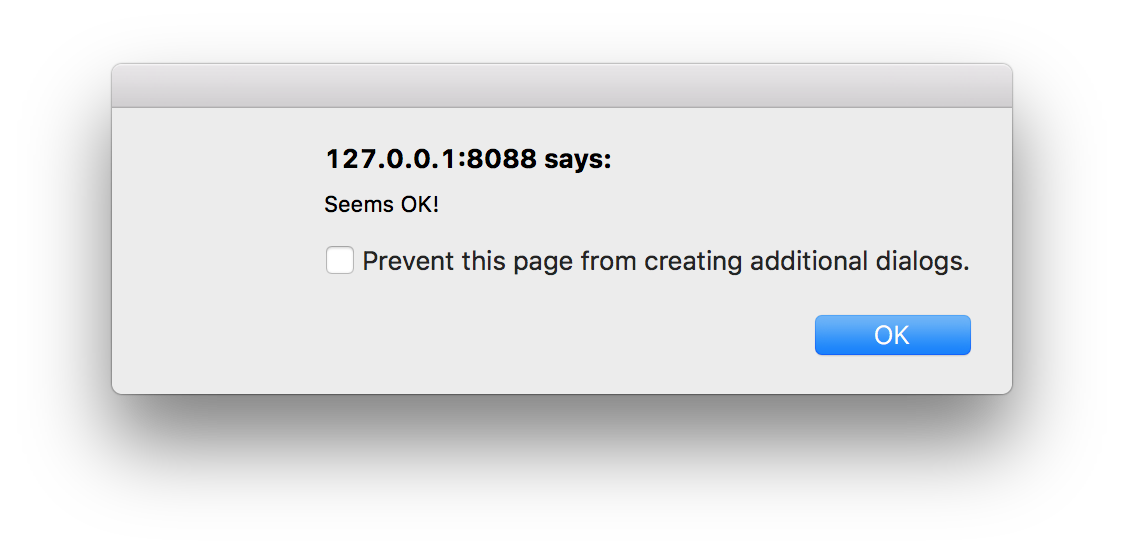
点击 测试连接 按钮来确认两端都没问题。如果 Superset 能够成功连接并获得授权,那么你将看到如下弹窗提醒:
此外,你应该能够在页面底部看到 Superset 能够读取到的、你刚添加的数据库中已经创建的表:

如果连接没问题,点击位于页面底部的 保存 按钮来保存这个配置:
添加新表
到此数据库已经配置好了,你需要添加一个将要用于查询的具体的表到 Superset 中。
在 数据源 按钮下,选择 数据表 选项:
在跳转的结果页中,单击右上角的绿色“+”号按钮:
为了添加新表到 Superset 中你只需要添加少许的几个信息即可:
- 表名

- 在 数据库 下拉列表中选择目标库(例如,你刚才添加上去的一个)
- 可选的,数据库的 schema。如果数据表是存在于默认的 schema 中(例如 PostgreSQL 或者 Redshift 中的 _public_),那么该选项可以留空。
单击 保存 按钮来保存配置:
当页面重定向到数据表清单页面后,你应该能看到一条信息提示说你的表已经创建好了:

这条信息同时也告诉你可以编辑表配置。我们当前将仅会编辑一小部分配置-为了能让你开始-同时剩下一些留在高级教程中。
在你刚才创建的表旁边单击编辑按钮:
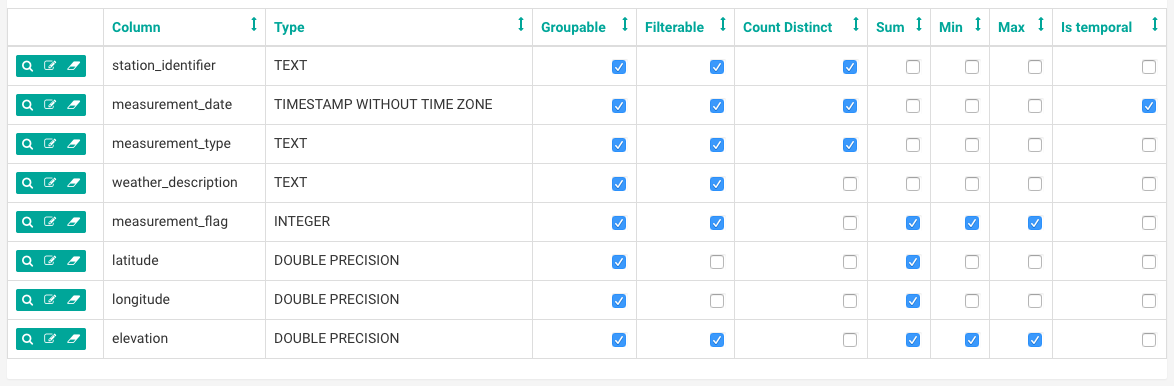
在结果页中,点击 列列表 标签。在这里,你可以定义一些在探索数据时使用到的具体列。我们将会历遍这些选项去描述它们的作用:
- 如果你希望用户根据具体的列来进行分组,那么在 可分组 下勾选它
- 如果你需要根据具体的列来进行过滤,那么在 可过滤 下勾选它
- 是否有一些字段你需要去统计它的唯一值个数的?勾选 唯一性统计
- 是否有一些字段你需要去求和的,或者想要得到一些基本的统计信息?那么 求和、最小值、最大值 列会有帮助
- 所有的日期或者时间字段,都应该勾选上 表示时间(原文是 is temporal )。我们将会在稍后讲述它们是如何操作的。
(译注:目前我安装上的版本中,只剩下可分组、可过滤、表示时间这三个选项了)
以下是已经针对天气数据配置好的字段。对于天气数据的测量(比如降雨量、降雪量等等)来说,根据以下这些字段它已经足够去分组和过滤的了:
如上图所示,点击 保存 按钮以保存这些配置。
探索数据
要探索数据,只需要在表列表中点击你刚才创建的表的名字即可:

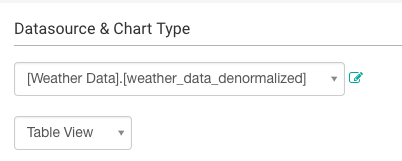
默认地,展现在你面前的是表视图(Table View):
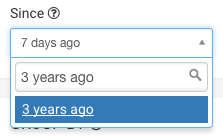
让我们使用一些基本的查询来统计表中的所有记录数。首先,我们需要更改 时间(Since)过滤器来取得数据的时间范围,你可以通过一些简单的词语来应用这个筛选,例如“3年前”:
而这个时间区间的上限,在 Until 过滤器中,默认是 现在,当然这个可能并不是你想要的。
再看到位于 分组 下方的 指标 部分,可以在其中输入 “Count” —— 你会看到一个根据你的输入而匹配出来的指标列表:
选择 COUNT(*) 指标,然后点击位于探索器顶部旁边的绿色按钮:
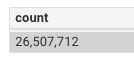
你将会右侧的表格里看到查询结果:
让我们在 分组 区域中,以 weather_description 字段为分组,取得以天气记录类型为分类的记录数有多少:
执行查询:

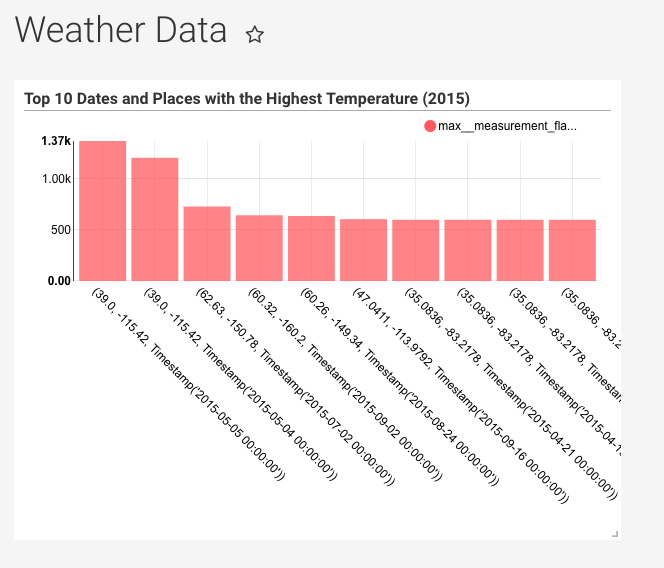
让我们查找一个更加有用的数据:在 2015 年有记录的温度最高的时间和地点的 TOP 10。
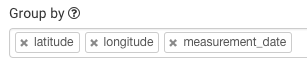
在 分组 区域中,把 weather_description 替换为 latitude_,_longitude 和 _measurement_date_:
同时在 指标 区域中,把 COUNT(*) 替换为 _max__measurement_flag_:

max__measurement_flag 指标是在我们前面配置表的时候,勾选了 measurement_flag 字段对应的 Max 选框而创建的,指明这个字段是一个数值并且当需要根据指定的字段进行分组的时候我们要在其中查询它的最大值。
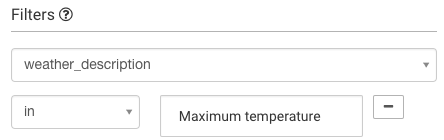
在本案例中,measurement_flag 是测量所需要使用到的值,它很明显是依赖于测量的类别的(研究者会记录不同的降雨量和气温的值)。因此,我们必须仅在 weather_description 相等于 “Maximum temperature” 的记录中过滤我们的查询,这个过滤会在探索器窗口底部的 过滤 模块中进行:
最后,由于我们仅关心 top 10,所以我们要限制我们的查询结果为 10 条记录,通过位于 Options 头下方的 行限制 来实现:

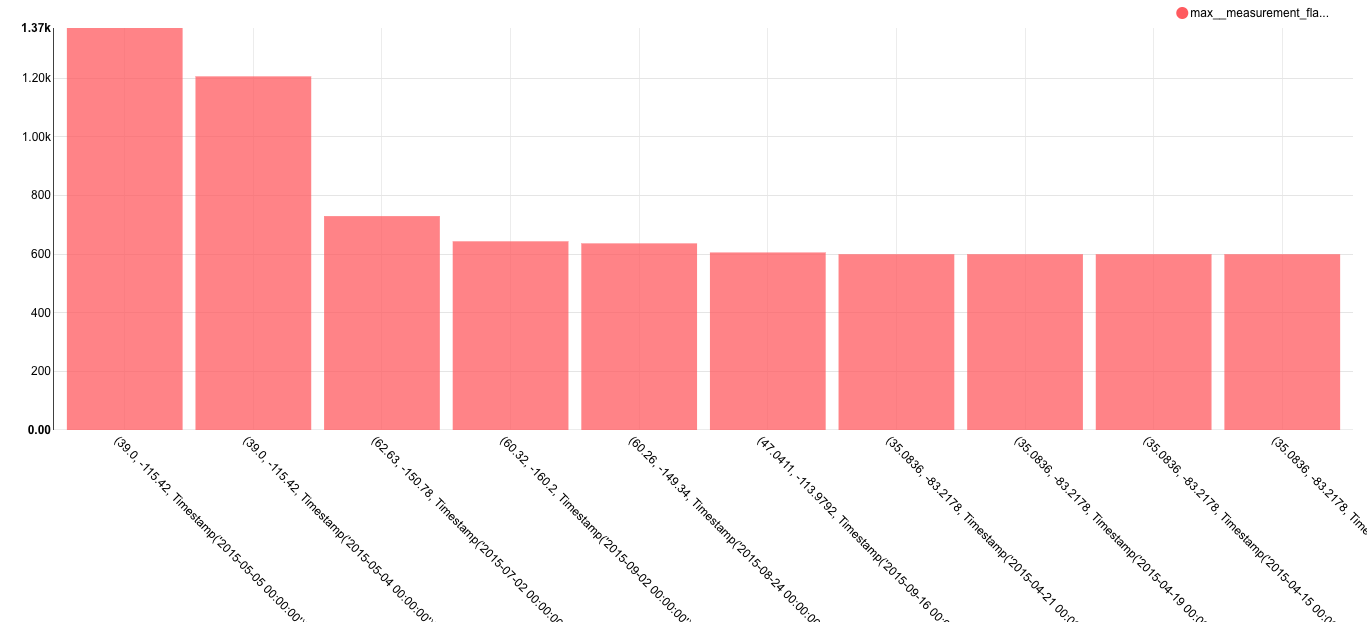
点击 查询 然后可以得到如下的结果:
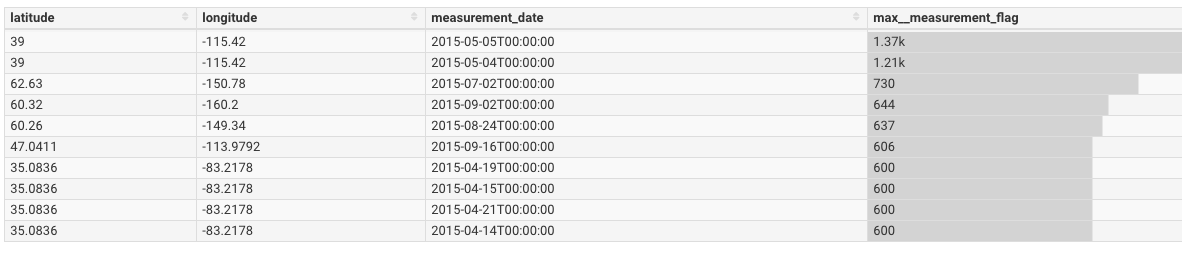
在这个数据集中,最高温度以十分之一摄氏度记录( is recorded in tenths of a degree Celsius)。最大值是 1370,在内华达州中部测量得到的,相当于 137 摄氏度,或约等于 278 华氏度。这个数据可能是错的。我们已经使用 Superset 探查了一些异常值,但这仅仅是冰山一角。
你可以通过这些方法来做许多事情:
- 默认的显示数值的格式是 1.37k,是不便于人们阅读的。可能你会更加喜欢使用全的、使用逗号分隔的值。通过修改配置(编辑 表配置 > 列出 SQL 指标 > 编辑指标 > D3 格式)你可以更改任何一个指标数据的格式。
- 此外,可能你想把温度直接以原生的摄氏度来显示,而不是显示它的 10 倍值,又或者你需要把它转换成华氏度来显示。你可以修改针对数据库执行的 SQL 语句,将转换逻辑直接映射到指标本身(编辑 表配置 > 列出 SQL 指标 > 编辑指标 > SQL 表达式)。
现在,让我们为这些数据创建一个更好的可视化图表并且把它添加到看板中。
我们更改图表类型为 “分布-柱状图”:
我们前面设置的对最高温度指标的过滤器可以保留,但是查询语句和格式选项是依赖于图表类型的,因此你必须要再次配置这些值:
你应该注意到了,对于这个图表来说,它有更多的格式化选项:设置轴标签、外边距、刻度等等。为了在更多的受众面前展示图表,你可能会想要应用多个这些图表并且把它们添加到看板中。现在,我们执行查询并且得到如下的图表:
创建切片和看板
这些图可能对于研究者来说是有用的,因此让我们来保存它。在 Superset 中,一个保存好的查询被称为一个 切片(Slice)。
为了创建切片,单击位于探索器左上角的保存按钮:
此时会有一个弹窗出现,要求填写切片的名字,和一个是否要添加到看板的可选项。由于我们还没有创建任务看板,这里我们可以创建一个同时直接添加我们的切片到这个看板中:
点击保存,然后你会被重定向回原来的查询界面。同时可以看到我们的切片和看板都已经成功创建了:

来检查一下我们的新看板。点击 看板 菜单:

找到刚才创建的看板:

一切安好-我们的切片也在这里:
但是它比我们预期的要小一点。幸运的是,你可以调整在看板中的切片。点击它,保持鼠标按下不要放开并且拖动右下角直到你想要的大小:

调整完之后,你会被提示去点击看板左上方的按钮来保存这个新的配置。
恭喜你!你已经成功地在 Superset 中连接、分析并且进行了数据可视化操作。这里面有许许多多的表配置与可视化选项,所以请开始探索与创建你自己的切片和看板吧。
本翻译版权归本人 博客园-东围居士 所有,转载请注明出处













