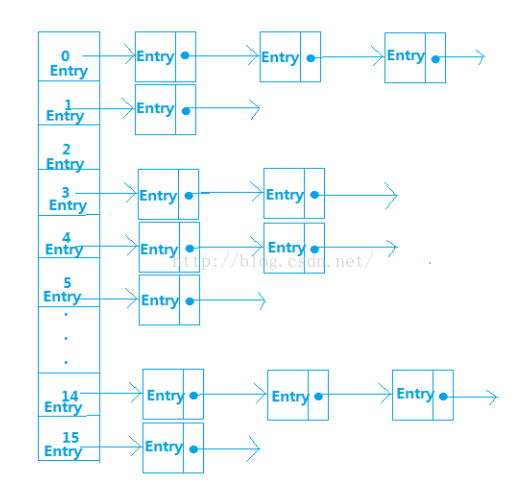
一、简介和应用 哈希表(Hash Table)是一种高效的数据结构,通过键值对(key-value)存储数据,提供快速的插入、删除和查找操作。它使用哈希函数将键映射到表中的位置,使得平均时间复杂度可以达到O(1)。
应用场景:数据库索引、缓存实现(如Redis)、字典和符号表、编译器中的变量管理、网络路由表、密码存储和验证。
二、特点和注意事项 特点:
1.快速访问:平均时间复杂度O(1) 2.灵活大小:可以动态调整容量 3.冲突处理:使用链表法解决哈希冲突 4.简单接口:提供插入、删除、查找基本操作 5.内存效率:相比其他数据结构更节省空间 三、实现步骤解析 定义键值对结构:创建存储键值对的pairs结构 实现链表节点:模板化的链表节点用于处理冲突 哈希表类设计: 初始化哈希表数组 提供默认和指定大小的构造函数 核心操作实现: 插入:计算哈希地址,处理冲突 删除:查找并移除指定键 查找:快速定位键对应的值 辅助功能: 打印整个哈希表内容 四、完整代码和注释
#include<iostream>using namespACe std;// 键值对结构体struct pairs {
int key; // 键
int val; // 值};// 链表节点模板template<typename T>struct listnode {
T val; // 存储的值
listnode* next=nullptr; // 下一个节点指针
// 默认构造函数
listnode() {}
// 带值构造函数
listnode(T v) {
val = v;
}};// 哈希表类class hash_map {
listnode<pairs>** map; // 哈希表数组(链表指针数组)
int size; // 哈希表大小
public:
// 默认构造函数(大小1000)
hash_map() {
size = 1000;
map = new listnode<pairs>*[size]; // 分配数组
for (int i = 0; i < size; i++) {
map[i] = nullptr; // 初始化每个槽位为空
}
}
// 指定大小的构造函数
hash_map(int size) {
this->size = size;
map = new listnode<pairs>*[size];
for (int i = 0; i < size; i++) {
map[i] = nullptr;
}
}
// 插入键值对
void ins(pairs pair) {
int address = pair.key % size; // 计算哈希地址
listnode<pairs>* newnode = new listnode<pairs>(pair); // 创建新节点
listnode<pairs>* tmp = map[address]; // 获取槽位头节点
// 如果槽位为空,直接插入
if (!tmp) {
map[address] = newnode;
return;
}
// 否则找到链表末尾插入
while (tmp->next) {
tmp = tmp->next;
}
tmp->next = newnode;
}
// 删除指定键的节点
void del(int key) {
int address = key % size; // 计算哈希地址
listnode<pairs>* tmp = map[address]; // 获取槽位头节点
// 如果头节点就是要删除的节点
if (tmp->val.key == key) {
map[address] = map[address]->next; // 跳过该节点
return;
}
// 否则遍历查找要删除的节点
while (tmp->next->val.key != key) {
tmp = tmp->next;
}
tmp->next = tmp->next->next; // 跳过要删除的节点
}
// 查找指定键的值
int find(int key) {
int address = key % size; // 计算哈希地址
listnode<pairs>* tmp = map[address]; // 获取槽位头节点
// 遍历链表查找键
while (tmp and tmp->val.key != key) {
tmp = tmp->next;
}
// 如果没找到返回-1
if (!tmp) return -1;
// 找到返回对应的值
return tmp->val.val;
}
// 打印整个哈希表
void print() {
for (int i = 0; i < size; i++) {
listnode<pairs>* tmp = map[i]; // 获取每个槽位的头节点
// 打印该槽位的所有键值对
while (tmp) {
cout << tmp->val.key << ":" << tmp->val.val << " ";
tmp = tmp->next;
}
cout << endl;
}
cout << endl;
}};五、总结 哈希表是一种极其重要的数据结构,本文通过C++实现展示了其基本原理和核心操作。理解哈希表的工作原理对于学习更高级的数据结构和算法至关重要。在实际应用中,可以根据需求调整哈希函数、冲突解决策略和扩容机制来优化性能。 链接:哈希表