大家好,我是IT共享者,人称皮皮。
前面几天给大家分享了MySQL数据库知识,没来得及看的小伙伴可以前往:Mysql查询语句进阶知识集锦,一篇文章教会你进行Mysql数据库和数据表的基本操作,关于数据库的安装可以参考:手把手教你进行Mysql5.x版本的安装及解决安装过程中的bug。
上篇文章主要给大家介绍了Sqlite数据库的安装、图形化管理系统、基本数据类型、基本关键字和数据库的相关操作,干货|Sqlite数据库知识必知必会(上篇),今天皮皮紧接上篇文章,继续给大家分享数据库知识,一起来看看吧。
前言
前面我们学习了很多数据库,虽然它们功能非常丰富,但是占用空间比较大,使得我们的系统负荷变大,这对于我们新手小白来说不是一个理想的选择,于是乎,Sqlite闪亮登场,它受人喜爱的真正原因正是因为它足够小,无需安装和管理配置,简单容易上手,支持数据库的大小也有2TB,足够我们个人开发爱好者使用了。
一、数据表相关操作
1).创建数据表
CREATE TABLE student (
ID INTEGER DEFAULT '1406061' PRIMARY KEY AUTOINCREMENT NOT NULL,
NAME NVARCHAR(100) UNIQUE NOT NULL,
score INTEGER NOT NULL,
time TIMESTAMP NOT NULL
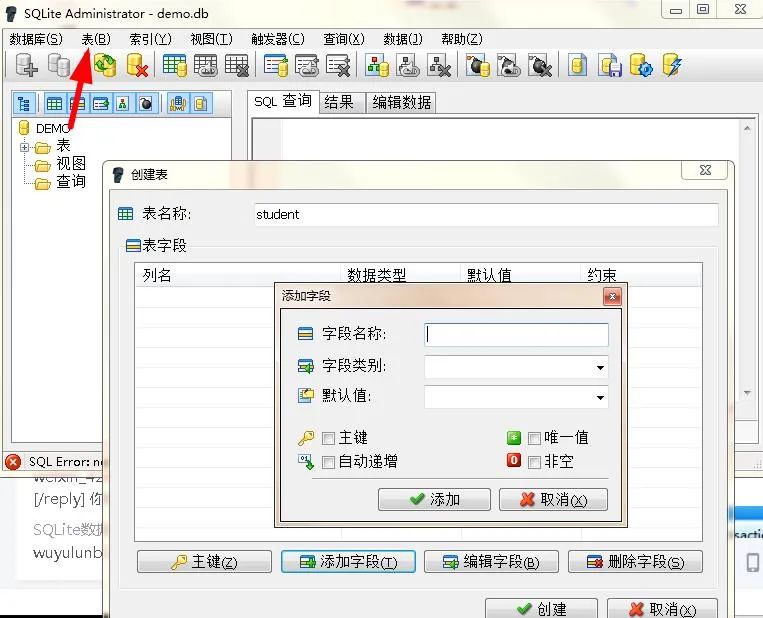
);我们可以使用SqliteAdmin快速生成表,如下:

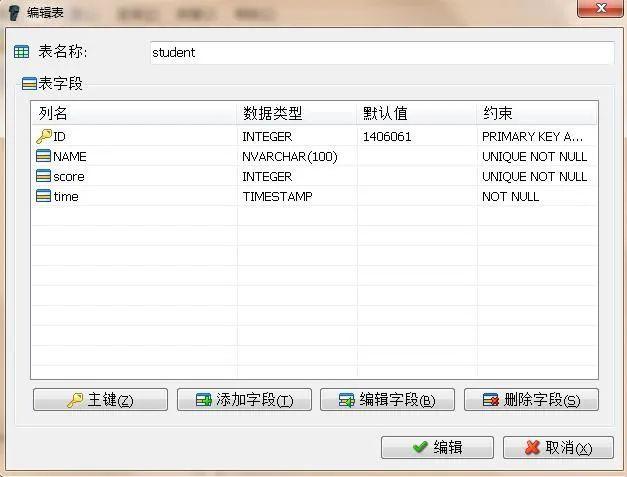
这样我们的表就建立成功了。这里小编在软件中用的是DEMO这个数据文件,而在命令窗口中用的是TEST这个数据库文件,因为一个数据库文件不允许在两个位置打开的缘故。
2).删除表
DROP TABLE people;3).显示表名
.tables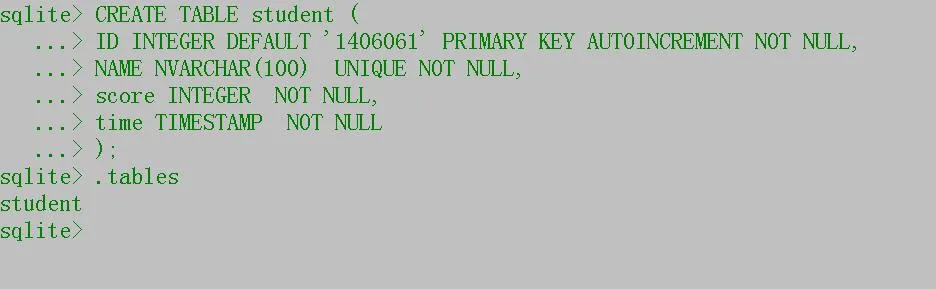
4).数据表的增删改查
1)).增加
这里我们可以给刚创建的表添加一个数据,如下:
insert into student(ID,NAME,score,time) values(1406063,'任性的90后boy',90,'2020-07-06 12:23:32');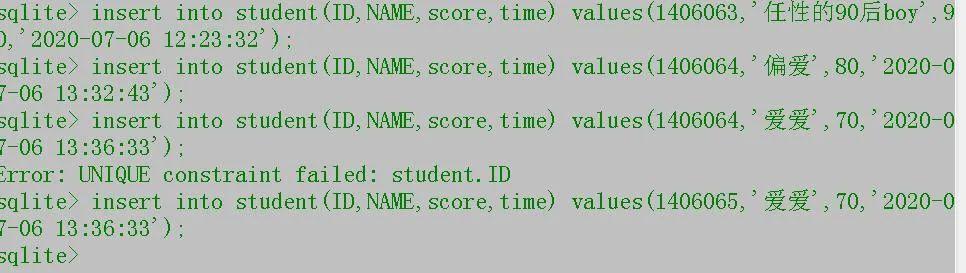
这里我插入了三行数据,其中有一行报错是因为我使用了相同的ID号,而我的数据库的ID号是不允许重复的,故而会报错,改成其它的就好了,如果你把ID设为自增的话,就不需要你去写了,这里我用到了自增,所以大家不必写Sqlite会自动填充进去的。这里也可以省掉字段名,直接写值,如下:
我们还可以给表添加新列,如下;
alter table people add column aa char(10);#添加列并且列名为aa注:Sqlite3并不支持带有UNIQUE约束的列
2)).删除
delete from people;#删除表数据
delete from people where score<20#删除people数据表score数值小于20的记录3)).修改
其实就是更新操作,如下;
update people set score=100 where age=46;#当age=46时score设置为100查找不管是在哪个数据库中方法都是相当多的,因为查询操作是最常见也是最频繁的,下面我们就来详细说说:
1))).查询所有的结果
select * from student;
我们可以看到虽然结果打印出了,但是并不是那么美观,我们将它的打印格式化一下,如下;

这下就完美多了。虽然这种方法很不错,但是如果数据列很多的话就无法完全显示了,这个时候我们就需要设置列的宽度,如下:
.width 10 20 152))).查询指定结果
select NAME,score from student; #打印出NAME和score列的结果
select * from people where score<20 and age<40;#当score小于20并且age小于40的时候
select *from people where score between 10 and 30;#当score为10~30之间时
select *from people where NAME LIKE '放大%';#当name的开始处含有放大
select *from people where NAME glob '放大*';#与上同
select *from where score not in(12,23);#当score不属于12~233))).查找排序
select * from people order by score desc; #对score降序排序4))).查找指定数量的数据
select * from people limit 3 offset 2#偏移2个单位然后输出三行数据,其实就是输出后三行数据5))).查找重复数据并消除
select distinct * from people where score>10;#当score大于10的时候消除重复数据6))).查找数据并进行分组
select NAME ,max(age) from people where score>10 group by age#返回score大于10的时候age的最大值7))).查找数据进行分组并过滤分组
select NAME ,max(age) from people where score>10 group by age having count(NAME)>1;#名称计数大于15).表的重命名
alter table people rename to man;#将表名people改为man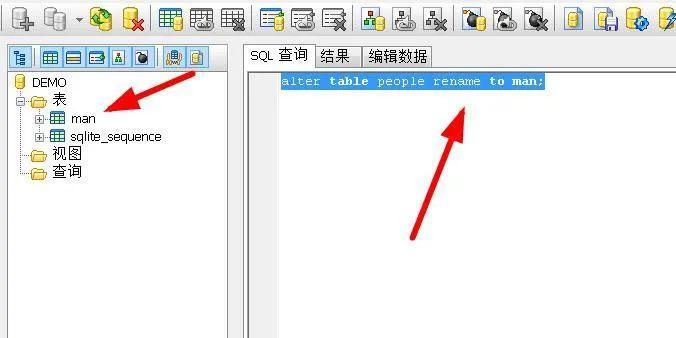
6).数据表的连接
这里的连接分为内外交叉三种连接,使用好了可以极大提高我们的工作效率。这里我们再次创建一张表,如下:
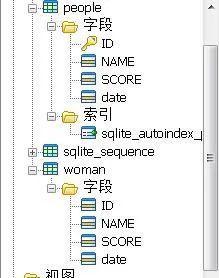
1)).交叉连接
select * from people cross join woman;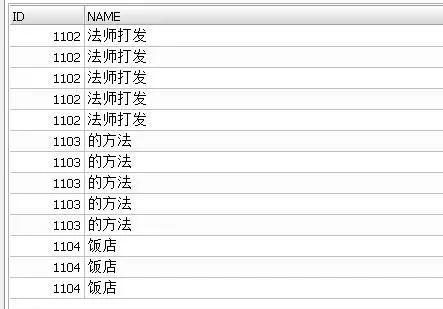
2)).内连接
select * from people inner join woman;3)).外连接
select * from people outer join woman;注:Sqlite3只支持左外连接。
7).表的复制
create table man as select * from people where 1=0;#复制表结构
create table woman as select * from people;#复制表结构和数据8).临时表
有时候我们不需要存储所有表的数据,这个时候临时表就很有使用的必要了。如下:
#创建一个临时表
create temporary table temp_table(
id int primary key,
name varchar(50) unique not null,
age int not null
);
#查看临时表
temp.temp_table
#删除临时表
drop table temp.temp_table;5.索引操作
1).创建索引
create index user on people(score);#在people表的score字段上设置索引
create unique name on people(NAME);#在people表的score字段上设置唯一索引
create index pa on people(score,age)#在people表的score和age字段上设置索引2).查看索引
SELECT * FROM sqlite_master WHERE type = 'index';
这里我们之前仅仅只是创建了一个索引,那就是”user“,为何会有两个索引了,而且最上面的索引好像跟我们并没有什么关系,也不像是自己创建的,其实,这个就是隐式索引,这个隐式索引在我们创建表的时候就连带着一起创建了的,只是为了让查询更加快速而已,影响不大。
3).使用索引
这里涉及到两个关键字请配套使用,表示索引来自于哪里的意思。
select * from people indexed by user where score>10;4).删除索引
drop index user;注:数据量较小不应使用索引,以免给系统增压。
6.视图操作
1).创建视图
create view name as select NAME from people;#创建NAME字段的视图2).使用视图
select *from name;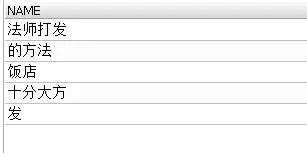
这样就可以直接输出视图字段的所有值了。
3).删除视图
drop view name;7.触发器
触发器就是使得多个表的交互增强,互相调用,满足条件就调用哪个表,语法格式如下:
create trigger 触发器 after(before) insert(delete update)
on 表1
begin
insert into 表2(表2字段,表2字段,n) VALUES(表1值, 表1值,,,,n);
END;1).创建触发器
#给people表创建一个触发器
create trigger cf
after insert on people
begin
insert into woman(w_ID,NAME,SCORE,date) values(new.ID,'向前插入',100,datetime('now'));
end;2).查看触发器
select * from sqlite_master where type = 'trigger'AND tbl_name='people';#查看people表的触发器3).删除触发器
drop trigger cf;8.事务
有了事务可以让我们的Sqlite语句工作的更加有条不紊,一般大致分为事务开始 提交 回滚 结束,下面来看看:
begin;#开始
insert into people('gf',65,datetime('now'));
rollback; #回滚就是撤销
COMMIT;提交保存数据
end;#结束这里的数据没有插入到“people”表中哦,是不是超级简单了?
二、总结
这篇文章主要介绍了Sqlite数据库的数据表、索引、视图、触发器和事务操作知识,干货满满。
皮皮自从学过Sqlite之后,就果断卸载了Mysql和Mongo了,主要是目前还用不着Mysql数据库和Mongo那么强大的数据,够用就好。
我是皮皮,如果觉得文章不错,记得三连噢,大家有问题也可以点击下方的图片,加我好友,交个朋友也好呀~