
1.keys命令
keys命令相信大家应该都用过,该命令会遍历整个redis的字典空间,对要查找的key进行匹配并返回。
就像官方文档所说:在生产环境使用该方法的过程中要非常小心,因为redis服务器在执行该命令的时候其他客户端读写命令都会被阻塞。
使用方法:
KEYS pattern 示例:
127.0.0.1:6379> set why1 1
OK
127.0.0.1:6379> set why2 2
OK
127.0.0.1:6379> set why3 3
OK
127.0.0.1:6379> set why4 4
OK
127.0.0.1:6379> keys why*
1) "why3"
2) "why4"
3) "why2"
4) "why1"
127.0.0.1:6379>2.redis的HashTable(字典)
keys命令,是遍历整个数据库。而redis是又是一个k-v型的内存数据库,一说到k-v,不由自主就想到了Java的HashMap。那么redis的"hashtable"的数据结构是什么样的呢?
1.HashTable的数据结构上下文
我们以debug模式运行redis-server的时候,可以看到在redis.c的initServer方法中,初始化了db。
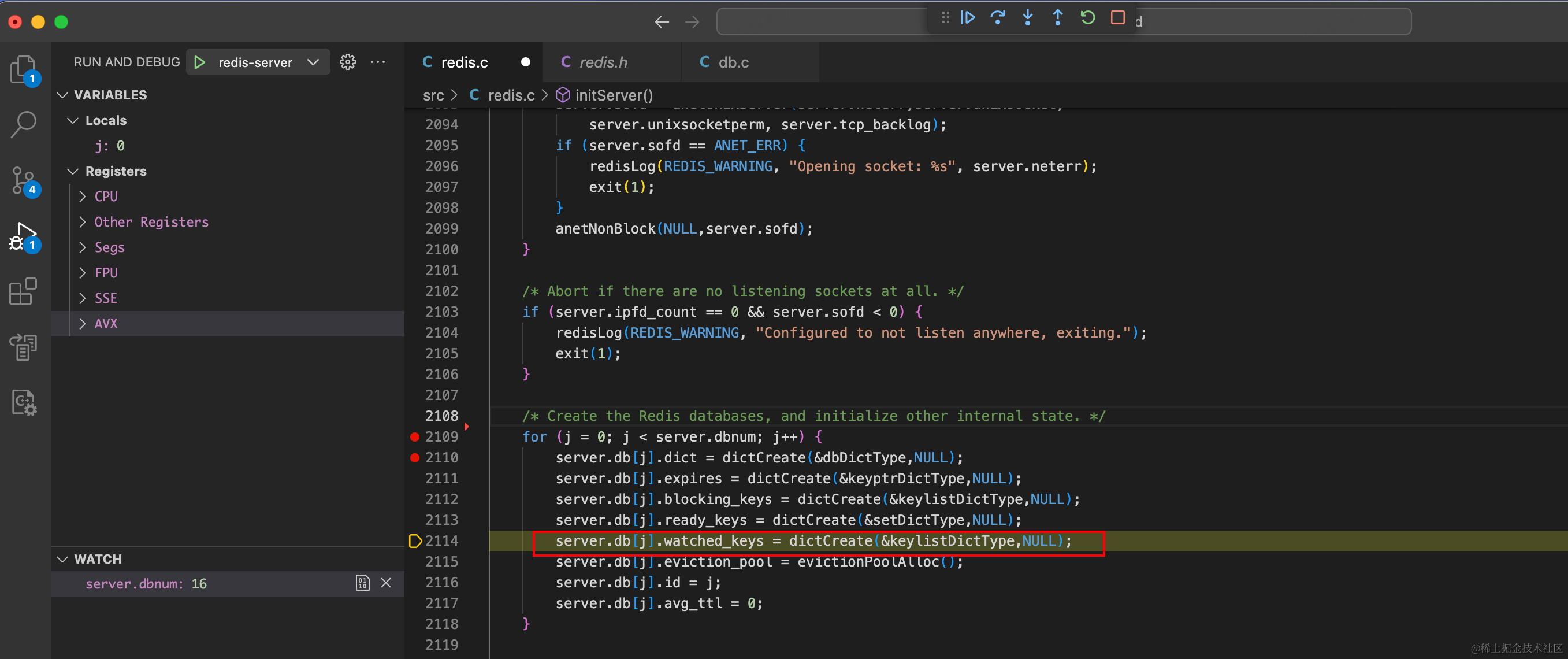
dbnum的值来源于配置:databases,默认为16。
在Redis.h中,对每个数据库实例做了定义:
/* Redis database representation. There are multiple databases identified
* by integers from 0 (the default database) up to the max configured
* database. The database number is the 'id' field in the structure. */
typedef struct redisDb {
dict *dict; /* The keyspace for this DB */
//删除了一些参数.......
} redisDb;那看样子,dict可能是对应的哈希表实现了,我们看下dict的结构:
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dict {
//一系列操作键值空间的函数
dictType *type;
//私有数据
void *privdata;
dictht ht[2];
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;看样子dict并不是最终的哈希表。我们继续看下dictht的结构:
typedef struct dictht {
// hash表的数组
dictEntry **table;
//表的大小
unsigned long size;
//size-1,用于计算索引
unsigned long sizemask;
//hash表中元素的数量
unsigned long used;
} dictht;看样子dicttht就是哈希表的实现了。可以看到dictht中定义了一个dictEntry类型的数组table,又定义了一系列的和table有关的上下文。
我们继续看下dictEntry的结构:
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
} v;
struct dictEntry *next;
} dictEntry;看样子dictEntry就是存储我们数据的地方了,看到next指针,我们可以猜到,redis解决hash冲突的方法和HashMap一样,也是拉链法。
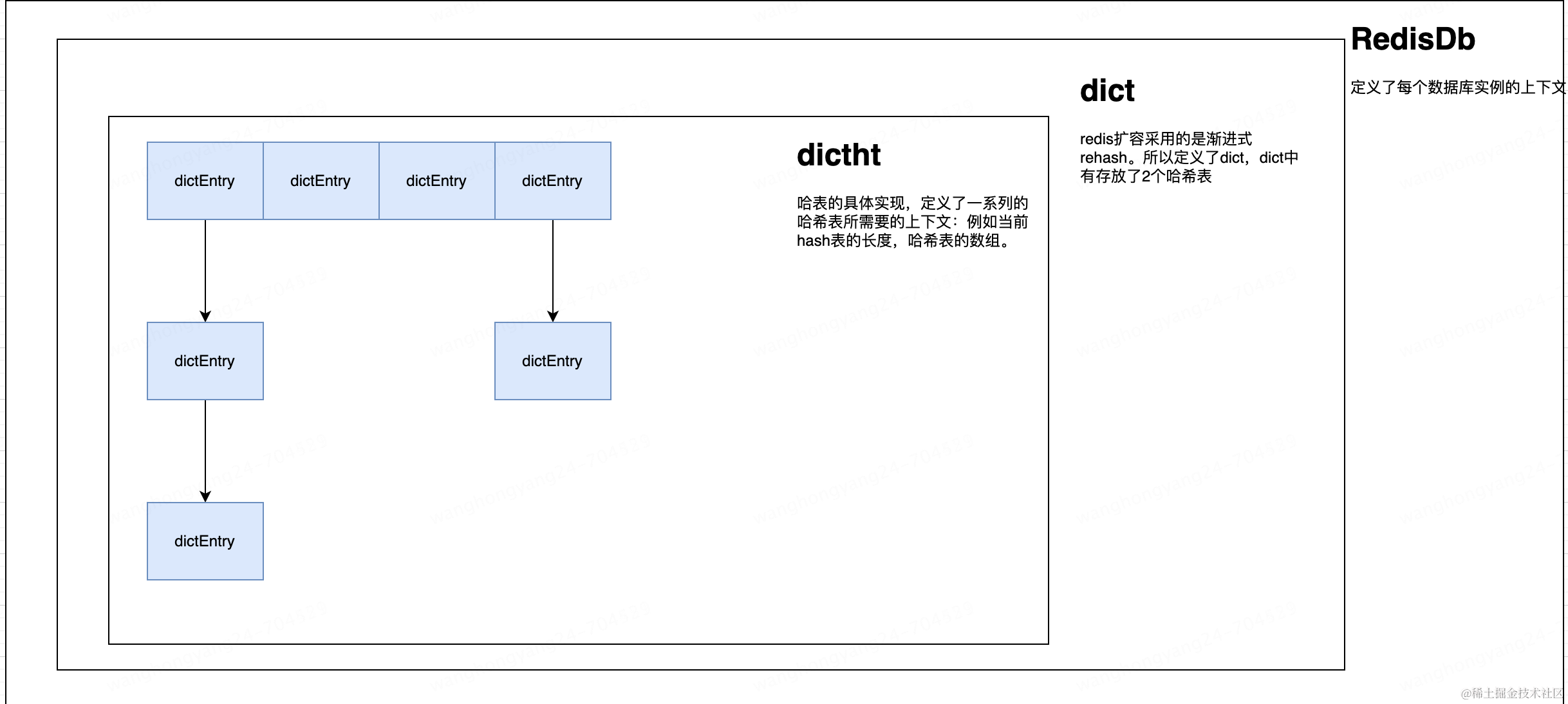
到这里我们可以总结一下:
- dict是hash表的最外层,存储了整个键值空间。并通过dictType定义了一系列的操作键值的函数。
- dictht是hash表的实现,定义了hash表的数据结构。
- 而dictEntry则是定义了数据的存放结构。
2.渐进式rehash
redis的哈希表和HashMap在设计上面一个比较明显不同就是rehash操作。因为redis的定义是一个数据库。所以其存放的数据会很多很多,为了防止在rehash的过程中因为大批量数据需要做迁移而引起的服务器长时间阻塞,redis采用的方法是渐进式rehash。
首先我们重新看一下dict结构体,它定义了2个hashtable。其中ht[1]就是协助完成渐进式rehash的。
typedef struct dict {
//一系列操作键值空间的函数
dictType *type;
//私有数据
void *privdata;
dictht ht[2];
int rehashidx; /* rehashing not in progress if rehashidx == -1 */
int iterators; /* number of iterators currently running */
} dict;1.rehash的触发
就拿新增操作来说,每次新增前,都会调用_dictExpandIfNeeded,检测一下是否要进行扩容操作:
static int _dictExpandIfNeeded(dict *d)
{
/* Incremental rehashing already in progress. Return. */
if (dictIsRehashing(d)) return DICT_OK;
/* If the hash table is empty expand it to the initial size. */
// T = O(1)
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE);
/* If we reached the 1:1 ratio, and we are allowed to resize the hash
* table (global setting) or we should avoid it but the ratio between
* elements/buckets is over the "safe" threshold, we resize doubling
* the number of buckets. */
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio))
{
// 扩容到原来的2倍
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}如果满足下面的case,就会调用dictExpand函数:
- 使用的数量used大于当前字典的长度size。
- 参数dict_can_resize为1或者当前数组长度满足强制扩容阈值dict_force_resize_ratio
就会去调用dictExpand函数,将当前字典扩容到已经使用元素的二倍。
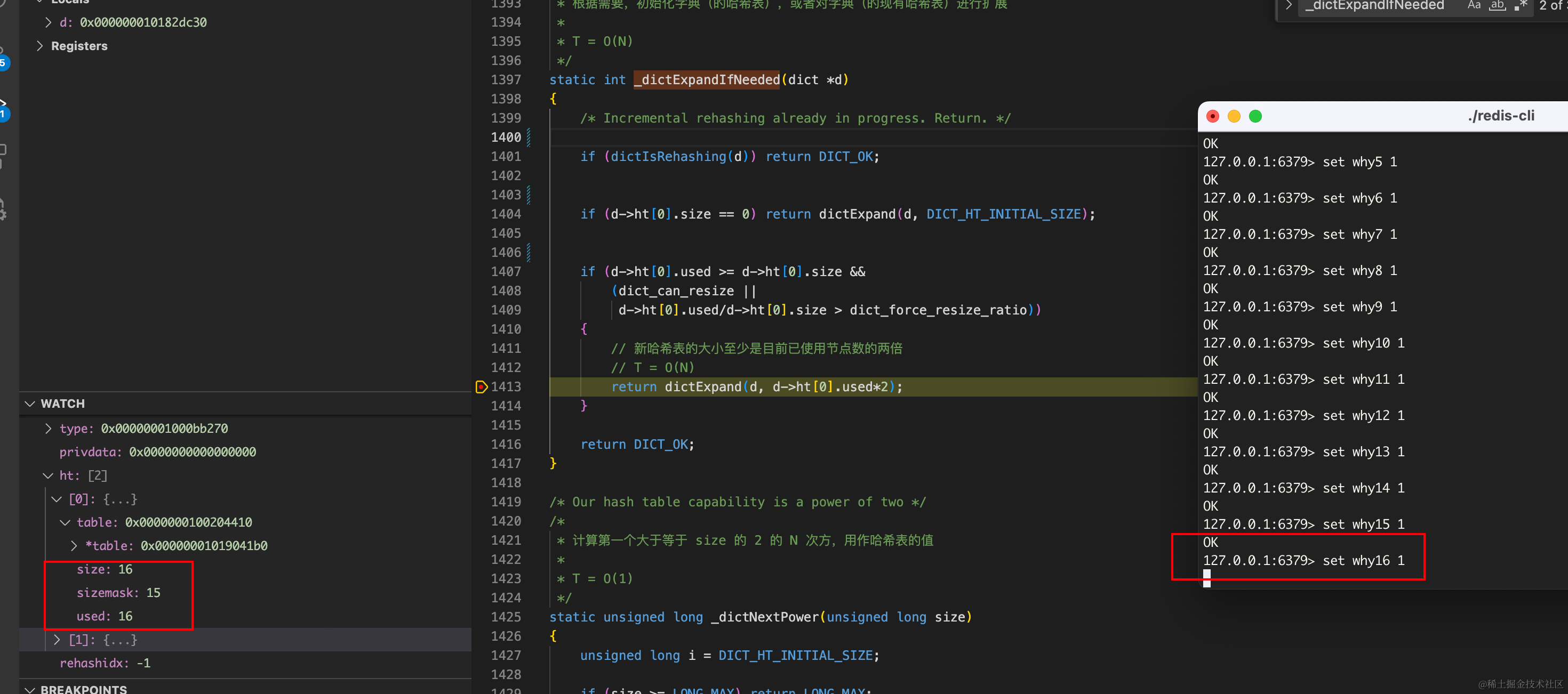
可以看到当我添加第16个元素的时候 就触发扩容操作了。
dictExpand函数负责扩容的的初始化动作(我们只看扩容部分的赋值逻辑):
- 调用_dictNextPower函数修正size,保证其大小始终是2的N次幂。
- 然后将dict中的ht[1]设置为扩容后的hashtable,并将rehashidx从-1设置为0。
int dictExpand(dict *d, unsigned long size)
{
dictht n; /* the new hash table */
unsigned long realsize = _dictNextPower(size);
/* the size is invalid if it is smaller than the number of
* elements already inside the hash table */
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
/* Allocate the new hash table and initialize all pointers to NULL */
n.size = realsize;
n.sizemask = realsize-1;
// T = O(N)
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
/* Is this the first initialization? If so it's not really a rehashing
* we just set the first hash table so that it can accept keys. */
if (d->ht[0].table == NULL) {
d->ht[0] = n;
return DICT_OK;
}
/* Prepare a second hash table for incremental rehashing */
d->ht[1] = n;
d->rehashidx = 0;
return DICT_OK;
}2.dict_force_resize_ratio和dict_can_resize
允许扩容的第二个条件中,需要dict_can_resize=1才允许扩容。这个参数的作用是什么?什么情况下dict_can_resize会被更新成0?
带着这两个问题我们看下dict_can_resize变量的注释:
/* Using dictEnableResize() / dictDisableResize() we make possible to
* enable/disable resizing of the hash table as needed. This is very important
* for Redis, as we use copy-on-write and don't want to move too much memory
* around when there is a child performing saving operations.
* Note that even when dict_can_resize is set to 0, not all resizes are
* prevented: a hash table is still allowed to grow if the ratio between
* the number of elements and the buckets > dict_force_resize_ratio.
*/
static int dict_can_resize = 1;
static unsigned int dict_force_resize_ratio = 5;注释中说的很清楚:不希望在执行写时复制的过程中再过多的去操作内存。
个人理解:save操作(比如 bgsave )通过fork函数创建的子进程,使用的是写时复制。执行save的过程中一方面有大量的读取内存的操作(子进程);另一方面如果在写时复制的过程中,redis服务端(父进程)又收到大量的写操作,那么就会触发共享对象的只读保护,引发缺页中断,进而触发页面的复制和页表的更新,这个时候系统负载会很大。为了降低系统负载,就尝试先关闭数据的迁移(数据迁移的过程中也涉及到了内存的读写操作)。
但是dict_can_resize并不会完全的去关闭迁移操作,如果这个时候load factor(used和size之比)超过dict_force_resize_ratio=5了,那么就强制做一次rehash。
3. 渐进rehash的处理
1.增删改查前协助rehash
进行rehash的函数是_dictRehashStep,该函数分别被dictAddRaw,dictGenericDelete,dictFind,dictGetRandomKey函数所调用。也就说redis每次在执行指令的时候都会尝试做一次数据迁移操作:
判断代码如下:
//还记得吗?在rehash开始前,将rehashidx设置为了0.
//如果当前rehashidx不为-1 说明在进行扩容
if (dictIsRehashing(d))
{
_dictRehashStep(d);
}
//dictIsRehashing的判断逻辑就是判断是否等于-1
#define dictIsRehashing(ht) ((ht)->rehashidx != -1)具体的,协助扩容代码如下:
当不存在安全迭代器的时候,进行一次数据的迁移。
static void _dictRehashStep(dict *d) {
if (d->iterators == 0)
dictRehash(d,1);
}dictRehash函数是真正做数据迁移的操作,n控制迁移的步数。可以知道的是在进行增删改查操作前,redis每次迁移1个hash槽下所有的数据到新的哈希表中:
int dictRehash(dict *d, int n) {
if (!dictIsRehashing(d)) return 0;
// 迁移次数
while(n--) {
dictEntry *de, *nextde;
/* Check if we already rehashed the whole table... */
//在下面可以看到每次迁移完成一个元素后,used都会做一个减1的操作. 那么当used等于0的时候,说明迁移结束了
if (d->ht[0].used == 0) {
//做一些数据的释放和hashtable的替换。
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
//设置当前状态为非扩容的标记
d->rehashidx = -1;
//返回0 说明rehash结束
return 0;
}
//越界判断
assert(d->ht[0].size > (unsigned)d->rehashidx);
//在旧的hashtable中找到一个非空的链表
while(d->ht[0].table[d->rehashidx] == NULL) d->rehashidx++;
de = d->ht[0].table[d->rehashidx];
//迁移开始
//整个while循环中做的操作就是将旧链表中的元素拿出来重新计算hash值,然后放到新hashtable中,并更新新旧hashtable的used
while(de) {
unsigned int h;
nextde = de->next;
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
// 更新rehashidx。也就是说rehashidx不等于的时候,它所指向的就是下一个要进行扩容的hash槽
d->rehashidx++;
}
//返回1 说明还需要继续rehash
return 1;
}2.定时事件中处理扩容
如果说我们的redis服务器正在扩容,但是还没什么读写请求,那这扩容总不能停下来不做了吧?所以redis除了在执行命令前做一个单步扩容外,在其定时事件中,也做了一次rehash操作:
void databasesCron(void) {
//省略和扩容无关的代码.....
//没有做后台线程在工作,才去做协助做rehash。
if (server.rdb_child_pid == -1 && server.aof_child_pid == -1) {
if (server.activerehashing) {
for (j = 0; j < dbs_per_call; j++) {
int work_done = incrementallyRehash(rehash_db % server.dbnum);
rehash_db++;
if (work_done) {
/* If the function did some work, stop here, we'll do
* more at the next cron loop. */
break;
}
}
}
}
}
}定时事件做迁移的前提:
- 没有rdb和aof在执行。
- Redid.config中的activerehashing配置开启。关于该配置的介绍:
# Active rehashing uses 1 millisecond every 100 milliseconds of CPU time in
# order to help rehashing the main Redis hash table (the one mapping top-level
# keys to values). The hash table implementation Redis uses (see dict.c)
# performs a lazy rehashing: the more operation you run into a hash table
# that is rehashing, the more rehashing "steps" are performed, so if the
# server is idle the rehashing is never complete and some more memory is used
# by the hash table.
#
# The default is to use this millisecond 10 times every second in order to
# active rehashing the main dictionaries, freeing memory when possible.
#
# If unsure:
# use "activerehashing no" if you have hard latency requirements and it is
# not a good thing in your environment that Redis can reply form time to time
# to queries with 2 milliseconds delay.
#
# use "activerehashing yes" if you don't have such hard requirements but
# want to free memory asap when possible.一次处理100个hash槽下面的数据:
int dictRehashMilliseconds(dict *d, int ms) {
long long start = timeInMilliseconds();
int rehashes = 0;
while(dictRehash(d,100)) {
rehashes += 100;
if (timeInMilliseconds()-start > ms) break;
}
return rehashes;
}3.keys命令的处理逻辑
说完了字典的数据结构和扩容操作后,我们回到key命令,看下keys命令的处理逻辑。keys命令的处理函数是src/db.c的keysCommand函数:
void keysCommand(redisClient *c) {
dictIterator *di;
dictEntry *de;
// 得到匹配模式
sds pattern = c->argv[1]->ptr;
int plen = sdslen(pattern), allkeys;
unsigned long numkeys = 0;
void *replylen = addDeferredMultiBulkLength(c);
// 获取一个安全迭代器 迭代当前连接的整个db
di = dictGetSafeIterator(c->db->dict);
allkeys = (pattern[0] == '*' && pattern[1] == '\0');
while((de = dictNext(di)) != NULL) {
sds key = dictGetKey(de);
robj *keyobj;
// 将键名和模式进行比对
if (allkeys || stringmatchlen(pattern,plen,key,sdslen(key),0)) {
// 创建一个保存键名字的字符串对象
keyobj = createStringObject(key,sdslen(key));
// 删除已过期键
if (expireIfNeeded(c->db,keyobj) == 0) {
addReplyBulk(c,keyobj);
numkeys++;
}
decrRefCount(keyobj);
}
}
//释放安全迭代器
dictReleaseIterator(di);
setDeferredMultiBulkLength(c,replylen,numkeys);
}处理逻辑很简单:解析命令,然后遍历当前连接对应的db,检查是否匹配,检查数据是否过期,最后将数据返回。
但是这个过程中,获取了一个安全迭代器,为什么有安全迭代器?安全指的是什么安全?线程安全吗?
4.安全迭代器和非安全迭代器
1.迭代器的上下文
先看下迭代器的结构体定义的参数:
/* If safe is set to 1 this is a safe iterator, that means, you can call
* dictAdd, dictFind, and other functions against the dictionary even while
* iterating. Otherwise it is a non safe iterator, and only dictNext()
* should be called while iterating. */
typedef struct dictIterator {
// 字典
dict *d;
int
table, //当前迭代器指向的hashtable,因为rehash存在2个hashtable,所以迭代器需要知道当前遍历到哪个了。
index, //迭代器所指向的hashtable的位置。
safe; //是否为安全迭代器
// entry :当前迭代的节点
// nextEntry :当前节点的下一个节点
dictEntry *entry, *nextEntry;
long long fingerprint; //指纹。非安全迭代器释放前做验证用
} dictIterator;从作者的注释中我们可以知道的是:迭代器区分安全和非安全,并不是为了处理并发问题,而是决定遍历的过程中可以不可以去修改数据。
安全迭代器在其迭代过程中,允许执行其他对字典的操作(最典型的就是过期键的清理)。
而非安全迭代器只能做遍历使用。
2.安全迭代器的创建
我们先看下安全迭代器的创建过程,安全迭代器的创建函数是dictGetSafeIterator:
dictIterator *dictGetSafeIterator(dict *d) {
dictIterator *i = dictGetIterator(d);
// 设置安全迭代器标识
i->safe = 1;
return i;
}内部调用了dictGetIterator函数,它的作用就是初始化迭代器:
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter));
iter->d = d;
iter->table = 0;
iter->index = -1;
iter->safe = 0;
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}小总结一下,初始化安全迭代器的过程有两步:
- 初始化迭代器的内存和参数。
- 设置迭代器标记为安全。
3.非安全迭代器的创建
非安全迭代器其实就是少了设置safe=1的那一步。
dictIterator *dictGetIterator(dict *d)
{
dictIterator *iter = zmalloc(sizeof(*iter));
iter->d = d;
iter->table = 0;
iter->index = -1;
iter->safe = 0;
iter->entry = NULL;
iter->nextEntry = NULL;
return iter;
}4.迭代器的使用
看下迭代器被使用的地方dictNext函数:
dictEntry *dictNext(dictIterator *iter)
{
while (1) {
//当entry=null当时候,会进入这个分支
if (iter->entry == NULL) {
dictht *ht = &iter->d->ht[iter->table];
//只有首次遍历,才会出现index=-1并且table等于0这种情况,这个时候会去更新iterators
if (iter->index == -1 && iter->table == 0) {
if (iter->safe)
//还记得我们的dict结构体中定义的变量吗?当安全迭代器首次进行遍历的时候
//就会增加该变量的值
iter->d->iterators++;
else
//非安全迭代器
iter->fingerprint = dictFingerprint(iter->d);
}
iter->index++;
if (iter->index >= (signed) ht->size) {
//遍历结束前判断是否在rehash,如果是,更新index=0,table=1。
if (dictIsRehashing(iter->d) && iter->table == 0) {
iter->table++;
iter->index = 0;
ht = &iter->d->ht[1];
} else {
break;
}
}
//综上所述,触发这个赋值的情况有2种:
//1.首次遍历hashtable[0]
//2.字典在进行rehash,首次遍历hashtable[1]
iter->entry = ht->table[iter->index];
} else {
iter->entry = iter->nextEntry;
}
if (iter->entry) {
//记录这次遍历的下一个节点
iter->nextEntry = iter->entry->next;
return iter->entry;
}
}
return NULL;
}- 该函数其实就是使用迭代器获取一个字典中的元素。
- 如果当前传入的是安全迭代器,在进行第一次遍历的时候,iterators会做一个增加。
- 如果当前是非安全迭代器,会计算一个fingerprint(不展开了,简单理解就是如果使用非安全迭代器的过程中,有数据被修改了那么指纹就会发生变化,当释放迭代器的时候会做指纹检测)。
- 如果当前在进行rehash,那么table[1]也会被遍历。
- 在函数返回前, iter->nextEntry = iter->entry->next记录了这次遍历过程中的下一条数据。并且下一次遍历会使用 iter->nextEntry。
iterators++的作用?
还记得分步rehash的函数判断吗?
static void _dictRehashStep(dict *d) {
if (d->iterators == 0) dictRehash(d,1);
}也就是说,当有安全迭代器存在的时候,单步rehash的操作会被禁止。
为什么要记录下一次要遍历的节点?
首先安全迭代器的定义是遍历的过程中可以做读写操作。如果迭代器返回的当前节点设置了过期时间,那么就可能因为过期导致该节点被清理掉,也就是从链表中移除。那么下一次迭代就会终止进而导致数据遍历的缺失。
5.迭代器的释放
迭代器的释放函数是dictReleaseIterator:
void dictReleaseIterator(dictIterator *iter)
{
if (!(iter->index == -1 && iter->table == 0)) {
// 释放安全迭代器对渐进式rehash的阻止
if (iter->safe)
iter->d->iterators--;
// 如果当前是非安全迭代器,需要看一下指纹是否有变化,如果有变化会触发一个警告:
/**
=== REDIS BUG REPORT START: Cut & paste starting from here ===
[23085] 20 Jan 22:45:08.802 * DB saved on disk
[23086] 20 Jan 22:45:08.804 # === ASSERTION FAILED ===
[23086] 20 Jan 22:45:08.808 # ==> dict.c:1029 'iter->fingerprint == dictFingerprint(iter->d)' is not true
*/
else
assert(iter->fingerprint == dictFingerprint(iter->d));
}
zfree(iter);
}5.总结
最后我们做一个总结:首先我们从keys命令出发对redis的字典结构和渐进式rehash做了一个分析。
渐进rehash的触发有2种情况:一个是redis读写的时候做一次rehash,一个是定时事件定时协助rehash(前提是配置开启并且没有进行rdb和aof)。
然后我们又从keys命令的处理函数出发,对redis的两种迭代器做了一次分析:
安全迭代器:安全迭代器会让渐进式rehash停止,并且还允许在迭代的过程中对数据做增删,能够保证不会遍历到重复的数据。
除了keys使用了安全迭代器外,像rdb持久化和BGREWRITEAOF都使用的安全迭代器去遍历的数据,来防止重复的数据和过期数据的写入。
我理解安全迭代器其实是给后台进程做各种数据的持久化用的。我上面说安全迭代器存在的时候,单步rehash的操作会被禁止。但是我们还有定时事件也在做rehash呀?那里并没有判断 if (d->iterators == 0) 。
但是它做了这个判断:if (server.rdb_child_pid == -1 && server.aof_child_pid == -1),在没有 BGSAVE 或者 BGREWRITEAOF 执行时,才对哈希表进行 rehash。
非安全迭代器:非安全迭代器只允许做遍历操作,可能遍历到重复数据(因为没有对rehash做限制,此时如果发生rehash操作,那么就可能将遍历过的数据迁移到未遍历过的位置上)。并且非安全迭代器还有一个fingerprint,每次释放迭代器前都会看一下指纹是否被修改过。
我个人理解,非安全迭代器其实是给redis的主进程用的。因为有fingerprint的存在,如果说后台进程使用了非安全迭代器,在后台进程使用的过程中,主进程做了大批量的数据修改,那么在释放的迭代器的时候,对fingerprint做的校验就会不通过。
全文完
参考资料:
redis官方文档:https://redis.io/
redis源码:https://github.com/redis/redis
书籍:《Redis设计与实现》
最后,本人能力有限,可能有分析不到位或者错误的地方,在此先说一声抱歉。
如果有错误的地方,请批评指正,谢谢!






